前言 在计算机视觉领域中,图像识别是一项非常重要的任务。而语义分割则是其中的一个子任务。与图像分类和目标检测不同,语义分割不仅需要识别出图像中的物体,还需要将每个像素分配给它所属的类别。本专栏适用于想要入门语义分割与想要对语义分割有一个全面系统的了解的读者。
本教程禁止转载。同时,本教程来自知识星球【CV技术指南】更多技术教程,可加入星球学习。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!
目录
随着计算机视觉领域的日渐成熟,许多领域都会用到语义分割的相关内容,这让它成为了学术果和工业界最火热的研究方向之一。应广大粉丝读者的需要,我们决定将以专栏的形式与大家一起分享关于语义分割的相关技术文章。
专栏将大致包含18篇推文,专栏目录初步安排如下:
(一) 简单介绍
(二) 入门FCN,简单分析语义分割+代码
(三) 复习FCN,介绍语义分割的基本结构
(四)~(九) 经典论文解读
(十) 引入Transformer结构和注意力机制
(十一)~(十三) 注意力机制的花样使用
(十四)~(十五) 双分支结构模型
(十六)~(十七) 多特性与信息
(十八) 总结
语义分割概念
当我们看到一张图片,我们能够直接分辨出图片中的各个物体,比如人、车、建筑等等。但是对于计算机来说,要想实现这一点就需要进行语义分割。语义分割是计算机视觉领域的一个任务,它的目的是将图像中的每个像素进行分类,划分为不同的语义类别,从而更好地理解图像。
举个例子,比如下面这张图:


我们希望计算机能够自动地识别出图像中的每个像素属于哪个类别,比如蓝色的是车,红色的是人,这就是语义分割的任务。
难点
从上图可以看出,语义分割的任务难点在于对物体边缘的精准切割,并将它们分配给正确的类别标签,这就需要模型具有足够的感知能力,能够理解图像中的不同物体、颜色、纹理和形状,以及它们之间的关系。同时,模型还需要能够对图像的每个像素进行分类,因为相同的物体可能在不同的位置、大小和方向上出现。
除了这种常规的难点,语义分割任务在实际应用上还会有一些更具体的问题,例如:
- 一张图片中可能有很多小物体,比如一堆砾石或者一群昆虫。这些小物体很难被计算机准确地识别和分类。
- 不同的物体可能看起来很相似,比如一只猫和一只狗。在这种情况下,模型需要能够区分它们,将它们分配给正确的类别。
- 一张图片的背景很复杂,比如一张公园里的图片,可能有很多树、草和建筑物。在这种情况下,计算机需要能够识别和分离背景和物体。
- 还需要能够处理不同尺度和角度的图片,并且能够泛化到新的场景中。例如,在训练模型时使用的图片可能都是正面拍摄的,但是在实际使用中,可能会遇到侧面拍摄的图片。
应用领域
语义分割在计算机视觉领域有着广泛的应用,比如自动驾驶、医学影像分析、地图制作等等。在自动驾驶中,语义分割可以帮助车辆更好地识别交通标志、行人、车辆等物体,提高驾驶安全性;在医学影像分析中,语义分割可以帮助医生更好地识别和定位肿瘤、器官等结构,提高疾病诊断准确性。
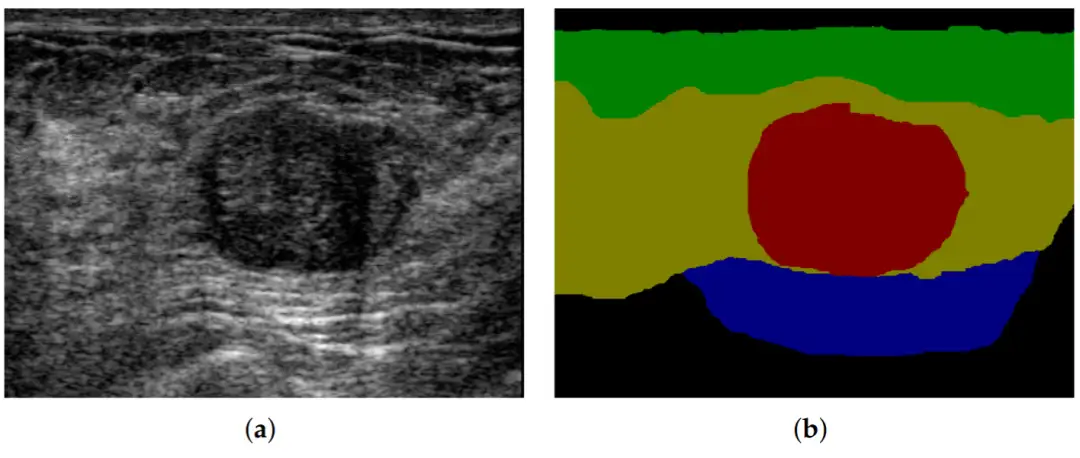
数据集
在语义分割中,数据集的质量对于算法的性能有着重要的影响。常用的语义分割数据集包括 Cityscapes、PASCAL VOC、COCO 等,在一些具体的细分领域中(医学、室内场景、室外场景、卫星图)还存在着许多其他的数据集,但抽象而言,数据集中总会包含以下内容:
最重要的————————— 原始的RGB图像 标注好的RGB图像
一般重要的
——————————————————————————————————————————
边界框:边界框是一个矩形框,用于标识图像中物体的位置和大小。这对于一些应用场景非常重要,例如目标检测和跟踪。
语义分割掩码:掩码是一种二进制图像,用于指示语义分割模型应该关注的区域。在许多情况下,我们只关注图像中的一部分,而不是整个图像,这时可以使用掩码来表示。
图像描述信息:有时候我们还会将一些关于图像的文本描述信息包含在数据集中。例如,一张图片可能包含一个人在沙滩上玩耍,这时候我们可以将这些文本描述信息包含在数据集中,有助于增强模型的语义理解能力。
数据集说明文档:包括数据集的详细说明和说明文档,如数据集大小,图像尺寸,标签类别等。
——————————————————————————————————————————
评价指标
评价指标是用来度量模型性能的重要工具。下面是几个常用的评价指标:
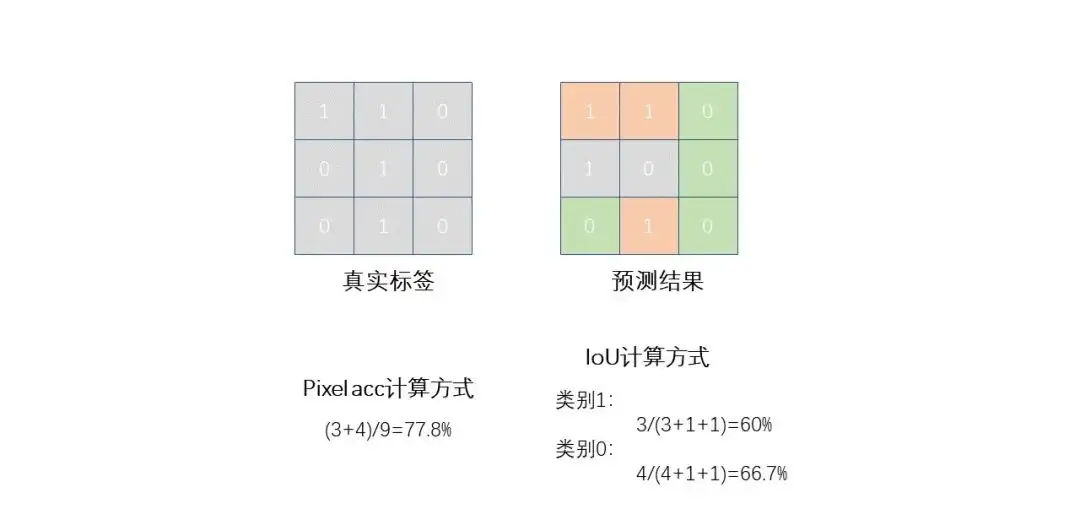
像素准确度(Pixel accuracy):像素准确度是指模型正确预测的像素占总像素数的比例。但它并不能区分不同类别的预测结果。
平均交并比(Mean Intersection over Union,简称mIOU):平均交并比是预测结果与真实标签之间的重叠度量,其计算方式为预测结果和真实标签的交集除以它们的并集。在所有类别的交并比的平均值是mIOU。mIOU是目前最流行的语义分割评价指标之一。
下面这幅图展示了这两个评价指标的算法:
除此之外,我们还有可能用到这两个指标的升级版:平均像素准确度(Mean pixel accuracy):平均像素准确度是像素准确度的加权平均值,其中权重是各个类别的像素数。可以区分不同类别的预测结果。频率加权交并比(Frequency Weighted Intersection over Union,简称FWIoU):FWIoU是平均交并比的变种,其权重是各个类别的像素数。这可以解决样本不均衡的问题。
最新研究进展
- 针对小目标的分割 由于小目标通常在图像中占据较少的像素,难以被分类器准确识别,因此针对小目标的语义分割一直是一个挑战。
- 半/无监督语义分割 在一些场景下,语义分割任务的标注成本较高,因此半监督和无监督都是比较热门的研究方向,核心是在利用少量标注(半监督)或者不使用标注(无监督)的情况下学习语义分割。
- 实时语义分割 实时语义分割的本质是轻量化,在自动驾驶等领域中具有重要的应用价值。为了实现实时语义分割,通常采用轻量化网络结构和各种硬件加速技术,以实现快速和高效的语义分割。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
【CV技术指南】咱们自己的CV全栈指导班、基础入门班、论文指导班 全面上线!!
CVPR 2023|21 篇数据集工作汇总(附打包下载链接)
CVPR 2023|两行代码高效缓解视觉Transformer过拟合,美图&国科大联合提出正则化方法DropKey
ViT-Adapter:用于密集预测任务的视觉 Transformer Adapter
CodeGeeX 130亿参数大模型的调优笔记:比FasterTransformer更快的解决方案
CVPR 2023 深挖无标签数据价值!SOLIDER:用于以人为中心的视觉
上线一天,4k star | Facebook:Segment Anything
Efficient-HRNet | EfficientNet思想+HRNet技术会不会更强更快呢?
ICLR 2023 | SoftMatch: 实现半监督学习中伪标签的质量和数量的trade-off
目标检测创新:一种基于区域的半监督方法,部分标签即可(附原论文下载)
CNN的反击!InceptionNeXt: 当 Inception 遇上 ConvNeXt
拯救脂肪肝第一步!自主诊断脂肪肝:3D医疗影像分割方案MedicalSeg
AI最全资料汇总 | 基础入门、技术前沿、工业应用、部署框架、实战教程学习
AAAI 2023 | 轻量级语义分割新范式: Head-Free 的线性 Transformer 结构
标签:分割,语义,像素,专栏,图像,视觉,CV From: https://www.cnblogs.com/wxkang/p/17352879.html