简介
近年来,随着以 OpenAI GPT2 模型 为代表的基于数百万网页数据训练的大型 Transformer 语言模型的兴起,开放域语言生成领域吸引了越来越多的关注。开放域中的条件语言生成效果令人印象深刻,典型的例子有: GPT2 在独角兽话题上的精彩续写,XLNet 以及 使用 CTRL 模型生成受控文本 等。促成这些进展的除了 transformer 架构的改进和大规模无监督训练数据外,更好的解码方法 也发挥了不可或缺的作用。
本文简述了不同的解码策略,同时向读者展示了如何使用流行的 transformers 库轻松实现这些解码策略!
下文中的所有功能均可用于 自回归 语言生成任务 (点击 此处 回顾)。简单复习一下, 自回归 语言生成是基于如下假设: 一个文本序列的概率分布可以分解为每个词基于其上文的条件概率的乘积。
$$ P(w_{1:T} | W_0 ) = \prod_{t=1}^T P(w_{t} | w_{1: t-1}, W_0) \text{ , 其中 } w_{1: 0} = \emptyset, $$
上式中,$W_0$ 是初始 上下文 单词序列。文本序列的长度 $T$ 通常时变的,并且对应于时间步 $t=T$。$P(w_{t} | w_{1: t- 1}, W_{0})$ 的词表中已包含 终止符 (End Of Sequence,EOS)。 transformers 目前已支持的自回归语言生成任务包括 GPT2 、 XLNet 、 OpenAi-GPT 、 CTRL 、 TransfoXL 、 XLM 、 Bart 、 T5 模型,并支持 PyTorch 和 TensorFlow (>= 2.0) 两种框架!
我们会介绍目前最常用的解码方法,主要有 贪心搜索 (Greedy search)、波束搜索 (Beam search)、Top-K 采样 (Top-K sampling) 以及 Top-p 采样 (Top-p sampling) 。
在此之前,我们先快速安装一下 transformers 并把模型加载进来。本文我们用 GPT2 模型在 TensorFlow 2.1 中进行演示,但 API 和使用 PyTorch 框架是一一对应的。
!pip install -q git+https://github.com/huggingface/transformers.git
!pip install -q tensorflow==2.1
import tensorflow as tf
from transformers import TFGPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
# add the EOS token as PAD token to avoid warnings
model = TFGPT2LMHeadModel.from_pretrained("gpt2",pad_token_id=tokenizer.eos_token_id)
贪心搜索
贪心搜索在每个时间步 $t$ 都简单地选择概率最高的词作为当前输出词: $w_t = argmax_{w}P(w | w_{1:t-1})$ ,如下图所示。
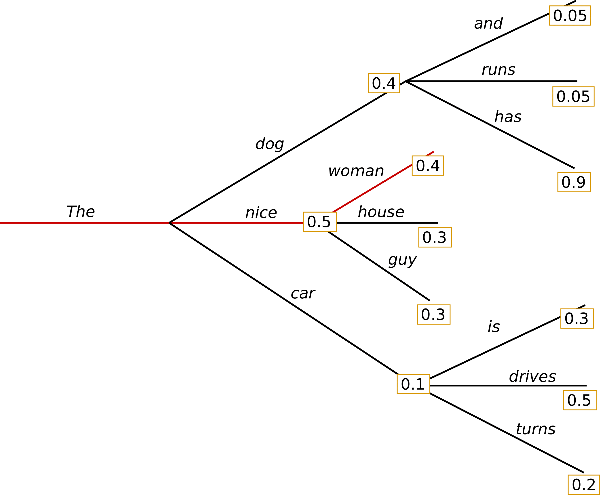
从单词 $\text{“The”}$ 开始,算法在第一步贪心地选择条件概率最高的词 $\text{“nice”}$ 作为输出,依此往后。最终生成的单词序列为 $(\text{“The”}, \text{“nice”}, \text{“woman”})$,其联合概率为 $0.5 \times 0.4 = 0.2$。
下面,我们输入文本序列 $(\text{“I”}, \text{“enjoy”}, \text{“walking”}, \text{“with”}, \text{“my”}, \text{“cute”}, \text{“dog”})$ 给 GPT2 模型,让模型生成下文。我们以此为例看看如何在 transformers 中使用贪心搜索:
# encode context the generation is conditioned on
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='tf')
# generate text until the output length (which includes the context length) reaches 50
greedy_output = model.generate(input_ids, max_length=50)
print("Output:\n" + 100 *'-')
print(tokenizer.decode(greedy_output[0], skip_special_tokens=True))
Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with my dog. I'm not sure if I'll ever be able to walk with my dog.
I'm not sure if I'll
好,我们已经用 GPT2 生成了第一个短文本
标签:采样,Transformers,text,top,dog,生成,文本,my,Top From: https://www.cnblogs.com/huggingface/p/17351307.html