虚拟化性能评估方法论
 计算
计算2022-12-26 17:42:49 34阅读
本文关键词:kvm虚拟化、性能评估、性能测试、性能优化
引言
什么是虚拟化,对一些功能进行抽象封装后不暴露内部结构对外提供功能我们可以叫它接口api,如果暴露内部细节形成新的功能接口,我们就可以认为这是一种虚拟化。虚拟化的功能之一是模拟一个和A一样的B,对于使用者来说,B长的和A一样,用着和A一样,方方面面都和A一样,那么B就是A,比如对于虚拟机和容器里运行的程序来说,和真实的物理机上一样有独立的进程空间和资源,他就认为自己处于真实的物理机上。
虚拟化是云计算领域的一项关键技术,它将信息资源重新进行了定义和划分,解决了信息资源在调度、分配、隔离等各方面的问题,很大程度提高了信息资源的利用率。
Kvm(KVM,Kernel-based Virtual Machine)是一个 Linux 的内核模块,基于硬件(如intel的VT-d、VT-x和AMD的AMD-v)的虚拟化的实现方式,提供了很好的性能和适用性。和qemu/libvirt配合使用形成了当前最流行的虚拟机管理器(VMM——Virtual Machine Manager)方案。

对于一个系统软件的使用者和维护者来说,解决可用性和稳定性之后的一个体验提升就是性能优化,流畅反应、惊人的速度总是令人心情愉悦,产品的竞争力大增。一般应用程序面向物理机开发优化,现在可能运行在虚拟机、容器上,部署在对应的云服务或者微服务,虚拟化层的多样性让应用程序的优化变得更具有挑战性。由于实现方式的不同,各自在性能损耗方面会有些差异。那么,
如何评估一个虚拟化环境或者一个软件系统的好坏?
如何改进和提升虚拟化的性能?
1、性能评估指标
通常评价一个系统的性能的三个指标是吞吐越高、延迟越低、资源利用率越少,系统性能越好。
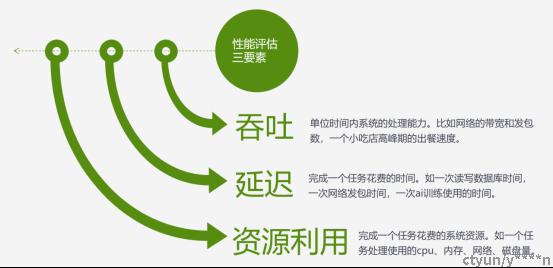
通过这三个维度我们就能唯一确定一个系统的性能状态。
2、性能评估工具
我们对性能评估,往往需要定一个评估规则和基准,以便于做对比分析。不同行业积累了不少优秀的工具,当然也可以根据自己的业务定制。主流的就是开源社区提供的一些工具,因为业务场景的复杂性,通用工具反应的分数可能和真实体验略有偏差,大厂往往喜欢根据自己的业务定制(也可能是通用工具跑出来的分数不如竞品~~)。
评测性能指标的“一个任务”也是精心挑选的,在专门的评测工具中可能包含一系列的负载,能够测试系统的各项性能,测试具有代表性或者高频的场景。
2.1 基于传统操作系统的性能评估工具
虚拟化的目的之一是让用户感觉自己处于一个真的物理环境,那我们就用真实的物理环境指标评估它是再合适不过了。
评估cpu性能,常用的是SPEC公司的CPU2000、CPU2006、sysbench的cpu工具,intel的mlc,也有unixbench(针对unix/linux环境各种计算、copy、系统调用等等)、SuperPI(计算圆周率)、cyclesoak,schbench(调度延迟)
评估内存性能,常规手段是一次内核编译、sysbench的内存工具、stream
评估磁盘性能,fio、hdparm
评估网络性能,netperf、iperf、pktgen、hping3、qperf
一些场景测试,java虚拟机的specjvm、dpdk的dpdk-testpmd、Lmbench
全虚拟化的情况下时间虚拟化有可能不准确,必要时使用物理时间或者网络时间校验。
下面我们详细介绍最具代表性的四种工具:unixbench、stream、fio、iperf。
2.1.1 unixbench
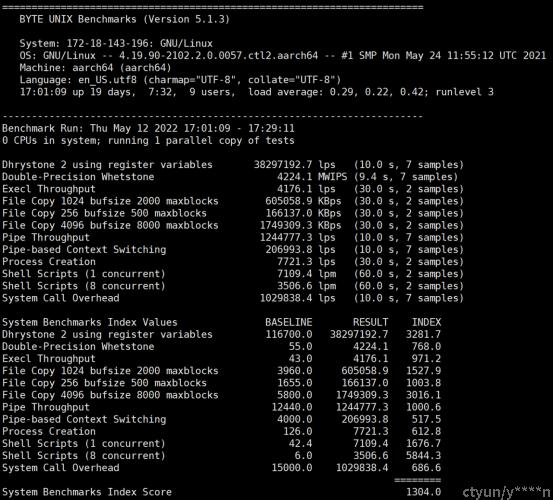
UnixBench 是一个类 Unix 系(Unix,BSD,Linux)统下的性能测试工具,一个开源工具,被广泛用与测试 Linux 系统主机的性能。UnixBench 的主要测试项目有:系统调用、读写、进程、图形化测试、2D、3D、管道、运算、C库等系统基准性能提供测试数据。此测试的目的是对类Unix 系统提供一个基本的性能指示,很多测试用于系统性能的不同方面,这些测试的结果是一个指数值(index value,如520),这个值是测试系统的测试结果与一个基线系统测试结果比较得到的指数值,这样比原始值更容易得到参考价值,测试集合里面所有的测试得到的指数值结合起来得到整个系统的指数值。
各项的测试有得分,然后有一个综合的得分,这样可以很方便的通过分数去比较。
基线系统是“George”, 源于1995 年的一个工作站:SPARCstation 20‐61,128MB RAM,Solaris2.3,此系统的指数值被设定为10,所以,如果一个系统的最后结果分数为520,意思是指此系统比基线系统运行快52 倍。
UnixBench也支持多CPU系统的测试,默认的行为是测试两次,第一次是一个进程的测试,第二次是N份测试,N等于CPU个数。这样的设计是为了以下目标:
* 测试系统的单任务性能
* 测试系统的多任务性能
* 测试系统并行处理的能力
UnixBench一个基于系统的基准测试工具,不单纯是CPU内存或者磁盘测试工具。测试结果不仅仅取决于硬件,也取决于系统、开发库、甚至是编译器。
测试的项目有:
* Dhrystone 2 using register variables:此项用于测试 字符串处理,因为没有浮点操作,所以深受软件和硬件设计、编译和链接、代码优化、对内存的、等待状态、整数数据类型的影响。
* Double-Precision Whetstone:这一项测试浮点数操作的速度和效率。这一测试包括几个模块,每个模块都包括一组用于科学计算的操作。覆盖面很广的一系列 c 函数:sin,cos,sqrt,exp,log 被用于整数和浮点数的数学运算、数组访问、条件分支和程序调用。此测试同时测试了整数和浮点数算术运算。
* Execl Throughput:此测试考察每秒钟可以执行的 execl 系统调用的次数。 execl 系统调用是 exec 函数族的一员。它和其他一些与之相似的命令一样是 execve() 函数的前端。
* File copy:测试从一个文件向另外一个文件传输数据的速率。每次测试使用不同大小的缓冲区。这一针对文件 read、write、copy 操作的测试统计规定时间(默认是 10s)内的文件 read、write、copy 操作次数。
* Pipe Throughput:管道(pipe)是进程间交流的最简单方式,这里的 Pipe throughtput 指的是一秒钟内一个进程可以向一个管道写 512 字节数据然后再读回的次数。需要注意的是,pipe throughtput 在实际编程中没有对应的真实存在。
* Pipe-based Context Switching:这个测试两个进程(每秒钟)通过一个管道交换一个不断增长的整数的次数。这一点很向现实编程中的一些应用,这个测试程序首先创建一个子进程,再和这个子进程进行双向的管道传输。
* Process Creation:测试每秒钟一个进程可以创建子进程然后收回子进程的次数(子进程一定立即退出)。process creation 的关注点是新进程进程控制块(process control block)的创建和内存分配,即一针见血地关注内存带宽。一般说来,这个测试被用于对操作系统进程创建这一系统调用的不同实现的比较。
* System Call Overhead:测试进入和离开操作系统内核的代价,即一次系统调用的代价。它利用一个反复地调用 getpid 函数的小程序达到此目的。
* Shell Scripts:测试一秒钟内一个进程可以并发地开始一个 shell 脚本的 n 个拷贝的次数,n 一般取值 1,2,4,8。(在测试时取 1,8)。这个脚本对一个数据文件进行一系列的变形操作(transformation)
工具获取
项目地址: https://github.com/kdlucas/byte-unixbench
安装依赖编译(以centos系统为例)
#yum -y install gcc gcc-c++ make libXext-devel perl perl-Time-HiRes mesa-libGL-devel libX11-devel
#make
#./Run -c 1 -c 4 表示执行两次,第一次单个copies,第二次4个copies的测试任务。
使用样例
#./Run
需要10-30分钟不等
测试结果:
2.1.2 stream
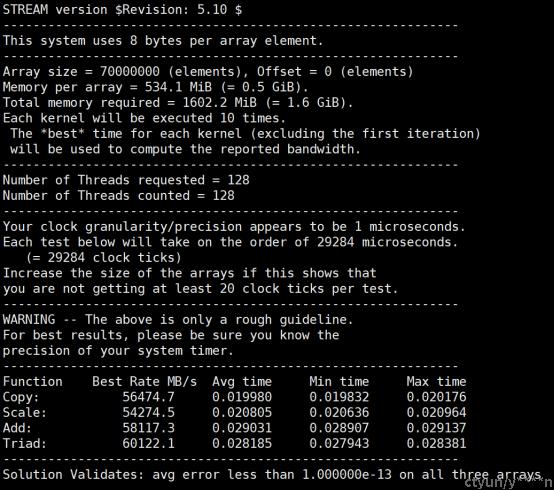
Stream测试是内存测试中业界公认的内存带宽性能测试基准工具,由Virginia University提供,通过生成四种不同模式下的内存读写操作,用于测试高性能计算机的内存带宽。 现代计算机中都是用缓存技术,为了保证测试正确反映计算机内存的读写性能,测试中使用的数据量应远大于缓存大小。 更多介绍请参考:http://www.cs.virginia.edu/stream/ref.html
Stream 是合成的benchmark 程序,用c和Fortran 77 编写,测试4个方面的操作。操作如下:
name kernel bytes FLOPS
------------------------------------------
COPY: a(i) = b(i) 16 0
SCALE: a(i) = q*b(i) 16 1
ADD: a(i) = b(i) + c(i) 24 1
TRIAD: a(i) = b(i) + q*c(i) 24 2
对应到测试分别代表:
COPY:先访问一个内存单元读出其中的值,再将值写入到另一个内存单元
SCALE:先从内存单元读出其中的值,作一个乘法运算,再将结果写入到另一个内存单元
ADD:先从内存单元读出两个值,做加法运算, 再将结果写入到另一个内存单元
TRIAD:先从内存单元中中读两个值a、b,对其进行乘加混合运算(a + 因子 * b ) ,将运算结果写入到另一个内存单元
工具获取
source code: http://www.cs.virginia.edu/stream/FTP/Code/
多线程编译:
# gcc -O -fopenmp -DSTREAM_ARRAY_SIZE=<array_size> -DNTIME=20 stream.c -o stream.o
参数说明:
-STREAM_ARRAY_SIZE 测试数组大小,默认是10000000,一般来说array size的大小是缓存大小的4倍
-NTIMES 测试时间,默认是10
-OFFSET 调节数组的内存对齐,默认为0,一般不用修改
-openMP多线程支持 添加-fopenmp选项,icc为-openmp,pgcc为-mp,Open64的opencc为-openmp
使用样例
#./stream.o
2.1.3 fio
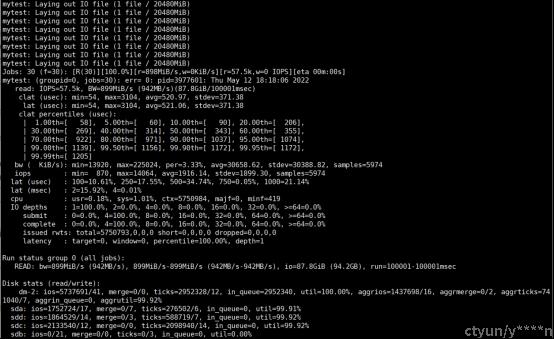
Fio常用来评估磁盘性能。
fio是一个用于基准测试和压力/硬件验证的I/O工具。它支持19种不同类型的I/O引擎(sync, mmap, libaio, posixaio, SG v3, splice, null, network, syslet, guasi, solarisaio等),I/O优先级(对于更新的Linux内核),速率I/O,分叉或线程作业,以及更多。它可以在块设备和文件上工作。Fio接受简单易懂的文本格式的职位描述。包括几个示例作业文件。fio显示各种I/O性能信息,包括完整的IO延迟和百分比。Fio在许多地方都有广泛的应用,包括基准测试、QA和验证。支持Linux、FreeBSD、NetBSD、OpenBSD、OS X、OpenSolaris、AIX、HP-UX、Android、Windows。
参数详解
bw=平均IO带宽
iops=IOPS
runt=线程运行时间
slat=提交延迟,提交该IO请求到kernel所花的时间(不包括kernel处理的时间)
clat=完成延迟, 提交该IO请求到kernel后,处理所花的时间
lat=响应时间
bw=带宽
cpu=利用率
IO depths=io队列
IO submit=单个IO提交要提交的IO数
IO complete=Like the above submit number, but for completions instead.
IO issued=The number of read/write requests issued, and how many of them were short.
IO latencies=IO完延迟的分布
io=总共执行了多少size的IO
aggrb=group总带宽
minb=最小.平均带宽.
maxb=最大平均带宽.
mint=group中线程的最短运行时间.
maxt=group中线程的最长运行时间.
ios=所有group总共执行的IO数.
merge=总共发生的IO合并数.
ticks=Number of ticks we kept the disk busy.
io_queue=花费在队列上的总共时间.
util=磁盘利用率
工具获取
yum install fio
或者官网下载:http://freecode.com/projects/fio
使用样例
#fio -direct=1 -iodepth 1 -thread -rw=read -ioengine=psync -bs=16k -size=20G -numjobs=30 -runtime=100 -group_reporting -name=mytest
2.1.4 iperf
iperf 是一款测试最大网络带宽的工具。支持各种参数的设置,比如时间,缓存以及协议(TCP,UDP,SCTP with IPv4 and IPv6)。Iperf每次测试可以报告带宽,延迟抖动和数据包丢失。利用Iperf这一特性,可以用来测试一些网络设备如路由器,防火墙,交换机等的性能。iperf需要同时在服务器和客户机上运行。
常用参数介绍,更多参数参考 #iperf --help:
服务器端和客户端共有:
-p, --port : 服务器端端口
-i, --interval:显示报告时间间隔,以秒为单位
-J, --json: 以JSON格式输出
--logfile f: 输出结果到一个log file
服务器端:
-s, --server: 以服务器模式运行
客户端:
-b, --bitrate:设置目标带宽,0 for unlimited,默认1Mb/s for UDP,unlimited for TCP,如果需要测试网络速度,可以将数字设置为高于网络提供商提供的最大带宽上限
-c, --client: 以客户端模式运行
-u, --udp: 用UDP协议,不加此参数时,是默认的TCP协议
-t, --time: 运行时间,以秒为单位
-l, --length: 设置缓冲区的大小,默认128KB for TCP,8KB for UDP
-M,--set-mss: 设置TCP/SCTP的最大MSS的值,(MTU-40 bytes)
-P, --parallel:客户端并行run的数量
工具获取
直接yum 安装: yum install iperf3
或编译安装版本如下http://software.es.net/iperf/
使用样例
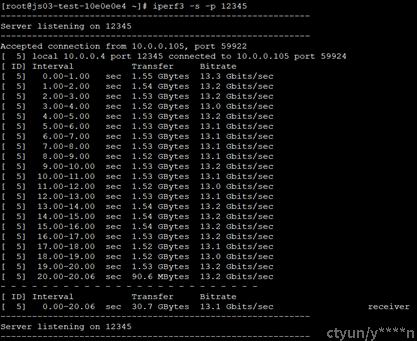
服务器端:
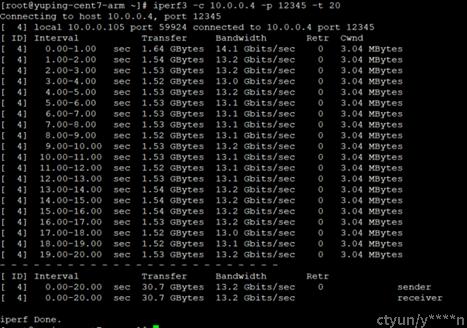
客户端:
2.2 基于虚拟化的性能评估工具
一些云厂商提供虚拟化方向的评估工具,如intel的vConsolidate、VMware的VMmark等。也有内核kvm方向的监测工具,基于kvmtrace/xentrace探针,linux使用perf工具检测kvm事件,比如统计10秒内vm的entry和exit次数:
#perf stat -e 'kvm:*' -p `pidof qemu-kvm` -a sleep 10
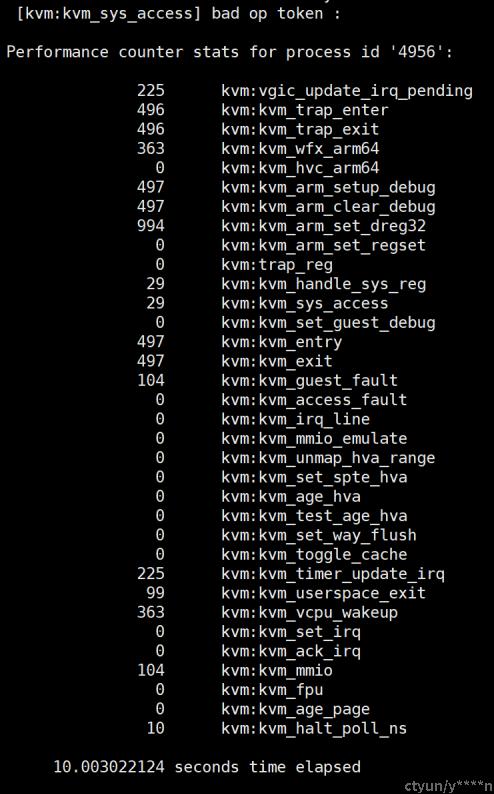
通过统计可以观察到虚拟化开销的位置和次数。
2.3 性能分析工具
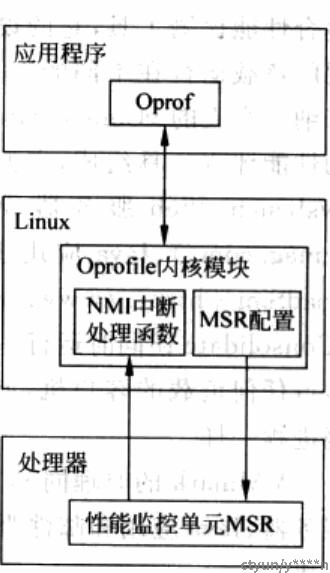
linux的oprofile项目,移植到xen后叫xenoprof
oprofile结构:
xenoprof结构:
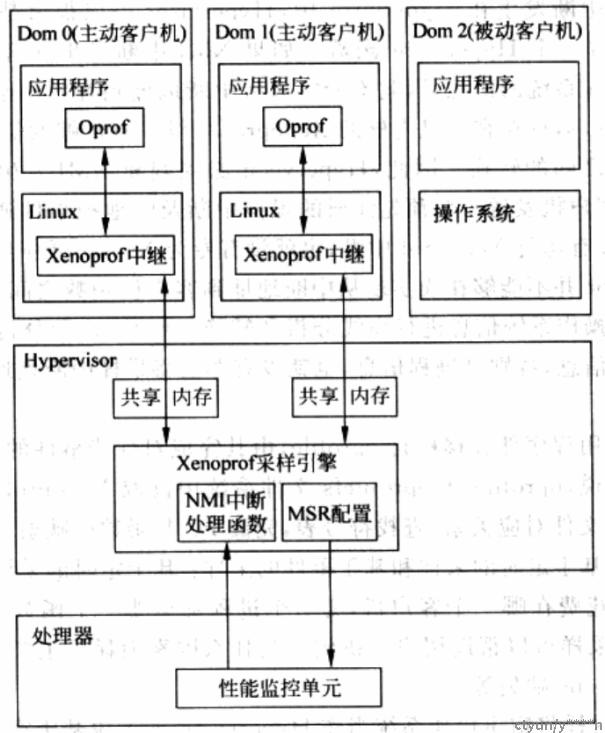
xentrace是xen架构下比较有力的探测方式,而kvm方式侧重于kvmtrace、perf、ftrace等内核级工具
常规的分析是通过sys/proc文件系统、或者:ps、top、free、lscpu、mpstat、vmstat、gdb/pstack、numastat、iostat、blktrace、sar等系统分析工具
3、 性能优化
性能评估的主要目的就是为了优化。
3.1 配置优化
性能的优化是一个全流程的任务,在软硬件资源限定的情况下,通过各种评估手段、分层分段来找到性能瓶颈点,继而不断攻破它。软件和业务各有特点、我们这里探讨一些不易察觉的、通用的优化。
bios:打开Pstate设置,从节能模式调节成性能模式,电源管理和cpu频率(睿频)会从根本上影响整机性能。mwait关闭会禁用idle驱动,cpu则也无法进入更深的睡眠状态,如果我们对内核比较熟悉,且有一定的掌控力,应该打开bios测的各种优化特性,从grub和内核驱动配置掌控调节对应的特性。
软件:内核编译参数相应的支持pstate相关功能,配置性能模式,设置大页内存;对vm进行绑核和透传设置、使能网卡多队列、指定cpu和内存的numa配置、进行相应的numa和中断平衡。
3.2 降低vm exit次数
我们大体上可以认为Cpu在宿主机上的操作和虚拟机内部的cpu操作叫做根模式和非根模式,两种状态的转换叫做VMExit和VMEntry,这种转换是实现虚拟化的基础,同时也占用许多开销。
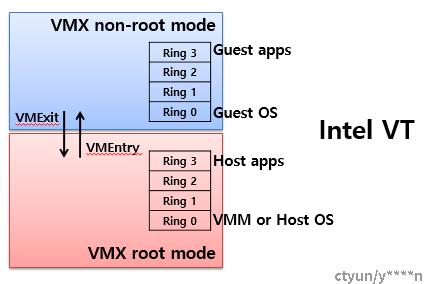
我们也有许多方式降低这部分的损耗。部分方式如下:
硬件加速,如打开影子TPR/CR 8寄存器减少此操作引发的退出
通过vm异常位图直接由硬件将异常注入vm的IDT中
共享内存
影子页表
硬件EPT可以降低退出频率
直接分配IO
将硬件设备直接透传给vm,是比较常用且有效的手段
批量Hypercall
3.3 全卸载
在云里,一台宿主机上可以开许多虚拟机,但是要预留一些cpu、内存给宿主机,不但用于本身的运行,也用于一些管理面、数据面、安全监控等程序的正常运行,这部分开销的比例单机并不太大,但是成千上万台的数据中心加和起来就是非常庞大的开销。对于怎么提升性能、降低这部分的开销至关重要。云厂商的底层工程师大部分的工作都是围绕这个目标直接或者间接开展的。

服务的cpu等硬件比fpga、智能网卡的要昂贵的多,如果将这些非虚拟机的程序运行在fpga或者智能网卡上,信息服务通过pci总线或者tcp/ip传递给主机,主机的资源将能够全部释放给业务,这种形式我们称为卸载,基于这个宏伟梦想,各个头部厂商也纷纷提出自己的计算、网络、存储卸载方案,并投入海量的研发资源,从硬件到软件的全系重构和适配。目前实现并落地全卸载的代表是阿里的神龙架构,aws的Nitro。
当前的智能网卡形态就是一张网卡上集成了cpu、内存、存储等硬件的主机,上面运行一个完整的操作系统,通过pci总线或者网络与主机直接联通。它给卸载提供了硬件和底层系统的环境基础。
网络卸载:kvm虚拟机使用的网络流量早期是通过ovsvswitch管理转化,要占用许多cpu资源、产生内存copy;后来有些厂商开始使用vhost-user dpdk方式,内存零拷贝,cpu开销并没有怎么缓解;终极大招来了,在主机上加一个fpga或者智能网卡,将网络的程序运行在智能网卡上,应用RDMA等技术降低网络延迟,消耗的是fpga或者智能网卡的算力,这样主机的cpu资源可以全部给虚拟机。
存储卸载:存储的物理形态分为云硬盘和本地硬盘,对于本地盘的性能提升近年火热的就是spdk方案,云盘形式大厂大多基于ceph、cinder形式,依托于fpga和外置芯片卡的方式行业内也都在推进。
计算卸载:kvm+qemu+网络组成提供了虚拟机的全部功能,libvirt是上层和下层的桥梁,主要负载在qemu底噪上,libvirt是上层直接接触的底座。将底噪底座挪走到智能网卡上,上层应用的改造和适配就是水到渠成的事。
目前行业现状是,因为研发投入较大,只有头部和硬件厂商偏重于这部分优化,卸载方案原理大同小异,实现各不相同。云的方式是可见的未来的主流互联网基础设施,是互联网中最重要的基石,性能优化又会有哪些挑战和变化,让我们拭目以待吧。
标签:方法论,IO,虚拟化,--,性能,内存,测试,评估 From: https://www.cnblogs.com/yaoyangding/p/17346769.html