pytorch在有限的资源下部署大语言模型(以ChatGLM-6B为例) 在PyTorch中加载预训练的模型时,通常的工作流程是这样的: 用简单的话来说,这些步骤是: 虽然这对常规大小的模型来说非常有效,但当我们处理一个巨大的模型时,这个工作流程有一些明显的局限性:在第1步,我们在RAM中加载一个完整版本的模型,并花一些时间随机初始化权重(这将在第3步被丢弃)。在第2步,我们在RAM中加载另一个完整版本的模型,并使用预训练的权重。如果你正在加载一个具有60亿个参数的模型,这意味着你需要为每个模型的副本提供24GB的RAM,所以总共需要48GB(其中一半用于在FP16中加载模型)。 引入accelerate处理大模型的第一个工具是上下文管理器init_empty_weights(),它可以帮助你在不使用任何RAM的情况下初始化一个模型,这样,步骤1就可以可以在任何尺寸的模型上进行。以下是它的工作原理: 例如: 初始化一个空的模型,参数略多于100B。这有赖于PyTorch 1.9中引入的元设备(meta device)。在上下文管理器下的初始化过程中,每次创建一个参数时,它都会移动到该设备上。 你的模型有可能大到即使是一个副本也无法装入RAM。这并不意味着它不能被加载:如果你有一个或几个GPU,这将有更多的内存可用于存储你的模型。在这种情况下,如果你的检查点被分割成几个较小的文件,我们称之为检查点碎片,效果会更好。 accelerate将处理分片检查点,只要你遵循以下格式:你的检查点应该在一个文件夹中,有几个文件包含部分状态字典,应该有一个JSON格式的索引,包含一个字典将参数名称映射到包含其权重的文件。例如,我们可以有一个包含以下内容的文件夹: 与index.json是以下文件: first_state_dict.bin包含 "linear1.weight "和 "linear1.bias "的权重。second_state_dict.bin是 "linear2.weight "和 "linear2.bias "的权重。 第二个工具是引入了一个函数load_checkpoint_and_dispatch(),它将允许你在你的空模型中加载一个检查点。这支持完整的检查点(一个单个文件包含整个状态描述)以及分片检查点。它还会在你可用的设备(GPU、CPURAM)上自动分配这些权重,所以如果你正在加载一个分片检查点,最大的RAM使用量将是最大分片的大小。 请注意,在transformer中用from_config加载模型并不绑定权重,这在加载不包含绑定权重的重复键的检查点时可能导致问题。所以你应该在加载检查点之前绑定权重。 然后加载我们刚刚下载的检查点: 通过传递device_map="auto",根据可用的资源,我们告诉模型的每一层放置在哪里。 no_split_module_classes=["GPTJBlock"] 表示属于GPTJBlock的模块不应该在不同的设备上被分割。你应该在这里设置所有包括某种residual(残差连接)的块。 你可以通过hf_device_map来查看accelearte挑选的设备图。 如果你喜欢明确地决定每层的位置,你也可以自己设计你的设备图。在这种情况下,上面的命令变成了: 现在我们已经做到了这一点,我们的模型位于几个设备之间,也许还有硬盘。但它仍然可以作为一个普通的PyTorch模型使用: 在幕后,accelerate为模型添加了钩子,因此: 你可以通过以下选项"auto", "balanced", "balanced_low_0", "sequential"让acclerate处理设备图的计算,或自己创建一个。如果你想更多地控制每个层应该去哪里,你可以在一个元设备上的模型上推导出模型的所有尺寸(从而计算出一个设备图)。 当你没有足够的GPU内存来容纳整个模型时,所有的选项都会产生相同的结果(也就是把所有能装的东西都装到GPU上,然后把重量卸到CPU上,如果没有足够的内存,甚至卸到磁盘上)。 当你有比模型大小更多的GPU内存可用时,这里是每个选项之间的区别: 首先注意,你可以通过使用max_memory参数(在fer_auto_device_map()和所有使用该参 的函数中可用)限制每个GPU上使用的内存。当设置max_memory时,你应该传递一个包含GPU标识符(例如0、1等)和 "cpu "键的字典,用于你希望用于CPU卸载的最大RAM。这些值可以是一个整数(以字节为单位),也可以是一个代表数字及其单位的字符串,例如 "10GiB "或 "10GB"。 这里有一个例子,我们不希望在两个GPU上各使用超过10GiB,而在模型权重上不超过30GiB的CPU内存: 当PyTorch发生首次分配时,它会加载CUDA内核,根据GPU的情况,它需要大约1-2GB的内存。因此,你的可用内存总是少于GPU的实际大小。要查看实际使用了多
少内存,请执行torch.ones(1).cuda()并查看内存使用情况。因此,当你用max_memory创建内存映射时,确保相应地调整可用的内存,以避免出先OOM。 此外,如果你对你的输出做一些额外的操作而不把它们放回CPU(例如在transformer的生成方法里面),如果你把你的输入放在一个GPU上,这个GPU将比其他的消耗更多的内存(加速器总是把输出放回输入的设备)。因此,如果你想优化最大的批处理量,并且你有很多GPU,给第一个GPU较少的内存。例如在8x80 A100设置上使用BLOOM-176B,接近理想的映射是: 你可以看到,我们给其余7个GPU的内存比GPU 0多了50%。 如果你选择自己完全设计设备映射,它应该是一个字典,键是你的模型的模块名称,值是一个有效的设备标识符(例如GPU是一个整数)或CPU卸载的 "cpu",磁盘卸载的 "disc"。键需要覆盖整个模型,然后你可以按照你的意愿定义你的设备映射:例如,如果你的模型有两个块(比方说block1和block2),它们各自包含三个线性层(比方 说线性1、线性2和线性3),一个有效的设备映射可以是: 另一个有效的可能是: 另一方面,这个是无效的,因为它没有涵盖模型的每个参数: 为了达到最高的效率,请确保你的设备映射以连续的方式将参数放在GPU上(例如 ,不要将第一个权重放在GPU 0上,然后将权重放在GPU 1上,最后一个权重再放 回GPU 0),以避免在GPU之间进行多次数据传输。 我们知道目前API的局限性: 基础环境: 下载相关文件: 正常情况下,我们使用Chat-GLM需要的显存大于13G,内存没有评估过,但上述的肯定是不够的,16G应该可以。 直接使用量化以后的模型: GPU使用4.9G,内存使用5.5G。 使用acclerate,只有一块GPU。 GPU使用9.7G,内存使用5.9G。第一轮输入你好后GPU使用11.2G。 使用accelerate,多块GPU。 环境:windwos下。GPU:4*4090 24G。内存:128G。python>=3.8,torch==2.0+117,transformers==4.28.1,acclerate==0.18.0。 注意,这里我们设置设备映射为balanced,并只使用前两块GPU。显卡占用情况: 会发现平均分配了显存,当然GPU 0分配得更多些、至此,关于如何进行大模型推理就全部完成了。 https://huggingface.co/docs/accelerate/usage_guides/big_modelingPart1知识准备
my_model = ModelClass(...)
state_dict =
torch.load(checkpoint_file)
1使用accelerate
上下文管理器
from accelerate import init_empty_weights
with init_empty_weights():
my_model = ModelClass(...)with init_empty_weights():
model = nn.Sequential(*[nn.Linear(10000, 10000) for _ in range(1000)])分布式检查点
first_state_dict.bin
index.json
second_state_dict.bin{
"linear1.weight": "first_state_dict.bin",
"linear1.bias": "first_state_dict.bin",
"linear2.weight": "second_state_dict.bin",
"linear2.bias": "second_state_dict.bin"
}加载权重
from accelerate import init_empty_weights
from transformers import AutoConfig, AutoModelForCausalLM
checkpoint = "EleutherAI/gpt-j-6B"
config = AutoConfig.from_pretrained(checkpoint)
with init_empty_weights():
model = AutoModelForCausalLM.from_config(config)model.tie_weights()model = load_checkpoint_and_dispatch(
model, "sharded-gpt-j-6B", device_map="auto", no_split_module_classes=["GPTJBlock"]
)
model.hf_device_map{'transformer.wte': 0,
'transformer.drop': 0,
'transformer.h.0': 0,
'transformer.h.1': 0,
'transformer.h.2': 0,
'transformer.h.3': 0,
'transformer.h.4': 0,
'transformer.h.5': 0,
'transformer.h.6': 0,
'transformer.h.7': 0,
'transformer.h.8': 0,
'transformer.h.9': 0,
'transformer.h.10': 0,
'transformer.h.11': 0,
'transformer.h.12': 0,
'transformer.h.13': 0,
'transformer.h.14': 0,
'transformer.h.15': 0,
'transformer.h.16': 0,
'transformer.h.17': 0,
'transformer.h.18': 0,
'transformer.h.19': 0,
'transformer.h.20': 0,
'transformer.h.21': 0,
'transformer.h.22': 0,
'transformer.h.23': 0,
'transformer.h.24': 1,
'transformer.h.25': 1,
'transformer.h.26': 1,
'transformer.h.27': 1,
'transformer.ln_f': 1,
'lm_head': 1}model = load_checkpoint_and_dispatch(model, "sharded-gpt-j-6B", device_map=my_device_map)运行模型
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
inputs = tokenizer("Hello, my name is", return_tensors="pt")
inputs = inputs.to(0)
output = model.generate(inputs["input_ids"])
tokenizer.decode(output[0].tolist())
设计一个设备图
from accelerate import infer_auto_device_map
device_map = infer_auto_device_map(my_model, max_memory={0: "10GiB", 1: "10GiB", "cpu": "30GiB"})
max_memory = {0: "30GIB", 1: "46GIB", 2: "46GIB", 3: "46GIB", 4: "46GIB", 5: "46GIB", 6: "46GIB", 7: "46GIB"}device_map = {"block1": 0, "block2": 1}device_map = {"block1": 0, "block2.linear1": 0, "block2.linear2": 1, "block2.linear3": 1}device_map = {"block1":0, "block2.linear1":1, "block2.linear2":1}
限制和进一步发展
Part2部署ChatGLM-6B
torch==2.0.0+cu118
transformers==4.28.1
accelerate==0.18.0
Tesla T4 15.3G
内存:11.8Ggit clone https://github.com/THUDM/ChatGLM-6B
cd ChatGLM-6B
git clone --depth=1 https://huggingface.co/THUDM/chatglm-6b THUDM/chatglm-6b
git clone --depth=1 https://huggingface.co/THUDM/chatglm-6b-int4 THUDM/chatglm-6b-int4
pip install -r requirements.txt
pip install gradio
pip install accelerate2第一种方案
from accelerate import infer_auto_device_map, init_empty_weights, load_checkpoint_and_dispatch
from transformers import AutoConfig, AutoModel, AutoModelForCausalLM, AutoTokenizer
import gradio as gr
import torch
import time
tokenizer = AutoTokenizer.from_pretrained("./THUDM/chatglm-6b-int4", trust_remote_code=True)
model = AutoModel.from_pretrained("./THUDM/chatglm-6b-int4", trust_remote_code=True).half().cuda()
model = model.eval()
def predict(input, history=None):
print(f'predict started: {time.time()}');
if history is None:
history = []
response, history = model.chat(tokenizer, input, history)
return response, history
while True:
text = input(">>用户:")
response, history = model.chat(tokenizer, input, history)
print(">>CHatGLM:", response)3第二种方案
%cd /content/ChatGLM-6B
from accelerate import infer_auto_device_map, init_empty_weights, load_checkpoint_and_dispatch
from transformers import AutoConfig, AutoModel, AutoModelForCausalLM, AutoTokenizer
import gradio as gr
import torch
import time
tokenizer = AutoTokenizer.from_pretrained("./THUDM/chatglm-6b", trust_remote_code=True)
config = AutoConfig.from_pretrained("./THUDM/chatglm-6b", trust_remote_code=True)
with init_empty_weights():
model = AutoModel.from_config(config, trust_remote_code=True)
for name, _ in model.named_parameters():
print(name)
# device_map = infer_auto_device_map(model, no_split_module_classes=["GLMBlock"])
# print(device_map)
device_map = {'transformer.word_embeddings': 0, 'transformer.layers.0': 0, 'transformer.layers.1': 0, 'transformer.layers.2': 0, 'transformer.layers.3': 0, 'transformer.layers.4': 0, 'transformer.layers.5': 0, 'transformer.layers.6': 0, 'transformer.layers.7': 0, 'transformer.layers.8': 0, 'transformer.layers.9': 0, 'transformer.layers.10': 0, 'transformer.layers.11': 0, 'transformer.layers.12': 0, 'transformer.layers.13': 0, 'transformer.layers.14': 0, 'transformer.layers.15': 0, 'transformer.layers.16': 0, 'transformer.layers.17': 0, 'transformer.layers.18': 0, 'transformer.layers.19': 0, 'transformer.layers.20': 0, 'transformer.layers.21': 'cpu', 'transformer.layers.22': 'cpu', 'transformer.layers.23': 'cpu', 'transformer.layers.24': 'cpu', 'transformer.layers.25': 'cpu', 'transformer.layers.26': 'cpu', 'transformer.layers.27': 'cpu', 'transformer.final_layernorm': 'cpu', 'lm_head': 'cpu'}
model = load_checkpoint_and_dispatch(model, "./THUDM/chatglm-6b", device_map=device_map, offload_folder="offload", offload_state_dict=True, no_split_module_classes=["GLMBlock"]).half()
def predict(input, history=None):
print(f'predict started: {time.time()}');
if history is None:
history = []
response, history = model.chat(tokenizer, input, history)
return response, history
while True:
history = None
text = input(">>用户:")
response, history = model.chat(tokenizer, text, history)
print(">>CHatGLM:", response)4第三种方案
import os
os.environ["cuda_visible_devices"] = "0,1"
from accelerate import infer_auto_device_map, init_empty_weights, load_checkpoint_and_dispatch
from transformers import AutoConfig, AutoModel, AutoModelForCausalLM, AutoTokenizer
# import gradio as gr
# import torch
import time
tokenizer = AutoTokenizer.from_pretrained(".\\chatglm-6b\\", trust_remote_code=True)
config = AutoConfig.from_pretrained(".\\chatglm-6b\\", trust_remote_code=True)
with init_empty_weights():
model = AutoModel.from_config(config, trust_remote_code=True)
for name, _ in model.named_parameters():
print(name)
# device_map = infer_auto_device_map(model, no_split_module_classes=["GLMBlock"])
# print(device_map)
# device_map = {'transformer.word_embeddings': 0, 'transformer.layers.0': 0, 'transformer.layers.1': 0, 'transformer.layers.2': 0, 'transformer.layers.3': 0, 'transformer.layers.4': 0, 'transformer.layers.5': 0, 'transformer.layers.6': 0, 'transformer.layers.7': 0, 'transformer.layers.8': 0, 'transformer.layers.9': 0, 'transformer.layers.10': 0, 'transformer.layers.11': 0, 'transformer.layers.12': 0, 'transformer.layers.13': 0, 'transformer.layers.14': 0, 'transformer.layers.15': 0, 'transformer.layers.16': 0, 'transformer.layers.17': 0, 'transformer.layers.18': 0, 'transformer.layers.19': 0, 'transformer.layers.20': 0, 'transformer.layers.21': 'cpu', 'transformer.layers.22': 'cpu', 'transformer.layers.23': 'cpu', 'transformer.layers.24': 'cpu', 'transformer.layers.25': 'cpu', 'transformer.layers.26': 'cpu', 'transformer.layers.27': 'cpu', 'transformer.final_layernorm': 'cpu', 'lm_head': 'cpu'}
model = load_checkpoint_and_dispatch(model, ".\\chatglm-6b\\", device_map="balanced", offload_folder="offload", offload_state_dict=True, no_split_module_classes=["GLMBlock"]).half()
def predict(input, history=None):
print(f'predict started: {time.time()}')
if history is None:
history = []
response, history = model.chat(tokenizer, input, history)
return response, history
while True:
history = None
text = input(">>用户:")
response, history = model.chat(tokenizer, text, history)
print(">>CHatGLM:", response)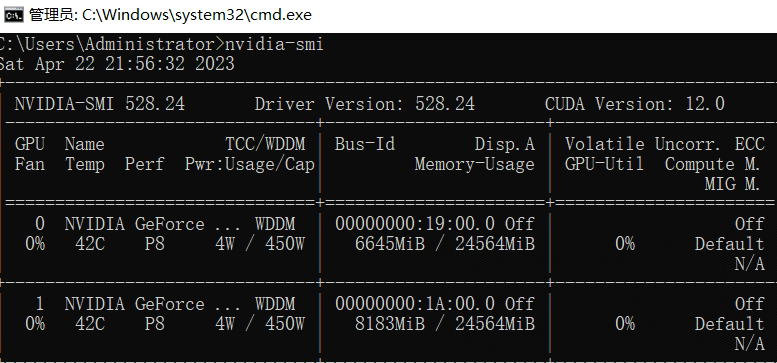
Part3参考
https://github.com/THUDM/ChatGLM-6B/issues/69
https://github.com/THUDM/ChatGLM-6B/issues/200