前言
从整体浅析Kafka集群结构、和Zookeeper之间的关系、长轮询机制、消息生产和消费以及顺序消费等。
名词解释
- Broker(Kafka服务)
- Controller(唯一充当控制器的Kafka服务)
- Topic(消息主题,一个主题包含多个)
- Partition(消息分区),Replica(分区副本),Leader(主分区),Follower(从分区)
- Metadata(元数据,集群结构、状态等信息)
- Offset(消息偏移量),Current-offset(消费进度/消费偏移量),Log-end-offset(分区最大消息偏移量)
- Producer(消息生产者,业务服务)
- Consumer(消息消费者,业务服务)
- Group(消费组,一个组包含多个消费者)
Kafka集群结构关系
Broker等于每一个Kafka服务,是一个JVM进程。
Topic是一个逻辑概念,生产和消费消息都需要指定Topic,不同业务的消息一般放在不同的Topic中。
一个Topic的消息可以按每条的粒度分片到不同的分区(Partition),分区分配在不同的Broker上,解决单机CPU和IO等性能瓶颈。
一个分区又分为一到多个副本(Replica),是一主(Leader)多从(Follower)的结构。主负责提供服务,从只负责同步和在主宕机的时候顶替主来实现高可用。
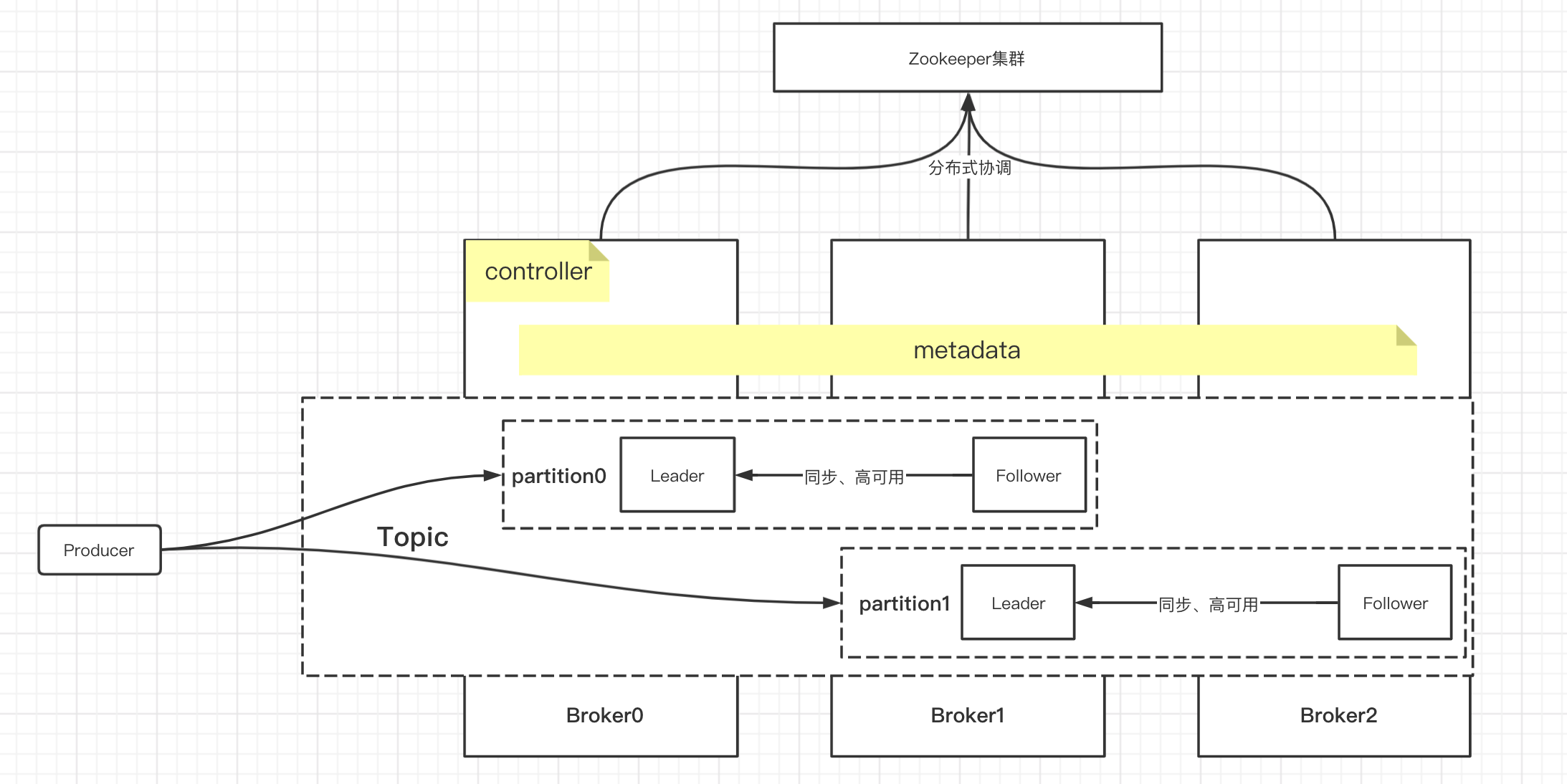
Kafka和Zookeeper
Kafka集群需要依赖Zookeeper作分布式协调,保存状态和实现选主。Kafka集群中会选出一个Broker来充当控制器(Controller),控制器负责管理分区和副本的状态以及执行管理任务,例如重新分配分区。最终这些数据保存在Zookeeper中称之为元数据(Metadata)。
Zookeeper高可靠性适合做分布式协调,但是不太适合高并发的访问和大量的IO交互,以前客户端读取元数据,维护消息偏移量(Offset)都需要经过Zookeeper。而新版本Kafka为了减轻Zookeeper的负担将很多请求转移到了Broker上,客户端可以通过Broker获取所有Broker的地址、维护消息偏移量、访问其他元数据、创建Topic、分区、副本等等。
高性能磁盘IO
Kafka消息最终是要保存到磁盘上的,最终顺序写入.log日志,这是它能够保证高性能的原因之一,磁盘的顺序读写效率远高于随机读写,减轻了磁盘寻址压力。另外还需要维护索引到.index和.timeindex来对.log进行检索。
消息生产和消费
生产者(Producer)生产消息指明归属的Topic推送给Broker,消息经过哈希取模算法分配到某一个分区(Partition),各个分区副本进行同步。
消费者(Consumer)指明Topic对其中消息进行消费,并且需要指明消费者归属的消费组(Group),消费组一般用来区分不同的业务线,不同消费组之间消费进度是隔离的。
消费者通过长轮询Broker批量拉取消息到本地,这样消费者可以按照自己的消费能力按需拉取消息,消费完后向Broke提交更新消费进度(Current-offset),一次拉取可能会拉到不同分区的消息,不同分区的消费进度分开维护。
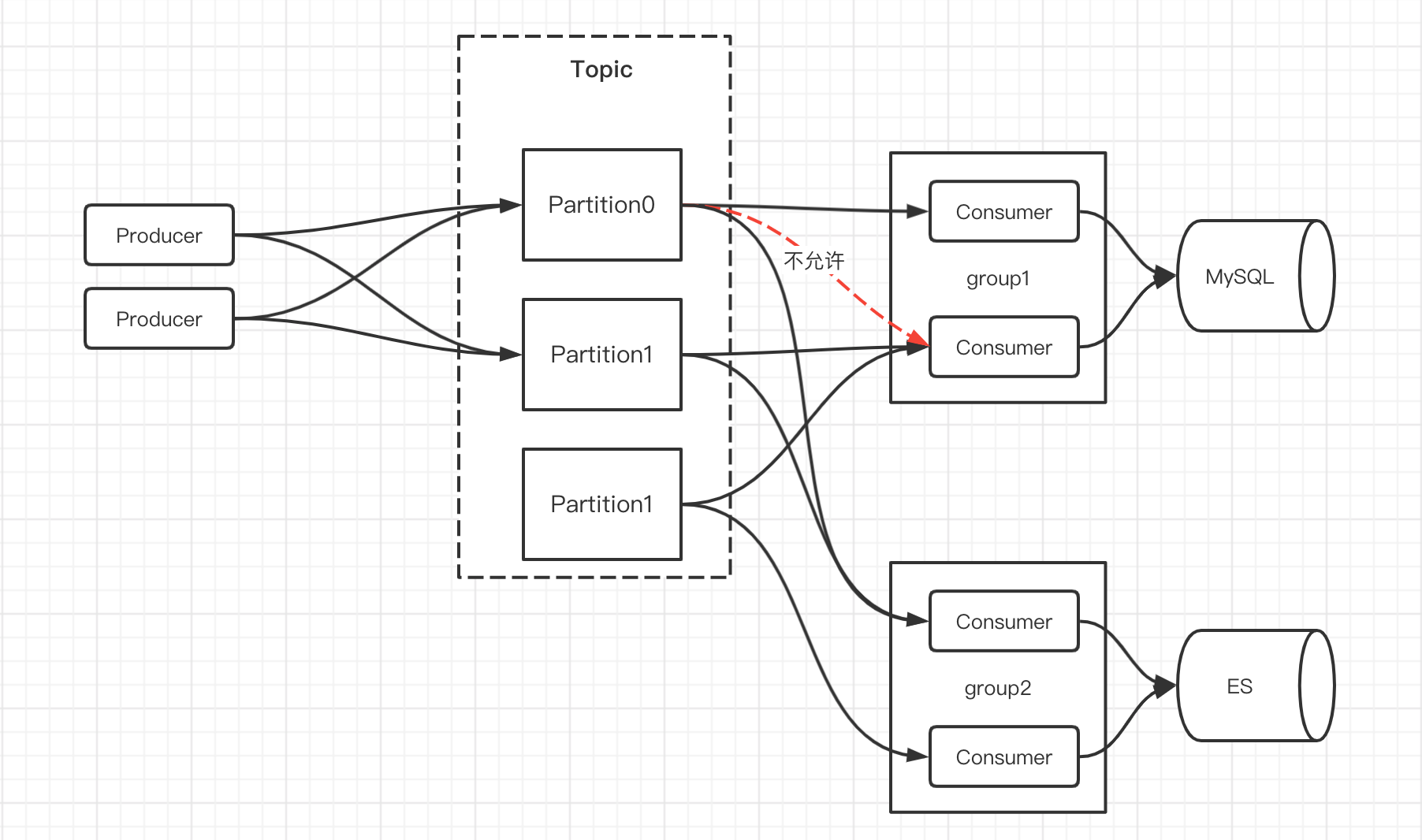
一条消息可以让多个消费组进行消费,但是在一个消费组中只能有一个消费者可以消费到这条消息。
在同一消费组中,一个分区只能由一个消费者消费,但是一个消费者可以消费多个分区的消息。假如两个消费进度不一样消费者消费同一分区,更新消费进度的时候就会产生混乱导致重复消费和消息丢失等问题。
消费进度提交方式
消费者(Consumer)可以手动或者自动提交消费进度(Current-offset)。
自动情况下,拉取完消息,程序经过配置的间隔时间后异步自动向Broker更新消费进度,这种方式性能较高但是容易产生重复消费和消息丢失问题。假如程序消费速度慢,还未消费完就自动提交了,此时宕机重启后消费不到当时未来得及消费的消息了,因为消费进度已经更新,产生了消息丢失问题。假如程序消费速度快,消费完还未到自动提交的时间宕机了,消费进度没更新,重启后又会重复消费到之前的消息,产生了重复消费问题。
手动提交则比较灵活,可以按条、分区、拉取的粒度提交消费进度。粒度越小,可靠性越高,但是由于提交频繁性能较低;粒度越大,可靠性越低,但是提交频率较低,多条数据还可以考虑并行执行,所以性能较高。
如何保证消息顺序消费
如果不需要保证消息顺序,分区可以任意横向扩展。
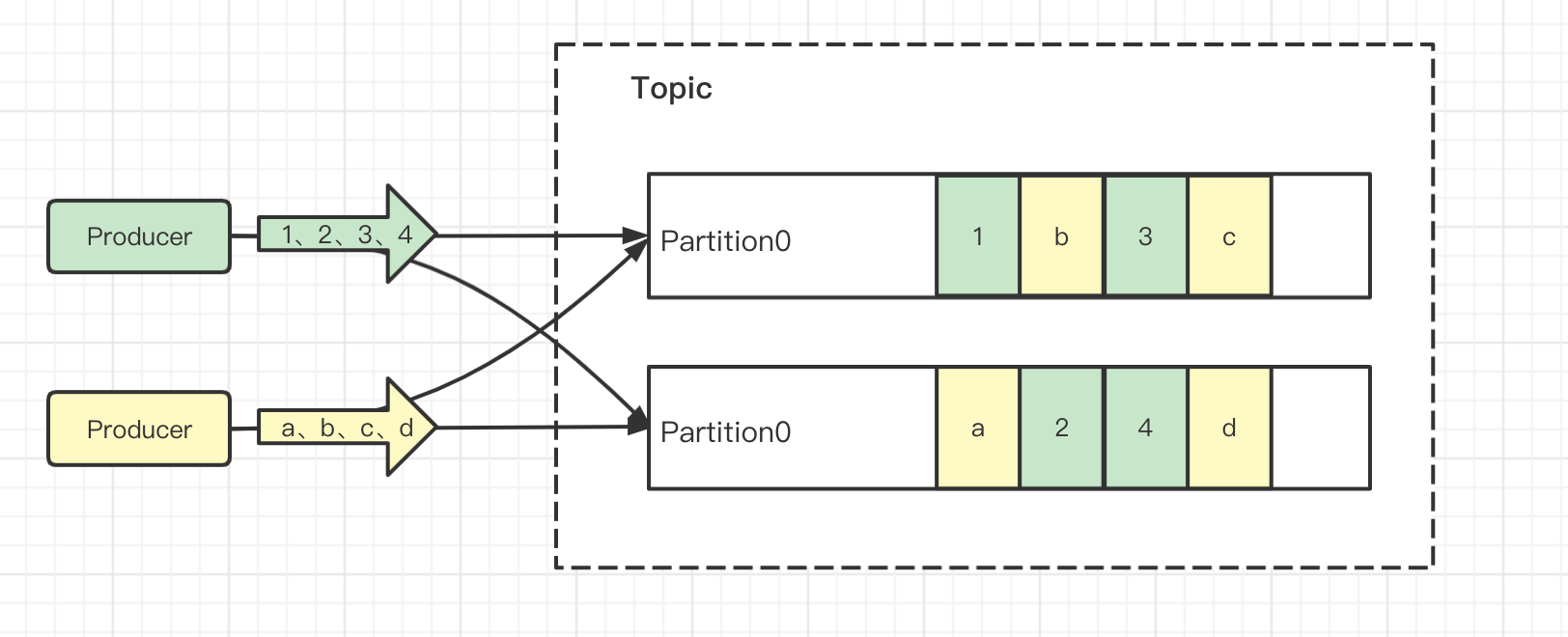
如果消息需要保证顺序,就得保证消息推送给Broker时是有序的,并且消息要指定同一消息键(Key),相同键的消息会被分配的同一个分区(Partition),Broker能保证同一分区的消息按接收的顺序保存。再由一个消费者(Consumer)消费这个分区的消息,并且消费的时候也要保证顺序。
不同键的消息可能会互相穿插保存在同一个分区,但是统一分区相同键的消息是保证顺序的。
什么是长轮询
常见获取消息方式有轮询、推送、和长轮询。
轮询是指消费者(Consumer)定时向消息队列(Message queue)获取消息。优点是可以按消费者自己的消费能力控制消费进度。缺点是轮询有时间间隔,消息获取不及时;没有消息时也会不停的空轮询,无用的建立、断开连接产生性能消耗。
推送是指消息队列主动向消费者推送消息。优点是能较及时让消费者收到消息。缺点是消费者消息能力是不一定的,消费不过来的时候会产生阻塞,不太好控制。为解决这问题,消费者需要告知消息队列消费进度,消息队列保存这个状态根据情况来推送消息。Apache ActiveMQ就是使用的这种。
长轮询是一种折中方案,定时轮询消息队列来获取消息。在没有消息的时候连接会保持,直到有消息返回,或者经过设置的超时时间后再断开重新轮询。这样可以根据能力按需消费,也可以避免空轮询问题。Kafka和借鉴Kafka开发的RocketMQ就是使用的这种。
标签:消费,分区,Broker,Kafka,消息,原理,解析,轮询 From: https://www.cnblogs.com/shuiyao3/p/17290652.html