标签:虚拟化 Bitfusion Orion 池化 CUDA Nvidia GPU
1 背景
Nvidia GPU得益于在深度学习领域强大的计算能力,使其在数据中心常年处于绝对的统治地位。尽管借助GPU虚拟化实现多任务混布,提高了GPU的利用率,缓解了长尾效应,但是GPU利用率的绝对值还是不高,长尾现象依然存在。
网卡池化、存储池化、内存池化、CPU池化等一系列相近基础设施领域的技术演进,让大家对GPU池化也产生了一些想法。面对依赖PCIe和NVLink实现小范围连接的GPU机器,人们迫切希望能跨TOR、跨机房甚至跨地域调用GPU,从而降低集群整体的GPU碎片率,GPU池化应运而生,而其中关键的技术难点在于实现远程GPU。
此外,GPU池化不仅可以结合GPU虚拟化实现GPU资源的极致共享,也可以突破CPU与GPU的配比极限,理论上可以实现任意配比。
2 远程GPU
在深度学习领域,Nvidia GPU的软件调用栈大致如下图所示,从上至下分别为:
-
User APP:业务层,如训练或推理任务等
-
Framework:框架层,如tensorflow、pytorch、paddle、megengine等
-
CUDA Runtime:CUDA Runtime及周边生态库,如cudart、cublas、cudnn、cufft、cusparse等
-
CUDA User Driver:用户态CUDA Driver,如cuda、nvml等
-
CUDA Kernel Driver:内核态CUDA Driver,参考官方开源代码,如nvidia.ko等
-
Nvidia GPU HW:GPU硬件
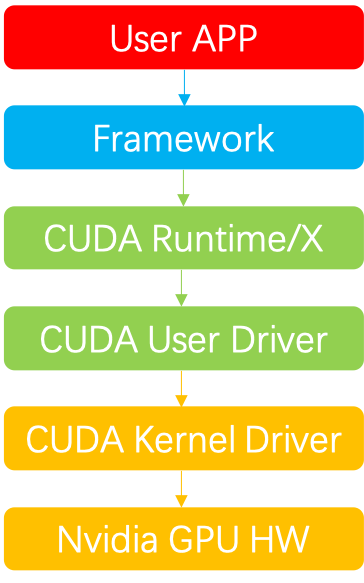
目前远程GPU主要通过DPU或者在CUDA Runtime/Driver层拦截API实现。
2.1 Fungible
Fungible通过DPU和PCI vSwitch经网络连接GPU,替代传统的PCIe直连方式,GPU连接数量也超过传统的8:1,达到了55:1。
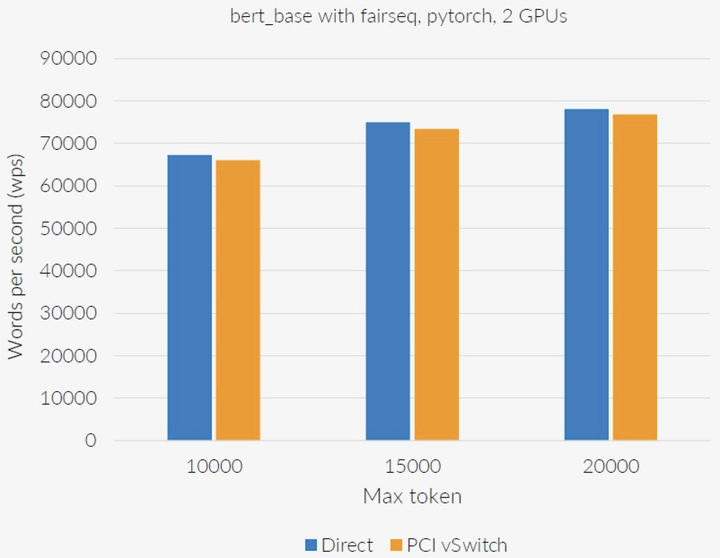
经过测试,连接2个GPU的DPU方案对性能的影响较小。在某些情况下,DPU解决方案的延迟更高,带宽也比PCIe低。如果将10个GPU连接到一个DPU上,那么物理带宽就会减少。
23年1月份,Fungible被微软收购,加入微软的数据中心基础设施工程团队,专注于提供多种DPU解决方案、网络创新和硬件系统改进。
西班牙Universitat Politecnica de Valencia并行架构组的一个开发项目,提供了一套远程GPU虚拟化解决方案,支持以透明的方式并发远程使用支持CUDA的设备。不仅可以部署在集群中,允许单个非MPI应用程序使用集群中的所有GPU,从而提高GPU利用率并降低总体成本,而且还可以在虚拟机中运行应用程序访问安装在远程物理机中的GPU。其最新的研究成果和计划都会放在官网,有兴趣的可以访问官网详细了解。
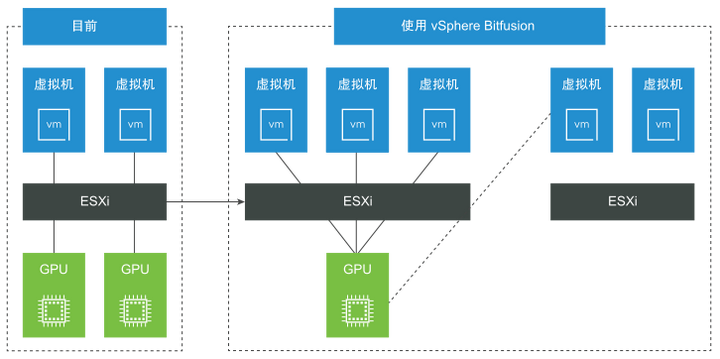
Bitfusion提供的GPU资源池的工作原理是在CUDA Driver层面上截获了所有的CUDA服务访问,然后把这些服务请求和数据通过网络传递给Bitfusion Server,在服务器这一端再把这些服务请求交给真正的CUDA Driver来处理。
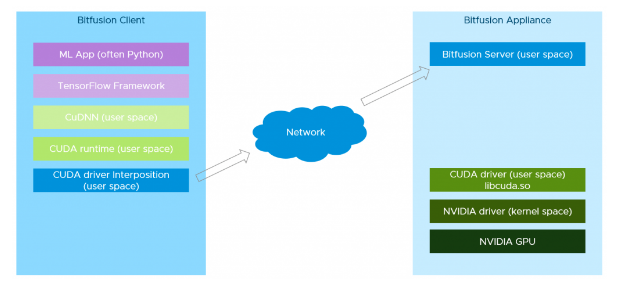
19年7月份,戴尔旗下的云计算公司VMware收购Bitfusion,之后这套方案被集成到vSphere平台中,主要分为两部分:
-
Bitfusion Server:把GPU安装在vSphere服务器上(要求vSphere 7以上版本),然后在上面运行Bitfusion Server,Bitfusion Server可以把物理GPU资源虚拟化,共享给多个用户使用。
-
Bitfusion Client:Bitfusion Client是运行在其他vSphere服务器上的Linux虚机(要求 vSphere 6.7 以上版本),机器学习工作负载运行在这些虚拟机上,Bitfusion会把它们对于GPU的服务请求通过网络传输给Bitfusion Server,计算完成后再返回结果。对于机器学习工作负载来说,远程GPU是完全透明的,它就像是在使用本地的GPU硬件。
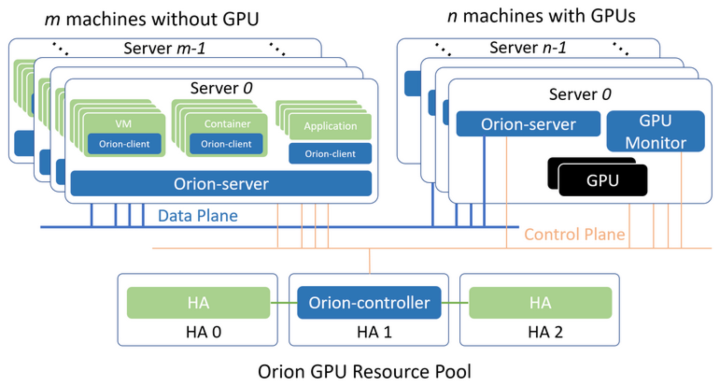
19年4月份,国内AI加速器虚拟化及资源池化服务商趋动科技成立,初创团队来自于Dell EMC中国研究院,主要为用户提供AI加速器虚拟化和资源池化软件及解决方案。其研发的Orion vGPU软件是一个为云或者数据中心的GPU提供资源池化和虚拟化能力的系统软件。通过高效的通讯机制,使得CUDA应用可以运行在云或者数据中心内任何一个物理机,容器或者虚拟机内无需挂载物理GPU,同时为这些应用程序提供在GPU资源池中的硬件算力。
OrionX主要通过拦截CUDA Runtime/Driver及其周边生态库的API实现,核心分为以下几个部分:
-
Orion Controller:负责整个GPU资源池的资源管理。其响应Orion Client的vGPU请求,并从GPU资源池中为Orion Client端的CUDA应用程序分配并返回Orion vGPU资源。
-
Orion Server:负责GPU资源化的后端服务程序,部署在每一个CPU以及GPU节点上,接管本机内的所有物理GPU。当Orion Client端应用程序运行时,通过Orion Controller的资源调度,建立和Orion Server的连接。Orion Server为其应用程序的所有CUDA调用提供一个隔离的运行环境以及真实GPU硬件算力。
-
Orion Client:模拟了NVidia CUDA的运行库环境,为CUDA程序提供了API接口兼容的全新实现。通过和Orion其他功能组件的配合,为CUDA应用程序虚拟化了一定数量的虚拟GPU(Orion vGPU)。使用CUDA动态链接库的CUDA应用程序可以通过操作系统环境设置,使得一个CUDA应用程序在运行时由操作系统负责链接到Orion Client提供的动态链接库上。由于Orion Client模拟了NVidia CUDA运行环境,因此CUDA应用程序可以透明无修改地直接运行在Orion vGPU之上。
3 其他
3.1 技术难点
由于Nvidia的闭源性,远程GPU存在不少的技术难点,比如Kernel Launch机制、Context机制、隐藏API等,同时工程上也存在一些难点,比如数以千计API拦截的开发和维护等,可参考
cuda hook开源代码。
3.2 GPU热迁移
GPU池化配合虚拟化可以更好地实现云服务的弹性伸缩,但在集群资源紧张或者碎片率较高时,弹性伸缩的成功率偏低,此时亟需GPU任务的热迁移技术,配合集群的统筹调度,提高云服务弹性伸缩的成功率。
标签:虚拟化,
Bitfusion,
Orion,
池化,
CUDA,
Nvidia,
GPU
From: https://www.cnblogs.com/bruceleely/p/17284095.html