前言 本文介绍了MIRNetV2,它的核心模块为MRB,它是一种多尺度特征提取、聚合模块。在多尺度方面,它通过下采样方式构建了三个尺度的特征;在特征聚合方面,它采用了SKNet一文的特征融合机制;在特征提取方面,它采用了一种全新的RCB模块。MIRNetV2的各方面性能都比MIRNetV1强!
本文转载自AIWalker
作者 | Happy
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。

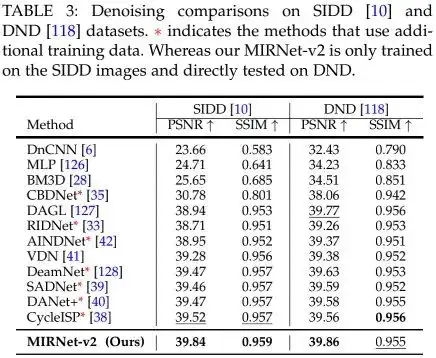
在正式介绍MIRNetV2之前,我们先来看一下它与MIRNetV1的性能对比,见下表。真可谓,MIRNetV2把MIRNetV1放在地上使劲的“摩擦”!关于MIRNet的介绍,可参见:https://zhuanlan.zhihu.com/p/261580767 。

1Method
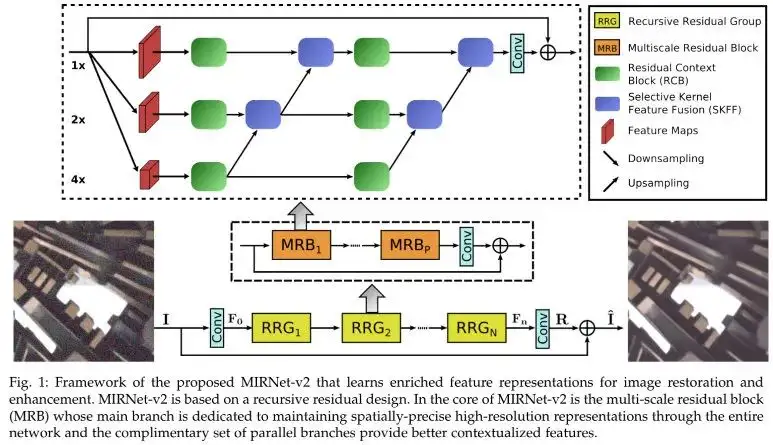
上图为MIRNetV2的网络架构示意图,它是在MIRNet的基础上演变而来(MIRNet的整体架构形态与RCAN非常相似,区别在于其核心Block)。
SKFF
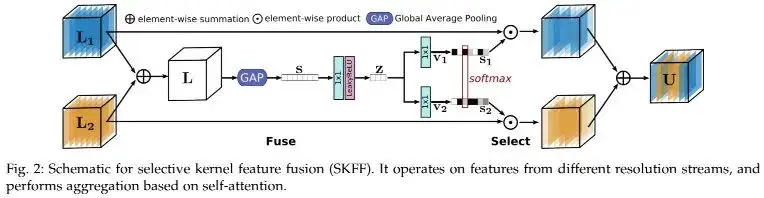
上图为MRB中用于特征聚合的SKFF模块结构示意图,关于该模块的介绍已经非常多了,也在不同结构设计中得到了广泛应用,该模块对于多尺度特征融合有非常优秀的效果,同时具有数据自适应性。关于SKFF直接看如下code可以看了,注:SKFF的输入为[feat1, feat2]。
class SKFF(nn.Module):
def __init__(self, in_channels, height=3,reduction=8,bias=False):
super(SKFF, self).__init__()
self.height = height
d = max(int(in_channels/reduction),4)
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv_du = nn.Sequential(nn.Conv2d(in_channels, d, 1, padding=0, bias=bias), nn.LeakyReLU(0.2))
self.fcs = nn.ModuleList([])
for i in range(self.height):
self.fcs.append(nn.Conv2d(d, in_channels, kernel_size=1, stride=1,bias=bias))
self.softmax = nn.Softmax(dim=1)
def forward(self, inp_feats):
batch_size = inp_feats[0].shape[0]
n_feats = inp_feats[0].shape[1]
inp_feats = torch.cat(inp_feats, dim=1)
inp_feats = inp_feats.view(batch_size, self.height, n_feats, inp_feats.shape[2], inp_feats.shape[3])
feats_U = torch.sum(inp_feats, dim=1)
feats_S = self.avg_pool(feats_U)
feats_Z = self.conv_du(feats_S)
attention_vectors = [fc(feats_Z) for fc in self.fcs]
attention_vectors = torch.cat(attention_vectors, dim=1)
attention_vectors = attention_vectors.view(batch_size, self.height, n_feats, 1, 1)
# stx()
attention_vectors = self.softmax(attention_vectors)
feats_V = torch.sum(inp_feats*attention_vectors, dim=1)
return feats_V
RCB
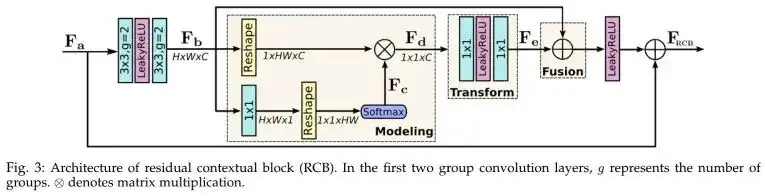
上图为MRB的核心模块RCB结构示意图,它是在ResBlock基础上演变而来。常规ResBlock的残差分支只包含两个卷积一个非线性激活;而RCB将ResBlock中卷积的groups参数设为,然后引入通道相关性建模(即上图中的Modeling)信息,将该信息进行变换后输入特征相融合。关于RCB,看一下下面Modeling的实现就差不多了。
class ContextBlock(nn.Module):
def __init__(self, n_feat, bias=False):
super(ContextBlock, self).__init__()
self.conv_mask = nn.Conv2d(n_feat, 1, kernel_size=1, bias=bias)
self.softmax = nn.Softmax(dim=2)
self.channel_add_conv = nn.Sequential(
nn.Conv2d(n_feat, n_feat, kernel_size=1, bias=bias),
nn.LeakyReLU(0.2),
nn.Conv2d(n_feat, n_feat, kernel_size=1, bias=bias)
)
def modeling(self, x):
batch, channel, height, width = x.size()
input_x = x
# [N, C, H * W]
input_x = input_x.view(batch, channel, height * width)
# [N, 1, C, H * W]
input_x = input_x.unsqueeze(1)
# [N, 1, H, W]
context_mask = self.conv_mask(x)
# [N, 1, H * W]
context_mask = context_mask.view(batch, 1, height * width)
# [N, 1, H * W]
context_mask = self.softmax(context_mask)
# [N, 1, H * W, 1]
context_mask = context_mask.unsqueeze(3)
# [N, 1, C, 1]
context = torch.matmul(input_x, context_mask)
# [N, C, 1, 1]
context = context.view(batch, channel, 1, 1)
return context
def forward(self, x):
# [N, C, 1, 1]
context = self.modeling(x)
# [N, C, 1, 1]
channel_add_term = self.channel_add_conv(context)
x = x + channel_add_term
return x
Training Regime
在训练方面,图像复原算法基本都采用随机裁剪的图像块进行模型训练。对于较大的图像块,CNN可以捕获更细粒度的细节并可以取得更优的性能,但会导致更长的训练时长;对于较小的图像块,尽管训练速度快,但会导致模型性能下降。
为达成训练效率与性能均衡,本文提出一种渐进式学习方案:网络先在小图像块上进行训练,在训练过程中阶段性的将图像块的尺寸调大。这种混合尺寸学习机制不仅可以加速训练,同时可以提升模型性能,可参照下表。

2Experiments

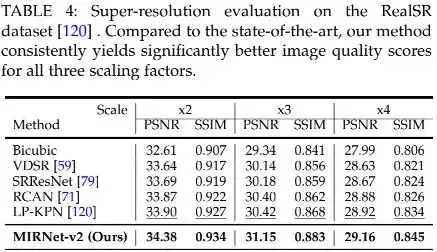

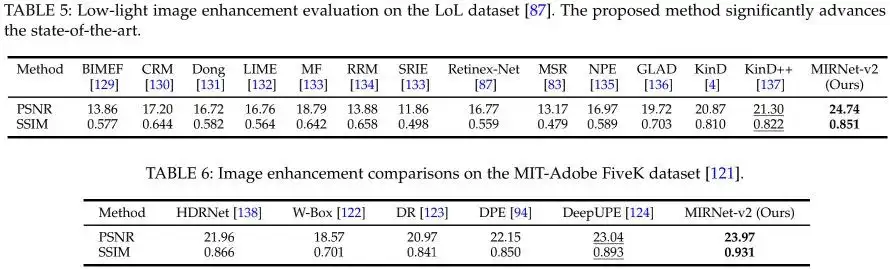


3MIRNetV1 vs MIRNetV2
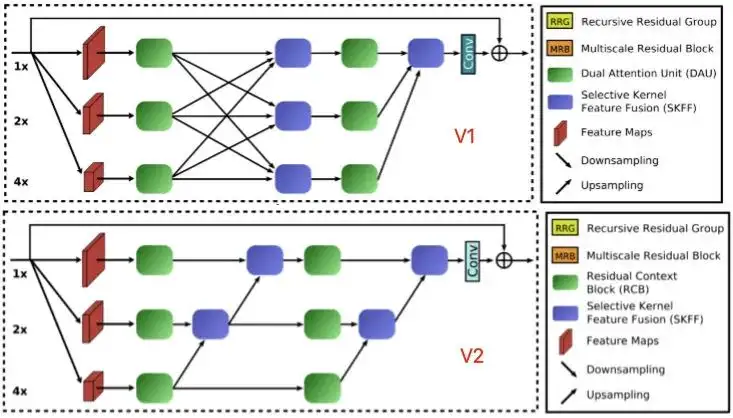
对于没有看过MIRNetV1的同学来说,直接看MIRNetV2的话,可能不知道MIRNetV2的改进点在哪里。在这里,我们对两者的差异进行简单的汇总(可参考上图),主要体现在两个方面:
- 模块方面:模块方面的差异可以参考上图。这里又有两个差异:(1) MRB的核心方面方面,MIRNet在ResBlock基础上引入了对偶注意力单元,MIRNetV2则引入了前面所提到的RCB单元;(2) 特征聚合方面,MIRNet对于每个尺度的特征都与其他两个尺寸的特征进行一次融合,而MIRNetV2则只进行了低分辨率特征向高分辨率特征的融合。事实上,在实现上,两者所使用的上采样和下采样也存在一些差异,MIRNetV1的实现更“臃肿”(多尺度),MIRNetV2的实现则更“简单”(插值+卷积)。
- 训练机制:MIRNetV1采用的是最基本的固定块尺寸方式进行训练,而MIRNetV2则采用了渐进式(伴随训练周期提升图像块尺寸)机制进行训练。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:444129970。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
AAAI 2023 | 一种通用的粗-细视觉Transformer加速方案
【免费送书活动】 全新轻量化模型 | 轻量化沙漏网络助力视觉感知涨点
目标检测、实例分割、旋转框样样精通!详解高性能检测算法 RTMDet
大卷积模型 + 大数据集 + 有监督训练!探寻ViT的前身:Big Transfer (BiT)
超快语义分割 | PP-LiteSeg集速度快、精度高、易部署等优点于一身,必会模型!!!
AAAI | Panini-Net | 基于GAN先验的退化感知特征插值人脸修
与SENet互补提升,华为诺亚提出自注意力新机制:Weight Excitation
最新FPN | CFPNet即插即用,助力检测涨点,YOLOX/YOLOv5均有效
消费级显卡的春天,GTX 3090 YOLOv5s单卡完整训练COCO数据集缩短11.35个小时
标签:更强,nn,self,bias,MIRNetV2,context,轻量,feats From: https://www.cnblogs.com/wxkang/p/17218069.html