前言 人体姿态估计(HPE)是计算机视觉中的一项经典任务,它主要通过识别人的关节的位置来表示人的方向。HPE可以用来理解和分析人类的几何和运动相关信息。Newell等人在Mask3D中提出的堆叠沙漏架构是第一个基于深度学习的HPE方法之一。
本文利用重复的自下而上和自上而下的处理,从不同的尺度上捕获信息,并引入中间监督,在每个阶段迭代细化预测。与当时最先进的方法相比,这导致了准确性的显著提高。
本文转载自集智书童
作者 | 小书童
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
本次联合中国水利水电出版社给公众号读者免费送书!参与方式见文末。


1、简介
HPE应该是一个实时的应用程序,因为它经常被用作另一个模块的前身。因此,在这种情况下,关注计算效率是至关重要的。在本研究中对堆叠的沙漏网络进行了架构和非架构修改,以获得一个既准确且计算效率高的模型。
在下文中对基线模型进行了简要描述。原始架构由多个堆叠的沙漏单元组成,每个沙漏单元由4个下采样和上采样级别组成。在每一级,通过残差块和最大池化操作实现下采样,而通过残差块以及朴素最近邻插值实现上采样。该过程确保模型捕获局部和全局信息,这对于连贯地了解全身以获得准确的最终姿态估计非常重要。在每个最大池化操作之后,网络分支以预池化分辨率通过另一个残差块应用更多卷积,其结果作为跳过连接添加到沙漏后半部分的相应上采样特征图。模型的输出是每个关节的热图,该热图对每个像素处关节存在的概率进行建模。预测每个沙漏后的中间热图,并对其应用损失。
此外,这些预测被投影到更多的通道,并作为后续沙漏的输入,以及当前沙漏的输入及其特征图输出。
源代码:https://github.com/jameelhassan/PoseEstimation
2、设计选择
2.1 深度可分离的卷积
深度可分离卷积取代传统卷积,减少卷积运算的参数数量。这是通过使用空间卷积单独分割卷积,然后通过点态卷积聚合通道信息来实现的,如图1所示。
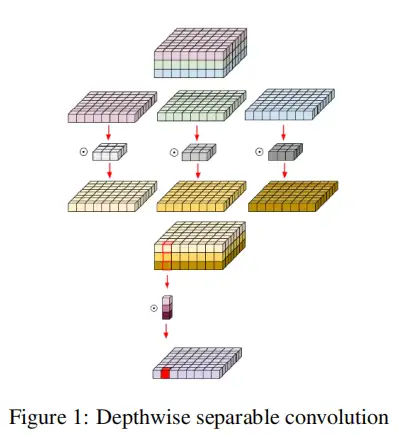
2.2 空洞卷积
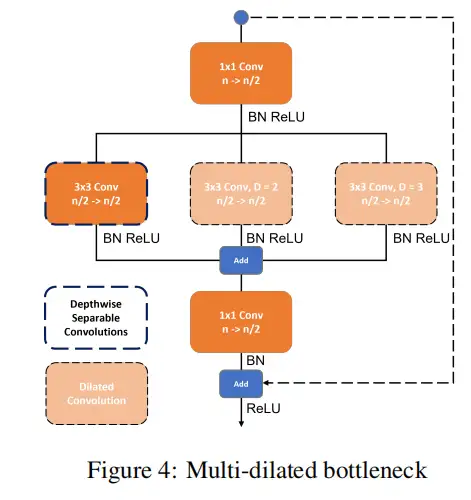
公式1中描述的空洞卷积是常规卷积运算的一种变体,其具有指数增加感受野而不损失分辨率或覆盖范围的能力,如池化运算的情况。
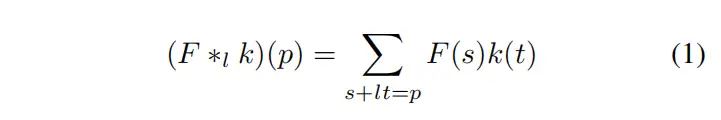
其中k是离散滤波器,是空洞因子,是空洞卷积运算。正则卷积对应于一维卷积。扩展卷积对计算复杂性几乎没有影响。
2.3 Ghost Bottleneck
Ghost 提出的Ghost Bottleneck也通过以不同的方式分割卷积,降低了卷积操作的计算复杂度。为了产生固定数量的通道,Ghost Bottleneck使用常规卷积输出一小部分通道,其余的则通过更简单的线性操作产生,如图2所示。这些通道通过连接和卷积输出所需的通道数量。
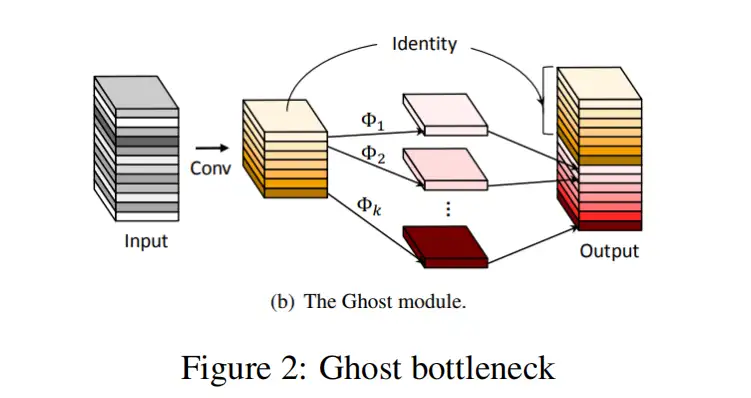
2.4 DiCE Bottleneck
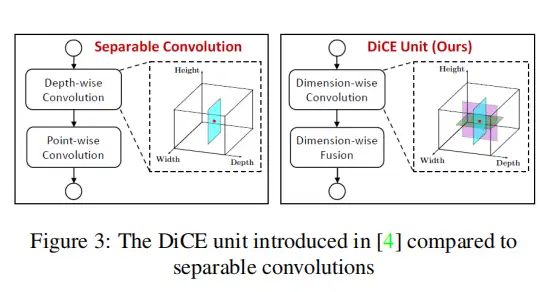
Dimension-wise Convolutions for Effificient Networks(DiCE)单元是由Mehta等人在DiceNet中提出的一个卷积单元,它融合了维向卷积之后和维向融合。卷积操作应用于三个输入维度(宽度、高度和深度)。为了沿着每个维度组合编码的信息,使用了一个有效的融合单元来组合这些表示。因此,直径单元可以有效地沿着空间尺寸和通道尺寸捕获信息。
2.5 Shuffle Bottleneck
shuffle单元首次在Shufflflenet中提出,它使用点卷积和通道Shuffle来提高计算效率和保持准确性。
2.6 Perceptual Loss
感知损失被用来比较带有微小差异的相似图像。在这里使用它作为两幅图像之间的特征水平均方误差(MSE)损失,它计算一个高级特征图的损失,而不是原始图像空间。
这里的假设是,如果第一个沙漏在高特征水平上“感知”第二个沙漏“感知”的东西,网络的整体性能将会得到改善。总损失,如式2所示,包括感知损失和预测损失中权重较高的原始预测损失。
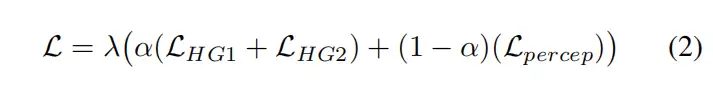
2.7 Residual connections
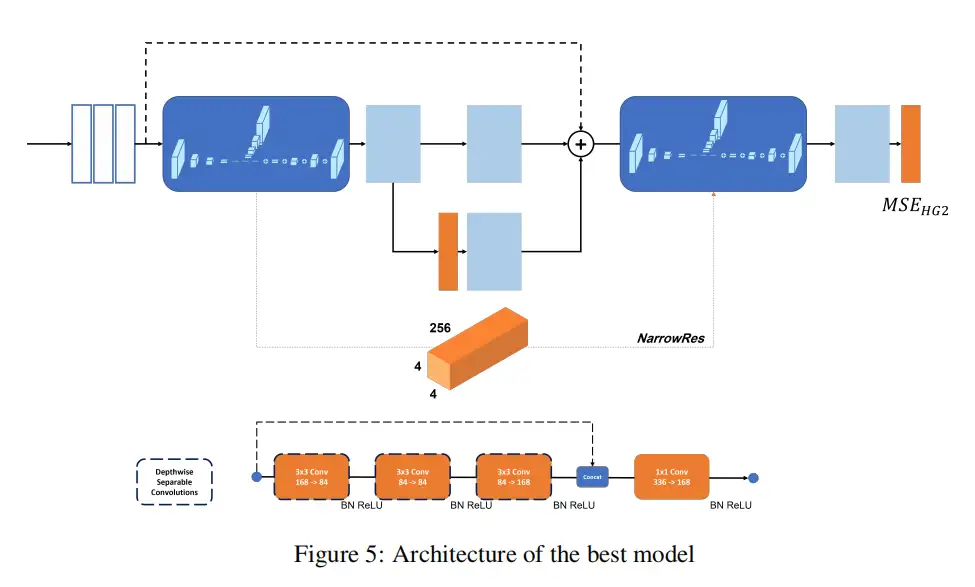
作者还用带有Concat的残差连接替换带有add的残差连接操作,然后进行逐点卷积,以获得所需数量的通道,称为「ResConcat」。还包括从沙漏最窄的特征图(颈部)到下一个沙漏颈部的残差连接,称为「NarrowRes」。
3、实验
3.1 Alternative bottlenecks
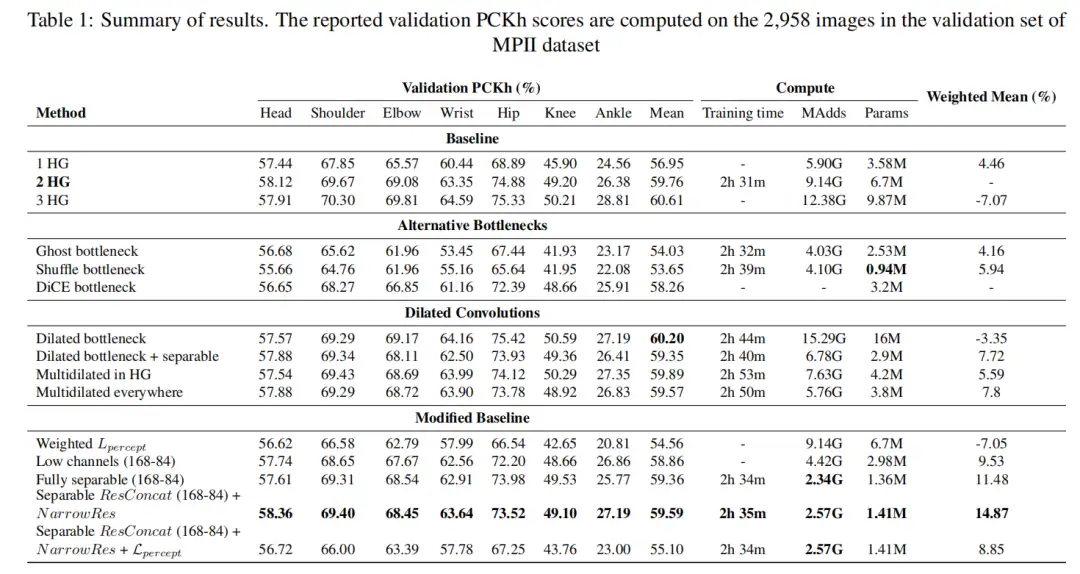
4、参考
[1].To Perceive or Not to Perceive: Lightweight Stacked Hourglass Network.
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:444129970。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
超快语义分割 | PP-LiteSeg集速度快、精度高、易部署等优点于一身,必会模型!!!
AAAI | Panini-Net | 基于GAN先验的退化感知特征插值人脸修
与SENet互补提升,华为诺亚提出自注意力新机制:Weight Excitation
最新FPN | CFPNet即插即用,助力检测涨点,YOLOX/YOLOv5均有效
消费级显卡的春天,GTX 3090 YOLOv5s单卡完整训练COCO数据集缩短11.35个小时
原来Transformer就是一种图神经网络,这个概念你清楚吗?
TensorFlow 真的要被 PyTorch 比下去了吗?
标签:涨点,沙漏,卷积,模型,残差,轻量化,视觉,CV From: https://www.cnblogs.com/wxkang/p/17212375.html