服务降级&熔断&限流
一、高并发&高可用
其实我们讲过所有的Spring Cloud知识,都为了解决两个问题:一个是高并发,一个是高可用。解决高并发&高可用问题的方法有很多,比如:
- 从应用层面:一个好汉三个帮,一个服务实例无法完成的事情,启动多个实例来完成,请求分流负载均衡。
- 从IO模型层面:越来越多的服务框架使用多路选择的异步IO模型,代替阻塞IO模型。
- 从架构层面:主从互备、读写分离等等
- 从算法层面:提高单位请求的运行效率,从而提高并发服务能力
- ……
但是无论你怎么升级硬件、改善架构、改善算法,永远都会有上限,也永远。服务能力就是会存在某一时间段内无法达到高可用的要求,甚至崩溃。
二、服务雪崩
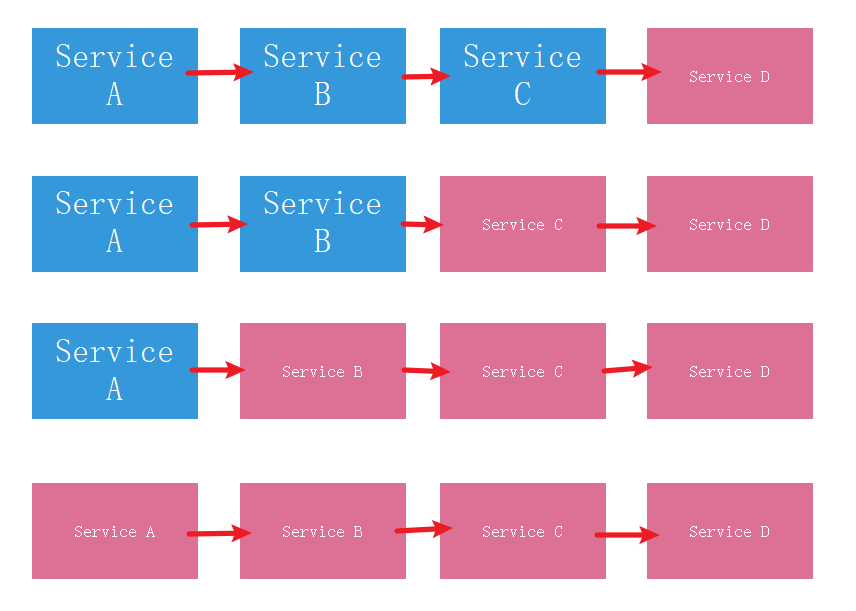
在分布式服务的系统内,很多的用户请求在系统内部都是存在级联式远程调用的。如下图所示:一次请求先后经过Service A、B、C、D,如果此时服务D发生异常,长时间无法响应或者根本不响应,将导致Service C服务调用无法正常响应,进而导致Service B和Service A的响应也出现问题。这种因为服务调用链中某一个服务不可达或超时等异常情况,导致其上游的服务也出现响应异常或者崩溃。当这种情况在高并发环境下就会导致整个系统响应超时、资源等待耗尽,这种现象就是“服务雪崩”。
当一个服务Service1需要在其方法实现中,调用多个服务提供者时,其中一个服务不可达或者超时的的情况发生,也会导致请求失败。在高并发的环境下,这个问题会更加凸显,也会导致整个微服务系统资源出现等待、无法释放的情况。从而产生服务雪崩。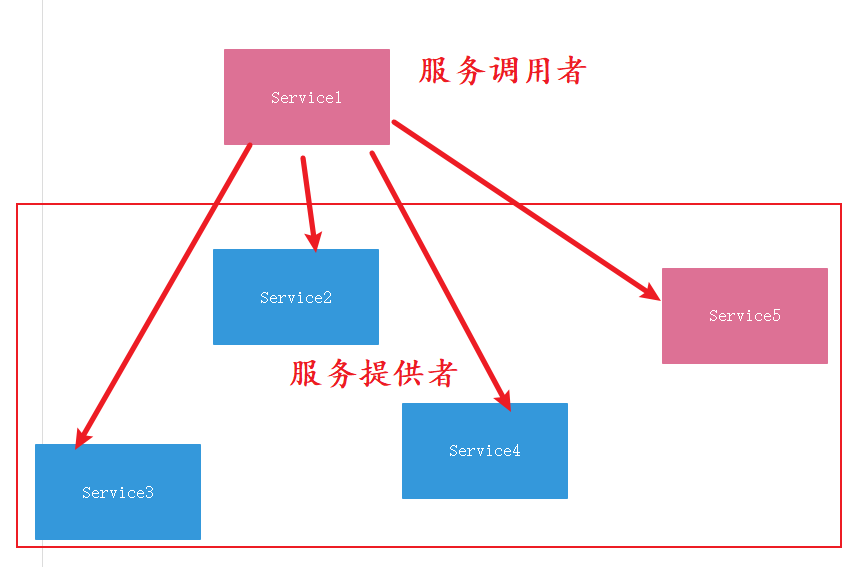
服务重试机制也会产生服务雪崩
很多朋友在遇到上面的问题时,很自然的想到我们之前为大家讲过的服务请求重试机制(Ribbon和OpenFeign都可以实现服务的请求失败重试)。
- 服务请求重试机制在很大程度上解决了由于网络瞬时不可达的问题,导致服务请求失败的问题。但是在很多的情况下:造成“服务雪崩”的元凶正是“服务重试”机制。
- 某个服务本来就已经出现问题了,造成资源占用无法释放、请求延时等问题。这时在请求失败之后又不断的发送重试请求,在原本就无法释放的资源基础上继续膨胀式占用,导致整个系统资源耗尽。导致服务雪崩。
- 那么是不是我们就应该将“服务重试”配置关闭掉呢?当然也不是,你不能因为马路上发生了车祸,就不让所有人开车。
三、如何解决雪崩的问题之一:服务熔断
理解“熔断”这个词的由来,可以帮助我们跟好的理解“熔断”在微服务体系应用的意义。
- 熔断机制的英文是circuit breaker mechanism,其中circuit breaker在电工学里就是断路器的意思。当电路中出现短路时,断路器会立即断开电路,保护电路负载的安全。
- 后来熔断机制被引入股票交易。最早起源于美国,1987年10月19日,纽约股票市场爆发了史上最大的一次崩盘事件,道琼斯工业指数一天之内重挫508.32点,跌幅达22.6%,由于没有熔断机制和涨跌幅限制,许多百万富翁一夜之间沦为贫民,这一天也被美国金融界称为“黑色星期一”。2020年(今年)由于新冠疫情的影响,美国股市多次触发熔断机制,在一段时间内暂停交易,进而对整个市场起到一定的保护作用。
服务熔断:指的是在服务提供者的错误率达到一定的比例之后, 断路器就会熔断一段时间,不再去请求服务提供者,从而避免上游服务被拖垮,进而达到保护整体系统可用性的目的。
熔断恢复:熔断时间过了以后再去尝试请求服务提供者,一旦服务提供者的服务能力恢复,请求将继续可以调用服务提供者,此过程完全不需认为参与。
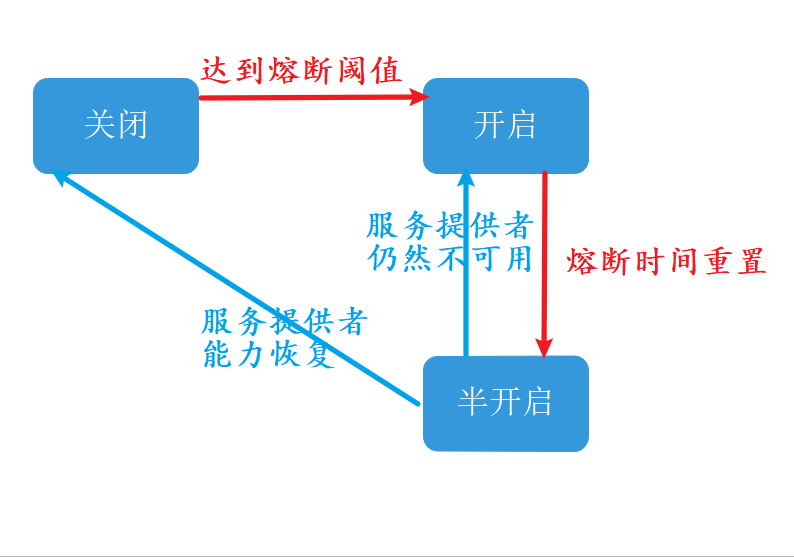
上图是“断路器”的状态转换图
- 断路器默认处于“关闭”状态,当服务提供者的错误率到达阈值,就会触发断路器“开启”。
- 断路器开启后进入熔断时间,到达熔断时间终点后重置熔断时间,进入“半开启”状态
- 在半开启状态下,如果服务提供者的服务能力恢复,则断路器关闭熔断状态。进而进入正常的服务状态。
- 在半开启状态下,如果服务提供者的服务能力未能恢复,则断路器再次触发服务熔断,进入熔断时间。
四、如何解决雪崩的问题之二:服务降级
通过上面的讲解,相信大家已经知道了服务熔断的含义及意义是什么。但是明显遗留了一个问题:服务熔断之后就不在去请求服务调用者原本的方法,那该去请求谁?总不能没有响应吧!这就需要使用到“服务降级”机制了。
白话说服务降级:服务降级是一种兜底的服务策略,体现了一种“实在不行就怎么这么样”的思想。想去北京买不到飞机票,实在不行就开车去吧;感冒了想去看病挂不上号,实在不行就先回家吃点药睡一觉吧;实在不行之后的处理方法,被称为fallback方法。
4.1.在服务调用端进行服务降级
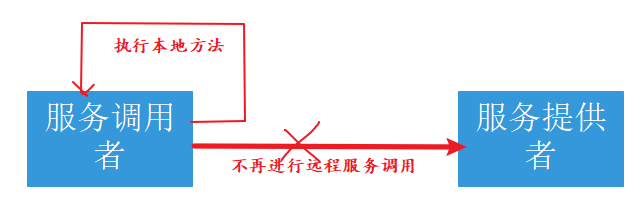
当服务提供者故障触发调用者服务的熔断机制,服务调用者就不再调用远程服务方法,而是调用本地的fallback方法。此时你需要预先提供一个处理方法,作为服务降级之后的执行方法,fallback返回值一般是设置的默认值或者来自缓存。
4.2.在服务提供端进行服务降级
除了可以在服务调用端实现服务降级,还可以在服务提供端实现服务降级。实际上在大型的微服务系统中,服务提供者和服务消费者并没有严格的区分,很多的服务既是提供者,也是消费者。
服务提供者原本的处理请求方法是AMethod(如运行时异常),已经不能响应请求,实在不行了就去执行预先定义好的fallback方法。fallback返回值一般是设置的默认值或者来自缓存。
当然,除了服务熔断会触发服务降级和程序运行时异常,还有其他几种异常也可以触发服务降级
- 响应超时
- 达到服务限流标准
- hystrix线程池或信号量爆满
五、服务限流
服务限流:通过对并发访问/请求进行限速或者一个时间窗口内的请求数量进行限制来保护系统,一旦达到限制速率则可以拒绝服务。拒绝服务之后,可以有如下的处理方式:
- 定向到错误页或告知资源没有了
- 排队或等待(比如秒杀、评论、下单)、
- 降级(返回默认数据或缓存数据)