
介绍
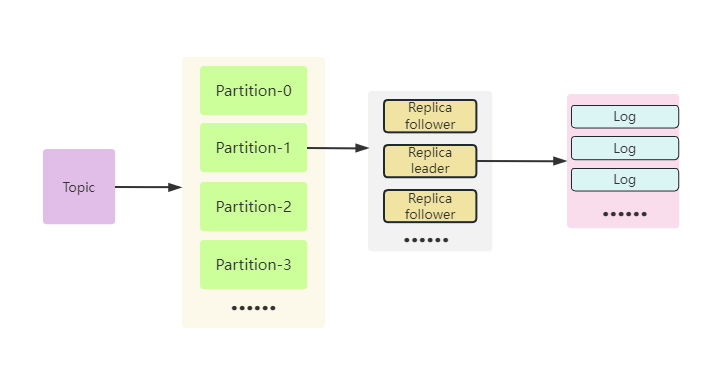
今天分享一下kafka的主题(topic),分区(partition)和副本(replication),主题是Kafka中很重要的部分,消息的生产和消费都要以主题为基础,一个主题可以对应多个分区,一个分区属于某个主题,一个分区又可以对应多个副本,副本分为leader和follower。
副本的作用是保证数据的高可用,一个副本在一个broker节点上,broker就是一个台机器或者一个kafka实例,当某个副本出现故障后,还可以使用其他副本的数据,如果只有一个副本,那么就无法保证高可用。
主题,分区实际上只是逻辑概念,真正消息存储的地方是副本的日志文件上,所以主题分区的作用是在逻辑上更加规范的管理日志文件。
主题,分区,副本关系如图所示:
创建主题分区
可以使用kafka-topics.sh创建topic,也可以使用Kafka AdminClient创建,当我们往Kafka发送消息的时候,如果指定的topic不存在,那么就会创建一个分区数为1的topic,不过这样做并不合适,我们应该规划好主题的分区,副本,然后在创建topic,这样对管理topic更加好。
kafka broker端默认设置了allow.auto.create.topics=true,所以会自动创建topic,为了更加规范和合理管理topic,我们可以将其设置为false,当然,一般情况下中我们肯定会进行手动创建topic,但是以防不确定因素,将其设置为false更保险一些。
使用kafka-topics.sh创建主题
bin/kafka-topics.sh --create --bootstrap-server 127.0.0.1:9092 --replication-factor 1 --partitions 2 --topic pig
使用Kafka AdminClient
创建topic名字为pig,分区数为1,副本数为1的分区。
Properties properties = new Properties();
properties.setProperty(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, "127.0.0.1:9092");
AdminClient adminClient = AdminClient.create(properties);
//创建topic
NewTopic newTopic = new NewTopic("pig", 4, (short) 2);
CreateTopicsResult result = adminClient.createTopics(Collections.singleton(newTopic));
需要注意的是,如果使用的是单机kafka,所以只有一个broker,如果副本设置大于1,那么就会抛出异常,因为一个副本对应一个broker。
创建了主题分区后,会在配置我们配置的日志目录(log.dirs)下生成对应的分区副本文件夹。
分区,副本详解
上面创建了分区数为4,副本为2的topic,使用命令 bin/kafka-topics.sh --describe --topic musk --bootstrap-server 127.0.0.1:9092查看分区情况。
如下名为musk的topic,分区数(PartitionCount)为4,副本数(ReplicationFactor)为2,有三个broker,kafka会将副本合理的划分到不同的机器上。

里面的数字0,1,2代表broker的唯一标识,因为在配置kafka集群的时候,三台机器的broker.id分别为0,1,2。
可知分区0的副本Leader在机器2上,副本follower在机器1上面,机器0上不存在分区0的副本,分区1的副本Leader在机器1上,副本follower在机器0上面,机器2上不存在分区1的副本,分区2和分区3以此类推。
从上面可以看出kafka要创建4个分区,每个分区对应两个副本,所以就存在8个副本,8个副本要平均分配到3台机器上上,所以就按照
3:3:2的比例分配副本,是按照平均分配的方式进行分配的。
下面我们创建分区数为4,副本为3的分区,如图所示。

可以看出,副本平均分配到了0,1,2三台机器上,每个分区有3个副本,所以4个分区有一共有12个副本。
可以看出是4个分区,每个分区3个副本,所以就有12个副本,12个副本分配到3台机器上面,所以比例是4:4:4。
AR,ISR,OSR
AR 集合(Assigned Replica set):AR 集合是指已经被分配到的分区副本集合。在 Kafka 集群中,每个分区都有若干个副本,其中一个是 leader 副本,负责处理读写请求,其他的是 follower 副本,用于备份数据和提高可用性。AR 集合就是所有被分配到的副本的集合,包括 leader 和 follower 副本。
ISR 集合(In-Sync Replica set):ISR 集合是指当前处于同步状态的副本集合。ISR 集合是 AR 集合的子集,即 ISR 集合中的副本与 leader 副本保持同步。如果一个 follower 副本与 leader 副本失去同步,那么它将从 ISR 集合中移除。
OSR 集合(Out-of-Sync Replica set):OSR 集合是指当前处于不同步状态的副本集合。OSR 集合是 AR 集合的另一个子集,即 OSR 集合中的副本与 leader 副本失去同步。这些副本可能正在追赶 leader,或者发生了某些错误导致与 leader 失去同步。在某些情况下,如果 ISR 集合缩小到了一个不可接受的程度,就需要将 OSR 集合中的副本加入 ISR 集合中,以保证可用性。
今天的分享就到这里,感谢你的观看,我们下期见!