2022年《知识图谱发展报告》是中国中文信息学会语言与知识计算专委会发布的报告,算是国内最权威的关于知识图谱领域的最全和最新进展了。包括知识表示与建模、知识表示学习、 实体抽取、实体关系抽取、事件知识获取、知识融合、知识推理、知识图谱的存储和查询、通用和领域知识资源、知识图谱质量评估与管理、基于知识的问答与对话、基于知识的搜索与推荐、知识图谱交叉前沿,共计13章。2022年《知识图谱发展报告》下载链接:https://url39.ctfile.com/f/2501739-668230065-8345de?p=2096 (访问密码: 2096)

第1章:知识表示与建模
知识表示:什么是知识表示(Knowledge Representation, KR)呢?主要是将现实世界中的各类知识表达成计算机可存储和可计算的结构,使得计算机可以无障碍地理解所存储的知识。
本体描述语言:XML、RDF、RDFS和OWL都是本体描述语言,RDFS(RDF Schema)主要是在RDF(Resource Description Framework)的基础上添加了Scheme。OWL(Web Ontology Language)是W3C推出的网络本体语言,提供了3种子语言:OWL Lite、OWL DL和OWL Full。OWL Lite主要面向需要构建分类层次和约束简单的本体用户;OWL DL主要提供给需要构建最强表达能力且保持计算的完整性和可判性的用户;OWL Full主要提供给追求最强表达能力和完全自由的RDF语法的使用者。
本体建模工具:本体建模的工具很多,但主要就是Protégé了,它可以用于概念建模、实体编辑、模型处理以及模型交换等,通知支持用户界面和OWL语言两种方式进行本体建模工作。
第2章:知识表示学习
知识表示学习:表示学习旨在将研究对象的语义信息表示为稠密低维实值向量。知识表示学习,则是面向知识图谱中的实体和关系进行表示学习。
1.开源工具
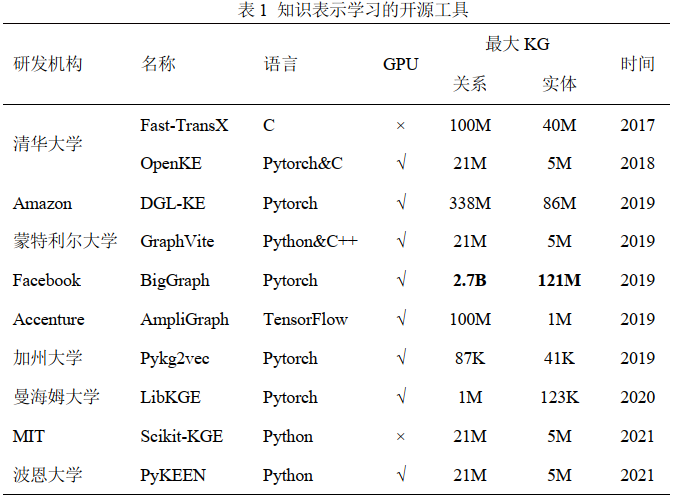
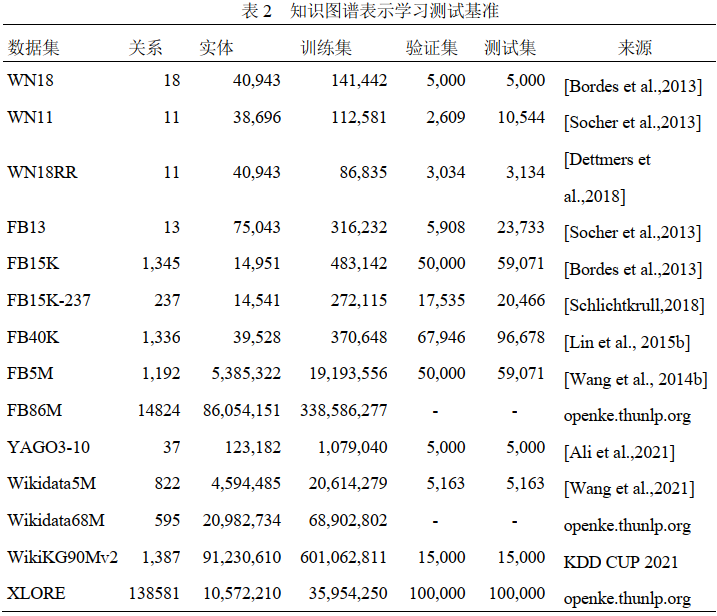
2.测试基准
第3章:实体抽取
实体抽取是知识图谱基础工作,非常重要,但是在工程上也很难做好。
第4章:实体关系抽取
实体关系抽取是知识图谱基础工作,非常重要,但是在工程上也很难做好。
第5章:事件知识获取
根据美国国家标准技术研究所组织ACE(Automatic Content Extraction)的定义,事件由事件触发词(Trigger)和描述事件结构的元素(Argument)构成,事件抽取任务主要包括以下两个步骤:
(1)事件类型识别:触发词是能够触动事件发生的词,是决定事件类型的最重要特征词。一般情况下,事件类型识别任务需要预先给定待抽取的事件类型。对于每一个检测到的事件还需要给其一个统一的标签以标识出它的事件类型。ACE2005/2007定义了8种事件类别以及33种子类别。
(2)事件元素识别:事件的元素是指事件的参与者,ACE为每种类型的事件制定了模板,模板的每个槽值对应着事件的元素。
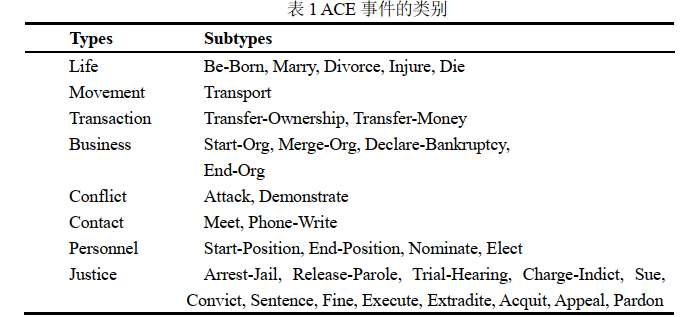
说明:只能说事件抽取应该比实体抽取和实体关系抽取更难吧。
第6章:知识融合
1.知识融合及研究内容
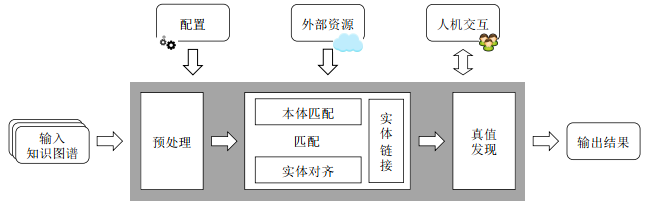
知识融合旨在将不同知识图谱融合为一个统一、一致、简洁的形式,为使用不同知识图谱的应用间的交互建立互操作性。知识融合常见的研究内容包括:本体匹配(也称为本体映射)、实体对齐(也称为实例匹配、实体消解)、真值发现(也称为真值推断)以及实体链接等,面临的核心挑战主要包括大规模、异构性、低资源等问题。
2.知识融合常见流程
第7章:知识推理
知识图谱推理:知识图谱推理指的是从给定知识图谱推导出新知识或者检测知识图谱的逻辑冲突。它的核心技术手段主要可分为两大类,即演绎系列,比如基于描述逻辑语言、逻辑规则的符号推理;归纳系列,比如基于嵌入表示学习、规则学习的统计推理。
基于符号的推理技术:被广泛用于生物医学中术语定义和概念分类、电商数据的不一致检测和查询重写等应用,有助于消除知识图谱中的噪声。
基于统计的推理技术:对知识图谱进行补全,有效地缓解知识图谱中存在的不完备问题。近期研究表明,两类技术的相互融合可以有效地提升知识图谱推理方法的鲁棒性、可迁移性、可解释性、可应用性等,进一步支持智能问答等图谱应用。
第8章:知识图谱的存储和查询
主要是掌握RDF和SPARQL,以及图数据库Neo4j,这样基本上就满足使用了。
第9章:通用和领域知识资源
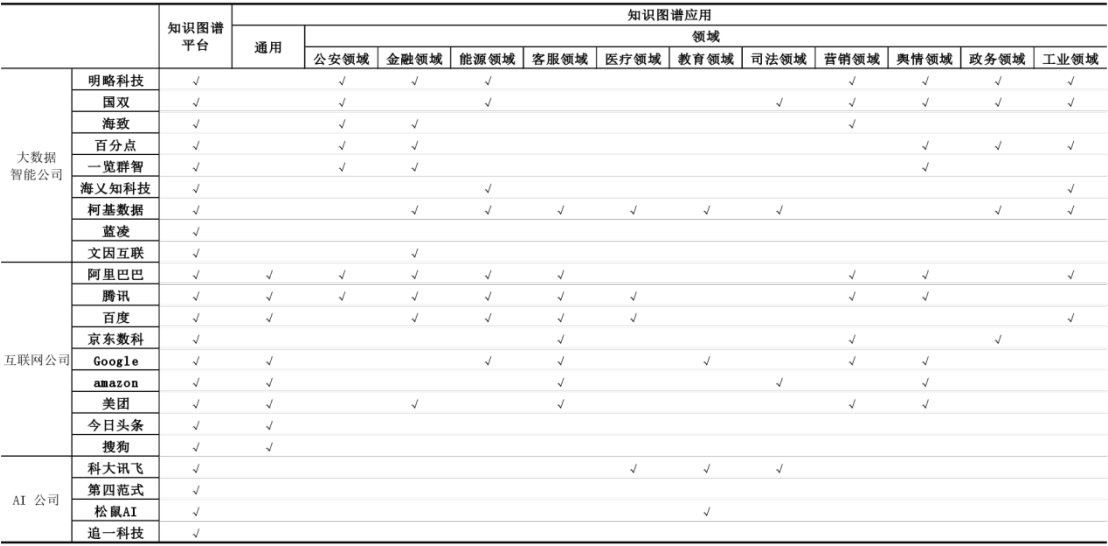
通用知识资源就是不分领域,而领域知识资源就是垂直领域。这里重点推荐下OpenKG,它是一个面向中文域开放的知识图谱社区项目,其主要目的是促进以中文为核心的知识图谱数据的开放、互联与众包,以及知识图谱工具、算法和平台的开源开放与互联,并且OpenKG聚集了大量开放的中文知识图谱数据、工具及文献。
1.国外知识图谱平台

2.国内知识图谱平台

3.知识图谱行业应用
第10章:知识图谱质量评估与管理
1.知识图谱质量管理对象
知识图谱中的质量的考察对象主要是概念、实体、属性这三类个体知识对象,以及概念之间的关系、概念与实体之间的关系、实体之间的关系等三类关系知识对象。
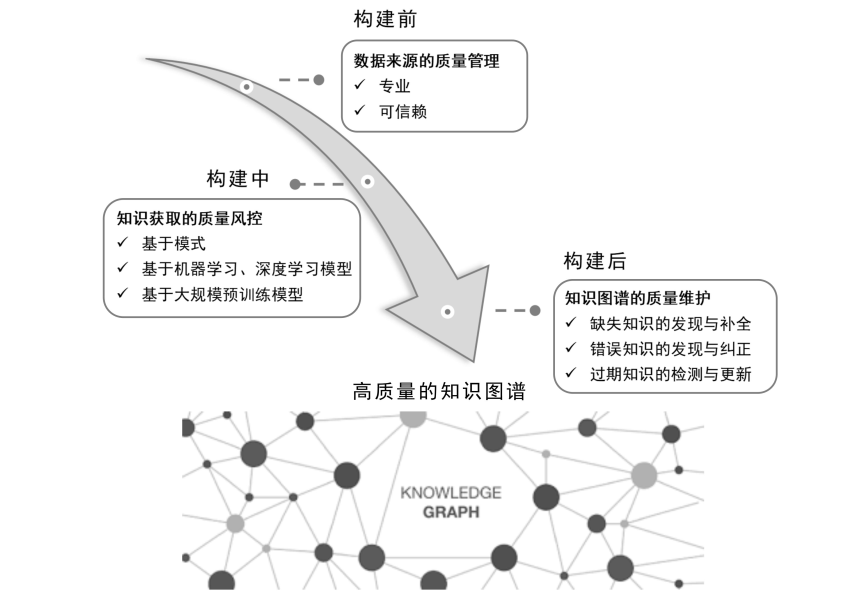
2.知识图谱质量管理生命周期
知识图谱的质量管理任务可以分为知识图谱构建前、中、后三个阶段实施。构建前的质量管理主要在于对数据来源的质量管理,即对于获取知识的数据源头做质量评估与管理;构建中的质量管理主要是知识获取手段和知识融合阶段的质量管理;构建后的质量管理指的是在知识图谱完成初步构建后,对知识图谱的质量进行进一步的完善与常规维护。例如,补全缺失的知识,发现并纠正错误知识,发现并更新过期知识等。
第11章:基于知识的问答与对话
问答系统:指让计算机自动回答用户所提出的问题,是信息服务的一种高级形式。不同于现有的搜索引擎,问答系统返回用户的不再是基于关键词匹配的相关文档排序,而是精准自然语言形式的答案。
对话系统:能够以自然语言与人类进行对话的计算机系统,它旨在让计算机能够“听懂”人类语言,并对于用户所提的消息返回准确、流利、一致的回复,甚至完成特定的操作。
问答是信息获取的高效方式,对话是人机交互的自然形式,问答可以看作一种需求明确的单轮对话。知识图谱是问答和对话系统的重要基础,其包含大量描述精准的结构化语义内容,有助于问答和对话系统为用户提供精准的知识服务。
说明:对话系统 = 自然语言处理 + 知识图谱 + 垂直行业。
第12章:基于知识的搜索与推荐
根据用户需求的不同目标类型,将现有工作主要分为以下三类:
(1)实体搜索与推荐:目标是从知识图谱中找出用户需要的实体。这是目前最常见、应用最广泛的一类工作,比如,电商领域的商品搜索与推荐,学术领域的论文搜索与推荐,电影和音乐的搜索与推荐等,都属于这类工作。
(2)实体关系搜索:目标是从知识图谱中找出用户关注的一组实体之间的关系。目前,这类工作的典型应用包括:商业领域的企业关系搜索,社交领域的人际关系链推荐,安全领域的特定目标关系搜索等。
(3)基于关键词的知识探索:目标是从知识图谱中找出用户感兴趣的子图。这是上述两类工作的泛化形式,主要应用场景是帮助用户探索和理解知识图谱的内容和结构,寻找用户感兴趣的信息。
第13章:知识图谱交叉前沿
知识图谱技术是知识图谱建立和应用的技术,是语义Web、自然语言处理和机器学习等的交叉学科。在实际应用中,知识图谱在知识融合、语义搜索和推荐、问答和对话系统以及大数据分析和决策等以数据为中心的应用中已经凸显出越来越重要的应用价值。
说明:知识图谱+一切,只有想不到的,没有知识图谱加不到的。
参考文献:
[1]知识图谱发展报告(2022):https://url39.ctfile.com/f/2501739-668230065-8345de?p=2096 (访问密码: 2096)
[2]Datasets on Crowdsourcing:http://dbgroup.cs.tsinghua.edu.cn/ligl/crowddata/
[3]OpenKG.CN中文开放知识图谱:http://www.openkg.cn/
吾爱DotNet
 专注于.NET领域的技术分享
专注于.NET领域的技术分享
人工智能干货推荐
 专注于人工智能领域的技术分享
专注于人工智能领域的技术分享