目前已经更新完《Java并发编程》,《Spring核心知识》《Docker教程》和《JVM性能优化》,都是多年面试总结。欢迎关注【后端精进之路】,轻松阅读全部文章。
Java并发编程:
- Java并发编程系列-(1) 并发编程基础
- Java并发编程系列-(2) 线程的并发工具类
- Java并发编程系列-(3) 原子操作与CAS
- Java并发编程系列-(4) 显式锁与AQS
- Java并发编程系列-(5) Java并发容器
- Java并发编程系列-(6) Java线程池
- Java并发编程系列-(7) Java线程安全
- Java并发编程系列-(8) JMM和底层实现原理
- Java并发编程系列-(9) JDK 8/9/10中的并发
Docker教程:
- Docker系列-(1) 原理与基本操作
- Docker系列-(2) 镜像制作与发布
- Docker系列-(3) Docker-compose使用与负载均衡
- Docker 安装 Jenkins 并实现项目自动化部署
- 如何0失误快速搭建K8s环境?你想了解的这都有
JVM性能优化:
- JVM性能优化系列-(1) Java内存区域
- JVM性能优化系列-(2) 垃圾收集器与内存分配策略
- JVM性能优化系列-(3) 虚拟机执行子系统
- JVM性能优化系列-(4) 编写高效Java程序
- JVM性能优化系列-(5) 早期编译优化
- JVM性能优化系列-(6) 晚期编译优化
- JVM性能优化系列-(7) 深入了解性能优化
Spring MVC系列:
Spark系列:
4. Spark任务调度
4.1 核心组件
本节主要介绍Spark运行过程中的核心以及相关组件。
4.1.1 Driver
Spark驱动器节点,用于执行Spark任务中的main方法,负责实际代码的执行工作。Driver在Spark作业时主要负责:
- 将用户程序转化为任务(job)
- 在Executor之间调度任务
- 跟踪Executor的执行情况
- 通过UI展示查询运行情况
4.1.2 Executor
Spark Executor 节点是一个JVM进程,负责在Spark作业中运行具体任务,任务彼此之间相互独立。 Spark应用启动时, Executor节点被同时启动, 并且始终伴随着整个Spark应用的生命周期而存在。 如果有Executor节点发生了故障或崩溃, Spark应用也可以继续执行,会将出错节点上的任务调度到其他 Executor节点上继续运行。
Executor 有两个核心功能:
- 负责运行组成Spark应用的任务,并将结果返回给Driver进程;
- 他们通过自身的块管理器(Block Manager)为用户程序中要求缓存的RDD提供内存式存储。RDD是直接缓存在Executor进程内的,因此任务可以在运行时充分利用缓存数据加速运算。
4.1.3 SparkContext
在Spark中由SparkContext负责与集群进行通讯、资源的申请以及任务的分配和监控等。当Work节点中的Executor运行完Task后,Driver同时负责将SparkContext关闭,通常也可以使用SparkContext来代表驱动程序(Driver)。
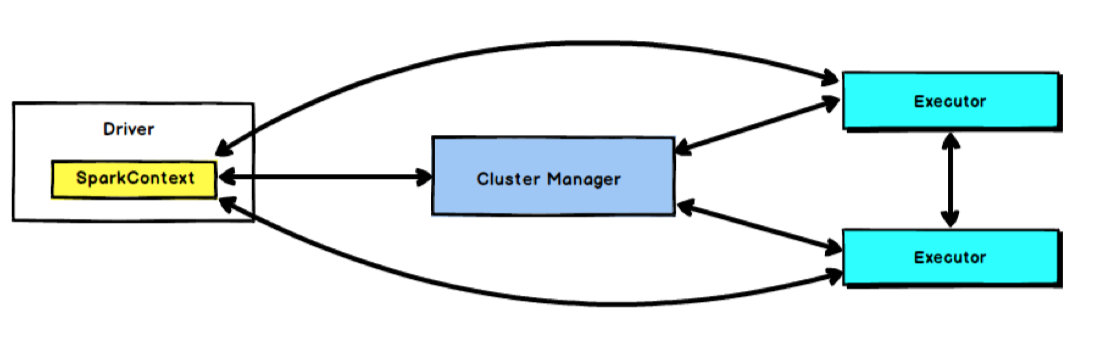
SparkContext 是用户通往 Spark 集群的唯一入口,可以用来在Spark集群中创建RDD 、累加器和广播变量。SparkContext 也是整个 Spark 应用程序中至关重要的一个对象, 可以说是整个Application运行调度的核心(不包括资源调度)。
SparkContext的核心作用是初始化 Spark 应用程序运行所需的核心组件,包括高层调度器(DAGScheduler)、底层调度器( TaskScheduler )和调度器的通信终端( SchedulerBackend ), 同时还会负责Spark程序向ClusterManager的注册等。
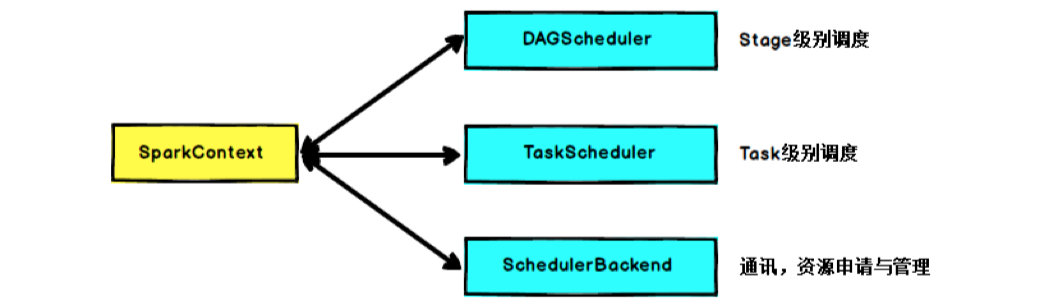
当RDD的action算子触发了作业( Job )后, SparkContext 会调用DAGScheduler根据宽窄依赖将 Job 划分成几个小的阶段( Stage ),TaskScheduler 会调度每个 Stage 的任务( Task ),另外,SchedulerBackend 负责申请和管理集群为当前Applic ation分配的计算资源(即 Executor ) 。
下图描述了Spark-On-Yarn 模式下在任务调度期间, ApplicationMaster、Driver以及Executor内部模块的交互过程:
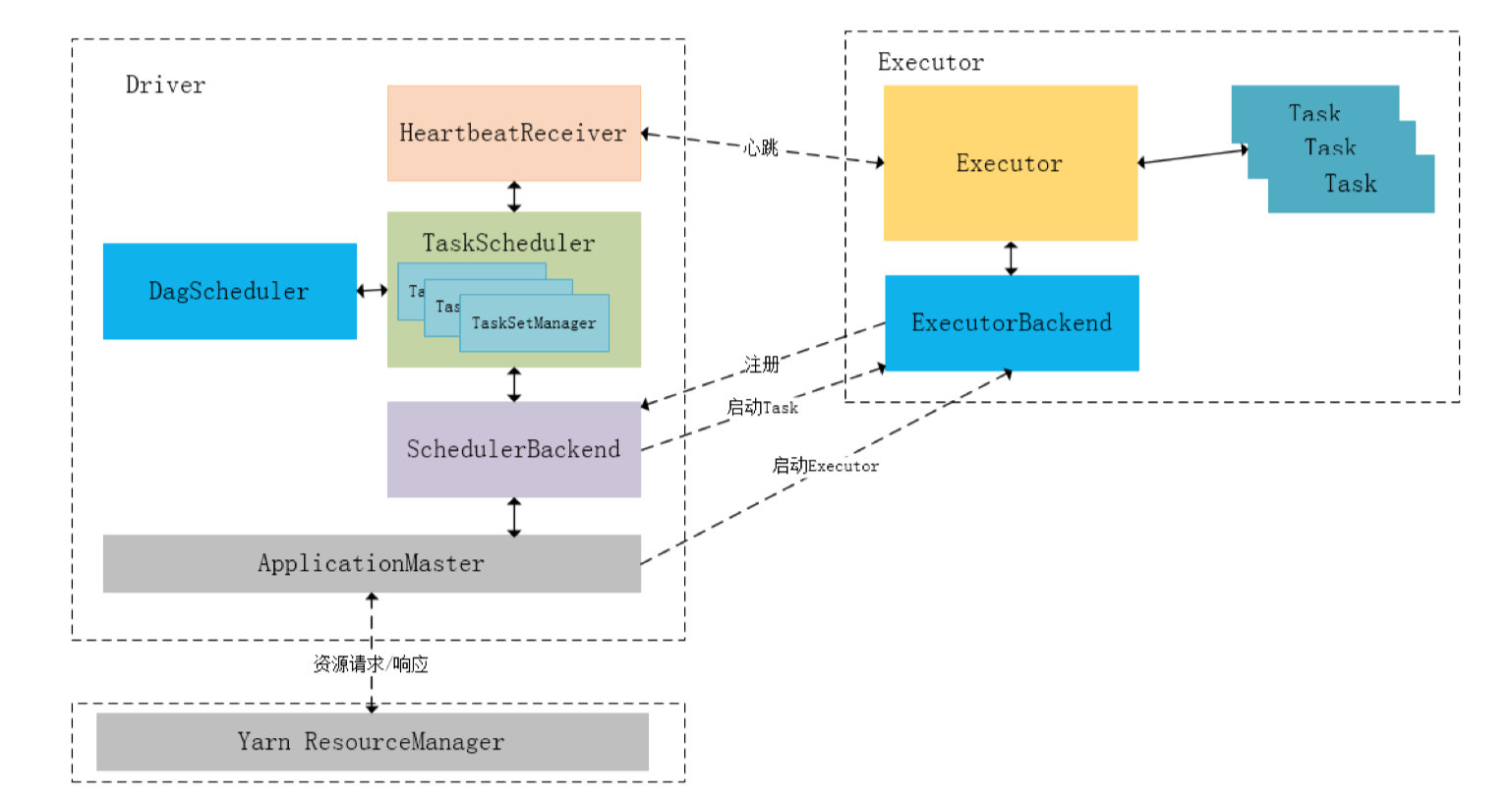
Driver初始化SparkContext过程中,会分别初始化DAGScheduler、TaskScheduler 、SchedulerBackend 以及 HeartbeatReceiver,并启动SchedulerBackend 以及 HeartbeatReceiver。SchedulerBackend通过 ApplicationMaster申请资源,并不断从TaskScheduler 中拿到合适的Task分发到Executor执行。HeartbeatReceiver 负责接收Executor的心跳信息,监控Executor的存活状况,并通知到TaskScheduler 。
4.2 YARN
Yarn虽然不属于Spark的组件,但是现在Spark程序基本都是依赖Yarn来调度,因此专门介绍下YARN。
Yarn(Yet Another Resource Negotiator)是Hadoop集群的资源管理系统,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
4.2.1 架构
将JobTracker和TaskTracker进行分离,它由下面几大构成组件:
a. 一个全局的资源管理器 ResourceManager
b. ResourceManager的每个节点代理 NodeManager
c. 表示每个应用的ApplicationMaster
d. 每一个ApplicationMaster拥有多个Container在NodeManager上运行
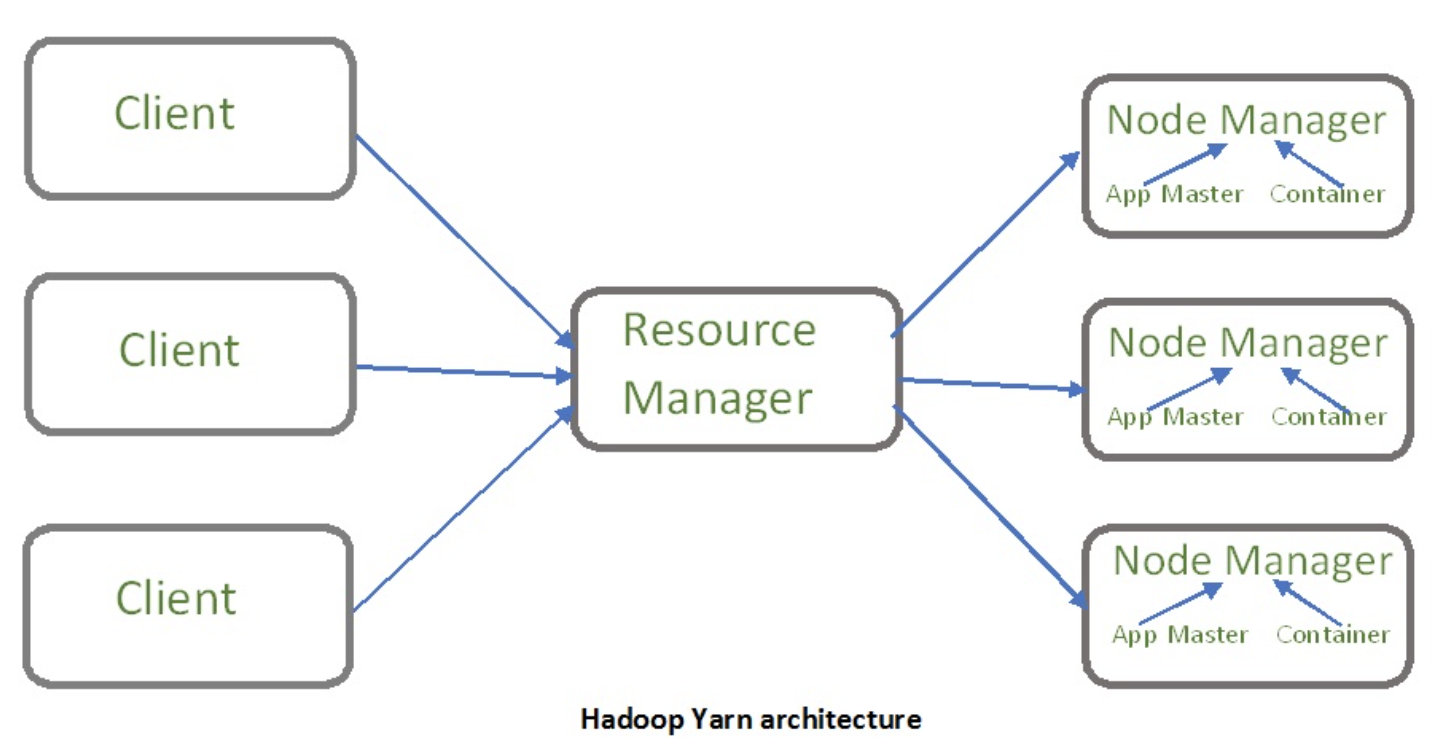
- Client:提交job。
- Resource Manager:它是YARN的主守护进程,负责所有应用程序之间的资源分配和管理。每当它接收到处理请求时,它都会将其转发给相应的节点管理器,并相应地分配资源以完成请求。它有两个主要组成部分:
- Scheduler:它根据分配的应用程序和可用资源执行调度。它是一个纯调度程序,意味着它不执行其他任务,例如监控或跟踪,并且不保证在任务失败时重新启动。 YARN调度器支持Capacity Scheduler、Fair Scheduler等插件对集群资源进行分区。
- Application Manager:它负责接受应用程序并与资源管理器协商第一个容器。如果任务失败,它还会重新启动 Application Master 容器。
-
Node Manager:它负责 Hadoop 集群上的单个节点,并管理应用程序和工作流以及该特定节点。它的主要工作是跟上资源管理器的步伐。它向资源管理器注册并发送带有节点健康状态的心跳。它监控资源使用情况,执行日志管理,还根据资源管理器的指示杀死容器。它还负责创建容器进程并根据Application master的请求启动它。
-
Application Master:应用程序是提交给框架的单个作业。应用主负责与资源管理器协商资源,跟踪单个应用的状态和监控进度。应用程序主机通过发送一个容器启动上下文(CLC)从节点管理器请求容器,其中包括应用程序需要运行的所有内容。一旦应用程序启动,它会不时地向资源管理器发送健康报告。
-
Container:它是单个节点上物理资源的集合,例如 RAM、CPU 内核和磁盘。容器由容器启动上下文(CLC)调用,这是一个包含环境变量、安全令牌、依赖项等信息的记录。
容器(Container)这个东西是 Yarn 对资源做的一层抽象。就像我们平时开发过程中,经常需要对底层一些东西进行封装,只提供给上层一个调用接口一样,Yarn 对资源的管理也是用到了这种思想。
如上所示,Yarn 将CPU核数,内存这些计算资源都封装成为一个个的容器(Container)。
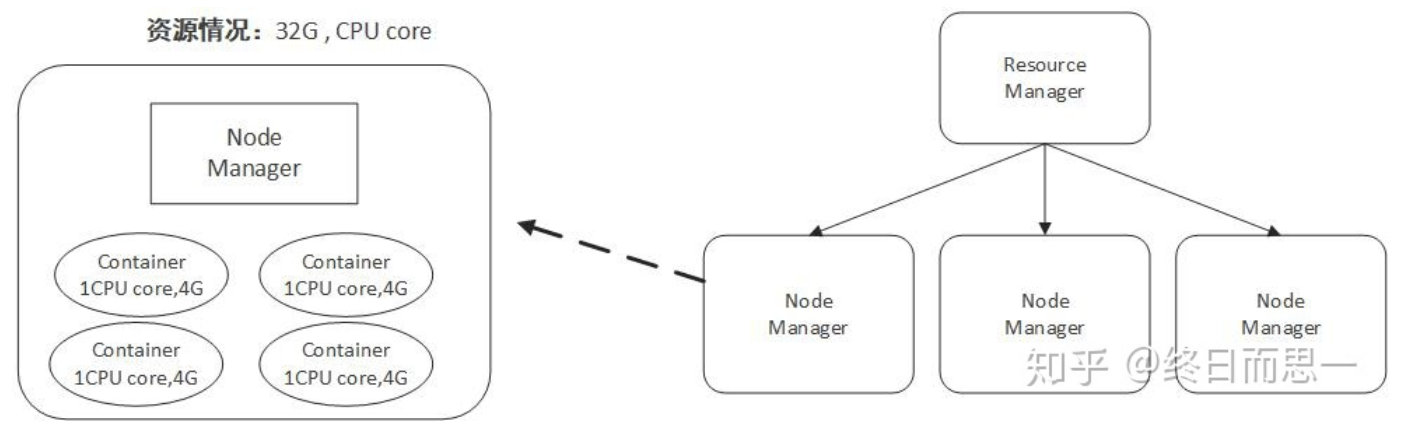
4.2.2 任务提交流程
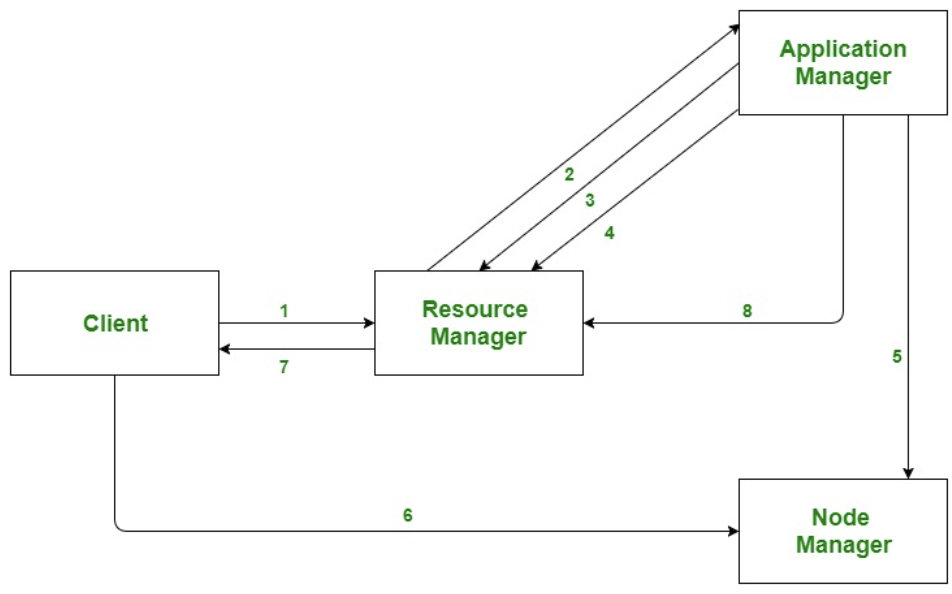
- 客户端提交申请
- Resource Manager分配一个Container来启动Application Manager
- Application Manager向Resource Manager注册自己
- AM从RM申请容器资源
- AM通知 Node Manager 启动容器
- 应用程序代码在容器中执行
- 客户端联系RM/AM以监控应用程序的状态
- Job完成后,AM向RM取消注册
4.3 Spark程序运行流程
在实际生产环境下, Spark集群的部署方式一般为 YARN-Cluster模式,之后的内核分析内容中我们默认集群的部署方式为YARN-Cluster模式。
下图展示了一个Spark应用程序从提交到运行的完整流程:
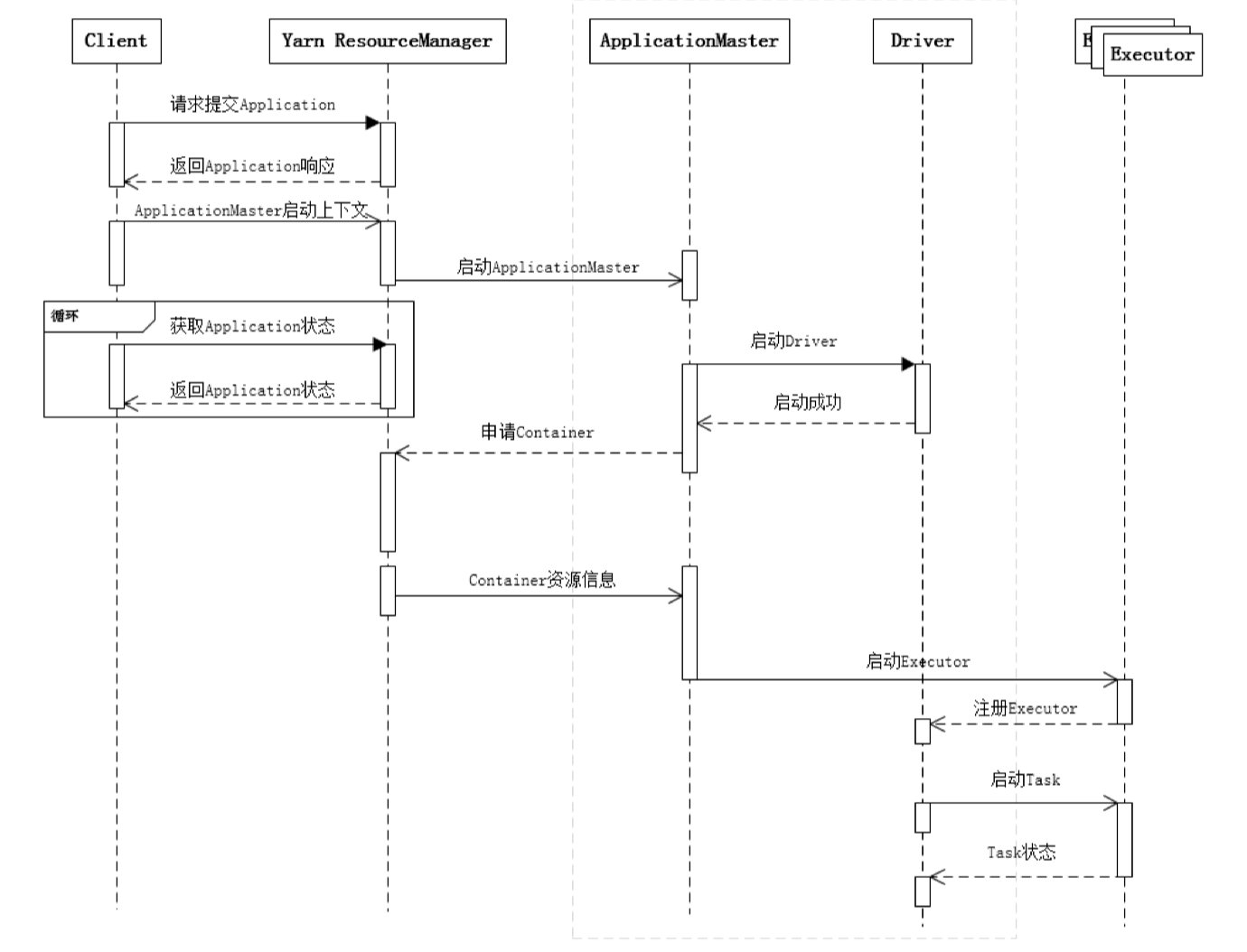
提交一个Spark应用程序,首先通过Client向 ResourceManager请求启动一个Application,同时检查是否有足够的资源满足Application的需求,如果资源条件满 足,则准备ApplicationMaster的启动上下文,交给 ResourceManager,并循环监控Application状态。
当提交的资源队列中有资源时, ResourceManager 会在某个 NodeManager 上启动 ApplicationMaster 进程,ApplicationMaster会单独启动Driver后台线程,当 Driver启动后,ApplicationMaster 会通过本地的 RPC 连接 Driver ,并开始向 ResourceManager 申请 Container 资源运行Executor进程(一个Executor对应与一个 Container),当ResourceManager返回Container 资源,ApplicationMaster则在对应的Container上启动 Executor 。
Driver 线程主要是初始化 SparkContext 对象, 准备运行所需的上下文, 然后一方面保持与ApplicationMaster 的 RPC 连接,通过 ApplicationMaster 申请资源,另一方面根据用户业务逻辑开始调度任务,将任务下发到已有的空闲Ex ecutor上。
当 ResourceManager 向 ApplicationMaster返回 Container 资源时,ApplicationMaster 就尝试在对应的 Container 上启动Executor 进程Executor进程起来后,会向Driver反向注册,注册成功后保持与Driver的心跳,同时等待 Driver 分发任务,当分发的任务执行完毕后,将任务状态上报给Driver 。
从上述时序图可知,Client只负责提交Application并监控 Application的状态。对于Spark的任务调度主要是集中在两个方面: 资源申请和任务分发,其主要是通过ApplicationMaster、Driver以及Executor之间来完成。
4.4 Spark任务调度概述
一个Spark程序包括Job、Stage以及Task三个概念:
- Job是以Action方法为界,遇到一个Action方法则触发一个Job;
- Stage是Job的子集,以RDD宽依赖(即Shuffle)为界,遇到Shuffle做一次划分;
- Task是Stage的子集,以并行度(分区数)来衡量,分区数是多少,则有多少个task。
Spark任务的调度总体上分两路进行,一路是Stage级的调度,一路是Task级的调度,总体的调度流程如下:
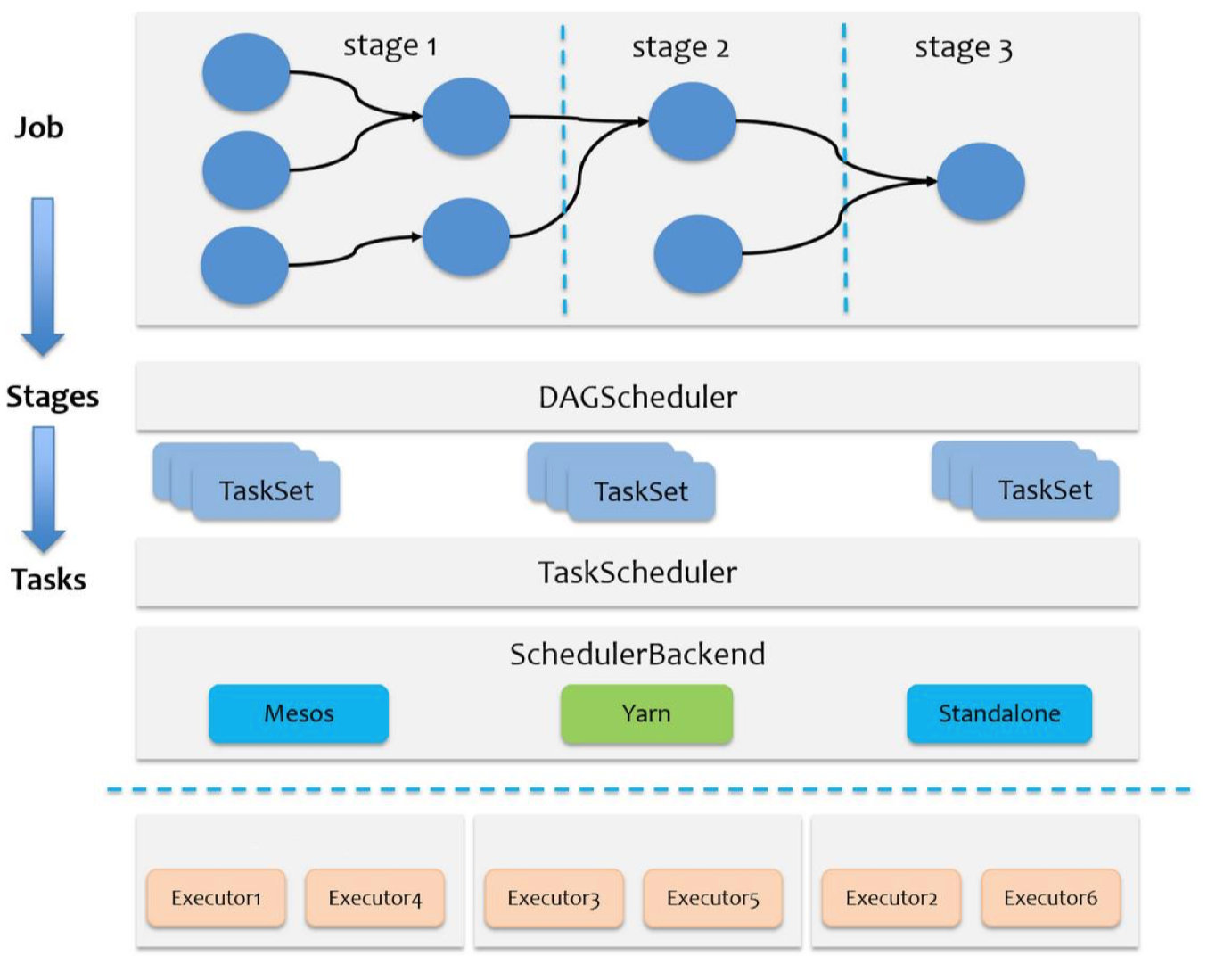
Spark RDD通过Transformation操作,形成了RDD血缘关系图,即DAG,最后通过Action的调用,触发job并调度执行。
-
DAGScheduler负责Stage级的调度,主要是将job切分成若干个Stages,并将每个Stage打包成TaskSet交给TaskScheudler调度。
-
TaskScheduler负责Task级的调度,将DAGScheduler传过来的TaskSet按照指定的调度策略分发到Executor上执行,调度过程中SchedulerBackend负责提供可用资源,其中SchedulerBackend有多种实现,分别对接不同的资源管理系统。
4.4.1 Spark Stage级调度
下图是Spark Stage级调度时的流程图:
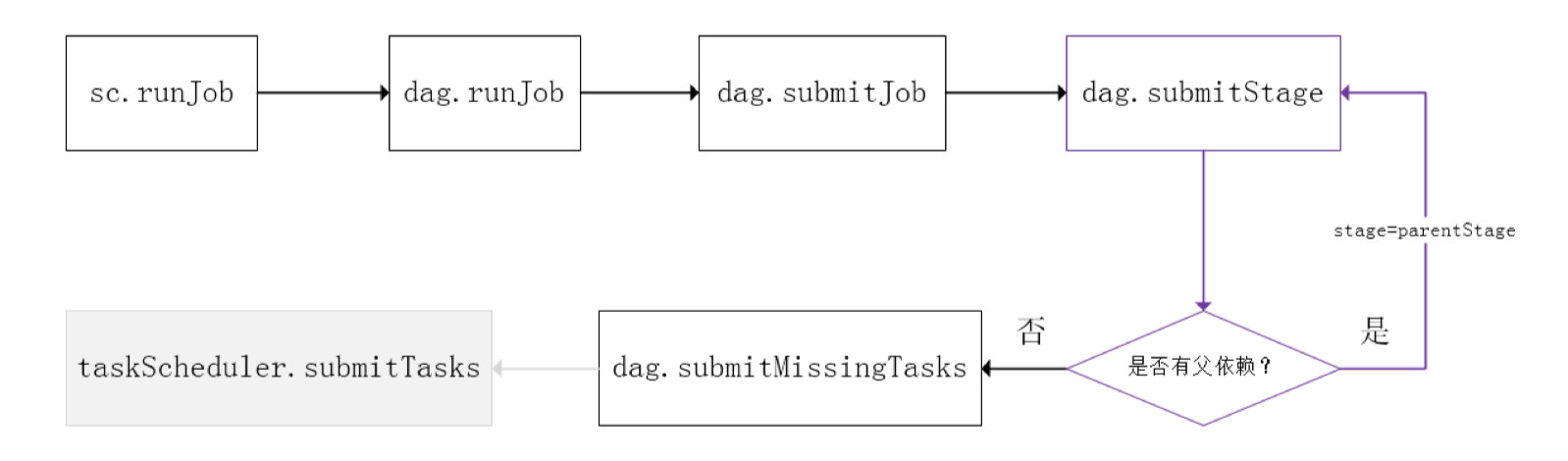
SparkContext将Job交给DAGScheduler提交, 它会根据 RDD 的血缘关系构成的 DAG 进行切分,将一个Job 划分为若干Stages,具体划分策略是,由最终的RDD不断通过依赖回溯判断父依赖是否是宽依赖,即以Shuffle为界,划分Stage,窄依赖的 RDD之间被划分到同一个 Stage 中,可以进行 pipeline 式的计算,如上图紫色流程部分。划分的Stages 分两类,一类叫做ResultStage,为 DAG 最下游的Stage,由Action方法决定,另一类叫做ShuffleMapStage,为下游Stage准备数据。
下图以WordCount为例,说明整个过程:
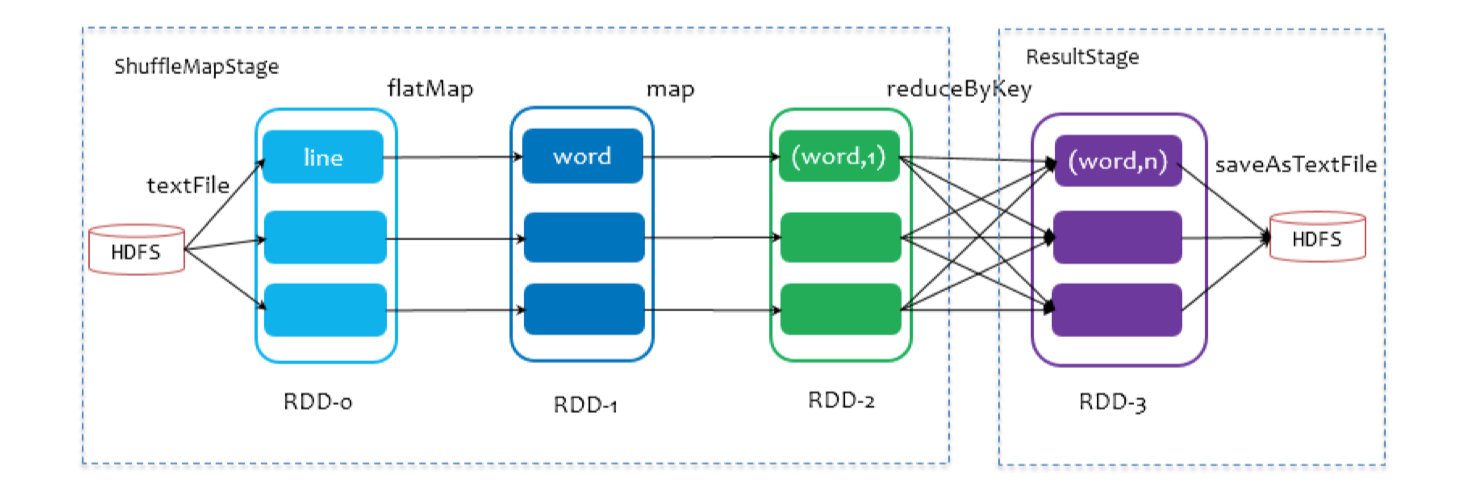

一个Stage是否被提交,需要判断它的父Stage是否执行,只有在父Stage执行完毕才能提交当前Stage,如果一个Stage没有父Stage,那么从该Stage开始提交。Stage提交时会将Task信息(分区信息以及方法等)序列化并被打包成TaskSet交给TaskScheduler。
4.4.2 Spark Task级调度
Spark Task的调度是由TaskScheduler来完成,由前文可知,DAGScheduler将Stage打包到TaskSet交给TaskScheduler,TaskScheduler会将TaskSet封装为TaskSetManager加入到调度队列中,TaskSetManager结构如下图所示。
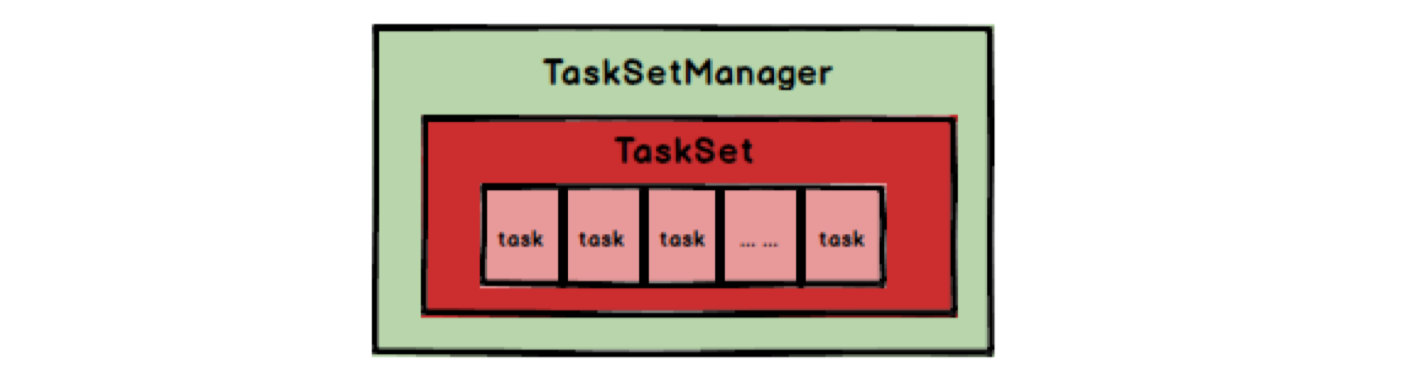
TaskSetManager负责监控管理同一个Stage中的Tasks,TaskScheduler就是以TaskSetManager为单元来调度任务。
TaskScheduler初始化后会启动SchedulerBackend,它负责跟外界打交道,接收Executor的注册信息,并维护Executor的状态,TaskScheduler在SchedulerBackend轮询它的时候,会从调度队列中按照指定的调度策略选择TaskSetManager去调度运行,大致方法调用流程如下图所示:
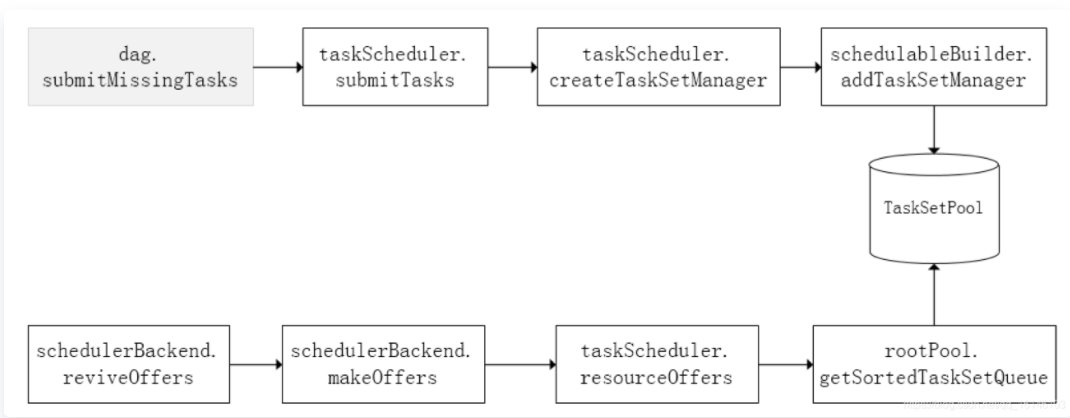
TaskScheduler提交Tasks的原理
-
获取当前TaskSet里的所有Task;
-
根据当前的TaskSet封装成对应的TaskSetManager。每一个TaskSet都会创建一个TaskSetManager与之对应。该TaskSetManager的作用就是监控它对应的所有的Task的执行状态和管理。TaskScheduler就是以TaskSetManager为调度单元去执行Tasks的;
-
将封装好的TaskSetManager加入到等待的调度队列等待调度,又schedueBuilder决定调度的顺序,scheduleBuilder有两种实现类,一种是FIFOOSchedulerBuilder,另一个是FairSchedulerBuilder,而Spark默认采用的是FIFO调度模式。
-
在初始化TaskSchedulerImpl的时候会调用start方法来启动SchedulerBackend,SchedulerBackend(实际上是CoarseGrainedSchedulerBackend)调用riviveOffers方法。SchedulerBackend负责与外界打交道,接受来自Executor的注册,并维护Executor的状态。
-
调用CoarseGrainedSchedulerBackend的riviveOffers方法对Tasks进行调度。
-
reviveOffers方法里向DriverEndpoint发送ReviveOffers消息触发调度任务的执行,DriverEndpoint接受到ReviveOffers消息后接着调用makeOffers方法
-
SchedulerBackend(实际上是CoarseGrainedSchedulerBackend)负责将新创建的Task分发给Executor上执行。
调度策略
TaskScheduler支持两种调度策略,一种是FIFO,也是默认的调度策略,另一种是FAIR。
在TaskScheduler初始化过程中会实例化rootPool,表示树的根节点,是Pool类型。
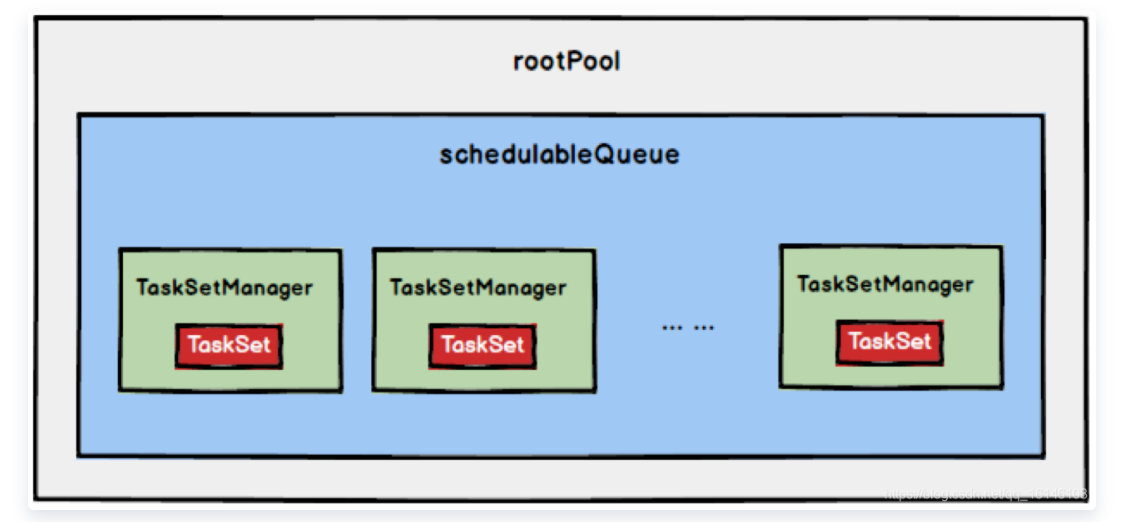
1. FIFO调度策略
如果是采用FIFO调度策略,则直接简单地将TaskSetManager按照先来先到的方式入队,出队时直接拿出最先进队的TaskSetManager,其树结构如下图所示,TaskSetManager保存在一个FIFO队列中。
2. FAIR调度策略(0.8开始支持)
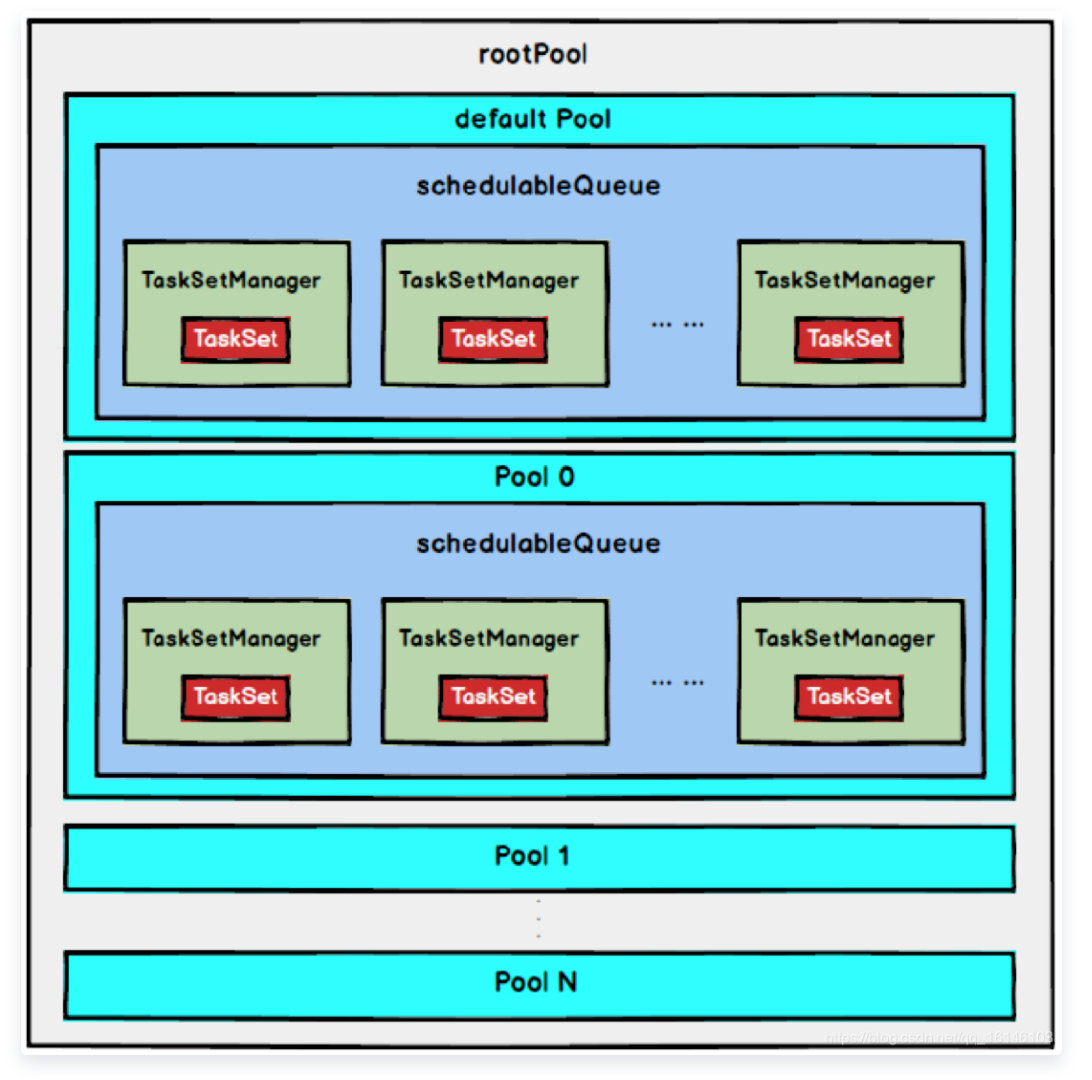
FAIR模式中有一个rootPool和多个子Pool,各个子Pool中存储着所有待分配的TaskSetMagager。
在FAIR模式中,需要先对子Pool进行排序,再对子Pool里面的TaskSetMagager进行排序,因为Pool和TaskSetMagager都继承了Schedulable特质,因此使用相同的排序算法。
排序过程的比较是基于Fair-share来比较的,每个要排序的对象包含三个属性: runningTasks值(正在运行的Task数)、minShare值、weight值,比较时会综合考量runningTasks值,minShare值以及weight值。
注意,minShare、weight的值均在公平调度配置文件fairscheduler.xml中被指定,调度池在构建阶段会读取此文件的相关配置。
比较规则如下:
- 如果 A 对象的runningTasks大于它的minShare,B 对象的runningTasks小于它的minShare,那么B排在A前面;(runningTasks 比 minShare 小的先执行)
- 如果A、B对象的 runningTasks 都小于它们的 minShare,那么就比较 runningTasks 与 math.max(minShare1, 1.0) 的比值(minShare使用率),谁小谁排前面;(minShare使用率低的先执行)
- 如果A、B对象的runningTasks都大于它们的minShare,那么就比较runningTasks与weight的比值(权重使用率),谁小谁排前面。(权重使用率低的先执行)
- 如果上述比较均相等,则比较名字。
整体上来说就是通过minShare和weight这两个参数控制比较过程,可以做到让minShare使用率和权重使用率少(实际运行task比例较少)的先运行。
FAIR模式排序完成后,所有的TaskSetManager被放入一个ArrayBuffer里,之后依次被取出并发送给Executor执行。
从调度队列中拿到TaskSetManager后,由于TaskSetManager封装了一个Stage的所有Task,并负责管理调度这些Task,那么接下来的工作就是TaskSetManager按照一定的规则一个个取出Task给TaskScheduler,TaskScheduler再交给SchedulerBackend去发到Executor上执行。
可以采用如下设置启动公平调度器:
val conf = new SparkConf().setMaster(...).setAppName(...)
conf.set("spark.scheduler.mode", "FAIR")
val sc = new SparkContext(conf)
本地化调度
DAGScheduler切割Job,划分Stage, 通过调用submitStage来提交一个Stage对应的tasks,submitStage会调用submitMissingTasks,submitMissingTasks 确定每个需要计算的 task 的preferredLocations,通过调用getPreferrdeLocations()得到partition的优先位置,由于一个partition对应一个Task,此partition的优先位置就是task的优先位置,
对于要提交到TaskScheduler的TaskSet中的每一个Task,该ask优先位置与其对应的partition对应的优先位置一致。
从调度队列中拿到TaskSetManager后,那么接下来的工作就是TaskSetManager按照一定的规则一个个取出task给TaskScheduler,TaskScheduler再交给SchedulerBackend去发到Executor上执行。前面也提到,TaskSetManager封装了一个Stage的所有Task,并负责管理调度这些Task。 根据每个Task的优先位置,确定Task的Locality级别,Locality一共有五种,优先级由高到低顺序:
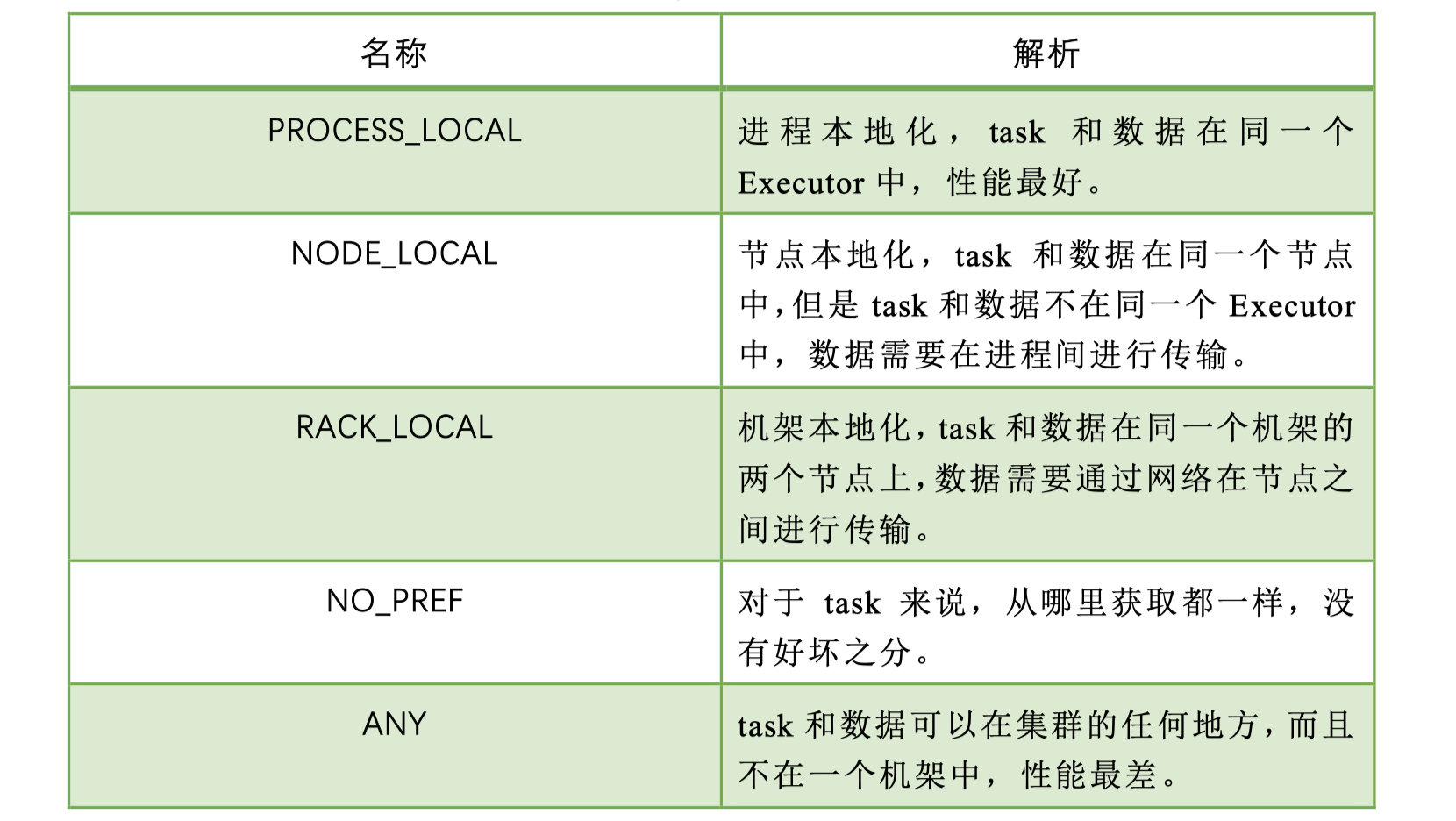
在调度执行时,Spark 调度总是会尽量让每个task以最高的本地性级别来启动,当一个task以本地性级别启动,但是该本地性级别对应的所有节点都没有空闲资源而启动失败,此时并不会马上降低本地性级别启动而是在某个时间长度内再次以本地性级别来启动该task,若超过限时时间则降级启动,去尝试下一个本地性级别,依次类推。
可以通过调大每个类别的最大容忍延迟时间,在等待阶段对应的Executor可能就会有相应的资源去执行此task,这就在在一定程度上提升了运行性能。
失败重试和黑名单
除了选择合适的Task调度运行外,还需要监控Task的执行状态,前面也提到,与外部打交道的是SchedulerBackend,Task被提交到Executor启动执行后,Executor会将执行状态上报给SchedulerBackend,SchedulerBackend则告诉TaskScheduler,TaskScheduler找到该Task对应的TaskSetManager,并通知到该TaskSetManager,这样TaskSetManager就知道Task的失败与成功状态,对于失败的Task,会记录它失败的次数,如果失败次数还没有超过最大重试次数,那么就把它放回待调度的Task池子中,否则整个Application失败。
在记录Task失败次数过程中,会记录它上一次失败所在的Executor Id和Host,这样下次再调度这个Task时,会使用黑名单机制,避免它被调度到上一次失败的节点上,起到一定的容错作用。黑名单记录Task上一次失败所在的Executor Id和Host,以及其对应的“拉黑”时间,“拉黑”时间是指这段时间内不要再往这个节点上调度这个Task了。
参考:
- https://cloud.tencent.com/developer/article/1733855
- https://www.jianshu.com/p/8cf5f16432f8
- https://blog.csdn.net/Suubyy/article/details/81945638