一、GPU 利用率的定义
本文的 GPU 利用率主要指 GPU 在时间片上的利用率,即通过 nvidia-smi 显示的 GPU-util 这个指标。统计方式为:在采样周期内,GPU 上面有 kernel 执行的时间百分比。
二、GPU 利用率低的本质
常见 GPU 任务运行流程图如下:
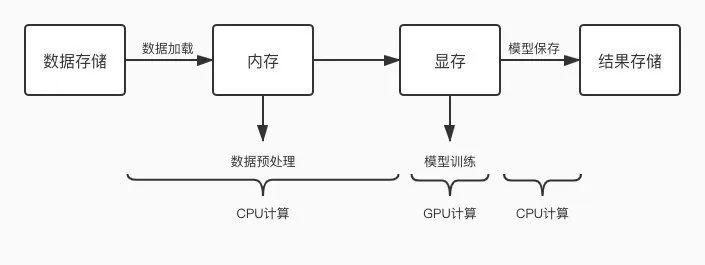

如上图所示,GPU 任务会交替的使用 CPU 和 GPU 进行计算,当 CPU 计算成为瓶颈时,就会出现 GPU 等待的问题,GPU 空跑那利用率就低了。那么优化的方向就是缩短一切使用 CPU 计算环节的耗时,减少 CPU 计算对 GPU 的阻塞情况。常见的 CPU 计算操作如下:
- 数据加载
- 数据预处理
- 模型保存
- loss 计算
- 评估指标计算
- 日志打印
- 指标上报
- 进度上报
三、常见 GPU 利用率低原因分析
1、数据加载相关
1)存储和计算跨城了,跨城加载数据太慢导致 GPU 利用率低
说明:例如数据存储在“深圳 ceph”,但是 GPU 计算集群在“重庆”,那就涉及跨城使用了,影响很大。
优化:要么迁移数据,要么更换计算资源,确保存储及计算是同城的。
2)存储介质性能太差
说明:不同存储介质读写性能比较:本机 SSD > ceph > cfs-1.5 > hdfs > mdfs
优化:将数据先同步到本机 SSD,然后读本机 SSD 进行训练。本机 SSD 盘为“/dockerdata”,可先将其他介质下的数据同步到此盘下进行测试,排除存储介质的影响。
3)小文件太多,导致文件 io 耗时太长
说明:多个小文件不是连续的存储,读取会浪费很多时间在寻道上
优化:将数据打包成一个大的文件,比如将许多图片文件转成一个 hdf5/pth/lmdb/TFRecord 等大文件
lmdb 格式转换样例:
https://github.com/Lyken17/Efficient-PyTorch#data-loader
其他格式转换方式请自行谷歌
4)未启用多进程并行读取数据
说明:未设置 num_workers 等参数或者设置的不合理,导致 cpu 性能没有跑起来,从而成为瓶颈,卡住 GPU
优化:设置 torch.utils.data.DataLoader 方法的 num_workers 参数、tf.data.TFRecordDataset 方法的 num_parallel_reads 参数或者 tf.data.Dataset.map 的 num_parallel_calls 参数。
5)未启用提前加载机制来实现 CPU 和 GPU 的并行
说明:未设置 prefetch_factor 等参数或者设置的不合理,导致 CPU 与 GPU 在时间上串行,CPU 运行时 GPU 利用率直接掉 0
优化:设置 torch.utils.data.DataLoader 方法的 prefetch_factor 参数 或者 tf.data.Dataset.prefetch()方法。prefetch_factor 表示每个 worker 提前加载的 sample 数量 (使用该参数需升级到 pytorch1.7 及以上),Dataset.prefetch()方法的参数 buffer_size 一般设置为:tf.data.experimental.AUTOTUNE,从而由 TensorFlow 自动选择合适的数值。
6)未设置共享内存 pin_memory
说明:未设置 torch.utils.data.DataLoader 方法的 pin_memory 或者设置成 False,则数据需从 CPU 传入到缓存 RAM 里面,再给传输到 GPU 上
优化:如果内存比较富裕,可以设置 pin_memory=True,直接将数据映射到 GPU 的相关内存块上,省掉一点数据传输时间
2、数据预处理相关
1)数据预处理逻辑太复杂
说明:数据预处理部分超过一个 for 循环的,都不应该和 GPU 训练部分放到一起
优化:a、设置 tf.data.Dataset.map 的 num_parallel_calls 参数,提高并行度,一般设置为 tf.data.experimental.AUTOTUNE,可让 TensorFlow 自动选择合适的数值。
b、将部分数据预处理步骤挪出训练任务,例如对图片的归一化等操作,提前开启一个 spark 分布式任务或者 cpu 任务处理好,再进行训练。
c、提前将预处理部分需要用到的配置文件等信息加载到内存中,不要每次计算的时候再去读取。
d、关于查询操作,多使用 dict 加速查询操作;减少 for、while 循环,降低预处理复杂度。
2)利用 GPU 进行数据预处理 -- Nvidia DALI
说明:Nvidia DALI 是一个专门用于加速数据预处理过程的库,既支持 GPU 又支持 CPU
优化:采用 DALI,将基于 CPU 的数据预处理流程改造成用 GPU 来计算
DALI 文档如下:https://zhuanlan.zhihu.com/p/105056158
3、模型保存相关
1)模型保存太频繁
说明:模型保存为 CPU 操作,太频繁容易导致 GPU 等待
优化:减少保存模型(checkpoint)的频率
4、指标相关
1)loss 计算太复杂
说明:含有 for 循环的复杂 loss 计算,导致 CPU 计算时间太长从而阻塞 GPU
优化:该用低复杂度的 loss 或者使用多进程或多线程进行加速
2)指标上报太频繁
说明:指标上报操作太频繁,CPU 和 GPU 频繁切换导致 GPU 利用率低
优化:改成抽样上报,例如每 100 个 step 上报一次
5、日志相关
1)日志打印太频繁
说明:日志打印操作太频繁,CPU 和 GPU 频繁切换导致 GPU 利用率低
优化:改成抽样打印,例如每 100 个 step 打印一次
四、常见数据加载方法说明
1、pytorch 的 torch.utils.data.DataLoader
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None, *, prefetch_factor=2,
persistent_workers=False)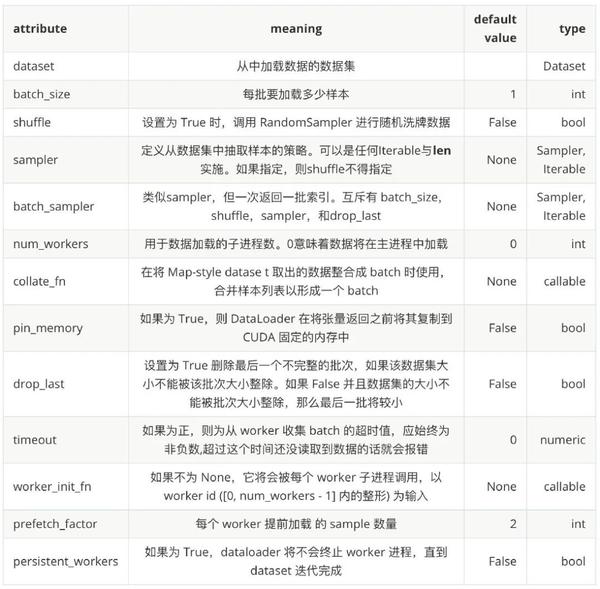

从参数定义中,我们可以看到 DataLoader 主要支持以下几个功能:
- 支持加载 map-style 和 iterable-style 的 dataset,主要涉及到的参数是 dataset
- 自定义数据加载顺序,主要涉及到的参数有 shuffle, sampler, batch_sampler, collate_fn
- 自动把数据整理成 batch 序列,主要涉及到的参数有 batch_size, batch_sampler, collate_fn, drop_last
- 单进程和多进程的数据加载,主要涉及到的参数有 num_workers, worker_init_fn
- 自动进行锁页内存读取 (memory pinning),主要涉及到的参数 pin_memory
- 支持数据预加载,主要涉及的参数 prefetch_factor
参考文档:https://pytorch.org/docs/stable/data.html
2、tensorflow 的 tf.data.Dataset
ds_train = tf.data.Dataset.from_tensor_slices((x,y))\
.shuffle(5000)\
.batch(batchs)\
.map(preprocess,num_parallel_calls=tf.data.experimental.AUTOTUNE)\
.prefetch(tf.data.experimental.AUTOTUNE)- Dataset.prefetch(): 可以让数据集对象 Dataset 在 å 训练时预取出若干个元素,使得在 GPU 训练的同时 CPU 可以准备数据,提升训练流程的效率
- Dataset.map(f): 转换函数 f 映射到数据集每一个元素; 可以利用多 CPU 资源,充分利用多核心的优势对数据进行并行化变换, num_parallel_calls 设置为 tf.data.experimental.AUTOTUNE 以让 TensorFlow 自动选择合适的数值,数据转换过程多进程执行,设置 num_parallel_calls 参数能发挥 cpu 多核心的优势
- Dataset.shuffle(buffer_size): 将数据集打乱,取出前 buffer_size 个元素放入,并从缓冲区中随机采样,采样后的数据用后续数据替换
- Dataset.batch(batch_size):将数据集分成批次,即对每 batch_size 个元素,使用 tf.stack() 在第 0 维合并,成为一个元素
参考文档:https://www.tensorflow.org/api_docs/python/tf/data/Dataset#methods_2
五、分布式任务常见的 GPU 利用率低问题
分布式任务相比单机任务多了一个机器间通信环节。如果在单机上面运行的好好的,扩展到多机后出现 GPU 利用率低,运行速度慢等问题,大概率是机器间通信时间太长导致的。请排查以下几点:
1、机器节点是否处在同一 modules?
答:机器节点处于不同 modules 时,多机间通信时间会长很多,deepspeed 组件已从平台层面增加调度到同一 modules 的策略,用户不需要操作;其他组件需联系我们开启。
2、多机时是否启用 GDRDMA?
答:能否启用 GDRDMA 和 NCCL 版本有关,经测试,使用 PyTorch1.7(自带 NCCL2.7.8)时,启动 GDRDMA 失败,和 Nvidia 的人沟通后确定是 NCCL 高版本的 bug,暂时使用的运行注入的方式来修复;使用 PyTorch1.6(自带 NCCL2.4.8)时,能够启用 GDRDMA。经测试,“NCCL2.4.8 + 启用 GDRDMA ” 比 “NCCL2.7.8 + 未启用 GDRDMA”提升 4%。通过设置 export NCCL_DEBUG=INFO,查看日志中是否出现[receive] via NET/IB/0/GDRDMA 和 [send] via NET/IB/0/GDRDMA,出现则说明启用 GDRDMA 成功,否则失败。


3、pytorch 数据并行是否采用 DistributedDataParallel ?
答:PyTorch 里的数据并行训练,涉及 nn.DataParallel (DP) 和nn.parallel.DistributedDataParallel (DDP) ,我们推荐使用 nn.parallel.DistributedDataParallel (DDP)。
标签:优化,利用率,data,tf,GPU,Dataset,数据,CPU From: https://www.cnblogs.com/chentiao/p/16661388.html