YUV视频格式到RGB32格式转换的速度优化 上篇
[email protected] 2007.10.30
tag: YUV,YCbCr,YUV到RGB颜色转换,YUV解码,VFW,视频,MMX,SSE,多核优化
摘要: 我们得到的很多视频数据(一些解码器的输出或者摄像头的输出等)都使用了一种
叫YUV的颜色格式;本文介绍了常见的YUV视频格式(YUY2/YVYU/UYVY/I420/YV12等)到
RGB颜色格式的转换,并尝试对转化的速度进行优化;
全文 分为:
《上篇》文章首先介绍了YUV颜色格式,并介绍了YUV颜色格式和RGB颜色格式之
间的相互转换;然后重点介绍了YUYV视频格式到RGB32格式的转化,并尝试进行了一
些速度优化;
《中篇》尝试使用MMX/SSE指令对前面实现的解码器核心进行速度优化;然
后简要介绍了一个使用这类CPU特殊指令时的代码框架,使得解码程序能够根据运行时
的CPU指令支持情况动态调用最佳的实现代码;并最终提供一个多核并行的优化版本;
《下篇》介绍YUV类型的其他种类繁多的视频数据编码格式;并将前面实现的解码
器核心(在不损失代码速度的前提下)进行必要的修改,使之适用于这些YUV视频格式
的解码;
(2010.11.23 color_table查询表扩大范围,以避免 color_table[Ye + csU_blue_16 * Ue ) >> 16 )]超界; 谢谢bug提交者 少浦.)
(2007.11.13 修正了一下颜色转换公式中的系数)
(2007.11.04 增加一个更深优化的全查表的实现DECODE_YUYV_TableEx;
对DECODE_YUYV_Common做了一点小的调整和改进)
正文:
代码使用C++,编译器:VC2005
涉及到汇编的时候假定为x86平台;
现在的高清视频帧尺寸越来越大,所以本文测试的图片大小将使用1024x576和
1920x1080两种常见的帧尺寸来测试解码器速度;
测试平台:(CPU:AMD64x2 4200+(2.37G); 内存:DDR2 677(双通道); 编译器:VC2005)
测试平台:(CPU:Intel Core2 4400(2.00G);内存:DDR2 667(双通道); 编译器:VC2005)
A:YUV颜色空间介绍,YUV颜色空间和RGB颜色空间的转换公式
YUV(或称为YCbCr)颜色空间中Y代表亮度,“U”和“V”表示的则是色度。
(这里假设YUV和RGB的颜色分量值都是无符号的8bit整数)
RGB颜色空间到YUV颜色空间的转换公式:
Y= 0.256788*R + 0.504129*G + 0.097906*B + 16;
U=-0.148223*R - 0.290993*G + 0.439216*B + 128;
V= 0.439216*R - 0.367788*G - 0.071427*B + 128;
YUV颜色空间到RGB颜色空间的转换公式:
B= 1.164383 * (Y - 16) + 2.017232*(U - 128);
G= 1.164383 * (Y - 16) - 0.391762*(U - 128) - 0.812968*(V - 128);
R= 1.164383 * (Y - 16) + 1.596027*(V - 128);
( 补充:
在视频格式中基本上都用的上面的转换公式;但在其他一些
地方可能会使用下面的转换公式(不同的使用场合可能有不同的转换系数):
Y = 0.299*R + 0.587*G + 0.114*B;
U = -0.147*R - 0.289*G + 0.436*B;
V = 0.615*R - 0.515*G - 0.100*B;
R = Y + 1.14*V;
G = Y - 0.39*U - 0.58*V;
B = Y + 2.03*U;
)
B.RGB32颜色和图片的数据定义:
typedef unsigned char TUInt8; // [0..255]
typedef unsigned long TUInt32;
struct TARGB32 // 32 bit color
{
TUInt8 b,g,r,a; // a is alpha
};
struct TPicRegion // 一块颜色数据区的描述,便于参数传递
{
TARGB32 * pdata; // 颜色数据首地址
long byte_width; // 一行数据的物理宽度(字节宽度);
// abs(byte_width)有可能大于等于width*sizeof(TARGB32);
long width; // 像素宽度
long height; // 像素高度
};
// 那么访问一个点的函数可以写为:
__forceinline TARGB32 & Pixels( const TPicRegion & pic, const long x, const long y)
{
return ( (TARGB32 * )((TUInt8 * )pic.pdata + pic.byte_width * y) )[x];
}
(注意:__forceinline表示总是内联代码,如果你的编译器不支持,请改写为inline关键词)
C.YUYV(也可以叫做YUY2)视频格式到RGB32的转化
(本文先集中优化YUYV视频格式到RGB32的转化,然后再扩展到其他视频格式)
YUYV视频格式的内存数据布局图示:
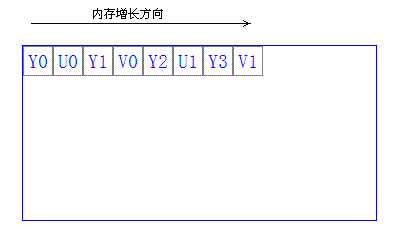
图中可以看出Y的数据量是U或者V的两倍,这是因为人的眼睛一般对亮度比对颜
色更敏感一些,所以将连续的两个像素的U(或V)值只保存一个U(或V)值,那么每个
像素平均占用16bit储存空间;
解码YUYV视频格式的一个简单浮点实现:
__forceinline long border_color( long color)
{
if (color > 255 )
return 255 ;
else if (color < 0 )
return 0 ;
else
return color;
}
__forceinline TARGB32 YUVToRGB32_float( const TUInt8 Y, const TUInt8 U, const TUInt8 V)
{
TARGB32 result;
result.b= border_color( 1.164383 * (Y - 16) + 2.017232*(U - 128) );
result.g= border_color( 1.164383 * (Y - 16) - 0.391762*(U - 128) - 0.812968*(V - 128) );
result.r= border_color( 1.164383 * (Y - 16) + 1.596027*(V - 128) );
result.a = 255 ;
return result;
}
void DECODE_YUYV_Float( const TUInt8 * pYUYV, const TPicRegion & DstPic)
{
assert((DstPic.width & 1 ) == 0 );
TARGB32 * pDstLine = DstPic.pdata;
for ( long y = 0 ;y < DstPic.height; ++ y)
{
for ( long x = 0 ;x < DstPic.width;x += 2 )
{
pDstLine[x + 0 ] = YUVToRGB32_float(pYUYV[ 0 ],pYUYV[ 1 ],pYUYV[ 3 ]);
pDstLine[x + 1 ] = YUVToRGB32_float(pYUYV[ 2 ],pYUYV[ 1 ],pYUYV[ 3 ]);
pYUYV += 4 ;
}
((TUInt8 *& )pDstLine) += DstPic.byte_width;
}
}
速度测试:
//==============================================================================
// | 1024x576 | 1920x1080 |
//------------------------------------------------------------------------------
// | AMD64x2 | Core2 | AMD64x2 | Core2 |
//------------------------------------------------------------------------------
//DECODE_YUYV_Float 55.0 FPS 63.7 FPS 15.6 FPS 18.0 FPS
D.使用整数运算(定点数运算)来代替浮点运算
默认的浮点数到整数的转换是比较慢的运算;这里用整数运算来代替浮点运算;
使用16位定点数,原理是将浮点系数扩大2^16倍,并保存为整数(引入很小的误差),那么计算出来的值
再除以2^16就得到正确的结果了,而除以2^16可以优化为带符号的右移; 代码如下:
const int csU_blue_16 = 2.017232*(1<<16);
const int csU_green_16 = (-0.391762)*(1<<16);
const int csV_green_16 = (-0.812968)*(1<<16);
const int csV_red_16 = 1.596027*(1<<16);
__forceinline TARGB32 YUVToRGB32_Int( const TUInt8 Y, const TUInt8 U, const TUInt8 V)
{
TARGB32 result;
int Ye = csY_coeff_16 * (Y - 16 );
int Ue = U - 128 ;
int Ve = V - 128 ;
result.b = border_color( ( Ye + csU_blue_16 * Ue ) >> 16 );
result.g = border_color( ( Ye + csU_green_16 * Ue + csV_green_16 * Ve ) >> 16 );
result.r = border_color( ( Ye + csV_red_16 * Ve ) >> 16 );
result.a = 255 ;
return result;
}
void DECODE_YUYV_Int( const TUInt8 * pYUYV, const TPicRegion & DstPic)
{
assert((DstPic.width & 1 ) == 0 );
TARGB32 * pDstLine = DstPic.pdata;
for ( long y = 0 ;y < DstPic.height; ++ y)
{
for ( long x = 0 ;x < DstPic.width;x += 2 )
{
pDstLine[x + 0 ] = YUVToRGB32_Int(pYUYV[ 0 ],pYUYV[ 1 ],pYUYV[ 3 ]);
pDstLine[x + 1 ] = YUVToRGB32_Int(pYUYV[ 2 ],pYUYV[ 1 ],pYUYV[ 3 ]);
pYUYV += 4 ;
}
((TUInt8 *& )pDstLine) += DstPic.byte_width;
}
}
速度测试:
//==============================================================================
// | 1024x576 | 1920x1080 |
//------------------------------------------------------------------------------
// | AMD64x2 | Core2 | AMD64x2 | Core2 |
//------------------------------------------------------------------------------
//DECODE_YUYV_Int 137.1 FPS 131.9 FPS 39.0 FPS 37.1 FPS
E.优化border_color颜色饱和函数
因为border_color的实现使用了分支代码,在现代CPU上分支预测错的代价很大,这里使用一个
查找表来代替它;
static TUInt8 _color_table[ 256 * 5 ];
static const TUInt8 * color_table =& _color_table[ 256 *2];
class _CAuto_inti_color_table
{
public :
_CAuto_inti_color_table() {
for ( int i = 0 ;i < 256 *5 ; ++ i)
_color_table[i] = border_color(i - 256*2 );
}
};
static _CAuto_inti_color_table _Auto_inti_color_table;
__forceinline TARGB32 YUVToRGB32_RGBTable( const TUInt8 Y, const TUInt8 U, const TUInt8 V)
{
TARGB32 result;
int Ye = csY_coeff_16 * (Y - 16 );
int Ue = U - 128 ;
int Ve = V - 128 ;
result.b = color_table[ ( Ye + csU_blue_16 * Ue ) >> 16 ];
result.g = color_table[ ( Ye + csU_green_16 * Ue + csV_green_16 * Ve ) >> 16 ];
result.r = color_table[ ( Ye + csV_red_16 * Ve ) >> 16 ];
result.a = 255 ;
return result;
}
void DECODE_YUYV_RGBTable( const TUInt8 * pYUYV, const TPicRegion & DstPic)
{
assert((DstPic.width & 1 ) == 0 );
TARGB32 * pDstLine = DstPic.pdata;
for ( long y = 0 ;y < DstPic.height; ++ y)
{
for ( long x = 0 ;x < DstPic.width;x += 2 )
{
pDstLine[x + 0 ] = YUVToRGB32_RGBTable(pYUYV[ 0 ],pYUYV[ 1 ],pYUYV[ 3 ]);
pDstLine[x + 1 ] = YUVToRGB32_RGBTable(pYUYV[ 2 ],pYUYV[ 1 ],pYUYV[ 3 ]);
pYUYV += 4 ;
}
((TUInt8 *& )pDstLine) += DstPic.byte_width;
}
}
速度测试:
//==============================================================================
// | 1024x576 | 1920x1080 |
//------------------------------------------------------------------------------
// | AMD64x2 | Core2 | AMD64x2 | Core2 |
//------------------------------------------------------------------------------
//DECODE_YUYV_RGBTable 164.8 FPS 152.9 FPS 47.1 FPS 43.7 FPS
F.使用查找表来代乘法运算
其实,现在的x86 CPU做乘法是很快的,用查找表的内存访问来代替乘法不见得会更快;
本文章讨论它的意义在于,该实现版本在其他平台的CPU上可能有很好的优化效果;在奔腾4上
该版本DECODE_YUYV_Table也很可能比DECODE_YUYV_RGBTable快,我没有测试过;
static int Um_blue_table[ 256 ];
static int Um_green_table[ 256 ];
static int Vm_green_table[ 256 ];
static int Vm_red_table[ 256 ];
class _CAuto_inti_yuv_table
{
public :
_CAuto_inti_yuv_table() {
for ( int i = 0 ;i < 256 ; ++ i)
{
Ym_table[i] = csY_coeff_16 * (i - 16 );
Um_blue_table[i] = csU_blue_16 * (i - 128 );
Um_green_table[i] = csU_green_16 * (i - 128 );
Vm_green_table[i] = csV_green_16 * (i - 128 );
Vm_red_table[i] = csV_red_16 * (i - 128 );
}
}
};
static _CAuto_inti_yuv_table _Auto_inti_yuv_table;
__forceinline TARGB32 YUVToRGB32_Table( const TUInt8 Y, const TUInt8 U, const TUInt8 V)
{
TARGB32 result;
int Ye = Ym_table[Y];
result.b = color_table[ ( Ye + Um_blue_table[U] ) >> 16 ];
result.g = color_table[ ( Ye + Um_green_table[U] + Vm_green_table[V] ) >> 16 ];
result.r = color_table[ ( Ye + Vm_red_table[V] ) >> 16 ];
result.a = 255 ;
return result;
}
void DECODE_YUYV_Table( const TUInt8 * pYUYV, const TPicRegion & DstPic)
{
assert((DstPic.width & 1 ) == 0 );
TARGB32 * pDstLine = DstPic.pdata;
for ( long y = 0 ;y < DstPic.height; ++ y)
{
for ( long x = 0 ;x < DstPic.width;x += 2 )
{
pDstLine[x + 0 ] = YUVToRGB32_Table(pYUYV[ 0 ],pYUYV[ 1 ],pYUYV[ 3 ]);
pDstLine[x + 1 ] = YUVToRGB32_Table(pYUYV[ 2 ],pYUYV[ 1 ],pYUYV[ 3 ]);
pYUYV += 4 ;
}
((TUInt8 *& )pDstLine) += DstPic.byte_width;
}
}
速度测试:
//==============================================================================
// | 1024x576 | 1920x1080 |
//------------------------------------------------------------------------------
// | AMD64x2 | Core2 | AMD64x2 | Core2 |
//------------------------------------------------------------------------------
//DECODE_YUYV_Table 146.1 FPS 151.3 FPS 41.8 FPS 43.5 FPS
(提示:在没有“带符号右移”的CPU体系下或者能够忍受一点点小的误差,可以在生成YUV的查找表的时候不扩大2^16倍,从而在计算出结果的时候也就不需要右移16位的修正了,这样改进后函数速度还会提高一些)
2007.11.04 补充一个更深优化的全查表的实现DECODE_YUYV_TableEx;
// 全查表static int Ym_tableEx[ 256 ];
static int Um_blue_tableEx[ 256 ];
static int Um_green_tableEx[ 256 ];
static int Vm_green_tableEx[ 256 ];
static int Vm_red_tableEx[ 256 ];
class _CAuto_inti_yuv_tableEx
{
public :
_CAuto_inti_yuv_tableEx() {
for ( int i = 0 ;i < 256 ; ++ i)
{
Ym_tableEx[i] = (csY_coeff_16 * (i - 16 ) ) >> 16 ;
Um_blue_tableEx[i] = (csU_blue_16 * (i - 128 ) ) >> 16 ;
Um_green_tableEx[i] = (csU_green_16 * (i - 128 ) ) >> 16 ;
Vm_green_tableEx[i] = (csV_green_16 * (i - 128 ) ) >> 16 ;
Vm_red_tableEx[i] = (csV_red_16 * (i - 128 ) ) >> 16 ;
}
}
};
static _CAuto_inti_yuv_tableEx _Auto_inti_yuv_tableEx;
__forceinline void YUVToRGB32_Two_TableEx(TARGB32 * pDst, const TUInt8 Y0, const TUInt8 Y1, const TUInt8 U, const TUInt8 V)
{
int Ye0 = Ym_tableEx[Y0];
int Ye1 = Ym_tableEx[Y1];
int Ue_blue = Um_blue_tableEx[U];
int Ue_green = Um_green_tableEx[U];
int Ve_green = Vm_green_tableEx[V];
int Ve_red = Vm_red_tableEx[V];
int UeVe_green = Ue_green + Ve_green;
((TUInt32 * )pDst)[ 0 ] = color_table[ ( Ye0 + Ue_blue ) ]
| ( color_table[ ( Ye0 + UeVe_green )] << 8 )
| ( color_table[ ( Ye0 + Ve_red )] << 16 )
| ( 255 << 24 );
((TUInt32 * )pDst)[ 1 ] = color_table[ ( Ye1 + Ue_blue ) ]
| ( color_table[ ( Ye1 + UeVe_green )] << 8 )
| ( color_table[ ( Ye1 + Ve_red )] << 16 )
| ( 255 << 24 );
}
void DECODE_YUYV_TableEx_line(TARGB32 * pDstLine, const TUInt8 * pYUYV, long width)
{
for ( long x = 0 ;x < width;x += 2 )
{
YUVToRGB32_Two_TableEx( & pDstLine[x],pYUYV[ 0 ],pYUYV[ 2 ],pYUYV[ 1 ],pYUYV[ 3 ]);
pYUYV += 4 ;
}
}
void DECODE_YUYV_TableEx( const TUInt8 * pYUYV, const TPicRegion & DstPic)
{
assert((DstPic.width & 1 ) == 0 );
long YUV_byte_width = (DstPic.width >> 1 ) << 2 ;
TARGB32 * pDstLine = DstPic.pdata;
for ( long y = 0 ;y < DstPic.height; ++ y)
{
DECODE_YUYV_TableEx_line(pDstLine,pYUYV,DstPic.width);
pYUYV += YUV_byte_width;
((TUInt8 *& )pDstLine) += DstPic.byte_width;
}
}
速度测试:
//==============================================================================
// | 1024x576 | 1920x1080 |
//------------------------------------------------------------------------------
// | AMD64x2 | Core2 | AMD64x2 | Core2 |
//------------------------------------------------------------------------------
//DECODE_YUYV_TableEx 236.5 FPS 300.5 FPS 68.1 FPS 85.0 FPS
G.优化U和V的计算、合并写内存
由于两个像素共享U和V值,关于它们的两次计算,有部分代码可以共享;
所以实现一个一次转换两个像素的版本;
写内存的时候,合并成4字节来写,这样在现在的CPU上更加有效率(注意:在intel的
Xeon CPU上这个改动反而会慢一些):
{
int Ye0 = csY_coeff_16 * (Y0 - 16 );
int Ye1 = csY_coeff_16 * (Y1 - 16 );
int Ue = (U - 128 );
int Ue_blue = csU_blue_16 * Ue;
int Ue_green = csU_green_16 * Ue;
int Ve = (V - 128 );
int Ve_green = csV_green_16 * Ve;
int Ve_red = csV_red_16 * Ve;
int UeVe_green = Ue_green + Ve_green;
((TUInt32 * )pDst)[ 0 ] = color_table[ ( Ye0 + Ue_blue ) >> 16 ]
| ( color_table[ ( Ye0 + UeVe_green ) >> 16 ] << 8 )
| ( color_table[ ( Ye0 + Ve_red ) >> 16 ] << 16 )
| ( 255 << 24 );
((TUInt32 * )pDst)[ 1 ] = color_table[ ( Ye1 + Ue_blue ) >> 16 ]
| ( color_table[ ( Ye1 + UeVe_green ) >> 16 ] << 8 )
| ( color_table[ ( Ye1 + Ve_red ) >> 16 ] << 16 )
| ( 255 << 24 );
}
void DECODE_YUYV_Common_line(TARGB32 * pDstLine, const TUInt8 * pYUYV, long width)
{
for ( long x = 0 ;x < width;x += 2 )
{
YUVToRGB32_Two( & pDstLine[x],pYUYV[ 0 ],pYUYV[ 2 ],pYUYV[ 1 ],pYUYV[ 3 ]);
pYUYV += 4 ;
}
}
void DECODE_YUYV_Common( const TUInt8 * pYUYV, const TPicRegion & DstPic)
{
assert((DstPic.width & 1 ) == 0 );
long YUV_byte_width = (DstPic.width >> 1 ) << 2 ;
TARGB32 * pDstLine = DstPic.pdata;
for ( long y = 0 ;y < DstPic.height; ++ y)
{
DECODE_YUYV_Common_line(pDstLine,pYUYV,DstPic.width);
pYUYV += YUV_byte_width;
((TUInt8 *& )pDstLine) += DstPic.byte_width;
}
}
速度测试:
//==============================================================================
// | 1024x576 | 1920x1080 |
//------------------------------------------------------------------------------
// | AMD64x2 | Core2 | AMD64x2 | Core2 |
//------------------------------------------------------------------------------
//DECODE_YUYV_Common 250.7 FPS 287.1 FPS 71.9 FPS 80.7 FPS
H:把测试成绩放在一起
//测试平台:(CPU:AMD64x2 4200+(2.37G); 内存:DDR2 677(双通道); 编译器:VC2005)
//测试平台:(CPU:Intel Core2 4400(2.00G);内存:DDR2 667(双通道); 编译器:VC2005)
//==============================================================================
// | 1024x576 | 1920x1080 |
//------------------------------------------------------------------------------
// | AMD64x2 | Core2 | AMD64x2 | Core2 |
//------------------------------------------------------------------------------
//DECODE_YUYV_Float 55.0 FPS 63.7 FPS 15.6 FPS 18.0 FPS
//DECODE_YUYV_Int 137.1 FPS 131.9 FPS 39.0 FPS 37.1 FPS
//DECODE_YUYV_RGBTable 164.8 FPS 152.9 FPS 47.1 FPS 43.7 FPS
//DECODE_YUYV_Table 146.1 FPS 151.3 FPS 41.8 FPS 43.5 FPS
//DECODE_YUYV_TableEx 236.5 FPS 300.5 FPS 68.1 FPS 85.0 FPS
//DECODE_YUYV_Common 250.7 FPS 287.1 FPS 71.9 FPS 80.7 FPS