问题:现有联邦学习研究集中在提高模型精度和完成时间-------准确率与效率,即又快又好。然而实际中客户不愿意投入到无回报的FL中。
1前言:机器学习的不足->引出联邦学习->联邦学习面临的挑战,由于这些挑战,引出文章想要强调的事:客户愿意参加FL的前提是能够获得足够的回报。->引出激励机制
引入激励机制的原因:
1、参与FL给参与方带来计算资源的消耗、网络带宽的占用和电池寿命的缩短,充分的奖励可以激励它们容忍这些代价并做出贡献。
2、只有参与方自己才能决定自己何时何地以及如何参与FL。
激励机制面临的两个挑战
1、如何评估每个客户端的贡献
来自服务器视角的挑战:如何通过提供最小的奖励来获得更高的学习性能是一个挑战(大农场主不给草吃硬挤奶)
2、如何招募和留住更多的客户
来自客户端视角的挑战:如何提供公平、有利可图和安全的学习机会,以获得足够的客户参与
2背景
联邦学习:人工智能面临数据孤岛挑战》联邦学习被提出》联邦学习的训练流程原理
激励机制
3基于客户数据贡献
通过客户贡献设计激励机制归纳两类:数据数量和数据质量

数据质量:
《29,Collaborative machine learning with incentive-aware model rewards》基于Shapley值设计一个激励感知的奖励方案,给每个客户一个定制的机器学习模型作为奖励,而不是货币补偿,不能直接应用FL
《19,Profit allocation for federated learning》提出了一种基于Shapley值的有效度量,称为贡献指数,通过联邦学习的中间结果,在不同的训练数据集组合上近似重构模型,以避免额外的训练。
《22,Fmore: An incentive scheme of multi-dimensional auction for federated learning in mec》考虑了联邦学习中的多维动态边缘资源,提出了一种新的联邦学习多维激励框架。利用博弈论推导出每个客户的最优策略,并利用期望效用引导参数服务器选择最优客户来训练机器学习模型
《21,Hierarchical incentive mechanism design for federated machine learning in mobile networks》提出了一种基于联邦学习的PrivacyProfection方法,提出了一种多客户场景下的分层激励机制体系结构。 他们利用契约理论建立了客户和用户之间的激励机制,并利用联盟博弈理论根据客户的边际贡献对其进行奖励。 通过逆向归纳法,先求解契约制定问题,再求解条件博弈问题。
《20,A sustainable incentive scheme for federated learning》提出了一种公平的激励方案&联邦学习激励器(FLI),以避免联邦学习训练过程中的不公平待遇。 FLI可以根据三个标准动态调整客户的贡献,以使贡献与奖励相匹配
数据数量:
《26,Deepchain: Auditable and privacy-preserving deep learning with blockchain-based incentive》设计客户端共同参与深度学习模型训练的协同训练框架。
《27,FLchain: A blockchain for auditable federated learning with trust and incentive》提出FLChain来构建一个分散的、可公开审计的、健康的、有信任和激励的联邦学习生态系统。 在FLChain中,诚实的客户可以根据自己的贡献通过一个经过训练的模型获得公平分配的利润,恶意的客户可以被及时发现并受到严厉的惩罚

4基于客户声誉

作者:反向人
链接:https://zhuanlan.zhihu.com/p/595679334
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
《30,Mobile edge computing, blockchain and reputation-based crowdsourcing iot federated learning: A secure, decentralized and privacy-preserving system》一个基于区块链的信誉系统,一开始每个客户信誉值相同,贡献正确有用的模型参数信誉值增加,上传恶意参数信誉值减小,声誉高的客户下一轮训练更容易被选到
《31,Towards blockchain-based reputation-aware federated learning》提出了一个基于区块链的信誉系统,在该系统中,边缘设备、雾节点和云服务器这三种参与者可以相互评分。具体来说,边缘设备在向雾节点和云服务器请求模型参数后,可以对它们进行分级。 同样,FOG节点可以根据数据丰富度、上下文感知度等对连接的边缘设备进行分级,云服务器可以根据参与度、共享意愿等对FOG节点和边缘设备进行分级,系统通过智能合约对联邦学习中每个参与者的声誉进行聚合、计算和记录。
但是,评分机制过于主观,缺乏质量评价方案;每个参与者只有一个分数容易受到恶意评分
所以《32,Reliable federated learning for mobile networks》提出了一个基于区块链的可靠联邦学习信誉系统。对于每一个客户机,为了将所有任务发布者给出的不同评分进行组合和关联,它的综合信誉值将由一个多权重主观逻辑模型产生。

5基于客户资源
两种资源分配:计算资源和通信资源

计算资源:
《36,Motivating workers in federated learning: A stackelberg game perspective》提出了一种激励机制来平衡每次迭代的时延。参数服务器具有有限的预算,并在客户端之间分配其预算,以激励它们贡献其CPU功率,并以目标精度实现快速收敛。
《37,Federated learning for edge networks:Resource optimization and incentive mechanism》提出了一个Stackelberg博弈,通过优化客户端之间的计算资源分配策略和参数服务器的预算分配来提高其性能。还利用Stackelberg博弈制定激励机制,激励客户参与联邦学习
《39,An incentive mechanism design for efficient edge learning by deep reinforcement learning》提出了一种基于DRL的激励机制设计方法,并在动态网络环境下寻找模型训练时间和参数服务器支付之间的最优折衷
通信资源:
《40,An incentive mechanism for federated learning in wireless cellular network: An auction approach,》将基站和客户端之间的激励机制设计为一个拍卖博弈,其中基站是拍卖者,客户端是卖方。客户端希望能量消耗小,基站希望社会福利最大化。提出了一种原始-对偶贪心算法来解决NP难问题。
《38,A crowdsourcing framework for on-device federated learning》通过构建一个考虑模型参数交换过程中通信效率的通信效率成本模型,提出了一个新的众包平台,采用两阶段Stackelberg博弈方法求解初始对偶优化问题,其中每一方都使自己的利益最大化。

作者:反向人
链接:https://zhuanlan.zhihu.com/p/595679334
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
6未来方向
1、多方联邦学习
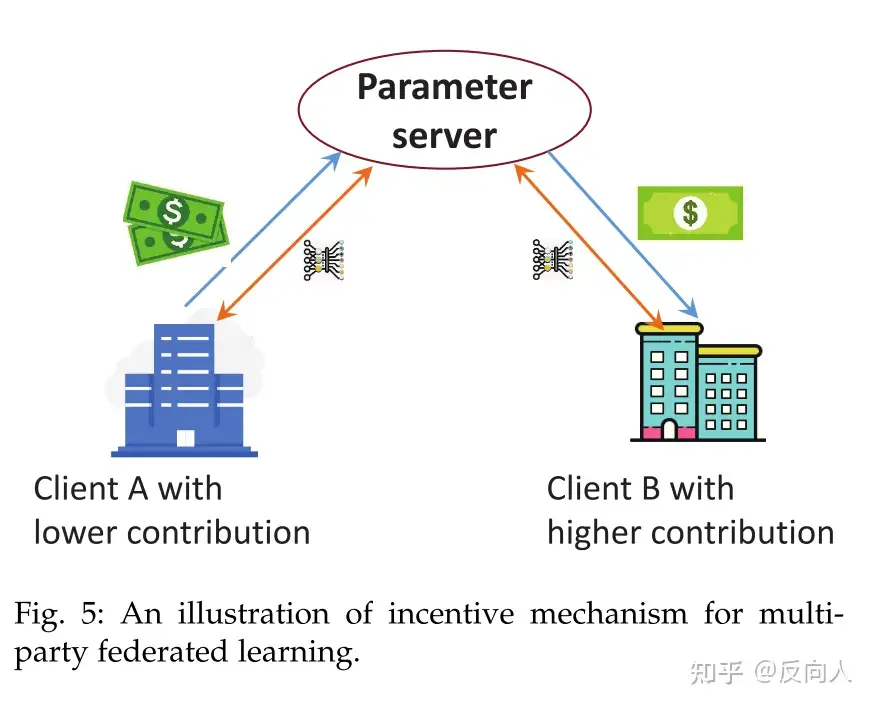
当各方相互竞争时,其他竞争者可以从自身贡献中收益,客户可能不愿意参与联邦学习,俗称不想被别人白嫖,还想白嫖别人。
激励机制是这种竞争+合作关系的解决方案之一
2、激励驱动联邦学习
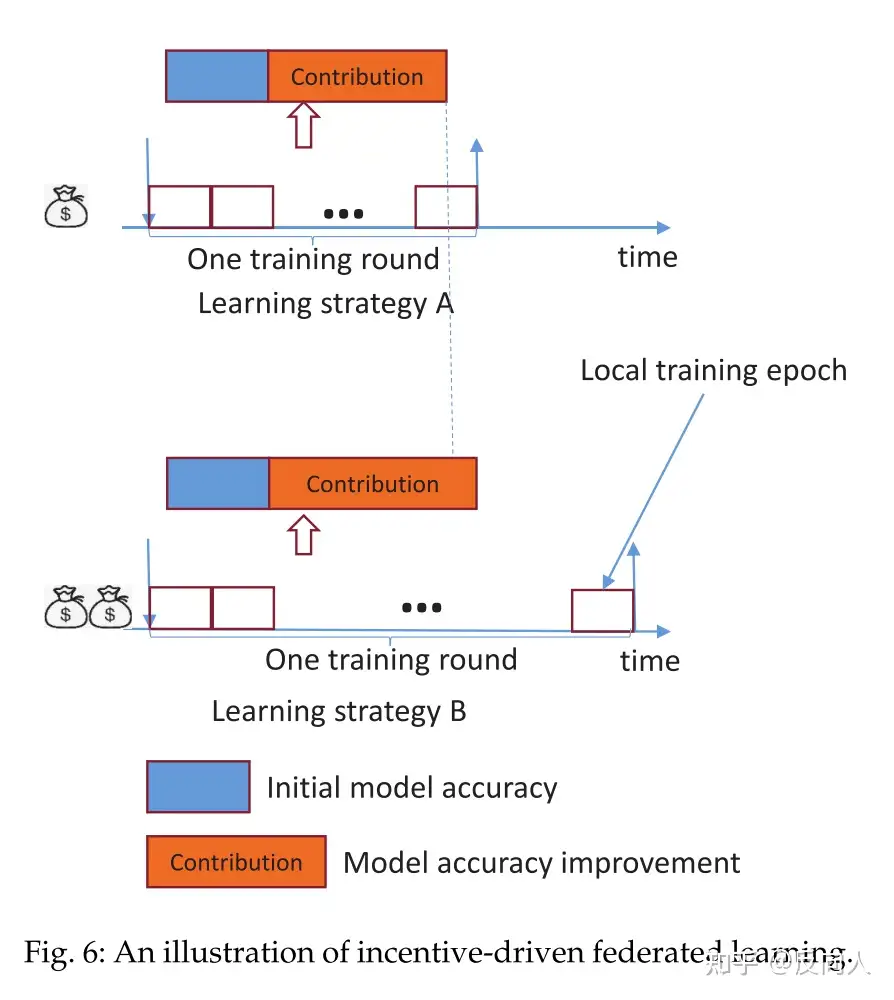
没有真正与联邦学习算法相结合
通过控制局部历元的数目来调整联邦学习算法。 在学习策略A中,参数服务器在每一轮训练中给客户端的资金较少,客户端用较少的局部时间训练局部机器学习模型,获得较少的模型精度提高。
在学习策略B中,参数服务器在每一轮训练中给客户端更多的资金,驱动他们训练具有更多局部时间的机器学习模型,使模型的精度得到更高的提高。
很难判断学习策略A是否优于学习策略B,如何用激励驱动的方法谨慎地控制局部纪元的数量不仅是困难的,也是具有挑战性的。
3、安全联邦学习
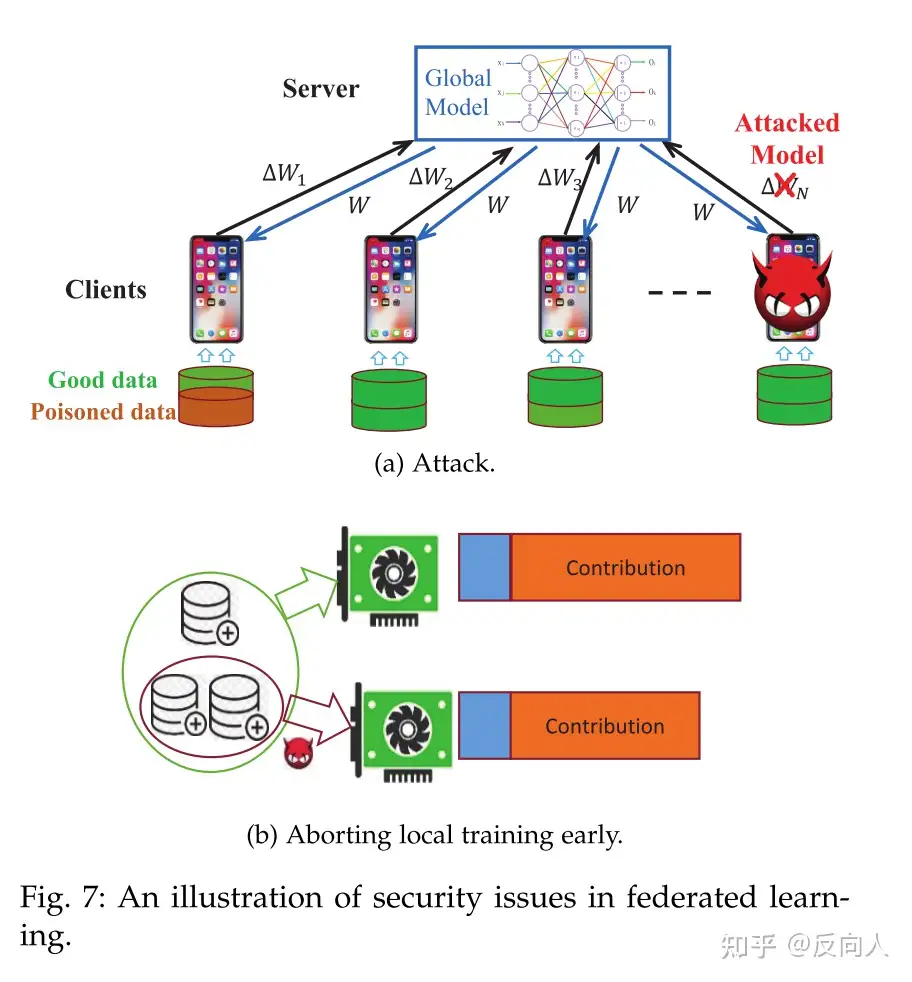
a中,产生不正确梯度的方法有两种:一种是在训练数据中注入中毒数据,另一种是上传中毒模型。 有了这两种攻击,联邦学习就会产生偏差。
b中,客户端可以用较少的训练数据训练本地机器学习模型,从而提前中止本地训练。 这样,客户对联邦学习系统的贡献就会减少
通过激励机制可以惩罚恶意客户,从而降低其作恶的概率。 比如声誉系统,对模型有负面影响声誉就降低,声誉过低就禁止参加联邦学习
标签:Learning,08,Mechanism,学习,learning,联邦,amp,data,客户端 From: https://www.cnblogs.com/2506406916zhy/p/17119162.html