目录
GPT系列
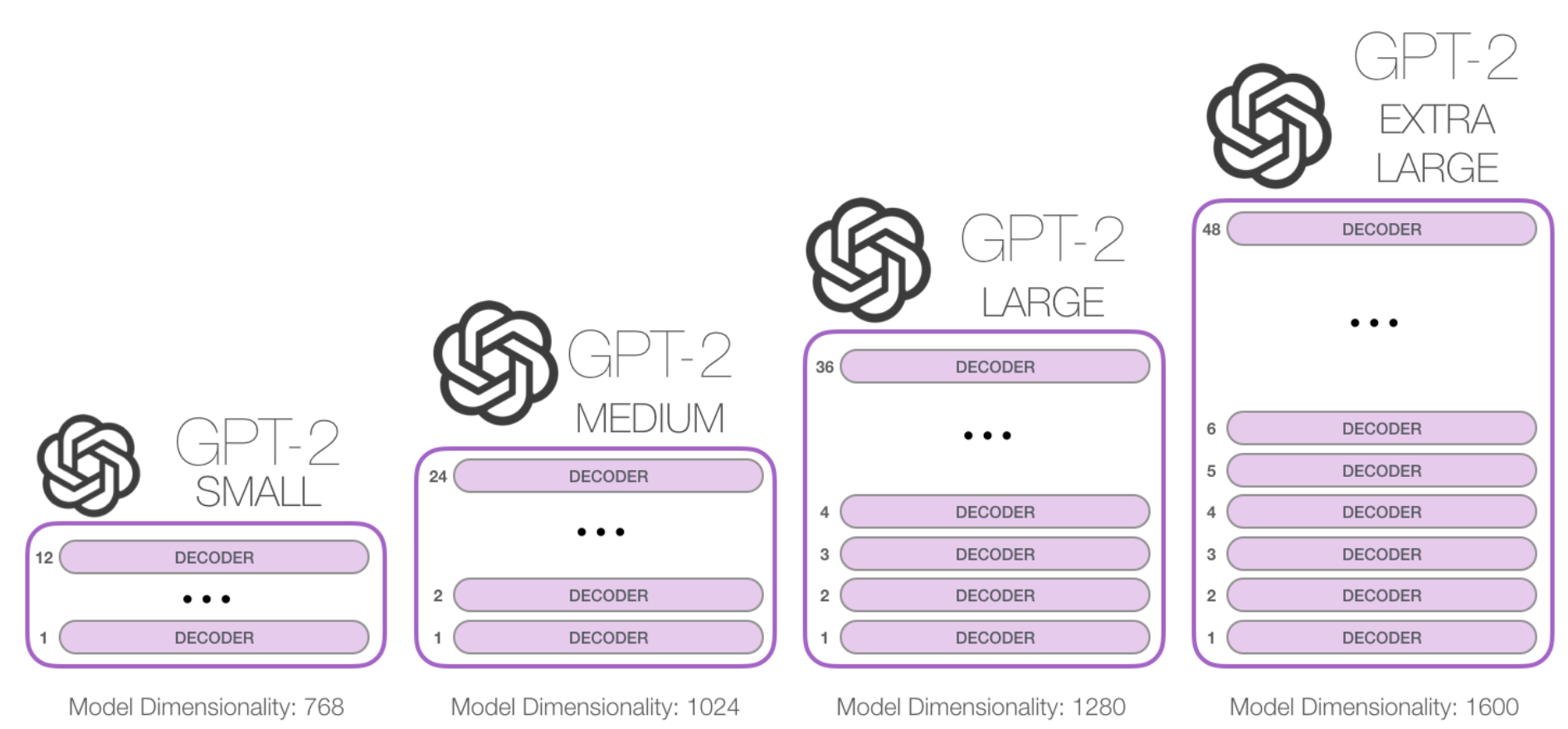
GPT2
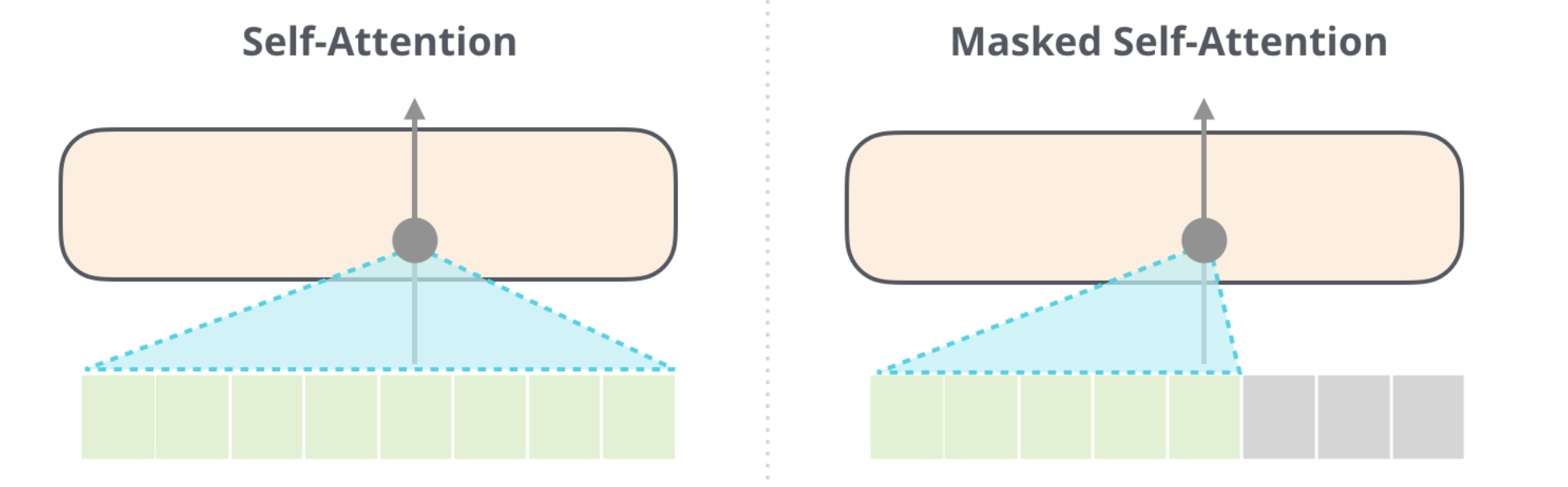
The GPT-2 is built using transformer decoder blocks. BERT, on the other hand, uses transformer encoder blocks.
auto-regressive: outputs one token at a time

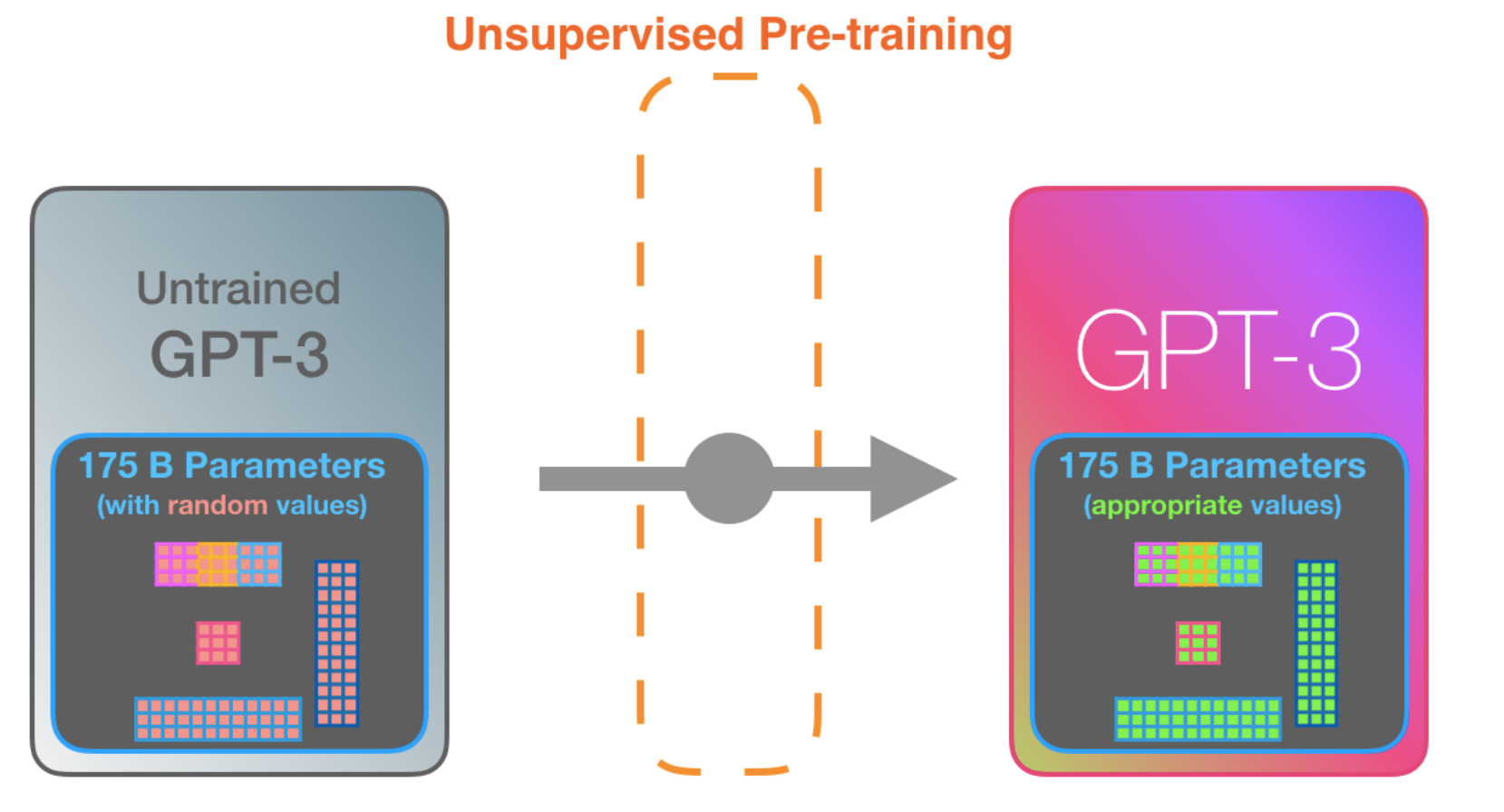
GPT3
96 transformer decoder layers. Each of these layers has its own 1.8B parameter
The difference with GPT3 is the alternating dense and sparse self-attention layers.
InstructGPT
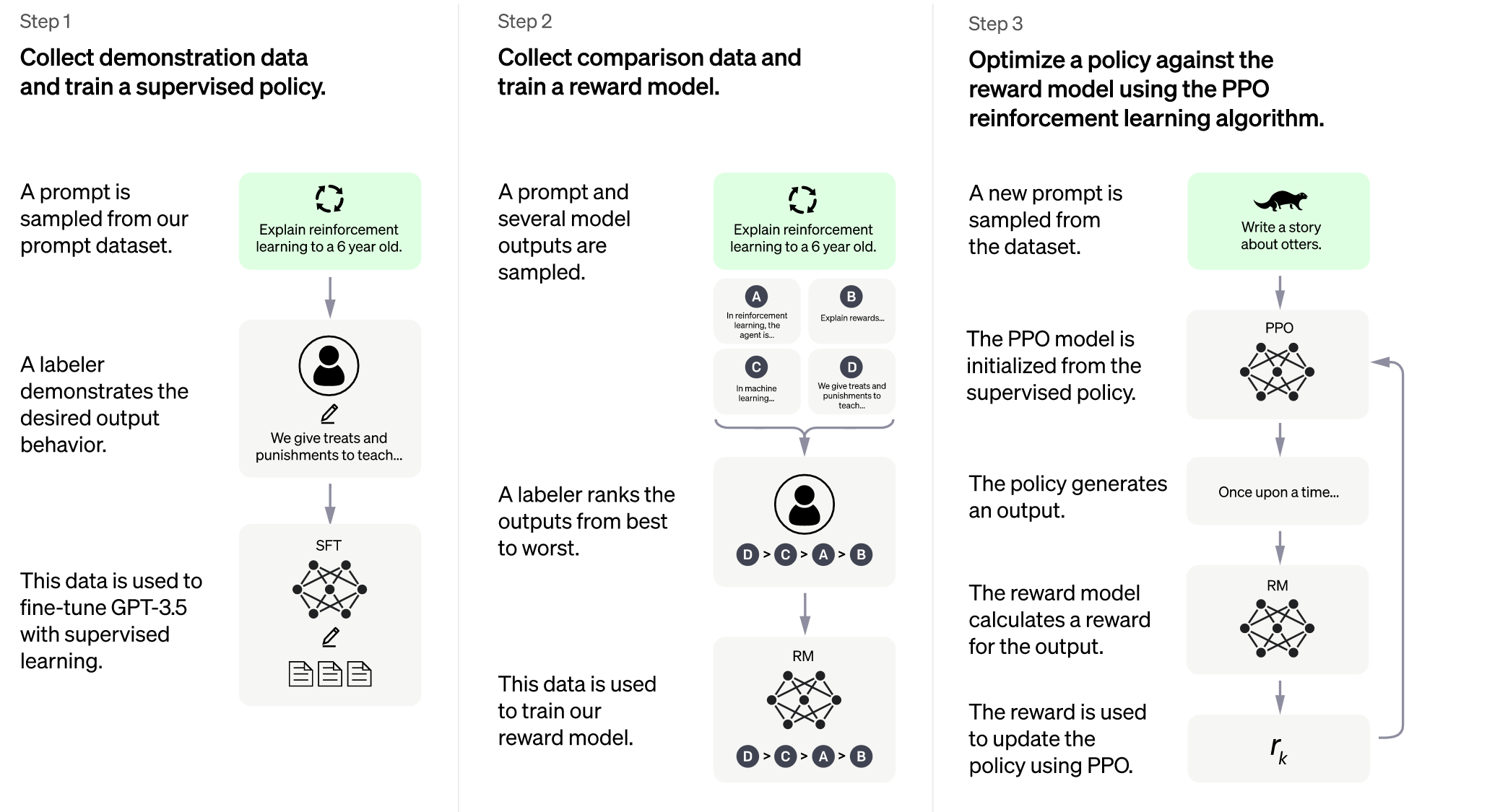
Step 1: Collect demonstration data, and train a supervised policy. Our labelers provide demonstrations of the desired behavior on the input prompt distribution (see Section 3.2 for details on this distribution). We then fine-tune a pretrained GPT-3 model on this data using supervised learning.
Step 2: Collect comparison data, and train a reward model. We collect a dataset of comparisons between model outputs, where labelers indicate which output they prefer for a given input. We then train a reward model to predict the human-preferred output.
Step 3: Optimize a policy against the reward model using PPO. We use the output of the RM as a scalar reward. We fine-tune the supervised policy to optimize this reward using the PPO algorithm (Schulman et al., 2017).
Steps 2 and 3 can be iterated continuously; more comparison data is collected on the current best policy, which is used to train a new RM and then a new policy. In practice, most of our comparison data comes from our supervised policies, with some coming from our PPO policies.
SFT: input prompt,output response
RM:input prompt and response, and output a scalar reward,即指定prompt,给response打分
RL:使用PPO微调SFT,RM作为值函数
chatGPT
We trained this model using Reinforcement Learning from Human Feedback (RLHF), using the same methods as InstructGPT, but with slight differences in the data collection setup.
sparrow[类chatgpt]
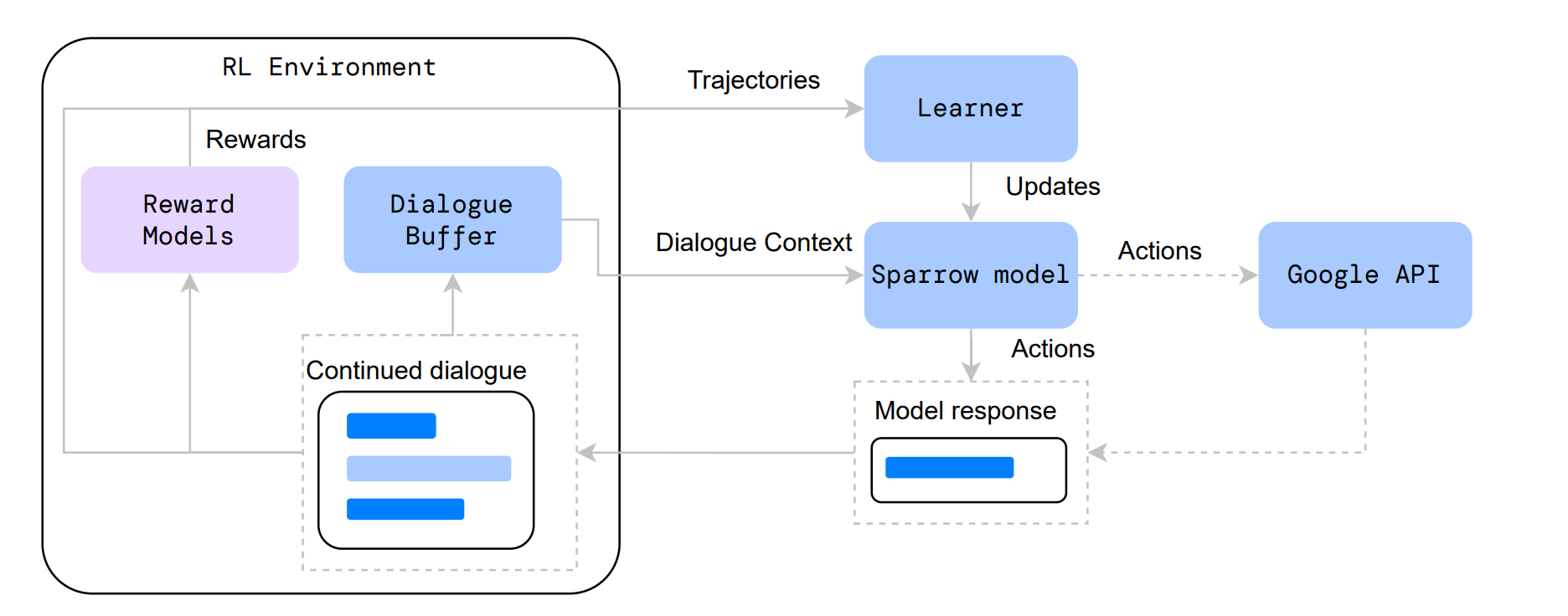
references
https://jalammar.github.io/illustrated-gpt2/
https://openai.com/blog/chatgpt/
Sparrow. https://www.deepmind.com/blog/building-safer-dialogue-agents
标签:系列,policy,简记,GPT,using,model,reward,data From: https://www.cnblogs.com/gongyanzh/p/17099006.html