目录
给自己挖个坑,这些都是工程上需要掌握的知识。
模型压缩
将高精度数据转为低精度格式,可以加快运算速度,同时也会降低网络推理的精度。
一般来说会将数据从浮点型转为int8型,有时会转为int16型。
量化后可以重新训练,恢复部分精度。
基于MNN的训练量化实现过程可以参考这篇博客
量化
稀疏化训练
剪枝
知识蒸馏
自蒸馏
集成
使用精细化模型结构
模型扩张
深度
宽度
输入图像的分辨率
深度、宽度、分辨率联合扩张
使用精细化模型结构
计算模型的各种成本
torchsummary是个不错的库,可以使用它查看网络结构、参数量和模型大小等信息。目前我发现的不足是无法支持LSTM(但是可以支持GRU)。这里使用之前写的AlexNet举个例子。
首先导入库,然后加载模型,最后使用summary函数并指定输入大小。
import models
from torchsummary import summary
model = models.AlexNet(outputdim=1000)
summary(model,(3,224,224))
输出如下

参数量
在打印出来的网络结构下面的三行,这些参数是通过其上方打印出来的网络结构右侧各层的参数量相加得到的。

-
Total params: 共计参数量
-
Trainable params: 可训练参数量
-
Non-trainable params: 不可训练参数量
各种操作的参数量计算方法
-
卷积参数量:(kernel_width * kernel_height * input_channels + bias_num) * output_channels PS:如果没有bias则bias_num为0,有bias则bias_num为1
-
全连接层参数量:(input_params + bias_num) * output_params PS:同上
占用空间
在打印出的信息的最后四行。
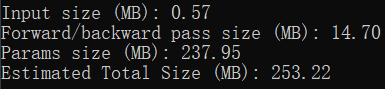
-
Input size (MB): 使用torchsummary时喂进去的输入大小。一般来说输入的batch_size默认为1,所以这里呈现的就是一份输入的大小。 Input size = input_datas * 4 / 1024 / 1024 PS:乘4是因为默认数据格式是float32,占4字节,除以两次1024是将Byte转为MB
-
Forward/backward pass size (MB): 网络中所有输出的大小(打印出来的网络结构中的output shape中的输出大小)的和的两倍(一次前向,一次反向)。这个数值的具体含义我目前还没有理解透彻。 PS:同样需要乘4、除以两次1024
-
Params size (MB): 上文中计算出来的总参数量的大小。 Params size = Total_params * 4 / 1024 / 1024 PS:同样需要乘4、除以两次1024
Estimated Total Size (MB): 总大小。
如果使用 ↓ 来保存模型(只保存参数),保存出来的模型大小与 Params size 几乎相同。
torch.save(model.state_dict(), 'trainedModels/test.pth')
计算量(FLOPS、FLOPs)
FLOPS
每秒浮点运算次数。一般来说硬件的FLOPS以T或P来评估。
不同硬件的FLOPS可以直接查到或根据其核心频率计算得到。
FLOPs
浮点运算数、模型计算量。
-
卷积:FLOPs = kernel_width * kernel_height * input_channels * output_width * output_height * output_channels
-
池化:FLOPs = kernel_width * kernel_height * output_width * output_height * output_channels
-
全局池化:FLOPs = input_width * intput_height * intput_channels
-
深度可分离卷积:FLOPs = input_channels * output_width * output_height * (kernel_width * kernel_height + output_channels)
-
ReLU:FLOPs = input_width * intput_height * intput_channels
-
Sigmoid:FLOPs = input_width * intput_height * intput_channels * 4
-
全连接:FLOPs = (input_channels * 2 + 1) * output_channels
-
BatchNormalization:FLOPs可以忽略,因为推理时没有用到
以上计算公式参考了这篇知乎。
从卷积的FLOPs计算公式中可以应证在Efficientnet那篇论文中提到的
将深度扩大两倍,FLOPs会扩大两倍。但是将宽度或输入图像的分辨率扩大两倍,FLOPs会扩大四倍。
同样的,如果我们减小一半深度,FLOPs会减小一半;减小一半宽度或输入图像的分辨率,FLOPs会减小四分之一。
使用thop库可以查看FLOPs和总参数量。 用下面的代码把summary和thop的输出做一个对比。
import models
from torchsummary import summary
import torch
from thop import profile
model = models.AlexNet(outputdim=1000)
summary(model,(3,224,224))
input = torch.randn(1,3,224,224)
flops, params = profile(model, (input,))
print("flops = ", flops)
print("params = ", params)

从输出可以看到,两个库计算得到的参数量是一致的,thop计算得到的FLOPs大概为1.1million左右,换算过来也就是1.058G左右。
但是网上公布的AlexNet的FLOPs约为0.7G左右,这是因为他们计算的是论文原文中的那种并行的AlexNet结构,其使用了两块显卡进行计算,因此大家计算FLOPs时计算的是一张卡上的计算量。
运行时占用内存
这个不太好计算,我目前还没有找到实用的计算方法。
最好的方法还是运行一下然后实时监控内存占用情况。
推理速度
网络的推理速度受以下因素影响:
- 推理之外的文件读写操作,如数据的读取和预处理。(这个其实不算在推理速度里。。。但是对程序运行速度有关,所以我列了出来)
- 模型的后处理操作,这些操作可能没有用到GPU而是在CPU上进行运算的。
- 推理时的计算量,也就是FLOPs。
- GPU的显存带宽,FLOPs少但是显存带宽低也会限制推理速度,因为每次计算都会涉及到向显存中进行数据读写。
解决方案:
- 使用各种办法优化数据预处理速度。比如优化代码、c++的O3编译优化、将一些预处理步骤放到GPU上进行而不是CPU上进行等。
- 优化后处理算法、将一些后处理步骤放到GPU上进行而不是CPU上进行等。
- 优化模型结构,对模型进行压缩。
- 使用更nb的显卡~
(冲一个3090)~,使用对显存带宽要求低的算子。
对推理时间的计算就很简单了,python、c++都有自己的time库,推理之前计一个时刻,推理之后计一个时刻,然后将两个时刻相减即可。
标签:模型,height,channels,input,output,FLOPs,KAWAKO,压缩 From: https://www.cnblogs.com/KAWAKO/p/17072913.html