短链应用场景
- 业务背景:为啥需要短链
- 公司电商产品推广、业务活动页、广告落地页 缺少实时【数据反馈和渠道效果分析】
- 老项目业务推广【没人维护,无法做埋点】需要统计效果
- APP和营销活动发送营销短信链接过长,【浪费短信发送费用】
- 国内【反垄断后】微信、抖音、淘宝 流量互通,很多知识付费公司需要做 私域流量、社群运营
- 可以对外做产品输出,实现商业化能力增加公司营收
- 积累终端数据和人群数据,为公司未来产品人群做策略助力
-
短链组成
- 协议://短链域名/短链码
-
最简单的方式
- 一个短链编码,去数据库select * from table where code =XXX,返回给用户就行
微服务功能
生命周期
接口
创建者(UI图大体类似哈)
- 流量包管理
- 免费流量包
- 付费流量包
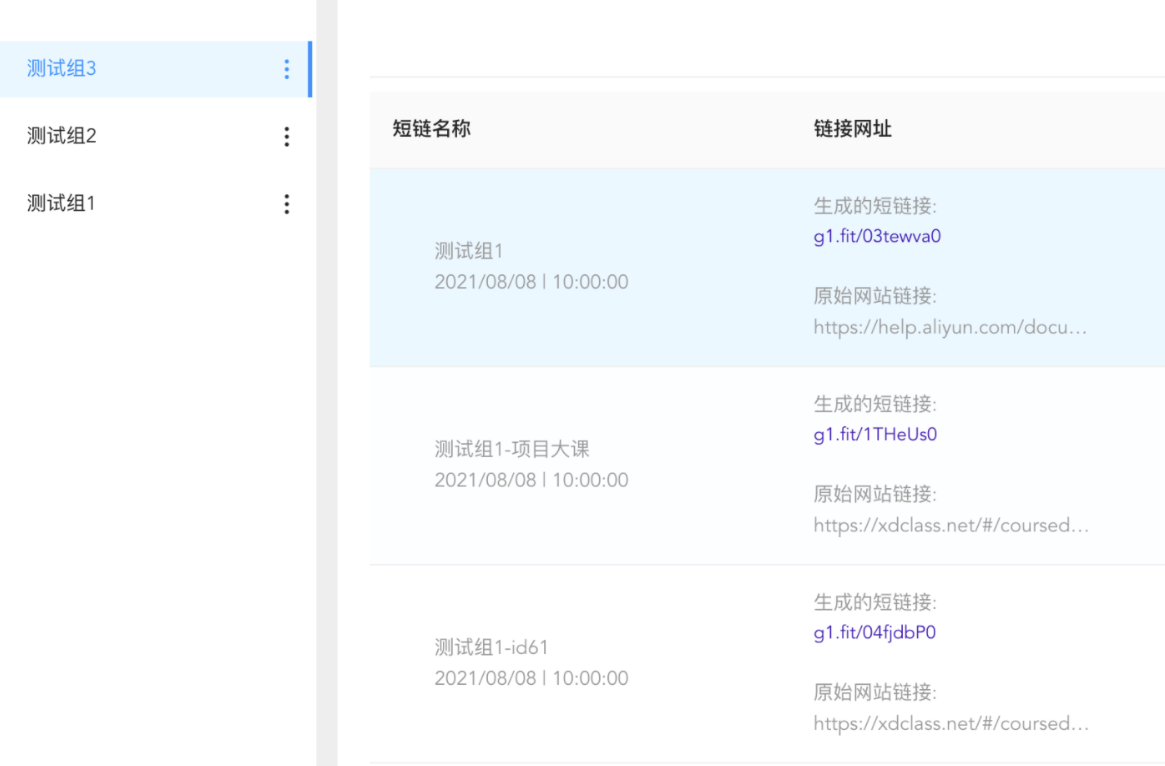
分组管理
- 新增分组
- 删除分组
- 修改分组
- 查看分组下的短链
分组作用,例如:同一个链接需要生成多端的短链,抖音、快手、B站三个平台作为分组,后期埋点数据可以用来分析引流收益
短链管理
-
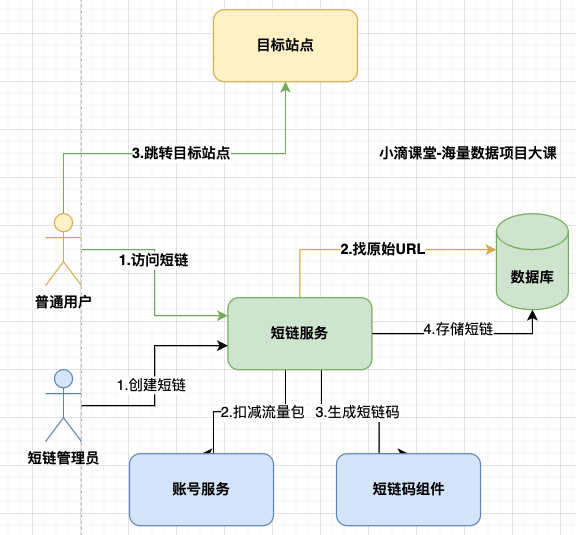
创建短链
- 目标地址
- 短链标题
- 短链域名
- 所属分组
- 有效期
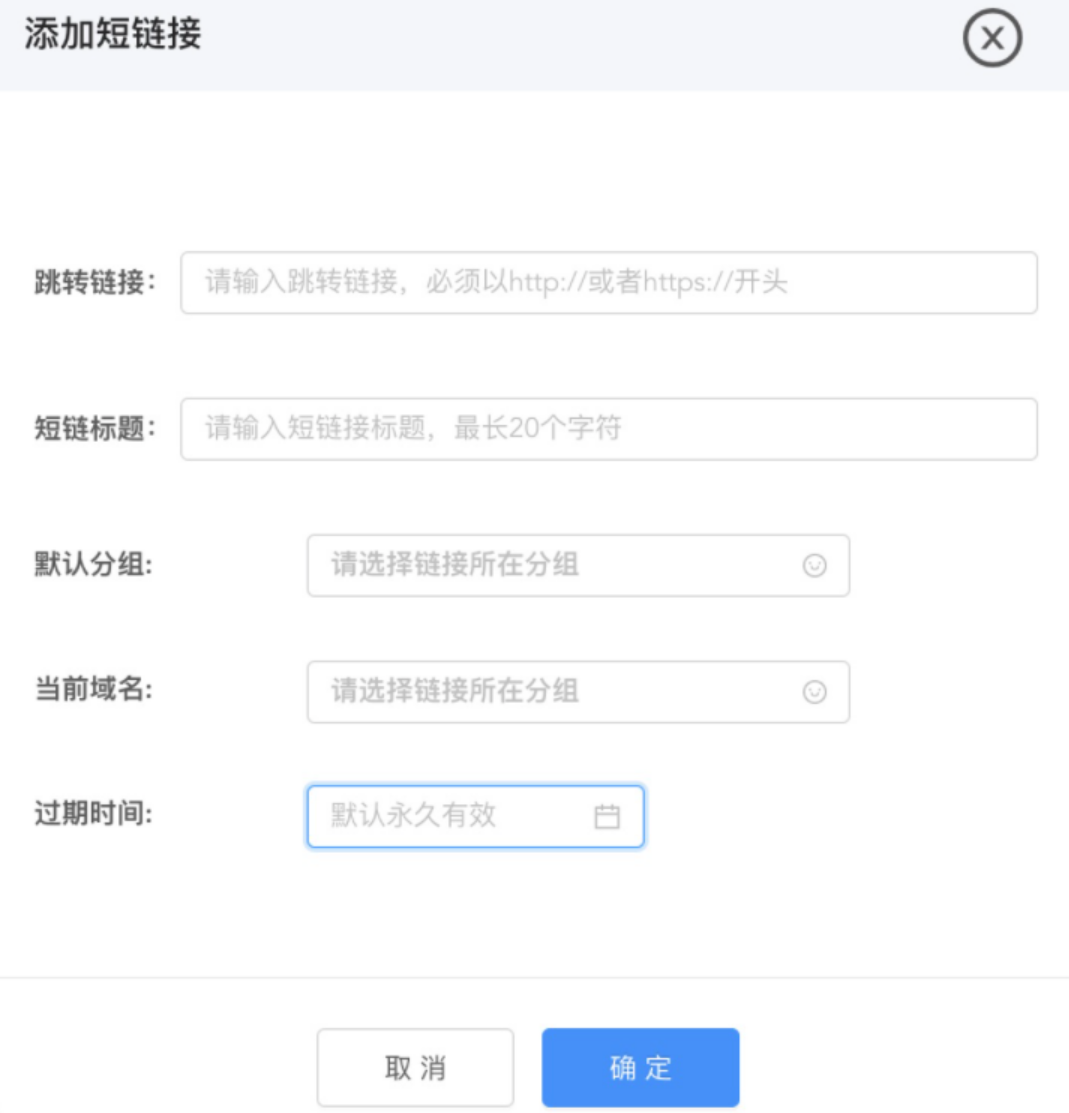
-
删除短链
-
修改短链
-
查看短链
- 访问PV、UV
- 地域分布
- 时间分布
- 来源分布
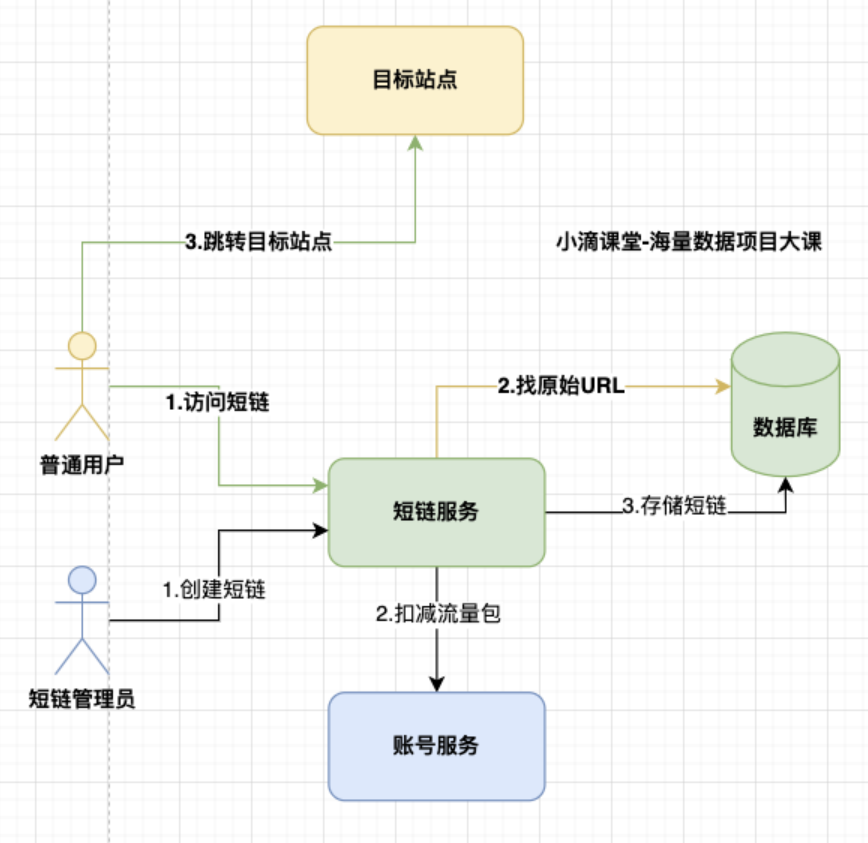
访问者
- 访问短链
- 跳转目标站点
短链服务问题解决方案
长链的关系和短链的关系是一对一还是一对多?
- 一个长链,在不同情况下,生成的短网址应该不一样,才不会造成冲突
- 多渠道推广下,也可以区分统计不同渠道的效果质量
- 所以是 一个短链接只能对应一个长链接,当然一个长链接可以对应多个短链接
前端访问短链是如何跳转到对应的页面的?
-
服务端转发
- 由服务器端进行的页面跳转,刚学Servlet时, 从OneServlet中转发到TwoServlet
- 地址栏不发生变化,显示的是上一个页面的地址
- 请求次数:只有1次请求
- 转发只能在同一个应用的组件之间进行,不可以转发给其他应用的地址
request.getRequestDispatcher("/two").forward(request, response);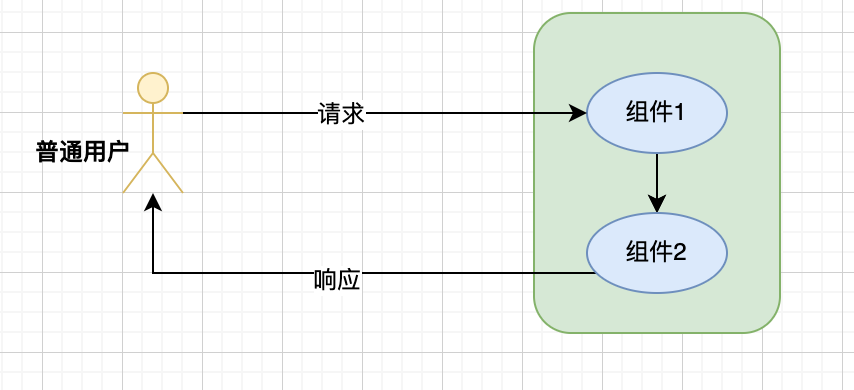
-
页面的跳转-重定向
- 由浏览器端进行的页面跳转
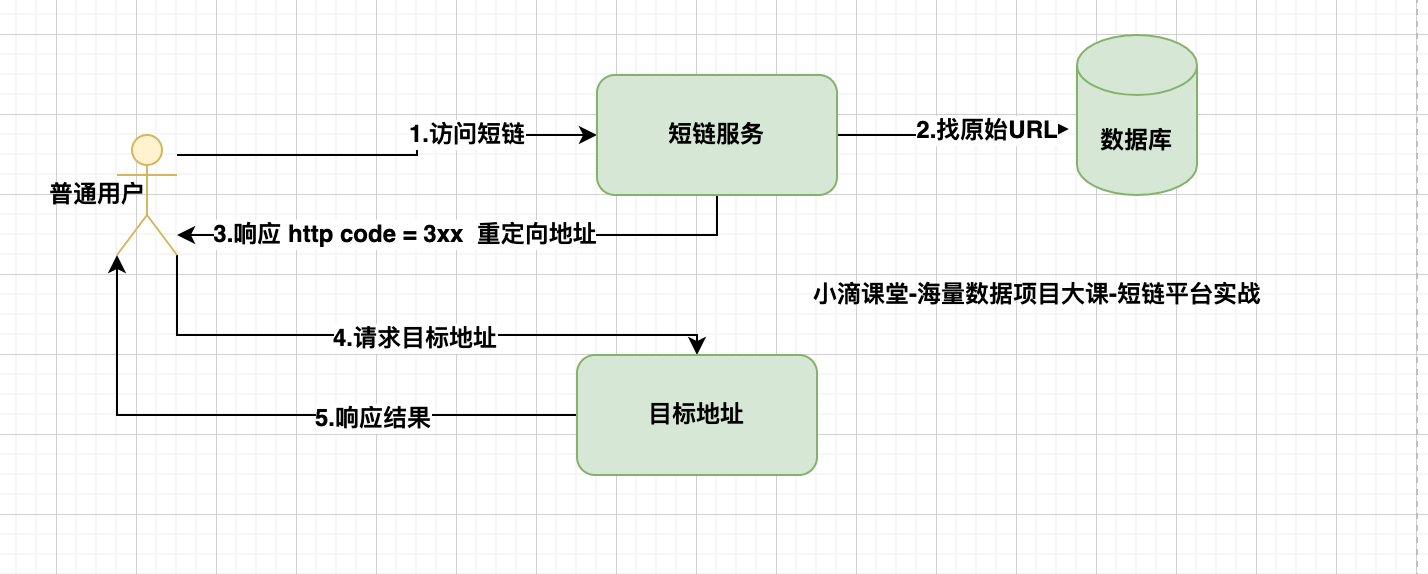
- 重定向涉及到3xx状态码,访问跳转是301还是302,301和302代表啥意思?
- 301 是永久重定向
- 会被浏览器硬缓存,第一次会经过短链服务,后续再访问直接从浏览器缓存中获取目标地址
- 302 是临时重定向
- 不会被浏览器硬缓存,每次都是会访问短链服务
- 短地址一经生成就不会变化,所以用 301 是同时对服务器压力也会有一定减少
- 但是如果使用了 301,无法统计到短地址被点击的次数
- 所以选择302虽然会增加服务器压力,但是有很多数据可以获取进行分析
- 选择使用302,这个也可以对违规推广的链接进行实时封禁
- 301 是永久重定向
短链码如何是如何生成的
- 短链码特点
- 生成性能强劲
- 碰撞概率低
- 避免重复
- 恶意猜测
- 业务规则安全
-
方式
-
自增ID
- 利用插入数据库,利用数据库自增id
- 把自增id转成62进制作为短链码
- 短链码的长度不固定,随着 id 变大,短链码长度也增长
- 可以指定从某个长度开始增长,到百亿、千亿数量
- 转换工具:https://tool.lu/hexconvert/
- 是否存在重复: 不重复
- 但短链码是有序的递增,存在【业务数据安全】问题
-
MD5内容压缩
- 长链接做md5加密
43E08496,9E5CF455,E6D2D2B3,3407A6D2- 加密串查询是否已经生成过短链接
- 如果已经存在,则拼接时间戳再MD5加密,插入数据库
- 如果不存在则把长链接、长链接加密串插入数据库
- 取MD5后 最后1 个 8 位字符串作为短链码
- 是否存在重复: 存在碰撞(重复)可能
- 是有损压缩算法,数据量超大情况碰撞概念越大
- 比如 【小滴课堂-老王的女友】有300多个,每再多1个,再同一天生日的概率越大,就更加复杂
-
数据脱敏解决方案
- 什么是数据脱敏
-
也叫数据的去隐私化,在给定脱敏规则和策略的情况下,对敏感数据比如
手机号、身份证等信息,进行转换或者修改的一种技术手段,防止敏感数据直接在不可靠的环境下使用和泄露、撞库等 -
技术分两类
- 静态数据脱敏
- 将生产数据导出,进行对外发送或者给开发、测试人员等
- 动态数据脱敏
- 程序直接连接生产数据的场景,如运维人员在运维的工作中直接连接生产数据库进行运维
- 客服人员在生产中通过后台查询的个人信息
- 静态数据脱敏
-
MurMurHash
Murmur哈希是一种非加密散列函数,适用于一般的基于散列的查找。
它在2008年由Austin Appleby创建,在Github上托管,名为“SMHasher” 的测试套件。
它也存在许多变种,所有这些变种都已经被公开。
该名称来自两个基本操作,乘法(MU)和旋转(R)--来自百科
-
是一种【非加密型】哈希函数且【随机分布】特征表现更良好
-
由于是非加密的哈希函数,性能会比MD5强
-
再很多地方都用到比如Guava、Jedis、HBase、Lucence等
-
存在两个版本
- MurmurHash2(产生32位或64位值)
- MurmurHash3(产生32位或128位值)
-
数据量
-
MurmurHash的 32 bit 能表示的最大值近 43 亿的10进制
- 满足多数业务,如果接近43亿则冲突概率大
-
产品目标【超理想情况】
首年日活用户: 10万 首年日新增短链数据:10万*50 = 500万 年新增短链数:500万 * 365天 = 18.2亿 年新增用户数:50万/1年 年营收目标: 10万付费用户 * 客单价200元 = 2千万 新增短链:50条/用户每日-
MurMurHash得到的数值是10进制,一般会转化为62进制进行缩短
- 例子
- 10进制:1813342104
- 转62进制:1YIB7i
- https://tool.lu/hexconvert/
- 例子
-
常规短链码是6~8位数字+大小写字母组合
0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ 6 位 62 进制数可表示 568 亿个短链(62的6次方,每位都有62个可能,如果扩大位数到7位,则可以支持3万5200亿)- MurmurHash的 32 bit 满足多数业务 43亿
- 拼接上库-表位则可以表示更多数据(后续会讲分库分表的,库表位)
- 7位则可以到到 43亿 * 62 = 2666亿
- 8位则可以到到 2666亿 * 62 = 1.65万亿条数据
- 结合短链过期数据归档,理论上满足未来全部需求了
- 数据库存储
- 单表1千万 * 62个库 * 62表 = 384亿数据
-
分库分表配置
分组管理-水平分库分表配置
-
需求
- 未来2年,短链平台累计5百万用户
- 短链组:一个用户30个组,就是1.5亿个组
- 单表不超过1千万数据,需要分15张表
- 进一步延伸,进行水平分库分表,比如 2库、4库、8库、16库
- 一个库一张表
- 需要降低单表数据量,进行水平分库分表
- 分库数量:线上分16库,本地分2库即可
- 分片key: account_no,查询维度都是根据account_no进行查询
- 分片策略:行表达式分片策略 InlineShardingStrategy
- 未来2年,短链平台累计5百万用户
-
配置
#----------短链组,策略:水平分库,不水平分表--------------
# 先进行水平分库, 水平分库策略,行表达式分片
spring.shardingsphere.sharding.tables.link_group.database-strategy.inline.sharding-column=account_no
spring.shardingsphere.sharding.tables.link_group.database-strategy.inline.algorithm-expression=ds$->{account_no % 2}
分库分表免迁移扩容方案-库码编码
-
需要解决的问题
- 数据量增加,扩容避免迁移数据或者免迁移
- 前期数据量不多,不浪费库表系统资源
- 分库分表:16个库, 每个库64个表,总量就是 1024个表
-
短链码
- 比如 g1.fit/92AEva 的短链码 92AEva
-
如何做?
- 从短链码入手-增加库表位
- 类似案例-阿里这边商品订单号-里面也包括了库表信息(规则不能说)
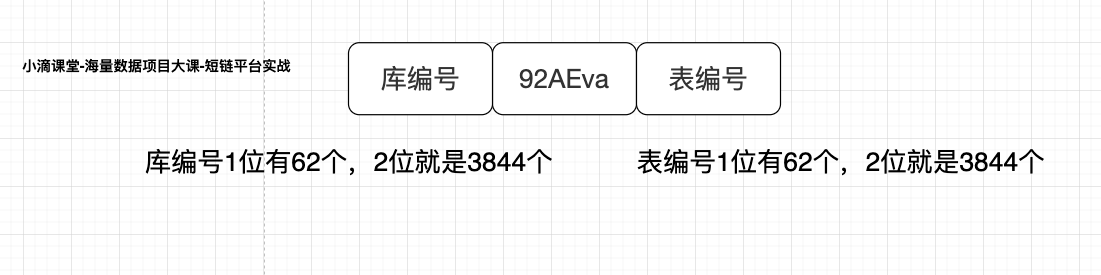
- 为啥能做到免迁移扩容?
- A92AEva1
- 由于短链码的前缀和后缀是是固定的,所以扩容也不影响旧的数据
- 类似的免迁移扩容策略还有哪些?
- 时间范围分库分表
- id范围分库分表
分片策略加权负载均衡
冗余双写架构
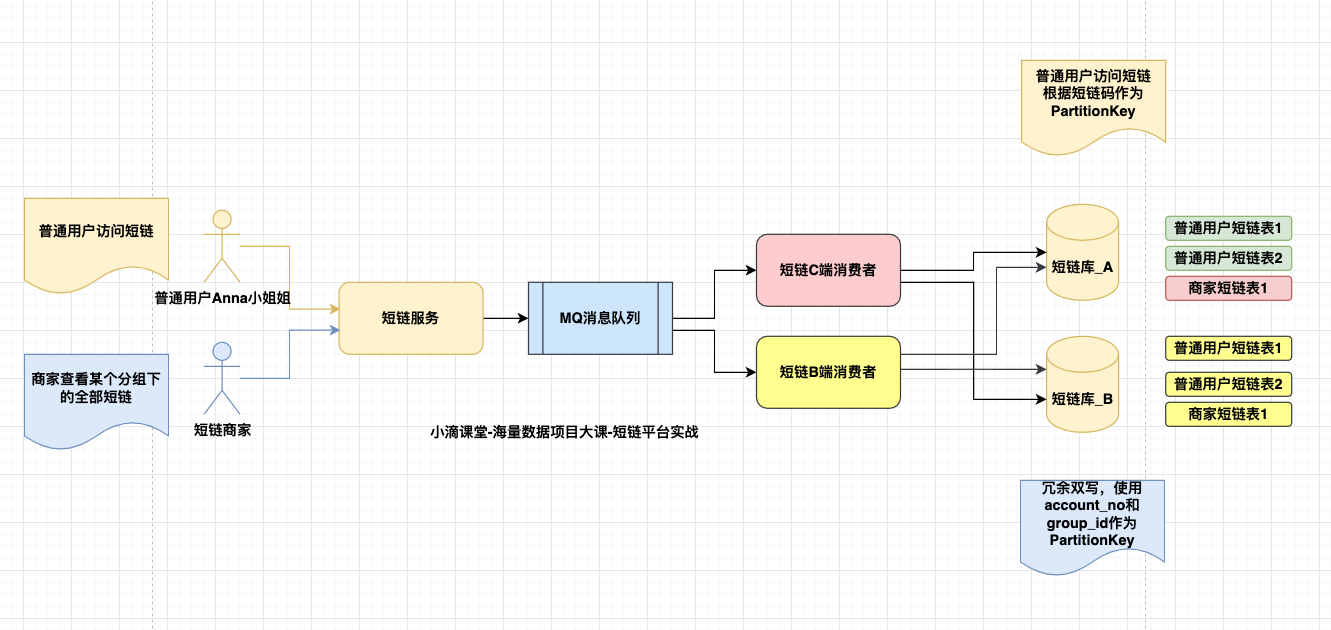
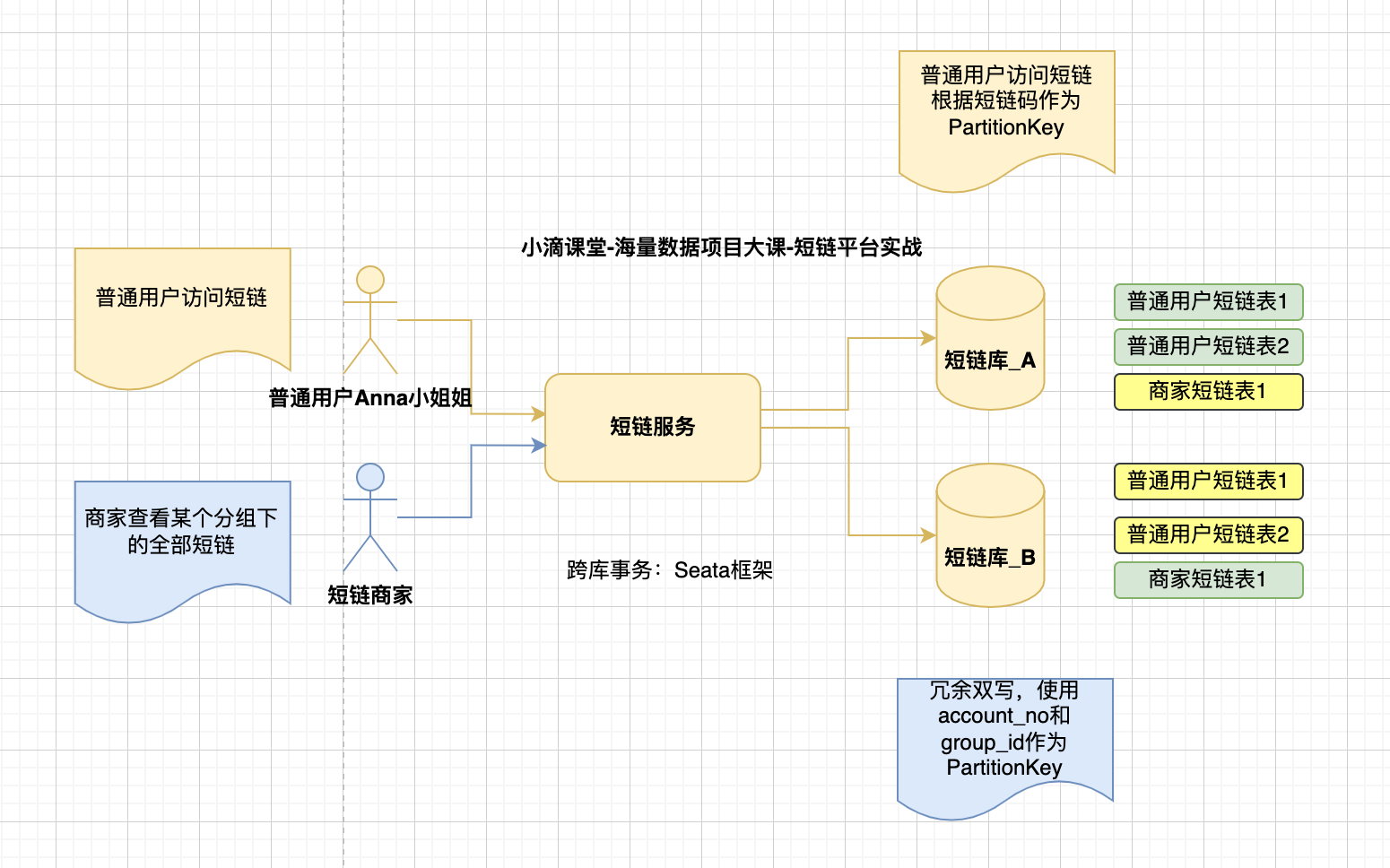
问题:商家怎么看自己的全部短链
* 普通用户根据短链码可以路由到对应的库表
* 但是商家创建的短链码都是没规律,分布再不同的库表上
-
不同维度查看数据,场景是不一样的,
-
主要是分:有PartitionKey,没PartitionKey两个场景
- 电商订单案例一:
- 订单表 的partionKey是user_id,用户查看自己的订 单列表方便
- 但商家查看自己店铺的订单列表就麻烦,分布在不同数据节点
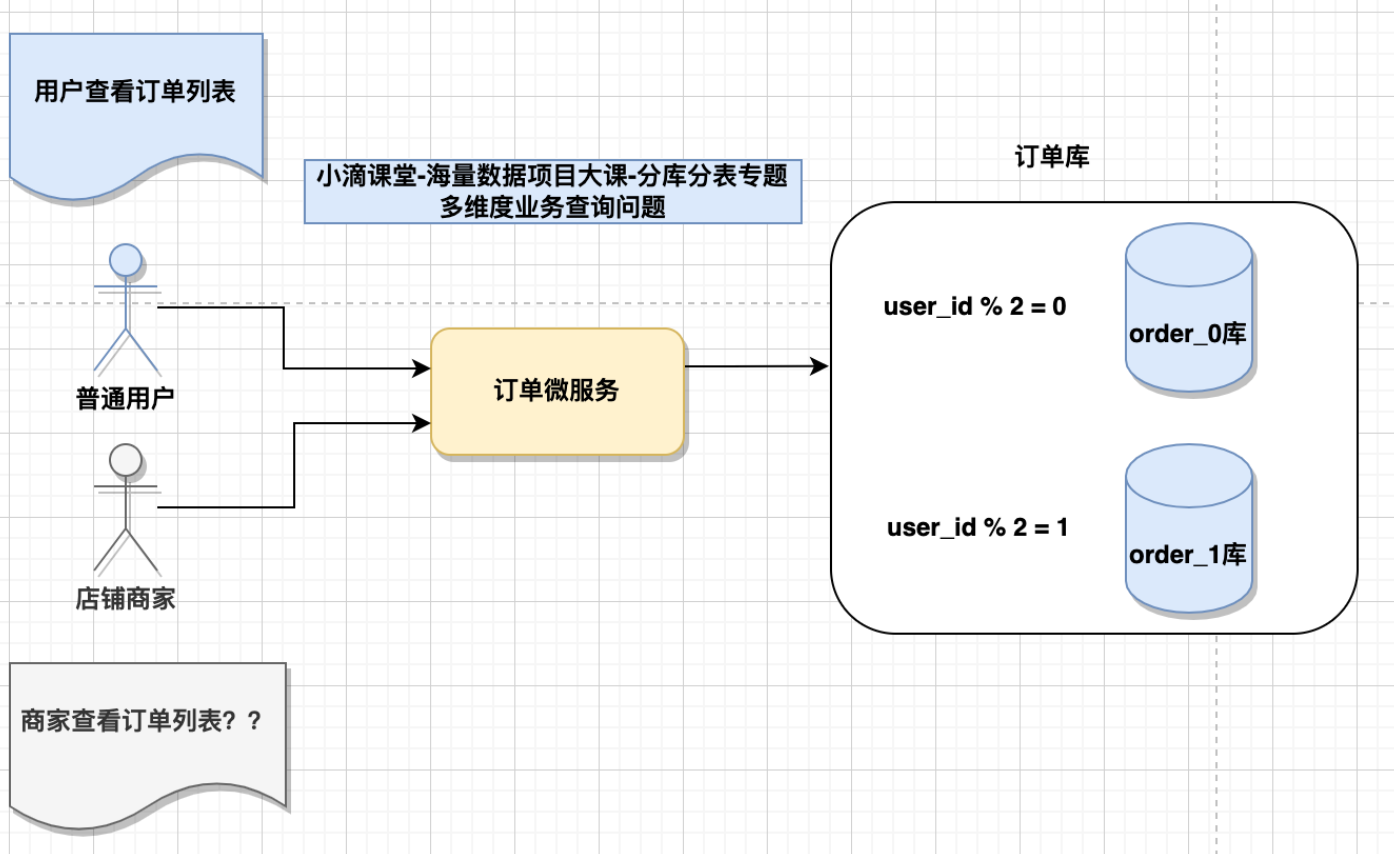
- 短链访问案例
- 普通用户访问短链,根据短链码code可以解析到对应的库表
- 但短链商家,查看自己全部的短链就麻烦了,分布再不同的库下面
- 电商订单案例一:
-
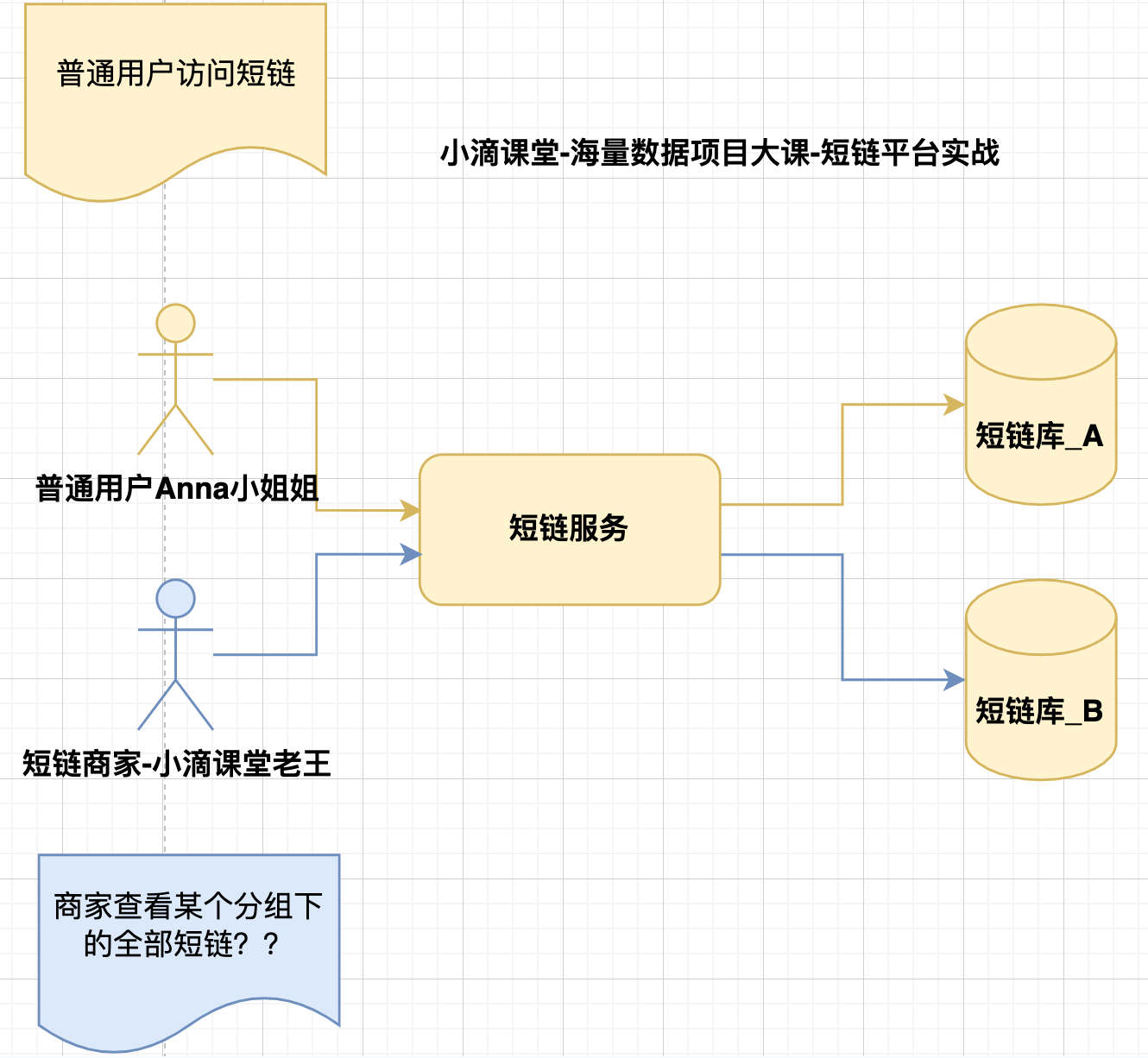
- 这个是【 通用的业务场景痛点 】
- 除了上面的电商业务、短链业务,还有更多
- 招聘网站业务
- 企业查看自己某个岗位的面试记录
- 应聘者查看自己的全部面试记录
- 痛点:
- 根据user_id进行hash分库分表
- 但是企业的岗位存在不同user_id进行面试
分库分表多维度查询解决方案
方案一【字段解析配置】
-
分库分表后的查询问题
- 有PartitionKey,没PartitionKey两个场景
- 不同维度查询是不一样的,怎么解决?
-
解决方案
-
字段解析配置
-
NOSQL冗余
-
本身库表冗余双写方案
- 部分字段冗余
- 全量内容冗余
-
-
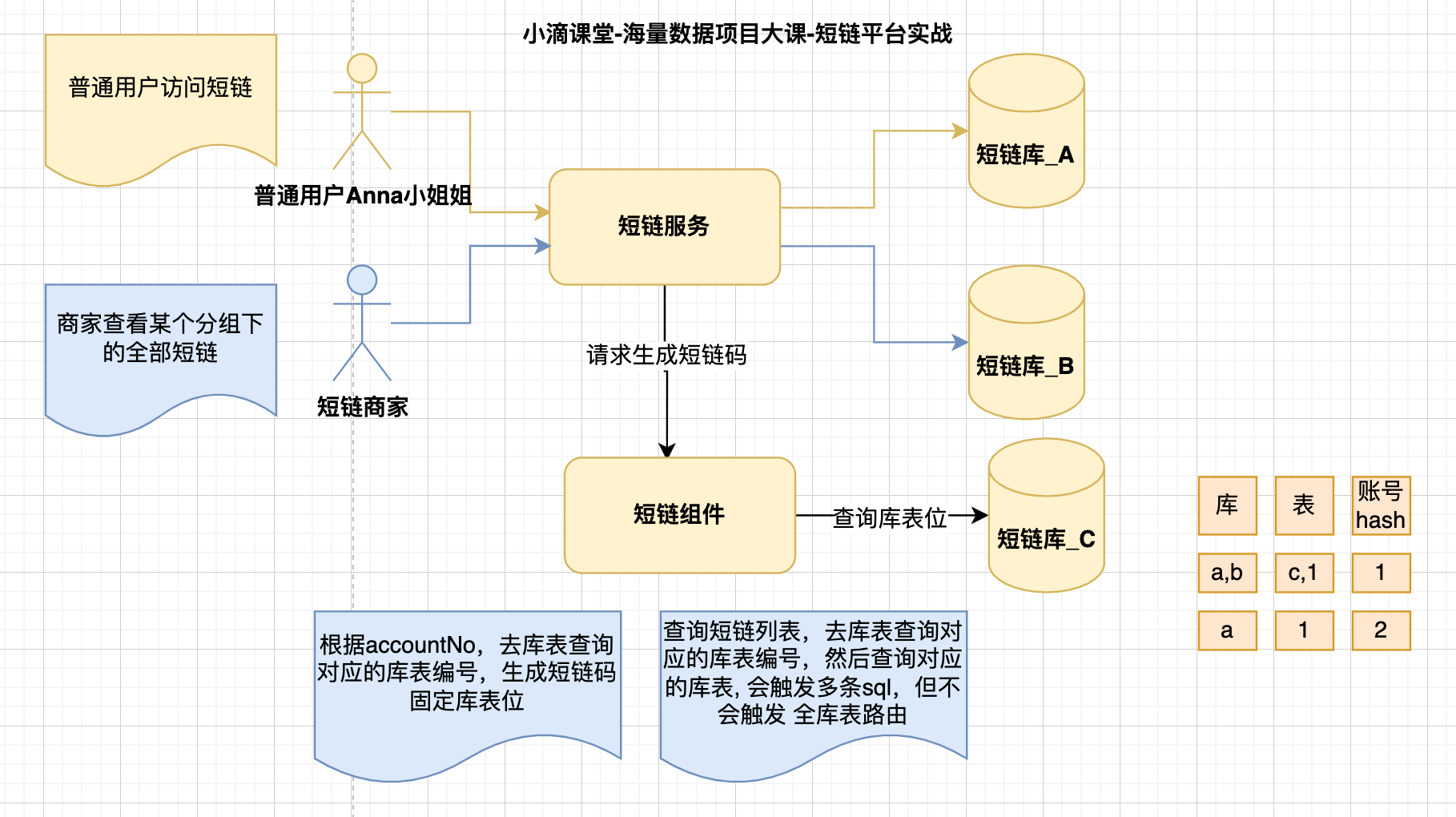
解决方式一(字段解析配置):
- 建一个表,存储account_no对应的库表位,商家生成的【短链码】固定前缀或者后缀
- 即【短链码】里面包括了商家的信息
方案二【NOSQL方案】
-
分库分表后的查询问题
- 有PartitionKey,没PartitionKey两个场景
- 不同维度查询是不一样的,怎么解决?
- 解决方案
- 字段解析配置
- NOSQL冗余
- 本身库表冗余双写方案
- 部分字段冗余
- 全量内容冗余
-
解决方式二:
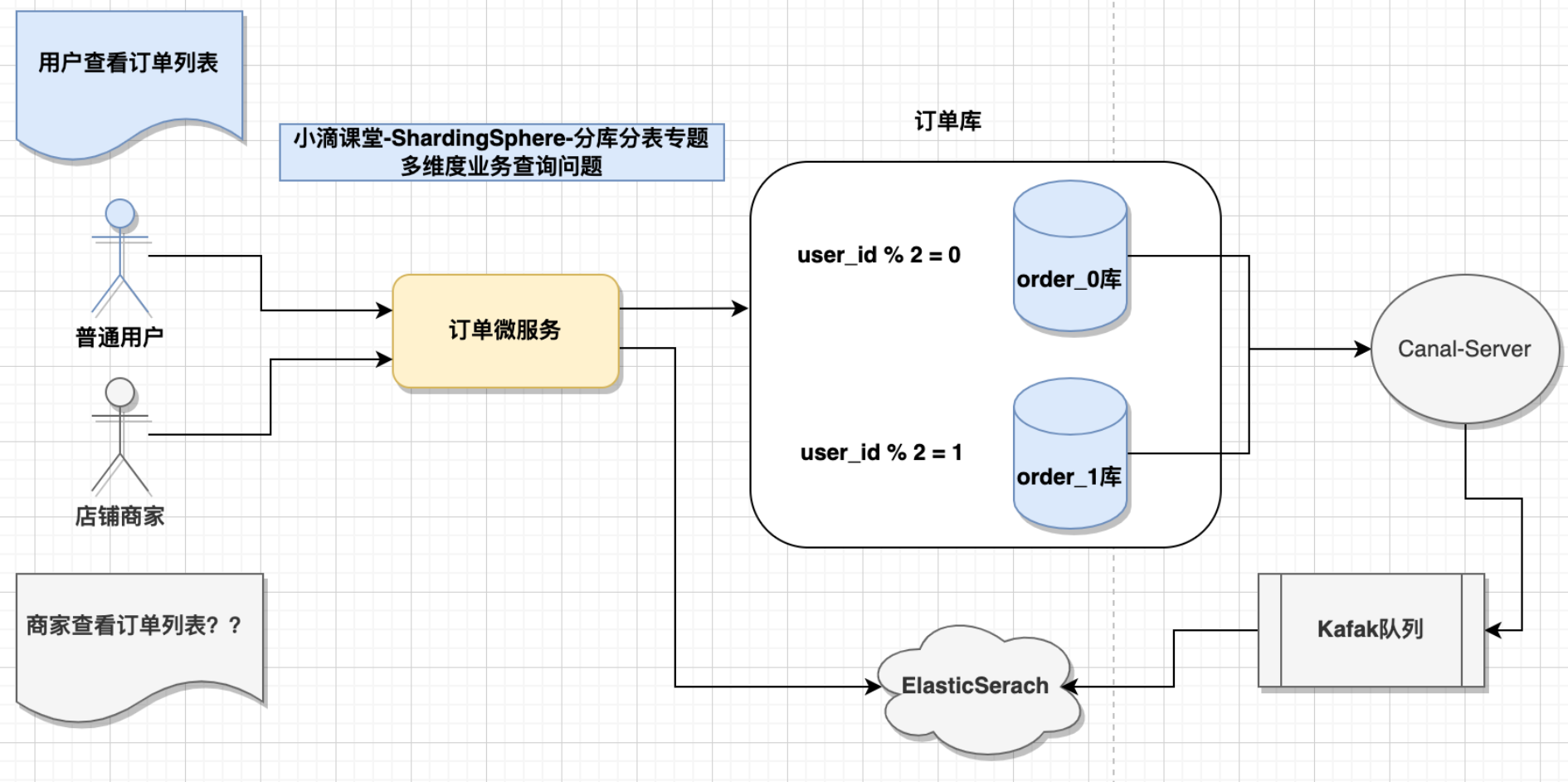
- 电商订单案例
- 订单表 的partionKey是user_id,用户查看自己的订单列表方便
- 但商家查看自己店铺的订单列表就麻烦,分布在不同数据节点
- 订单冗余存储在es上一份
- 业务架构流程
- 短链平台案例
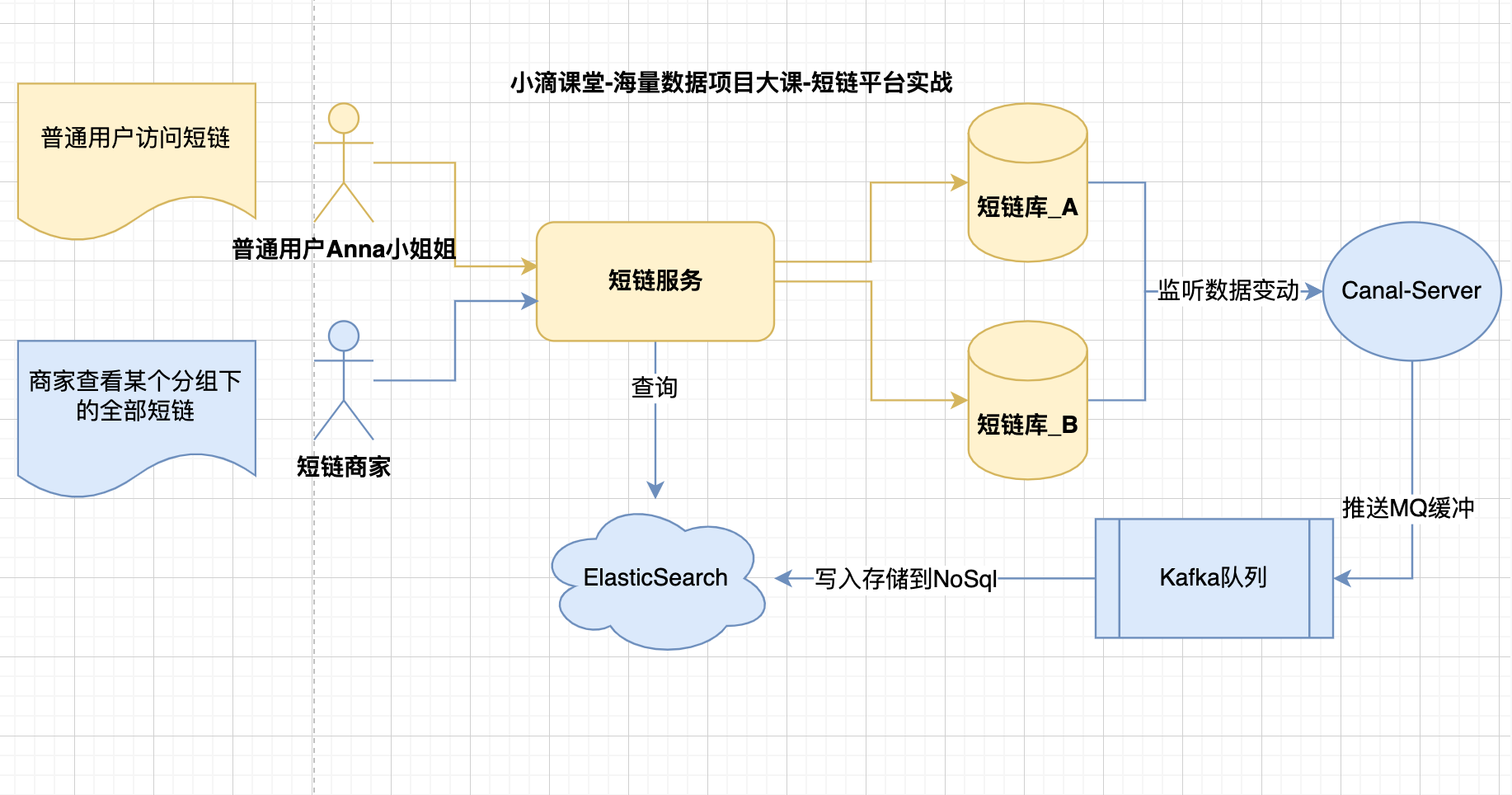
- 短链表的partionKey是短链码,用户访问短码方便解析
- 但商家查看自己某个分组下全部短链列表就麻烦,分布在不同数据节点
- 短链码冗余存储在es上一份
- 业务架构流程
- 电商订单案例
方案三【冗余双写方案】
-
分库分表后的查询问题
- 有PartitionKey,没PartitionKey两个场景
- 不同维度查询是不一样的,怎么解决?
-
解决方式三:
- 电商场景
- b2b平台,比如淘宝、京东,买家和卖家都要能够看到自己的订单列表
- 无论是按照买家id切分订单表,还是按照卖家id切分订单表都没法满足要求
- 拆分买家库和卖家库
- 买家库,按照用户的id来分库分表
- 卖家库,按照卖家的id来分库分表
- 数据冗余
- 下订单的时候写两份数据
- 在买家库和卖家库各写一份

- 短链场景
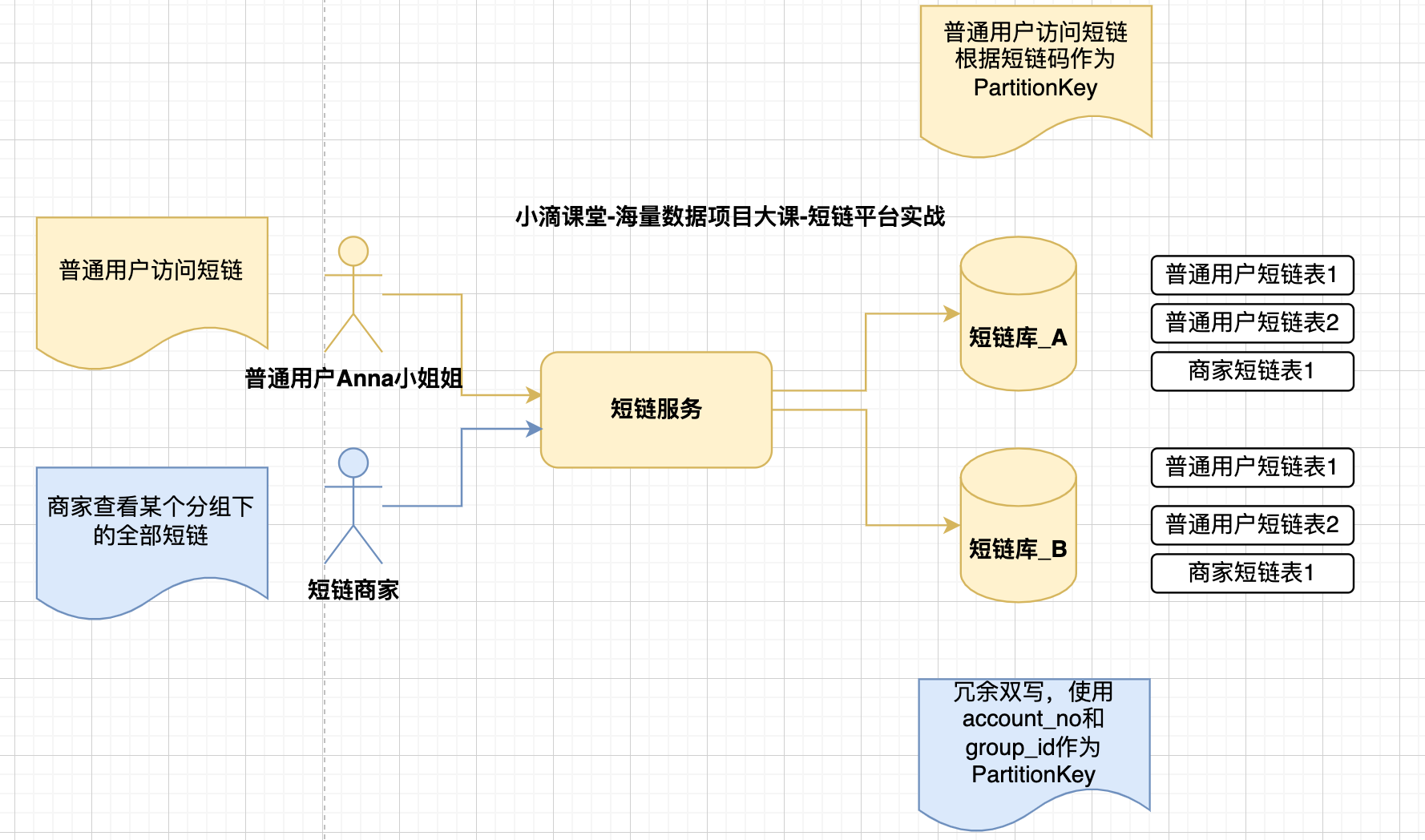
- 电商场景
冗余双写分布式事务问题解决
- 方案一
- 直接RPC调用+Seata分布式事务框架
- 优点:强一致性,代码逻辑简单,业务侵入性小
- 缺点:性能下降,seata本身存在一定的性能损耗
- Seata支持AT、TCC、Saga 三种模式
- AT:隔离性好和低改造成本, 但性能低
- TCC:性能和隔离性,但改造成本大
- Saga:性能和低改造成本,但隔离性不好
- Seata支持AT、TCC、Saga 三种模式
- 方案二(选用)
- 使用MQ, 生产者确认消息发送成功后,不同的消费者订阅消息消费
- 同时保证消息处理的幂等性
- 保证Broker的高可用
- 优点
- 实现简单,改造成本小
- 性能高,没有全局锁
- 缺点
- 弱一致性,需要强一致性的场景不适用
- 消费者消费失败,需要额外写接口回滚生产者业务逻辑
- 使用MQ, 生产者确认消息发送成功后,不同的消费者订阅消息消费