\(\mathtt{Link}\)
P8338 [AHOI2022] 排列 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
\(\mathtt{Description}\)
\(T\) 组数据。
对于一个长度为 \(n\) 的排列 \(P = (p_1, p_2, \ldots, p_n)\) 和整数 \(k \ge 0\),定义 \(P\) 的 \(k\) 次幂
\[P^{(k)} = \left( p^{(k)}_1, p^{(k)}_2, \ldots, p^{(k)}_n \right), \]该排列的第 \(i\) 项为
\[p^{(k)}_i = \begin{cases} i, & k = 0, \\ p^{(k - 1)}_{p_i}, & k > 0. \end{cases} \]容易证明任意排列的任意次幂都是一个排列。
定义排列 \(P\) 的循环值 \(v(P)\) 为最小的正整数 \(k\) 使得 \(P^{(k + 1)} = P\)。
给出一个长度为 \(n\) 的排列 \(A = (a_1, a_2, \ldots, a_n)\),对于整数 \(1 \le i, j \le n\),定义 \(f(i, j)\):若存在 \(k \ge 0\) 使得 \(a^{(k)}_i = j\),则 \(f(i, j) = 0\),否则设排列 \(A_{i, j}\) 为将排列 \(A\) 的第 \(i\) 项 \(a_i\) 和第 \(j\) 项 \(a_j\) 交换后得到的排列,则 \(f(i, j) = v(A_{i, j})\)。
求 \(\sum_{i = 1}^{n} \sum_{j = 1}^{n} f(i, j)\) 的值。答案可能很大,你只需要输出其对 \(({10}^9 + 7)\) 取模的结果。
\(\mathtt{Data} \text{ } \mathtt{Range} \text{ } \mathtt{\&} \text{ } \mathtt{Restrictions}\)
-
\(1 \le T \le 5\);
-
\(1 \le a_i \le n \le 5 \times 10^5\)。
\(\mathtt{Solution}\)
首先明确一下排列的基本定义:长度为 \(n\) 的排列指的是一个 \(n\) 元组(可以理解为长度为 \(n\) 的数组),满足 \(1\) 到 \(n\) 这 \(n\) 个数,每个数都恰好在这个 \(n\) 元组中出现 \(1\) 次。
观察题目中排列的幂的定义,从 \(P^{(k)}\) 到 \(P^{(k + 1)}\),是通过将 \(P^{(k)}\) 中每一个数 \(v\) 更改为 \(p_v\) 得到的,也就是一种类似于 \(i \to p_i\) 的迭代。
考虑对于长度为 \(n\) 的排列 \(P\) ,构造一个有向图 \(G\),图 \(G\) 中恰有 \(n\) 个编号从 \(1\) 到 \(n\) 的点和 \(n\) 条边,第 \(i\) 条边为 \(i \to p_i\)。
发现这个图会是一堆简单环构成的(可以有自环),这是因为图 \(G\) 经过上述连边方式,每个点的入度一定恰好为 \(1\)(注意到排列的性质),出度也一定恰好为 \(1\),如此以来一定会形成一堆简单环的集合。
这么建图我们的目的在于将 \(i \to p_i\) 的迭代具体化——一开始有 \(n\) 个小人,第 \(i\) 个小人在节点 \(i\),每个小人顺着所在的环走 \(k\) 步后,第 \(i\) 个小人所在的节点就是 \(P^{(k)}\) 的第 \(i\) 个元素。
举个例子:\(P = (3, 1, 2)\)。对排列 \(P\) 建图得到:
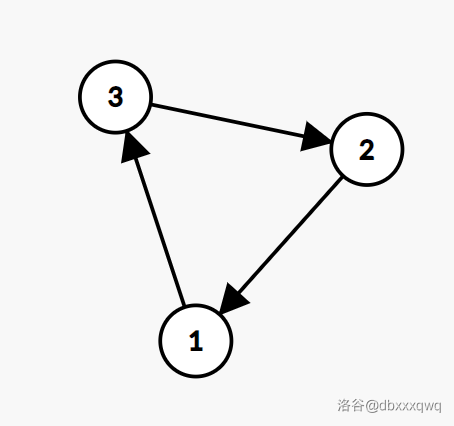
第 \(1\) 个小人一开始在 \(1\),第 \(2\) 个小人一开始在 \(2\),第 \(3\) 个小人一开始在 \(3\)。\(P^0 = (1, 2, 3)\)。
现在所有小人顺着走一步。第 \(1\) 个小人此时在 \(3\),第 \(2\) 个小人此时在 \(1\),第 \(3\) 个小人此时在 \(2\),因此 \(P^1 = (3, 1, 2)\)。
另外很显然 \(P^1 = P\)。
然后所有小人再顺着走一步,第 \(1\) 个小人此时在 \(2\),……就可以得到 \(P^2 = (2, 3, 1)\)。
然后再走一步,得到 \(P^3 = (1, 2, 3)\)。发现:这等于 \(P^0\)!
那么接下来肯定又会有 \(P^4 = P^1\),\(P^5 = P^2\),\(P^6 = P^3=P^0\),如此循环下去……发现循环节是 \(3\)。
事实上所有排列的幂都一定会出现循环,而循环节的长度正是 \(v(P)\) 的定义。
定义排列 \(P\) 的循环值 \(v(P)\) 为最小的正整数 \(k\) 使得 \(P^{(k + 1)} = P\)。
我们知道,\(P^ {(k +1)}\) 代表第 \(i\) 个小人在节点 \(p_i\),每个人顺着走 \(k\) 步后的结果。
那么 \(P^{(k + 1)} = P\) 是什么意思? 也就是说,每个小人一开始在 \(p_i\),能满足所有人挨个顺着走 \(k\) 步后还能回到 \(p_i\)。\(v(P)\) 描述了 \(k\) 的最小值。
设总共有 \(m’\) 个环,第 \(i\) 个环的环长是 \(r_i\),于是有 \(v(P) = \operatorname{lcm}(r_1, r_2, \cdots, r_{m'})\)。原因:每个人在 \(p_i\),走 \(k\) 步还能回来,充要条件就是 \(k\) 是所有环长的倍数,那最小的 \(k\) 就是所有环长的最小公倍数。
举个例子,我们对 \(P = (4, 6, 8, 9, 2, 5, 10, 7, 1, 3)\) 进行循环值分析。首先画个图:
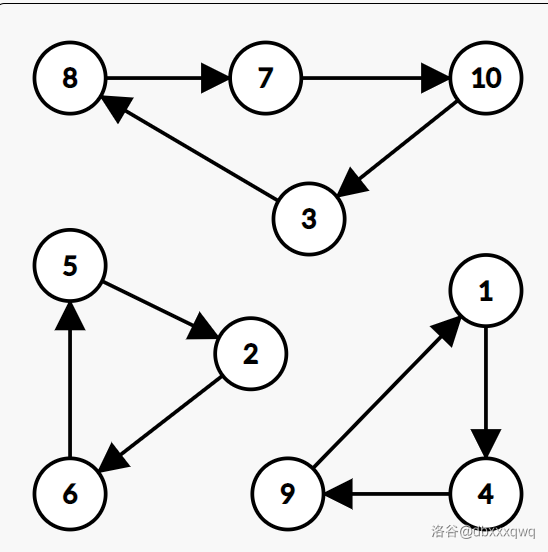
发现总共有 \(3\) 个环,长度分别为 \(4, 3, 3\),于是 \(v(P)\) 就应该等于 $ \operatorname{lcm}(4, 3, 3) = 12$。因为所有小人都至少走 \(12\) 步后,才能保证所有小人回到原位置。
现在来把视线转移到排列 \(A\) 上。
对于整数 \(1 \le i, j \le n\),定义 \(f(i, j)\):若存在 \(k \ge 0\) 使得 \(a^{(k)}_i = j\),则 \(f(i, j) = 0\),否则设排列 \(A_{i, j}\) 为将排列 \(A\) 的第 \(i\) 项 \(a_i\) 和第 \(j\) 项 \(a_j\) 交换后得到的排列,则 \(f(i, j) = v(A_{i, j})\)。
分别考虑。
什么时候存在 \(k \ge 0\) 使得 \(a^{(k)}_i = j\)?
先来看 \(a_i^{(k)}\) 是个什么东西。阅读题目我们发现,它其实是 \(A^k\) 的第 \(i\) 项。
考虑在 \(A\) 的图上,发现所有的 \(a_i^{(k)}\) 其实也就是在说图上的 \(a_i\) 这个点走 \(k\) 步。由于 \(k\) 的取值是任意的,那么只要 \(a_i\) 和 \(j\) 在同一个环上,那么 \(a_i\) 就可以走 \(k\) 步到达 \(j\)。
也就是说:\(a_i\) 和 \(j\) 在同一个环上,是存在 \(k \ge 0\) 使得 \(a^{(k)}_i = j\) 的充要条件。
否则,怎么求 \(v(A_{i, j})\)?
考虑交换 \(a_i\) 和 \(a_j\) 会有什么影响。
由于我们现在知道,\(a_i\) 和 \(j\) 不在同一个环上(否则会走上面那个分支),然后 \(j\) 在 \(a_j\) 在同一个环上,因此 \(a_i\) 和 \(a_j\) 不在同一个环上。
交换 \(a_i\) 和 \(a_j\),相当于在 \(A\) 对应的图基础上,将 \(i \to a_i\) 和 \(j \to a_j\) 这两条边分别改为 \(i \to a_j\) 和 \(j \to a_i\),其他的边都不变,形成的新图就是 \(A_{i, j}\) 的图。
发现这样修改,相当于将 \(a_i\) 和 \(a_j\) 所在的两个环合并成一个大环,环长是原来两个小环长的和。
证明:假设 \(pre_i\) 是 \(i\) 的前驱(\(a_i\) 是 \(i\) 的后继),假设原来是 \(pre_i \to i \to a_i \to \cdots \to pre_i\) 和 \(pre_j \to j \to a_j \to \cdots \to pre_j\) 两个小环,那么 \(A_{i, j}\) 的图里面就会变成 \(pre_i \to i \to a_j \to \cdots \to pre_j \to j \to a_i \to \cdots \to pre_i\) 这样一个大环。
举个例子,假设 \(A = (4, 6, 8, 9, 2, 5, 10, 7, 1, 3)\)(没错还是那个熟悉的排列)。把图再放一遍:
现在考虑从 \(A\) 扩展到 \(A_{5, 3}\)。\(a_5 = 2, a_3 = 8\),那么我们应该把 \(5 \to 2\) 和 \(3 \to 8\) 这两条边分别改为 \(5 \to 8\) 和 \(3 \to 2\)。
然后就会变成这样:
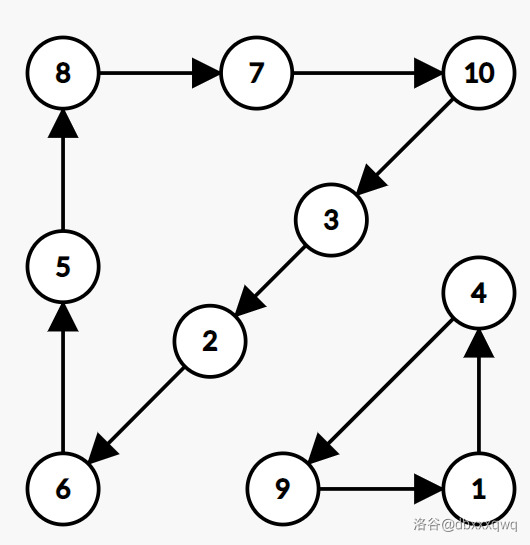
可以看到确实是 \(a_i\) 和 \(a_j\) 所在的两个环合并了。
所以 \(v(A_{i, j})\) 其实就是把 \(a_i\) 和 \(a_j\) 所在的两个环加和,和其他的所有环长取 \(\operatorname{lcm}\) 的结果。
上面这个例子中就是 \(v(A_{5, 3}) = \operatorname{lcm}(4 + 3, 3) = 21\)。
到这里已经理论可做了,我们已经大体完成了翻译题目的工作。现在考虑加速最后结果的计算。
还是上面那个图,再放一次:
我们把目标锁定在上面那个环和左下角那个环。会发现,从上面那个环随便选一个点,从左下角那个环随便选一个点,交换,结果肯定是 \(21\)。比如:\(v(A_{5, 8}) = v(A_{2, 7}) = v(A_{6, 10}) = v(A_{2, 3}) = 21\)。
再把目标锁定在上面那个环和右下角那个环,发现随便选之后答案仍然是 \(21\)。\(v(A_{8, 9}) = v(A_{7, 1}) = v(A_{3, 4}) = v(A_{9, 3}) = 21\)。
那有不是 \(21\) 的吗?如果我们把目标锁定在下面这两个环,那么答案就会恒为 \(\operatorname{lcm}(4, 3 + 3) = 12\)。
为什么会这样呢?发现他跟我们选取两个点所在的环的长度有关系。选取两个点所在环长度分别是 \(3, 4\),那答案就是 \(21\);选取的两个点所在环长度分别是 \(3, 3\),那么答案就是 \(12\)。那为啥没有 \(4, 4\) 呢,因为没有两个长度为 \(4\) 的环,选不出来。
如果两个环的长度相同,我们可以认为他们的本质是相同的,设本质不同的环总共有 \(m\) 个,这个 \(m\) 最多可能有多少个?
我们知道,环长总和不能超过 \(n\),因此最坏的情况就是环长分别为 \(1, 2, 3, \cdots, m\) 的情况,即使这样 \(m\) 也是 \(\sqrt n\) 量级的。
这是一个经典结论:如果 \(\Sigma w_i = n\),那么值不同的 \(w_i\) 的种类是 \(\sqrt n\) 量级的(而且不满)。
因此只要枚举本质不同的环长,进行计算。
我们设 \(v(i, j)\) 表示将长度为 \(i\) 的环和长度为 \(j\) 的环合并后排列的循环值,考虑它会对最后的答案产生多少个贡献。我们再设 \(c_i\) 表示长度为 \(i\) 的环的数量。
需要分两种情况讨论:
- \(i \ne j\),根据乘法原理,贡献量应该是长度为 \(i\) 的所有环里的所有点的数量(数目为 \(c_i \times i\),环数量乘环长),乘上长度为 \(j\) 的所有环里所有点的数量(数目为 \(c_j \times j\)),也就是 \(c_i \times i \times c_j \times j\)。
- \(i = j\),即 \(v(i, i)\) 的贡献。首先肯定需要满足 \(c_i > 1\),因为至少有 \(2\) 个长度为 \(i\) 的环才能实现交换。同样根据乘法原理能得到贡献是 \(c_i \times i \times (c_i - 1) \times i\)。
根据对称性,上面的第一种情况中,也可以直接把 \(j\) 从 \(i + 1\) 开始枚举,给贡献乘个 \(2\) 就行了。
由于枚举的开销是 \(m \times m= n\) 的,直接从 \(n^2\) 优化到线性。
到这里复杂度是 \(\operatorname{O}(n \times m \log n) = \operatorname{O(n \sqrt{n} \log n)}\)。虽然拿不到满分也能拿到一个高分了。(这个复杂度似乎是 \(80\) 分)
我们发现原题实际上就是想维护一个可重集合的 \(\operatorname{lcm}\),支持询问删除 \(2\) 个数,增加 \(1\) 个数之后新的 \(\operatorname{lcm}\) 的操作。询问之间互相独立(一次询问不会真的增删数)
但是发现 \(\operatorname{lcm}\) 有可能非常大,很有可能不能直接算。
于是有了这样的启发:考虑对每个 \(r_i\) 质因数分解,然后取每个质因子的幂次最大值计算结果。不过事实上我们后面还要获取两个环合并后长度的质因数分解,他可能不在 \(r_i\) 中,所以我们需要把 \(n\) 以内的数都预处理质因数分解好。
注意这里有一个小技巧:将 \(2\) 到 \(n\) 所有数质因数分解,可以先对 \(2\) 到 \(n\) 跑线性筛,同时记录每个数的最小质因子。然后再对 \(2\) 到 \(n\) 每个数枚举,对于一个数,不断除以它的最小质因子,直到除尽,再把除尽后剩下的数接着不断除以它的最小质因子……直到分解到剩下 \(1\) 为止。这样因式分解的复杂度可以从 \(\operatorname{O}(n \sqrt n)\) 优化到 \(\operatorname{O}(n \log n)\)。
那么就可以转化为维护若干个质数幂(所有环长的质因数分解出来的所有质因子幂的并集,同样,是可重集),支持询问删除 \(2\) 个数对应的质因子幂,增加 \(1\) 个数对应的质因子幂的情况下,每一个质因子的最大幂的乘积(就是 \(\operatorname{lcm}\))。询问互相独立。
然后发现一开始那个集合只用记录下所有质因子幂中,每个质数对应最大的 \(3\) 个幂,因为后面的不可能影响到 \(\operatorname{lcm}\)。比如如果集合里有 \(2^2, 2^3, 2^4, 2^7\),那么 \(2^2\) 就是没有用的。因为删掉两个数后,\(2^3, 2^4, 2^7\) 会至少剩下一个,轮不到 \(2^2\) 头上,因此它可以直接放弃统计。
所以询问直接暴力删暴力加暴力获取最大值即可,一次询问中,每个质因数的暴力都是小常数级别的,所以单次询问是 \(\operatorname{O}(\log n)\) 的。
总复杂度 \(\operatorname{O}(n \log n)\)。小常数可以和跑不太满的 \(\log n\) 抵消抵消。
另外,实际上不需要建图,只需要写一个维护大小的并查集即可。
\(\mathtt{Time} \text{ } \mathtt{Complexity}\)
单个测试数据 \(\operatorname{O}(n \log n)\)。
\(\mathtt{Code}\)
#include <bits/stdc++.h>
#define int long long
inline int read() {
int x = 0;
bool flag = true;
char ch = getchar();
while (!isdigit(ch)) {
if (ch == '-')
flag = false;
ch = getchar();
}
while (isdigit(ch)) {
x = (x << 1) + (x << 3) + ch - '0';
ch = getchar();
}
if(flag)
return x;
return ~(x - 1);
}
inline bool updmax(int &x, int y) {
return y > x ? x = y, true : false;
}
const int maxn = 500005;
const int maxm = 805; // sqrt(maxn)
const int mod = (int)1e9 + 7;
int a[maxn];
int inv[maxn], pfmin[maxn]; // prime factor min,存放了一个数的最小质因子。
int pr[maxn], pcnt = 0;
bool isp[maxn];
int lcm = 1;
std :: vector <std :: pair <int, int> > pfs[maxn];
// pfs[i] 存的是 i 的质因数分解,为一个 pair <int, int> 数组。
// pair 的第一个元素是质因子,第二个元素是质因子对应的幂(不是指数,因为在这个题里没必要)。
// 具体看代码,代码比这些文字好懂。
inline void pre(int n = maxn - 5) {
inv[1] = pfmin[1] = 1;
for (int i = 2; i <= n; ++i)
inv[i] = (mod - mod / i) * inv[mod % i] % mod;
std :: memset(isp, true, sizeof(isp));
for (int i = 2; i <= n; ++i) {
if (isp[i]) {
pr[++pcnt] = i;
pfmin[i] = i;
}
for (int j = 1; j <= pcnt && i * pr[j] <= n; ++j) {
isp[i * pr[j]] = false;
pfmin[i * pr[j]] = pr[j];
if (i % pr[j] == 0)
break;
}
}
for (int i = 2; i <= n; ++i) {
int t = i;
while (t != 1) {
int p = pfmin[t], q = 1;
while (t % p == 0) {
q *= p;
t /= p;
}
pfs[i].emplace_back(p, q);
// printf("%lld %lld %lld\n", i, p, q);
}
}
}
int siz[maxn], fa[maxn];
inline int find(int x) {
while (x != fa[x])
x = fa[x] = fa[fa[x]];
return x;
}
inline void uni(int x, int y) {
x = find(x);
y = find(y);
if (x == y)
return ;
if (siz[x] > siz[y])
x ^= y ^= x ^= y;
fa[x] = y;
siz[y] += siz[x];
}
int cnt[maxn];
std :: vector <int> f[maxn];
inline void insert(int x) {
// printf("%lld\n", x);
for (auto v : pfs[x]) {
int p = v.first, q = v.second;
// printf("%lld %lld\n", p, q);
f[p].push_back(q);
std :: sort(f[p].begin(), f[p].end(), std :: greater <int> ());
// 这里 sort 可以看做常数级别,因为 f[p] 始终大小不超过 3
if (f[p].size() > 3)
f[p].pop_back();
}
return ;
}
int s[maxm], m;
std :: vector <std :: pair <int, int> > g[maxn];
// g[p][i] 表示第 i 个关于质数 p 的幂的修改,first 表示幂的值,second 表示修改量(1 / -1)
// 这个是我们的修改实现,举例说明:
// 删除 12 这个数,先质因数分解 2 ^ 2 * 3
// 然后转化成删掉两个质因子幂,一个 2 ^ 2,一个 3。
// 相当于我们把 2 ^ 2 和 3 的出现次数在集合中分别削了 1,所以 -1 就是两个修改的修改量
// 具体看代码。
int tcnt[maxn];
inline int getv(int p) {
int z = 1;
for (int q : f[p])
++tcnt[q];
for (auto v : g[p])
tcnt[v.first] += v.second;
for (int q : f[p]) {
if (tcnt[q] != 0) {
// 注意!!为什么这里要写成 != 0 而不能是 > 0!!!
// 首先,我们想:tcnt[q] 有可能小于 0 吗?
// 其实是可以构造的,只需要让 f[p][2] 这个质因子幂被删两次就可以了。
// (也就是说 f[p][2] 和 f[p][3](事实上没有)这两个质因子幂相同,而且恰好都被删,
// 但是因为 f[p][3] 因为只存前三个的原则并没有记录,所以 f[p][2] 会被记录一次删除两次。
// 所以 tcnt[q] < 0 是有可能的。
// 由于我们 tcnt[q] 是边扫边清零的(看下面第二行),为了清零成功,我们需要把 < 0 的也清零。
// updmax(z, q) 会被影响吗?
// 我们一次最多删两个数,那么 f[p][2] 被删了两次,f[p][0] 和 f[p][1] 肯定没被删过。
// 那么这一轮的 z 肯定会成功识别出 f[p][0],所以没有影响。
updmax(z, q);
tcnt[q] = 0;
}
}
for (auto v : g[p]) {
int q = v.first;
if (tcnt[q] != 0) {
// 这里同上,不能写 > 0。
// 这里 < 0 是因为可能会有删掉的质因子幂因为不是前三大没记录在 f 中。
updmax(z, q);
tcnt[q] = 0;
}
}
return z;
}
inline void modify(int x, int val) {
for (auto v : pfs[x]) {
int p = v.first, q = v.second;
(lcm *= inv[getv(p)]) %= mod;
g[p].push_back(std :: make_pair(q, val));
(lcm *= getv(p)) %= mod;
// 把 lcm 暴力除以原来 p 这里的贡献,修改之后再暴力乘回去。
}
}
inline void rec(int x) {
for (auto v : pfs[x])
g[v.first].clear();
// 清空修改
}
inline void init(int n = maxn - 5) {
std :: fill(siz + 1, siz + 1 + n, 1);
std :: iota(fa + 1, fa + 1 + n, 1);
std :: memset(cnt, 0, sizeof(cnt));
std :: memset(s, 0, sizeof(s));
m = 0;
for (int i = 1; i <= n; ++i)
f[i].clear();
lcm = 1;
}
signed main() {
int T = read();
pre();
while (T--) {
init();
int n = read();
for (int i = 1; i <= n; ++i) {
a[i] = read();
uni(i, a[i]);
}
for (int i = 1; i <= n; ++i) {
if (find(i) == i) {
++cnt[siz[i]];
insert(siz[i]);
// printf("%lld ", siz[i]);
}
}
for (int i = 1; i <= n; ++i)
if (cnt[i] > 0)
s[++m] = i;
for (int i = 1; i <= n; ++i) {
if (!f[i].empty())
(lcm *= f[i][0]) %= mod;
// 初始 lcm
}
// printf("%lld\n", lcm);
int ans = 0;
for (int i = 1; i <= m; ++i) {
int u = s[i];
if (cnt[u] >= 2) {
// puts("meitain");
int org = lcm;
modify(u << 1, 1);
modify(u, -1);
modify(u, -1);
// printf("%lld\n", lcm);
(ans += lcm * cnt[u] % mod * u % mod * (cnt[u] - 1) % mod * u % mod) %= mod;
rec(u << 1);
lcm = org;
}
for (int j = i + 1; j <= m; ++j) {
int v = s[j], org = lcm;
modify(u + v, 1);
modify(u, -1);
modify(v, -1);
(ans += 2 * lcm % mod * cnt[u] % mod * u % mod * cnt[v] % mod * v % mod) %= mod;
rec(u + v);
rec(u);
rec(v);
lcm = org;
}
}
printf("%lld\n", ans);
}
return 0;
}