0. 参考与前言
论文链接:https://ieeexplore.ieee.org/document/9812507
代码链接:https://github.com/PRBonn/make_it_dense
vdbfusion同组所出,自监督的scan completion,第一幅非常直白的表明了这个工作在做的任务,虽然数据结构 数据集不一样,但是很像grid map,elevation map 2.5D那边的补全,不过这个是mesh的surface mesh输出
1. Motivation
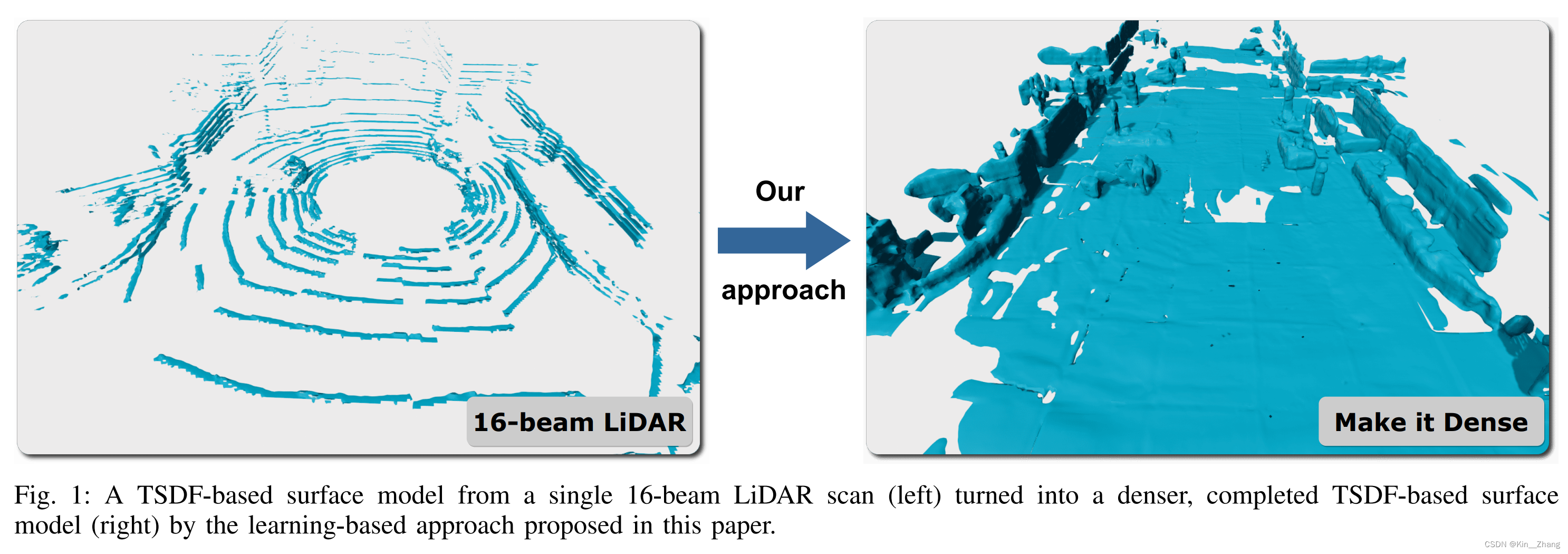
主要是为稀疏的点云输入,给一个dense的输出结果,首先是使用了vdbfusion的框架,然后propose a neural network去帮助frame-to-frame的3D 重建,走到 dense TSDF volume,这个基于一个 geometric scan completion network,是无需label的自监督训练
问题场景
主要是雷达的线束是16-128线,而价格也随线束的增加而线性增加,所以问题随之而来了:是否可以使用一个较为稀疏的信息,也能得到一个dense results map。[37] 中提到了这一问题的重要性,也就是无需积累帧数之间的数据结构也能得到一个dense observation,同时给到导航任务中
Contribution
提出了一个自监督的方法,可以将稀疏的3D激光雷达数据转成dense TSDF representation下的场景;与[10,19,37]不同之处是:we aim at completing single scans instead of completing a scene created from aggregated scans offline. 同时在相关工作中,也再次强调了这点:In contrast to these methods, which work on the aggregated volumes, we target the single scan setting to avoid the time-consuming buffering of scans.
过程主要是:
- we process the 3D LiDAR data and pass it to our CNN. The output of the network is a TSDF representation
- TSDF representation encodes the most recent observation plus synthetically completed data, which is then fused into a global map.
2. Method
- 使用单帧信息构建基于TSDF的volumetric representation,这样可以得到 \(\boldsymbol D_t^S(\bf x)\) 和 权重 \(\boldsymbol W_t^S(\bf x)\) 其中 \(\bf x\) 为voxel在grid中的位置
- 使用 \(\boldsymbol D_t^S(\bf x)\) 通过网络预测一个新的 TSDF value 我们用 \(\boldsymbol D_t^P(\bf x)\) 表示;网络目的:The network is trained to fill in values in a self-supervised way as if the data would have been recorded with a high-resolution LiDAR.
- 当 grids之间全局匹配时,我们将 预测的 \(\boldsymbol D_t^P(\bf x)\) 放入 global grid中去 \(\boldsymbol D_t^G(\bf x)\);然后由global signed distance fields 使用marching cubes [16] 得到surface representation
2.1 框架

输入:instead of raw data, 主要使用batch of TSDF volumes作为网络输入,原因主要是 TSDF的表达可以 split into non-overlapping volumes of 3.2 m^3;These volumes are batched together into a dense multidimensional tensor and then feed to our network
网络主要使用的是3D-UNet [6, 30],首先使用dense 3D convolutions 去增加通道数量;然后每一步的encoder增加output通道;然后以unet形式,前后 skip connect,具体可以看代码,定义的很清晰:
class ResNetBlock3d(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.conv1 = nn.Conv3d(in_channels, out_channels, kernel_size=3, padding=1, bias=False)
self.bn1 = nn.BatchNorm3d(out_channels)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv3d(out_channels, out_channels, kernel_size=3, padding=1, bias=False)
self.bn2 = nn.BatchNorm3d(out_channels)
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += identity
out = self.relu(out)
return out
class Unet3D(nn.Module):
def __init__(self, channels: List[int], layers_down: List[int], layers_up: List[int]):
super().__init__()
self.layers_down = nn.ModuleList()
self.layers_down.append(ResNetBlock3d(channels[0], channels[0]))
for i in range(1, len(channels)):
layer = [
nn.Conv3d(
channels[i - 1], channels[i], kernel_size=3, stride=2, padding=1, bias=False
),
nn.BatchNorm3d(channels[i]),
nn.ReLU(inplace=True),
]
# Do we need 4 resnet blocks here?
layer += [ResNetBlock3d(channels[i], channels[i]) for _ in range(layers_down[i])]
self.layers_down.append(nn.Sequential(*layer))
channels = channels[::-1]
self.layers_up_conv = nn.ModuleList()
for i in range(1, len(channels)):
self.layers_up_conv.append(
nn.Sequential(
nn.ConvTranspose3d(
channels[i - 1], channels[i], kernel_size=2, stride=2, bias=False
),
nn.BatchNorm3d(channels[i]),
nn.ReLU(inplace=True),
nn.Conv3d(channels[i], channels[i], kernel_size=3, padding=1, bias=False),
nn.BatchNorm3d(channels[i]),
nn.ReLU(inplace=True),
)
)
self.layers_up_res = nn.ModuleList()
for i in range(1, len(channels)):
layer = [ResNetBlock3d(channels[i], channels[i]) for _ in range(layers_up[i - 1])]
self.layers_up_res.append(nn.Sequential(*layer))
def forward(self, x):
xs = []
for layer in self.layers_down:
x = layer(x)
xs.append(x)
xs.reverse()
out = []
for i in range(len(self.layers_up_conv)):
x = self.layers_up_conv[i](x)
x = (x + xs[i + 1]) / 2.0
x = self.layers_up_res[i](x)
out.append(x)
return out
总网络借鉴的是Atlas [19] :
class AtlasNet(nn.Module):
def __init__(self, config: MkdConfig):
# xxx
# Network
self.feature_extractor = FeatureExtractor(channels=self.f_maps[0])
self.unet = Unet3D(
channels=self.f_maps,
layers_down=self.layers_down,
layers_up=self.layers_up,
)
self.decoders = nn.ModuleList(
[nn.Conv3d(c, 1, 1, bias=False) for c in self.f_maps[:-1]][::-1]
)
def forward(self, xs):
feats = self.feature_extractor(xs)
out = self.unet(feats)
output = {}
mask_occupied = []
for i, (decoder, x) in enumerate(zip(self.decoders, out)):
# regress the TSDF
tsdf = torch.tanh(decoder(x)) * 1.05
# use previous scale to sparsify current scale
if i > 0:
tsdf_prev = output[f"out_tsdf_{self.voxel_sizes[i - 1]}"]
tsdf_prev = F.interpolate(tsdf_prev, scale_factor=2)
mask_truncated = tsdf_prev.abs() >= self.occ_th[i - 1]
tsdf[mask_truncated] = tsdf_prev[mask_truncated].sign()
mask_occupied.append(~mask_truncated)
output[f"out_tsdf_{ self.voxel_sizes[i]}"] = tsdf
return output, mask_occupied
2.2 Multi-Resolution Loss
loss设计很有意思,在提前定好的每个分辨率(32cm, 16cm, 8cm) 都给出了一个l1 loss,然后sum起来,代码对应如下;公式对应,首先是sdf的转换,
\[\phi(x)=\operatorname{sgn}(x) \cdot \log (|x|+1) \]然后分辨率下的loss,
\[\mathcal{L}\left(\hat{D}_i, D_i\right)=\sum_{\mathbf{x} \in \mathcal{R}_i}\left\|\phi\left(\hat{D}_i(\mathbf{x})\right)-\phi\left(D_i(\mathbf{x})\right)\right\|_1 \]class SDFLoss(nn.Module):
def __init__(self, config: MkdConfig):
super().__init__()
self.config = config.loss
self.voxel_sizes = config.fusion.voxel_sizes
self.sdf_trunc = np.float32(1.0)
self.l1_loss = nn.L1Loss()
@staticmethod
def log_transform(sdf):
return sdf.sign() * (sdf.abs() + 1.0).log()
def forward(self, output, mask_occupied, targets):
losses = {}
for i, voxel_size_cm in enumerate(self.voxel_sizes):
pred = output[f"out_tsdf_{voxel_size_cm}"]
trgt = targets[f"gt_tsdf_{voxel_size_cm}"]["nodes"]
# Apply masking for the loss function
mask_observed = trgt.abs() < self.config.mask_occ_weight * self.sdf_trunc
planes = trgt == self.sdf_trunc
# Search for truncated planes along the target volume on X, Y, Z directions
if self.config.mask_plane_loss:
mask_planes = (
planes.all(-1, keepdim=True)
| planes.all(-2, keepdim=True)
| planes.all(-3, keepdim=True)
)
mask = mask_observed | mask_planes
else:
mask = mask_observed
mask &= mask_occupied[i - 1] if (i != 0 and self.config.mask_l1_loss) else True
if self.config.use_log_transform:
pred = self.log_transform(pred)
trgt = self.log_transform(trgt)
losses[f"{voxel_size_cm}"] = F.l1_loss(pred[mask], trgt[mask])
return losses
最后是整个sum,代码就是直接output sum起来了
# Compute Loss function
losses = self.loss(outputs, masks, targets)
loss = sum(losses.values())
2.3 Global Update
当我们获得了两个观测值后,一个是sensor data,一个是网络输出的,我们就可以将其整合到全局的grid下了,引入了一个权重,来指定 how much more we want to trust an actual measurement over a predicted TSDF value. 也就是下列公式所表示的,实验过程 让我们经验性的选择了 \(\eta=0.7\)
\[\begin{aligned}\Delta \mathbf{D}(\mathbf{x}) &=\eta \boldsymbol{W}_t^S(\mathbf{x}) \boldsymbol{D}_t^S(\mathbf{x})+(1-\eta) \boldsymbol{W}_t^P(\mathbf{x}) \boldsymbol{D}_{\underline{t}}^P(\mathbf{x}) \\\Delta \mathbf{W}(\mathbf{x}) &=\eta \boldsymbol{W}_t^S(\mathbf{x})+(1-\eta) \boldsymbol{W}_t^P(\mathbf{x})\end{aligned} \]当我们获得 \(\Delta \mathbf{D}\) 后 通过 [7] 所示 fuse for all voxels at location x
\[\begin{aligned} \boldsymbol{D}_t^G(\mathrm{x}) &=\frac{\boldsymbol{W}_{t-1}^G(\mathrm{x}) \cdot \boldsymbol{D}_{t-1}^G(\mathrm{x})+\Delta \mathbf{D}(\mathrm{x})}{\boldsymbol{W}_{t-1}^G(\mathrm{x})+\Delta \mathbf{W}(\mathrm{x})} \\ \boldsymbol{W}_t^G(\mathrm{x}) &=\boldsymbol{W}_{t-1}^G(\mathrm{x})+\Delta \mathbf{W}(\mathrm{x}) \end{aligned} \]代码对应 由vdbfusion那边调用的函数:
from vdbfusion import VDBVolume
self._global_map = VDBVolume(
self._config.voxel_size,
self._config.vox_trunc * self._config.voxel_size,
self._config.space_carving,
)
self._global_map.integrate(scan, pose, weight=self._config.eta)
self._global_map.integrate(grid=self.make_it_dense(scan), weight=1 - self._config.eta)
C++ vdbfusion那边是:
void VDBVolume::Integrate(openvdb::FloatGrid::Ptr grid,
const std::function<float(float)>& weighting_function) {
for (auto iter = grid->cbeginValueOn(); iter.test(); ++iter) {
const auto& sdf = iter.getValue();
const auto& voxel = iter.getCoord();
this->UpdateTSDF(sdf, voxel, weighting_function);
}
}
void VDBVolume::UpdateTSDF(const float& sdf,
const openvdb::Coord& voxel,
const std::function<float(float)>& weighting_function) {
using AccessorRW = openvdb::tree::ValueAccessorRW<openvdb::FloatTree>;
if (sdf > -sdf_trunc_) {
AccessorRW tsdf_acc = AccessorRW(tsdf_->tree());
AccessorRW weights_acc = AccessorRW(weights_->tree());
const float tsdf = std::min(sdf_trunc_, sdf);
const float weight = weighting_function(sdf);
const float last_weight = weights_acc.getValue(voxel);
const float last_tsdf = tsdf_acc.getValue(voxel);
const float new_weight = weight + last_weight;
const float new_tsdf = (last_tsdf * last_weight + tsdf * weight) / (new_weight);
tsdf_acc.setValue(voxel, new_tsdf);
weights_acc.setValue(voxel, new_weight);
}
}
3. 实验及结果
定量分析:
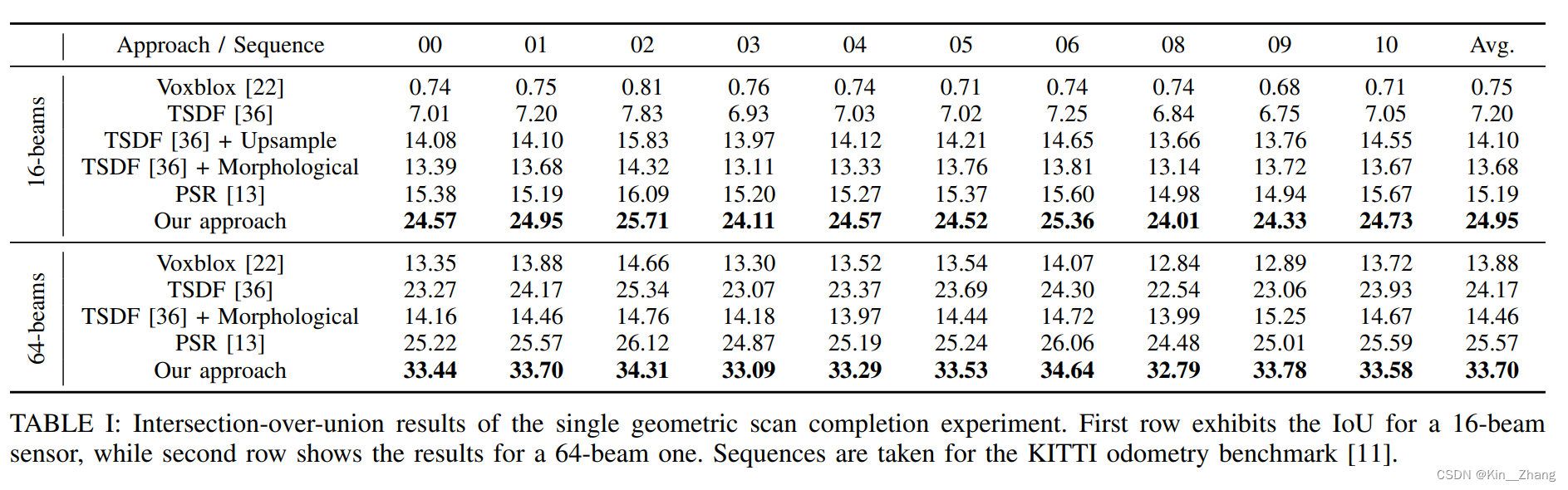
定性分析

更多可查看原文
4. Conclusion
总结方法:We combine traditional TSDF-based volumetric mapping with 3D convolutional neural networks to aid reconstruction on a frame-to-frame basis.
主要局限性是,data本身的稀疏性,可以尝试sparse convolutions 从而有效减少内存消耗和提升运行效率 (确实可以试试
赠人点赞 手有余香
标签:Completion,Outdoor,Dense,nn,self,mask,channels,tsdf,out From: https://www.cnblogs.com/kin-zhang/p/17031974.html