通过了解 CH 的几大特性了解千亿级企业 ClickHouse 实时处理引擎架构设计、核心技术设计、运行机理全流程。
- 1 初始 ClickHouse
- 1.1 什么是 ClickHouse
- 1.2 ClickHouse 的优缺点
- 1.3 谁在用 ClickHouse
- 3 数据引擎
- 3.1 库引擎
- 3.2 表引擎
- 3.3 MergeTree 引擎
- 4 工作原理
- 4.1 数据分区
- 4.2 列式存储
- 4.3 一级索引
- 4.4 二级索引
- 4.5 数据压缩
- 4.6 数据标记
- 5 查询流程
- ref
1 初始 ClickHouse
1.1 什么是 ClickHouse
ClickHouse 全称 Click Stream, Data WareHouse,是一个用于联机分析 (OLAP) 的列式数据库管理系统 (DBMS)。由俄罗斯本土搜索引擎企业 Yandex 公司为了自己公司自家的 Web 流量分析产品 Yandex.Metrica 开发,后来经过演变,逐渐形成为现在的 ClickHouse。
1.2 ClickHouse 的优缺点
- ClickHouse 的优点
ClickHouse 具有 ROLAP、在线实时查询、完整的 DBMS 功能支持、列式存储、不需要任何数据预处理、支持批量更新、拥有非常完善的 SQL 支持和函数、支持高可用、不依赖 Hadoop 复杂生态、开箱即用等许多特点。
在 1 亿数据集体量的情况下,ClickHouse 的平均响应速度是 Vertica 的 2.63 倍、InfiniDB 的 17 倍、MonetDB 的 27 倍、Hive 的 126 倍、MySQL 的 429 倍以及Greenplum 的 10 倍。测试结果:https://clickhouse.tech/benchmark/dbms/。
ClickHouse 虽然有这么多特点和优点,但显然也存在一些劣势:
- 没有完整的事务支持;
- 稀疏索引导致 ClickHouse 不擅长细粒度或者 key-value 类型数据的查询需求;
- 缺少高频率,低延迟的修改或删除已存在数据的能力。仅能用于批量删除或修改数据;
- 不擅长 join 操作,且语法特殊;
- 由于采用并行处理机制,即使一个查询也会使用一半 CPU 资源,所以不支持高并发。
1.3 谁在用 ClickHouse
ClickHouse 非常适用于商业智能领域(也就是我们所说的 BI 领域),除此之外,它也能够被广泛应用于广告流量、Web、App 流量、电信、金融、电子 商务、信息安全、网络游戏、物联网等众多其他领域。
ClickHouse 是近年来备受关注的开源列式数据库,主要用于数据分析(OLAP)领域。目前国内社区火热,各个大厂纷纷跟进大规模使用:
- 今日头条内部用 ClickHouse 来做用户行为分析,内部一共几千个 ClickHouse 节点,单集群最大 1200 节点,总数据量几十 PB,日增原始数据 300TB 左右。
- 腾讯内部用 ClickHouse 做游戏数据分析,并且为之建立了一整套监控运维体系。
- 携程内部从 18 年 7 月份开始接入试用,目前 80% 的业务都跑在 ClickHouse 上。每天数据增量十多亿,近百万次查询请求。
- 快手内部也在使用 ClickHouse,存储总量大约 10PB, 每天新增 200TB, 90% 查询小于 3S。
3 数据引擎
ClickHouse 是一个 OLAP 分析型数据库,也有库和表的概念,而且库和表还都提供了不同类型的引擎,所以关于 ClickHouse 的底层引擎可以分为「数据库引擎」和「表引擎」两种。
3.1 库引擎
ClickHouse 支持在创建库的时候指定库引擎,目前支持 5 种,分别是:Ordinary,Dictionary, Memory, Lazy, MySQL。其中 Ordinary 是默认库引擎,在此类型库引擎下,可以使用任意类型的表引擎。
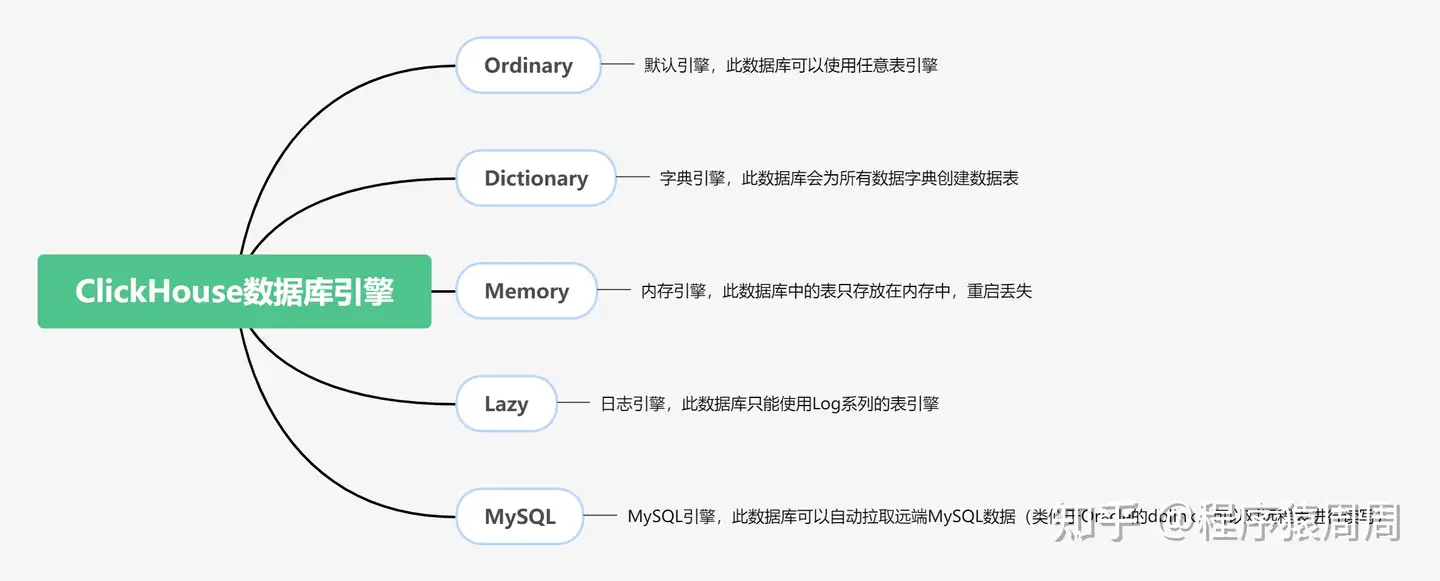
- 「Ordinary 引擎」:默认引擎,如果不指定数据库引擎创建的就是 Ordinary 数据库;
- 「Dictionary 引擎」:此数据库会自动为所有数据字典创建表;
- 「Memory 引擎」:所有数据只会保存在内存中,服务重启数据消失,该数据库引擎只能够创建 Memory 引擎表;
- 「MySQL 引擎」:改引擎会自动拉取远端 MySQL 中的数据,并在该库下创建 MySQL 表引擎的数据表;
- 「Lazy 延时引擎」:在距最近一次访问间隔
expiration_time_in_seconds时间段内,将表保存在内存中,仅适用于 Log 引擎表。
3.2 表引擎
相比于库引擎,表引擎在 ClickHouse 中的地位更加核心,它直接决定了 CH 中数据如何存储和读取,是否支持并发读写和 Idex 等等。
具体可看官网:https://clickhouse.tech/docs/zh/engines/table-engines/
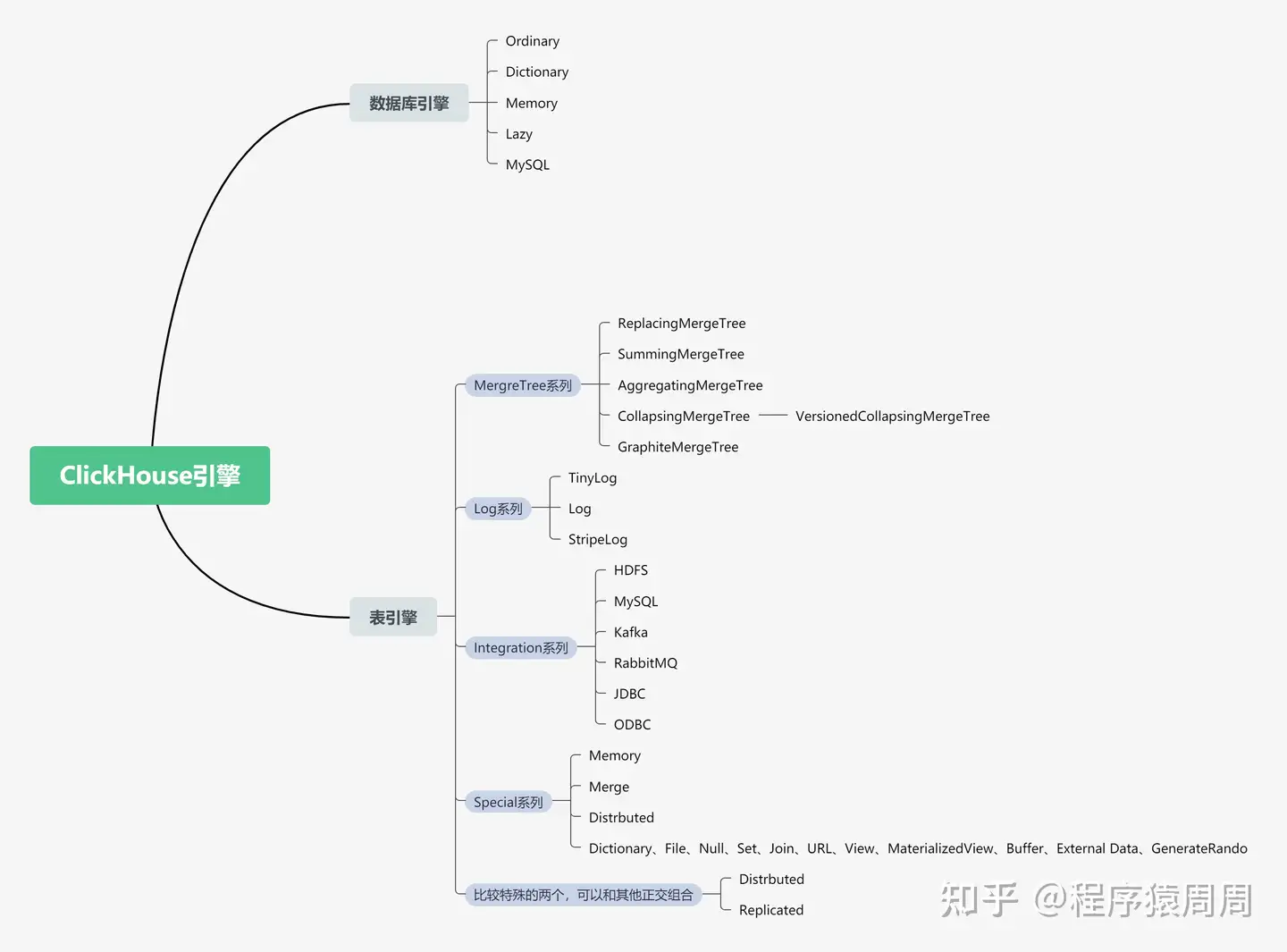
ClickHouse 的表引擎提供了四个系列(Log、MergeTree、Integration、Special)大约 28 种表引擎,各有各的用途。比如 Log 系列用来做小表数据分 析,MergeTree 系列用来做大数据量分析,而 Integration 系列则多用于外表数据集成。Log、Special、Integration 系列的表引擎相对来说,应用场景有限,功能简单,应用特殊用途,MergeTree 系列表引擎又和两种特殊表引擎(Replicated,Distributed)正交形成多种具备不同功能的 MergeTree 表引擎。
3.3 MergeTree 引擎
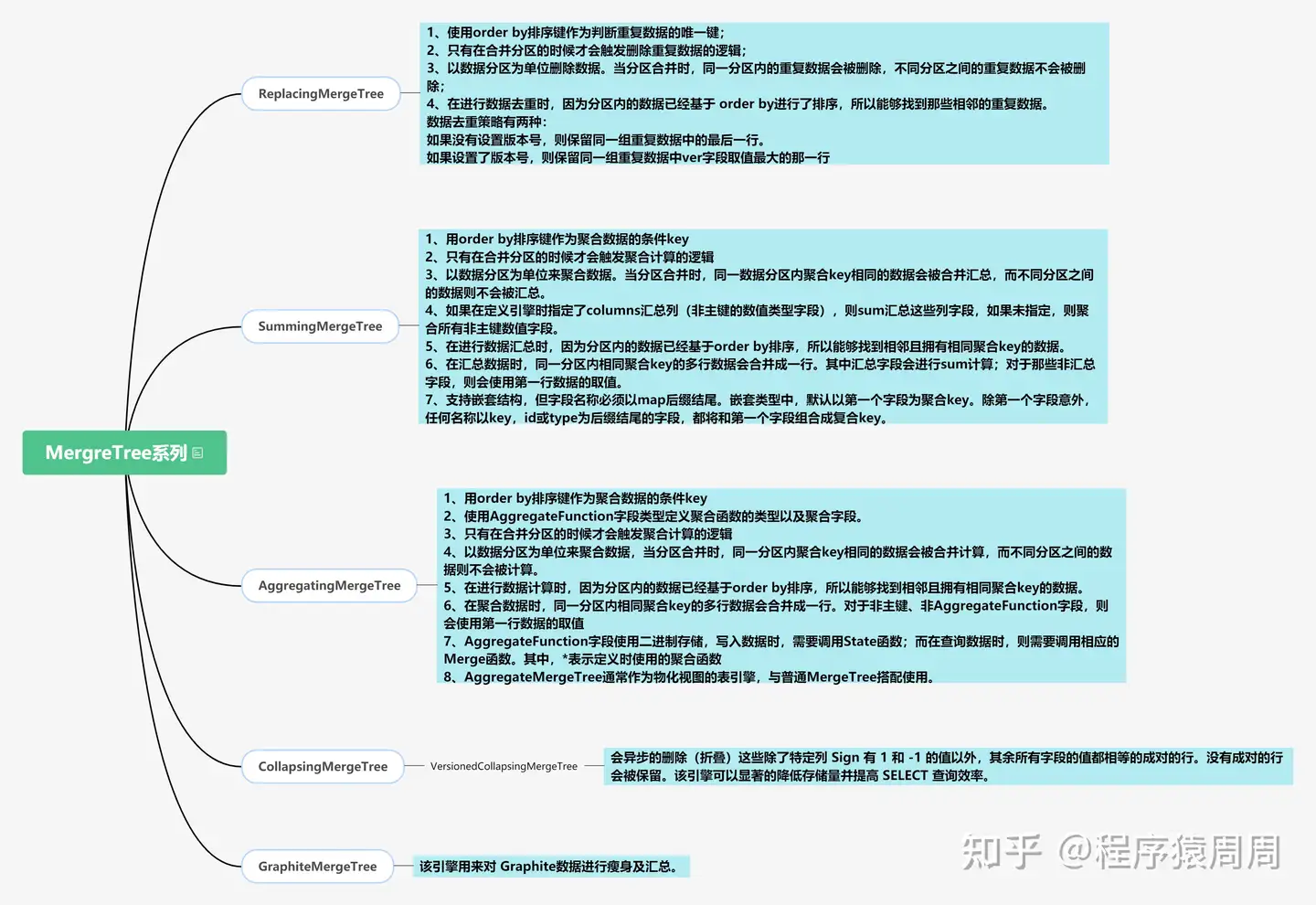
MergeTree 系列是 ClickHouse 官方主推的存储引擎,几乎支持全部的核心功能,该系列中,常用的表引擎有:MergeTree、ReplacingMergeTree、 CollapsingMergeTree、 VersionedCollapsingMergeTree、 SummingMergeTree、 AggregatingMergeTree 等。
「关于 MergeTree 的特性」
原生 MergeTree 表引擎主要用于海量数据分析,支持数据分区、存储有序、主键索引、稀疏索引、数据 TTL 等。MergeTree 支持所有ClickHouse SQL 语法,但是有些功能与 MySQL 并不一致,比如在 MergeTree 中主键并不用于去重。
为了解决 MergeTree 相同主键无法去重的问题,ClickHouse 提供了 ReplacingMergeTree 引擎,用来做去重。ReplacingMergeTree 确保数据最终被去重,但是无法保证查询过程中主键不重复。因为相同主键的数据可能被 shard 到不同的节点,但是 compaction 只能在一个节点中进行,而且 optimize 的时机也不确定。
解决删除场景,CollapsingMergeTree 引擎要求在建表语句中指定一个标记列 Sign(插入的时候指定为 1,删除的时候指定为 -1),后台 Compaction 时会将主键相同、Sign 相反的行进行折叠,也即删除。来消除 ReplacingMergeTree 的限制。
为了解决 CollapsingMergeTree 乱序写入情况下无法正常折叠问题,VersionedCollapsingMergeTree 表引擎在建表语句中新增了一 列 Version,用于在乱序情况下记录状态行与取消行的对应关系。主键相同,且 Version 相同、Sign 相反的行,在 Compaction 时会被删除。
解决聚合场景,ClickHouse 通过 SummingMergeTree 来支持对主键列进行预先聚合。在后台 Compaction 时,会将主键相同的多行进行 sum 求 和,然后使用一行数据取而代之,从而大幅度降低存储空间占用,提升聚合计算性能。同理还有 AggregatingMergeTree用来预聚合平均值。
「MergeTree 的建表语法」
CREATE TABLE [IF NOT EXISTS] [db_name.]table_name ( name1 [type] [DEFAULT|MATERIALIZED|ALIAS expr], name2 [type] [DEFAUErEMAMLERLALLIZED|ALIAS expr], 省略...
) ENGINE = MergeTree()
[PARTITION BY expr]
[ORDER BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[SETTINGS name=value, 省略...]
其中几个关键选项:
| 键 | 名称 | 必填 | 说明 |
|---|---|---|---|
| 「PARTITION BY」 | 分区键 | 否 | 指定表数据以何种标准进行分区,分区键既可以是单个列字段,也可以是多个列字段,同时也支持使用列表达式。如果没有执行分区字段,则所有数据都在一个分区里 |
| 「ORDER BY」 | 排序键 | 是 | 用于指定在一个数据片段内,数据以何种标准排序。通常与主键相同 |
| 「PRIMARY KEY」 | 主键 | 是 | 声明后会依照主键字段生成一级索引。通常与主键相同 |
| 「SETTINGS」 | 索引粒度 | 否 | 默认值为 8192,即 MergeTree 索引在默认每间隔 8192 行数据才生成一条索引 |
| 「SAMPLE BY」 | 抽样表达式 | 否 | 用于声明数据以何种标准进行采样 |
注意 「settings」 中的重要参数:
index_granularity默认是 8192 = 1024 * 8, 推荐不修改index_granularity_bytes默认 10M,需要通过 enable_mixed_granularity_parts 来开启enable_mixed_granularity_parts默认开启自适应索引粒度merge_with_ttl_timeout提供数据 TTL 功能。
「值得注意的是,MergeTree 主键索引是稀疏索引(一段数据创建一条索引)」。而每一条数据都生成索引则是「稠密索引」。
4 工作原理
ClickHouse 从 OLAP 场景需求出发,定制开发了一套全新的高效列式存储引擎,并且实现了数据有序存储、主键索引、稀疏索引、数据 Sharding、数据 Partitioning、TTL、主备复制等丰富功能。这些功能共同为 ClickHouse 极速的分析性能奠定了基础。
4.1 数据分区
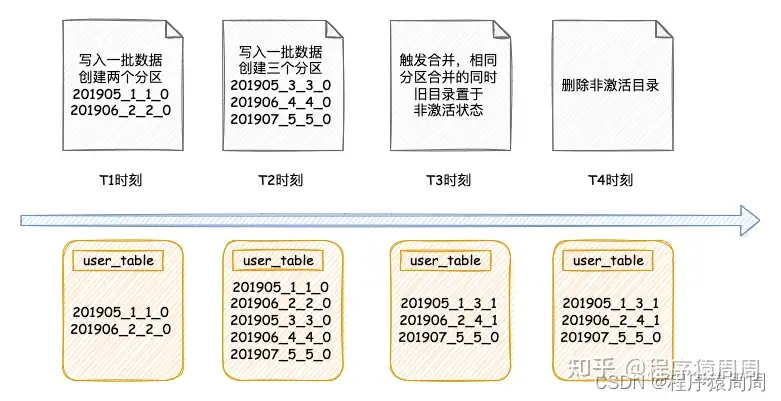
从物理结构来看,所谓「数据分区」,就是将所有一张表的说有数据按照某个维度划分成多个子文件夹。「与其他数据库以追加方式写入不同的是,MergeTree 每一批数据的写入(insert)都会生成一批新的分区目录」。在之后的某个时刻(写入后的 10~15 分钟,也可以手动执行 optimize 查询语句),ClickHouse 会通过后台任务再将属于相同分区的多个目录合并成一个新的目录。已经存在的旧分区目录也不会立即被删除,而是在之后的某个时刻通过后台任务被删除(默认 8 分钟)。
「分区文件夹的命名规则」
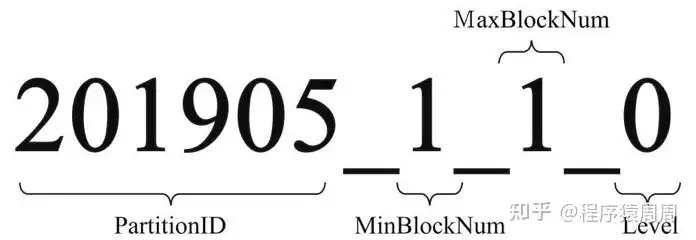
分区的命名规则:PartitionID_MinBlockNum_MaxBlockNum_Level:
1)partition_id:2021905,具体分区生成规则如下;
1)不指定分区键:如果建表时不指定分区键,则数据默认不分区,所有数据写到一个默认分区 all 里面。
2)使用整型:如果分区键取值属于整型且无法转换为日期类型 YYYVYMMDD 格式,则直接按照该整型的字符形式输出作为分区 ID 的取值。
3)使用日期类型:如果分区键取值属于日期类型,或者是能够转换为 YYYYMMDD 日期格式的整型,则按照分区表达式逻辑格式化后作为分区ID的取值。
4)使用其它类型:如果分区键取值既不属于整型,也不屋于日期类型,如 String、Float 等,则通过 128 位 Hash 算法取其 Hash 值作为分区 ID 的取值。
2)min_block_number:1,最小块编号,MergeTree引|擎从1开始计数,每次+1;
3)max block_number:1,最大块编号,新插入的数据,最小与最大编号一致;
4)level:0,这个可以理解为合并的次数,新插入的数据都是0,每合并1次+1。
「分区文件夹的合并规则」
 在这里插入图片描述
在这里插入图片描述
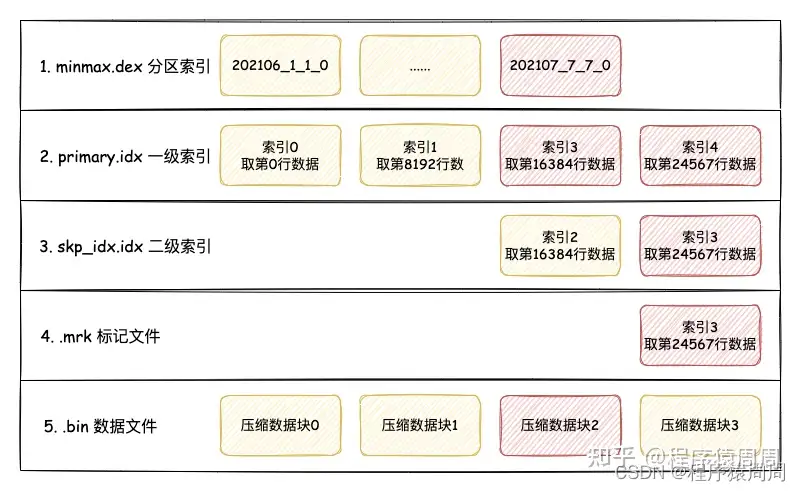
「分区文件夹中文件含义」
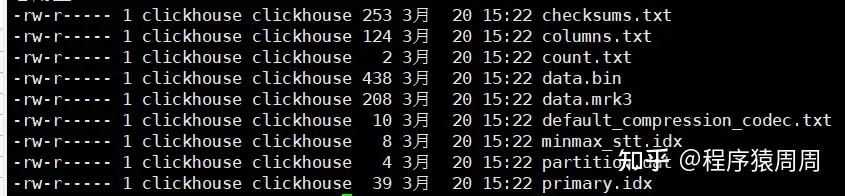
(这里是新版 mergtree 引擎,bin 和 mrk3 只有一个文件,老版本的是表中的每一个列都会有各自的一个 bin 和 mrk2 文件)
- checksums.txt 校验文件。使用二进制格式存储。它保存了余下各类文件(primary.idx、count.txt等)的 size 大小及 size 的哈希值,用于快速校 验文件的完整性和正确性。
- columns.txt 列信息文件,使用明文格式存储。用于保存此数据分区下的列字段信息 。
- count.txt 计数文件,使用明文格式存储。用于记录当前数据分区目录下数据的总行数。
- primary.idx 一级索引文件,主键索引文件。
- xxx.bin 数据文件,使用压缩格式存储,默认为 LZ4 压缩格式,用于存储某一列的数据,每一列都对应一个该文件,如列 date 为 date.bin。
- xxx.mrk2 列字段标记文件,如果使用了自适应大小的索引间隔,则标记文件以 .mrk2 命名,否则以 .mrk 命名。
- 还有二级索引 和 分区键相关信息文件,跳数索引文件等等
此处不展开,后面会详细介绍。
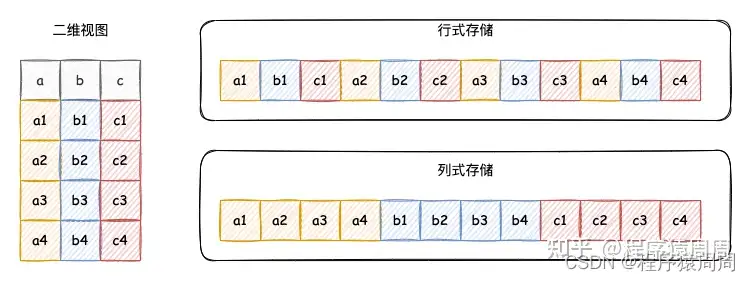
4.2 列式存储
因为 OLAP 一般都是对大量行、少量列做聚合分析,所以列式存储基本是必选方案,并且相比行式存储有以下几个优势:
- 「分析场景中往往需要读大量行但是少数几个列」。在行存模式下,数据按行连续存储,所有列的数据都存储在一个 block 中,不参与计算的列在 IO 时也要全部读出,读取操作被严重放大。而列存模式下,只需要读取参与计算的列即可,极大的减低了IO cost,加速了查询。
- 同一列中的数据属于同一类型,「压缩比高,数据压缩效果显著」。列存往往有着高达十倍甚至更高的压缩比,节省了大量的存储空间,降低了存储成本。
- 高压缩比意味着更小的 data size,从磁盘中读取相应数据耗时更短。同时也意味着同等大小的内存能够存放更多数据,系统cache效果更好。
- 根据不同类型自由选择压缩算法,可以针对不同列类型,选择最合适的压缩算法。
 在这里插入图片描述
在这里插入图片描述
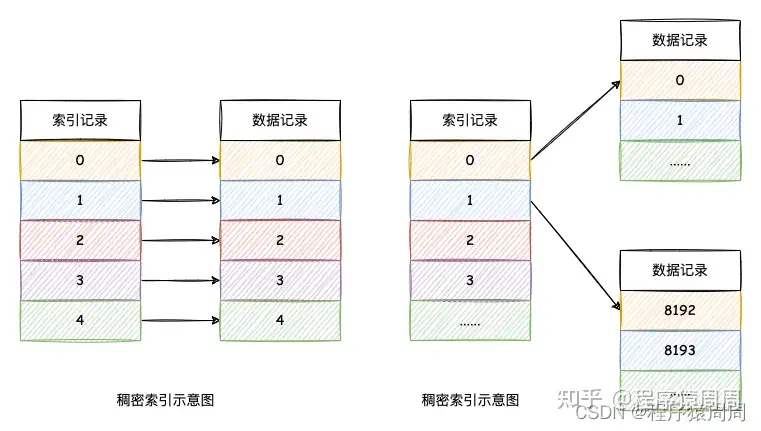
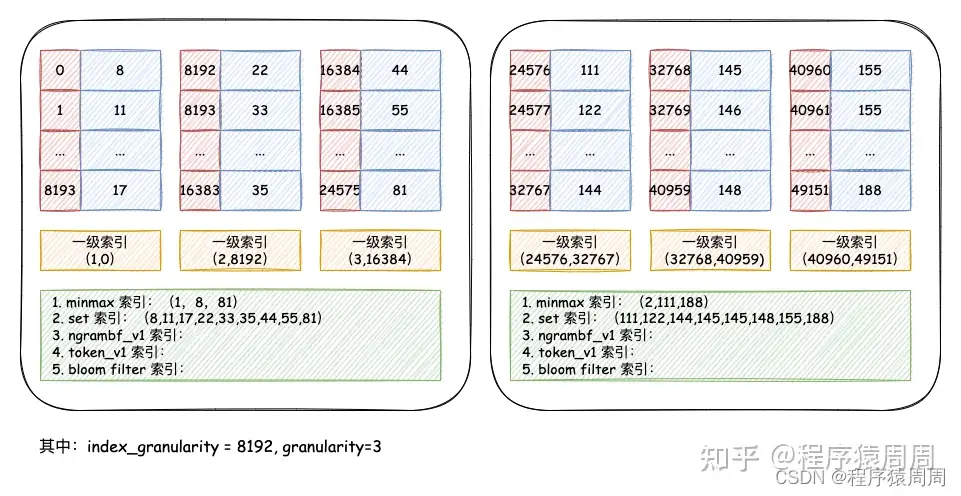
4.3 一级索引
使用 PRIMARY KEY 定义 MergeTree 的主键后,「会依据 index_granularity」 间隔(默认 8192 行)为数据表生成「一级索引」并保存至 primary.idx 文件内。一级索引是稀疏索引,其好处就是少量的索引标记就能记录大量的数据区间位置信息,在 ClickHouse 中,一级索引常驻内存。总的来说:一级索引和标记文件一一对齐,两个索引标记之间的数据就是一个数据区间,在数据文件中,这个数据区间的所有数据,生成一个压缩数据块。
 在这里插入图片描述
在这里插入图片描述
当然稀疏索引也有一个缺点就它并「不去重」。要想实现去重效果,需要结合具体的表引擎 ReplacingMergeTree、CollapsingMergeTree、VersionedCollapsingMergeTree 实现。
4.4 二级索引
ClickHouse 的「二级索引」又被称作「跳数索引」,其目的与「一级索引」一样,为了减少查找范围。但二级索引默认是关闭的,通过 granularity 参数控制粒度,开启后会在分区目录生成 skp_idx_[Column].idx 与 skp_idx_[Column].mrk 文件。二级索引的生成规则也很简单:每隔 granularity * index_granularity 条数据,就会 生成一条二级。
一张表支持声明多个二级索引,并且支持多种类型:minmax(最大最小)、set(去重集合)、 ngrambf_v1(ngram 分词布隆索引) 和 tokenbf_v1(标点符号分词布隆索引)。
- minmax:以 index_granularity 为单位,存储指定表达式计算后的 min、max 值;在等值和范围查询中能够帮助快速跳过不满足要求的块,减少 IO。
- set(max_rows):以 index granularity 为单位,存储指定表达式的 distinct value 集合,用于快速判断等值查询是否命中该块,减少 IO。
- ngrambf_v1(n, size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed):将 string 进行 ngram 分词后,构建 bloom filter,能够优化 等值、like、in 等查询条件.
- tokenbf_v1(size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed):与 ngrambf_v1 类似,区别是不使用 ngram 进行分词,而是通过标点符号进行词语分割。
- bloom_filter([false_positive]):对指定列构建 bloom filter,用于加速 等值、like、in 等查询条件的执行。
 在这里插入图片描述
在这里插入图片描述
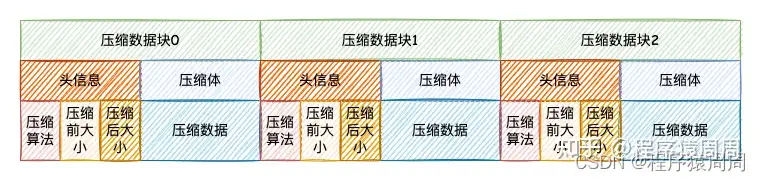
4.5 数据压缩
column.bin 是 ClickHouse 的数据存储文件,其中存储是一列的数据,由于一列是相同类型的数据,所以方便高效压缩。在进行压缩的时候,一个压缩「数据块」由「头信息」和「压缩数据」两部分组成。
- 头信息固定使用 9 位字节表示,具体由 1 个 UInt8(1字节)整型和 2 个 UInt32(4字节)整型组成,分别代表使用的压缩算法类型、压缩后的数据大小和压缩前的数据大小。
- 每个压缩数据块的体积,按照其压缩前的数据字节大小,都被严格控制在 64KB~1MB,其上下限分别由 min_compress_block_size(默认65536=64KB) 与 max_compress_block_size(默认1048576=1M)参数指定。
「具体压缩规则」
- 单个批次数据 size < 64KB:如果单个批次数据小于 64KB,则继续获取下一批数据,直至累积到size >= 64KB时,生成下一个压缩数据块。如果平均每条 记录小于8byte,多个数据批次压缩成一个数据块;
- 单个批次数据 64KB <= size <=1MB:如果单个批次数据大小恰好在 64KB 与 1MB 之间,则直接生成下一个压缩数据块;
- 单个批次数据 size > 1MB:如果单个批次数据直接超过 1MB,则首先按照 1MB 大小截断并生成下一个压缩数据块。剩余数据继续依照上述规则执行。此时,会出现一个批次数据生成多个压缩数据块的情况。再如果平均每条记录的大小超过 128byte,则会把当前这一个批次的数据压缩成多个数据块。
 在这里插入图片描述
在这里插入图片描述
4.6 数据标记
「数据标记文件」与 .bin 文件一一对应,「是一级索引和数据之间的映射」。即每一个列字段 [Column].bin 文件都有一个与之对应的 [Column].mrk2 数据标记文件,用于记录数据在 .bin 文件中的偏移量信息。一行标记数据使用一个元组表示,元组内包含两个整型数值的偏移量信息。它们分别表示在此段数据区间内,在对应的 .bin 压缩文件中,压缩数据块的起始偏移量,以及将该数据压缩块解压后,其未压缩数据的起始偏移量。标记数据与一级索引数据不同,它并不能常驻内存,而是使用 LRU 策略加快其取用速度。
所以数据的读取流程就是:
- 先根据一级索引,找到标记文件中的对应数据压缩块信息,并在
[Column].bin文件中找到对应压缩数据块,读取并解压; - 从解压缩的数据块中,以
index_granularity的粒度加载数据到内存中,执行查询,直至找到结果数据。
5 查询流程
数据查询的本质,可以看作一个不断减小数据范围的过程。在最理想的情况下,MergeTree 首先可以依次借助分区索引、一级索引和二级索引,将数据 扫描范围缩至最小。然后再借助数据标记,将需要解压与计算的数据范围缩至最小。
 在这里插入图片描述
在这里插入图片描述- 指定分区
- 指定字段([Column].bin)
- 根据一级索引(primary.idx)定位到标记文件([Column].mrk2)中的一条记录
- 扫描对应字段的 mark 标记文件,获取两个偏移量信息
- 根据第一个偏移量(查找数据所在压缩数据块处于这个
.bin文件中的偏移量)定位到一个压缩数据块 - 读取数据到内存执行解压缩
- 根据第二个偏移量(查找数据在压缩数据块解压后的偏移量)去内存解压缩数据中找到对应的数据
当然上述为理想情况,如果一次查询没有命中任何索引(分区、一级和二级索引),那么 MergeTree 就不能预先减少数据范围。不过 ClickHouse 依旧可以借助数据标记,以多线程的形式同时读取多个压缩数据块,提升查询速度。