目录
lab1
TODO: 个人觉得lab1没啥好说的
lab2
虽然论文基本都看懂了,也挺好理解,但是raft的提出也经历了许多时间,解决了一个又一个分布式难题,因此其中有许多步骤虽然知道要怎么做,但至于为什么要这么做并且解决了什么样的根本问题其实还是理解得云里雾里。srds,还是先照着论文把实验较为简单的部分做做
part A
实现框架
根据论文,Raft有三种状态:Follower, Candidate, Leader。其中状态转换图如下:
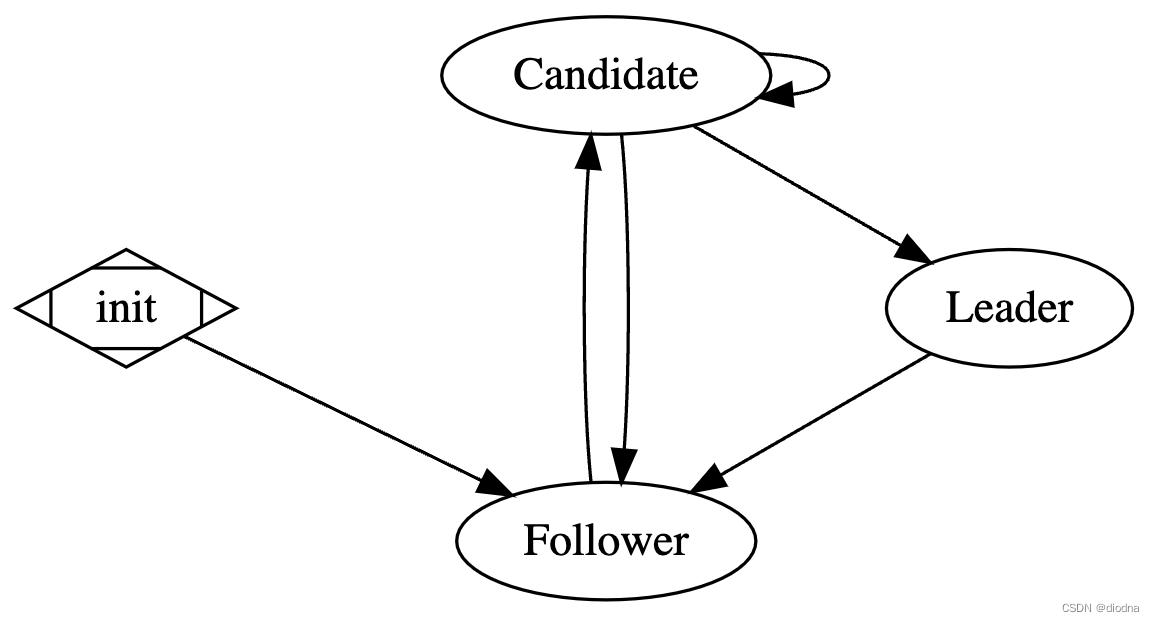
由于对于一个Raft来说同一时间点只会是其中的一种状态,因此我们在代码中将这三种通过协程解耦,即每进入一次新的状态,都开一个新的协程进行处理,而原状态所在协程此时只需清理资源并退出即可,这样的好处是状态之间的处理和转换不会互相依赖,例如从Follower进入Candidate时只需要一句go rf.startElection(),并且在退出Follower状态前清理所用到的timer等资源
框架细节
上述的状态转换图是用graphviz画的,因为刚用还不太熟练所以没有标出状态转换的条件,在此用文字描述一下。状态转换的条件十分重要,这影响了整个算法的正确性
- init->Follower:一个Raft实例(节点)从创建到启动第一个进入的状态就是Follower
- Follower->Candidate:节点在超时时间内收不到心跳,进入选举状态
- Candidate->Leader:节点收到的投票超过半数,进入领导者状态
- Candidate->Candidate:节点选举超时,开始新一轮选举
- Candidate->Follower:节点收到心跳或投票请求(要求term比currentTerm大),或者在请求投票的回复中被拒绝,上述两种情况都说明存在term更新的Leader,因此节点要回到Follower状态
- Leader->Follower:节点收到心跳或投票请求(要求term比currentTerm大),或者在发送心跳的回复中被拒绝,上述两种情况都说明存在term更新的Leader,因此节点要回到Follower状态
其中最后一点此时同时存在的两个Leader并不是同一个term中的,因此不会发生冲突
有了大致的框架流程与论文中提到的代码细节,那么代码就不难写了,接下来进入实现部分吧
代码
结构体定义
按照实验提示和论文中的figure 2,先把结构体都填好相应的字段
Raft:
type Raft struct {
mu sync.Mutex // Lock to protect shared access to this peer's state
peers []*labrpc.ClientEnd // RPC end points of all peers
persister *Persister // Object to hold this peer's persisted state
me int // this peer's index into peers[]
dead int32 // set by Kill()
// Your data here (2A, 2B, 2C).
// Look at the paper's Figure 2 for a description of what
// state a Raft server must maintain.
// persistent
currentTerm int
votedFor int
log []Entry
// volatile
commitIndex int
lastApplied int
// volatile on leaders
nextIndex []int
matchIndex []int
// others
state int // Follower, Candidate or Leader
heartbeatCh chan struct{}
}
// state costants
const (
Follower = iota
Candidate
Leader
)
// log entry
type Entry struct{}
其中未在论文中提到要定义的字段:state用来记录当前所处状态,heartbeatCh用来告知节点心跳或请求的到来
以下两个RPC通信相关的结构体就是完全跟论文的一样了
RequestVote相关的RPC结构体
type RequestVoteArgs struct {
// Your data here (2A, 2B).
Term int
CandidateId int
LastLogIndex int
LastLogTerm int
}
type RequestVoteReply struct {
// Your data here (2A).
Term int
VoteGranted bool
}
AppendEntries相关的RPC结构体
type AppendEntriesArgs struct {
Term int
LeaderId int
PrevLogIndex int
PrevLogTerm int
Entries []Entry
LeaderCommit int
}
type AppendEntriesReply struct {
Term int
Success bool
}
Follower状态
实验提示最好使用time.Sleep来模拟超时,个人感觉有点蠢,所以用了Timer,不知道partBCD会不会因为这个出什么奇怪的bug
func (rf *Raft) ticker() {
debug(dTimer, "S%d enter Follower", rf.me)
rf.mu.Lock()
rf.state = Follower
rf.mu.Unlock()
timer := time.NewTimer(randTimeout(toMin, toMax))
defer timer.Stop()
for rf.killed() == false {
select {
case <-timer.C: // election timeout
go rf.startElection()
return
case <-rf.heartbeatCh:
timer.Stop()
timer.Reset(randTimeout(toMin, toMax))
}
}
}
Follower状态比较简单,从框架中的状态图也可以看出Follower的状态转换比较简单,超时则开始选举即可
写到这里可以发现这个函数名有点意思,ticker,说明了best practice的代码可能不是围绕上述框架中的状态机来进行编写,不然估计函数名应该叫startFollower,enterFollower什么的
Candidate状态
func (rf *Raft) startElection() {
debug(dTimer, "S%d enter Candidate", rf.me)
rf.mu.Lock()
rf.state = Candidate
rf.votedFor = rf.me
rf.currentTerm++
rf.mu.Unlock()
ctx, cancel := context.WithTimeout(context.Background(), randTimeout(toMin, toMax))
replyCh := make(chan RequestVoteReply, len(rf.peers))
defer cancel()
for i := range rf.peers {
if i != rf.me {
go rf.requestVote(i, ctx, replyCh)
}
}
rf.watchElection(ctx, replyCh)
}
候选人状态要负责的事情就是向所有节点请求投自己一票,然后根据回复统计票数。由于是并发地请求投票,如果此时因为选举成功/选举失败而要转换状态的话,还需要通知还在请求投票的协程退出。rf.requestVote实现上述的“请求某个节点投自己一票”,rf.watchElection实现统计票数,并监听选举成功/失败。
其中context.Context帮助实现通知多个协程的退出,replyCh帮助实现将多个请求投票协程的结果汇总到watchElection中处理
func (rf *Raft) requestVote(server int, ctx context.Context, replyCh chan<- RequestVoteReply) {
for {
select {
case <-ctx.Done(): // timeout or canceled
return
default: // retry multiple times before election timeout
rf.mu.Lock()
args := RequestVoteArgs{}
reply := RequestVoteReply{}
args.CandidateId = rf.me
args.Term = rf.currentTerm
rf.mu.Unlock()
ok := rf.sendRequestVote(server, &args, &reply)
if ok {
if ctx.Err() == nil {
replyCh <- reply
}
return
}
}
}
}
func (rf *Raft) watchElection(ctx context.Context, replyCh <-chan RequestVoteReply) {
votedCount := 1
for {
select {
case <-ctx.Done():
go rf.startElection() // timeout, reenter Candidate state with next term
return
case reply := <-replyCh:
if reply.VoteGranted {
debug(dVote, "S%d got vote", rf.me)
votedCount++
if votedCount >= len(rf.peers)/2+1 {
go rf.startLeader() // get the majority of votes, enter Leader state
return
}
} else {
rf.mu.Lock()
rf.currentTerm = reply.Term
rf.mu.Unlock()
debug(dLeader, "S%d detect new leader from requestVote reply", rf.me)
go rf.ticker() // detect new leader from reply, enter Follower state
return
}
case <-rf.heartbeatCh: // detect new leader from heartbeat, enter Follower state
debug(dLeader, "S%d detect new leader from HBT", rf.me)
go rf.ticker()
return
}
}
}
可以看到当票数超过一半时,则调用rf.startLeader()进入Leader状态,并且退出监听。而当context超时被取消时,则开启新一轮的选举
Candidate状态在part A中应该算是最复杂的,因为它可能进入的下一个状态囊括了所有的状态
Leader状态
func (rf *Raft) startLeader() {
debug(dTimer, "S%d enter Leader", rf.me)
rf.mu.Lock()
rf.state = Leader
rf.mu.Unlock()
ticker := time.NewTicker(time.Duration(heartbeatInterval) * time.Millisecond)
defer ticker.Stop()
leaderDead := int32(0)
sendHBT := func() {
for i := range rf.peers {
if i != rf.me {
go rf.sendHeartBeat(i, &leaderDead)
}
}
}
sendHBT()
for {
select {
case <-ticker.C:
sendHBT()
case <-rf.heartbeatCh: // detect new leader from heartbeat, enter Follower
if atomic.CompareAndSwapInt32(&leaderDead, 0, 1) {
debug(dLeader, "S%d detect new leader from HBT", rf.me)
go rf.ticker()
}
return
}
}
}
领导者只需要负责定时向所有节点发送心跳,同时监听是否有心跳或投票请求到来,以转入Follower状态(参考上述状态转换第6点),在每个心跳的RPC通信中,如果心跳被拒绝,即reply.Success=false,也需要转入Follower状态
这个部分代码其实也可以改成每个协程拥有自己的定时器,并像Candidate状态那部分那样,使用context+replyCh来实现。但是我并没有这么做,而是只使用一个ticker,并在每次tick到来时统一发送心跳。但这么做会使得每个检测心跳与检查回复分别运行在不同的协程里,有重复进入follower状态的隐患(多次调用rf.ticker()),因此定义了一个leaderDead局部变量来表示是否已经退出Leader状态
func (rf *Raft) sendHeartBeat(server int, leaderDead *int32) {
rf.mu.Lock()
args := AppendEntriesArgs{}
reply := AppendEntriesReply{}
args.Term = rf.currentTerm
rf.mu.Unlock()
ok := rf.sendAppendEntries(server, &args, &reply)
if ok {
if !reply.Success { // detect new leader from reply, enter Follower
if atomic.CompareAndSwapInt32(leaderDead, 0, 1) {
rf.mu.Lock()
rf.currentTerm = reply.Term
rf.mu.Unlock()
debug(dLeader, "S%d detect new leader from S%d's HBT reply", rf.me, server)
go rf.ticker()
}
}
}
}
part B
待更新...
标签:状态,6.824,Candidate,int,Follower,Leader,rf,MIT,小记 From: https://www.cnblogs.com/nosae/p/16965848.html