【NeurIPS2022】ScalableViT: Rethinking the Context-oriented Generalization of Vision Transformer
这篇论文来自清华大学深圳研究生院和字节跳动。
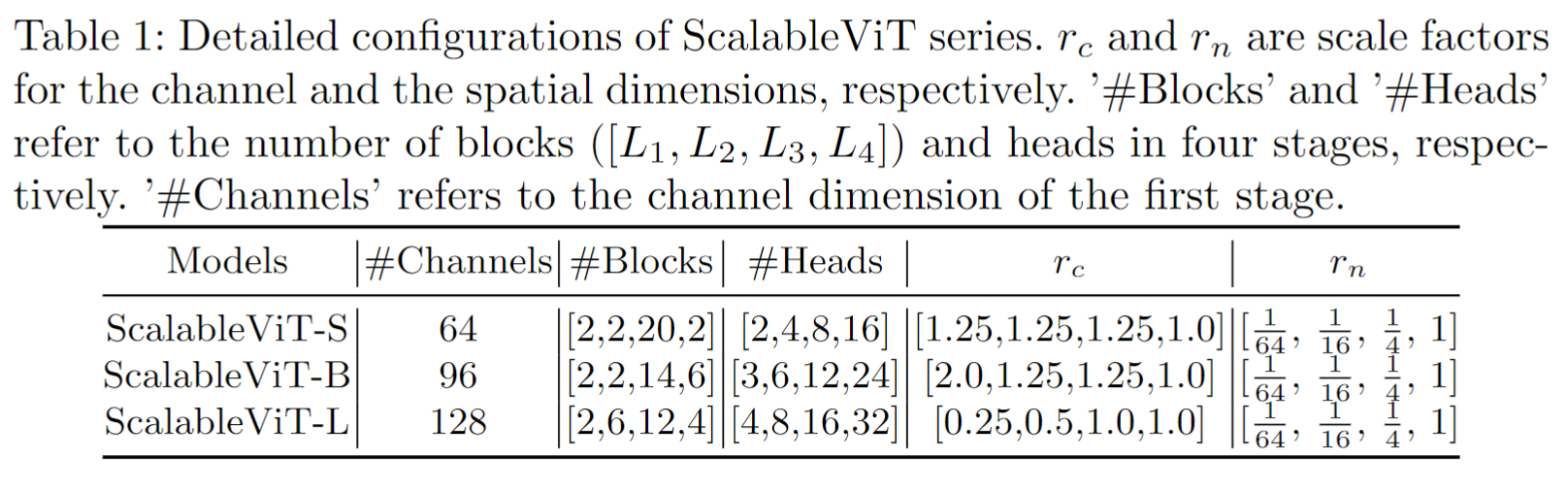
从Swin开始,attention一般都包括局部 window attention 和 全局attention 两个部分。模型的改进一般有两个:局部注意力和全局注意力。这篇论文也是如此,整体框架如下图所示,核心包括:局部注意力 Interactive Window Self-Attention (IWSA) 和 全局注意力 Scalable Self-Attention (SSA) 两个部分。
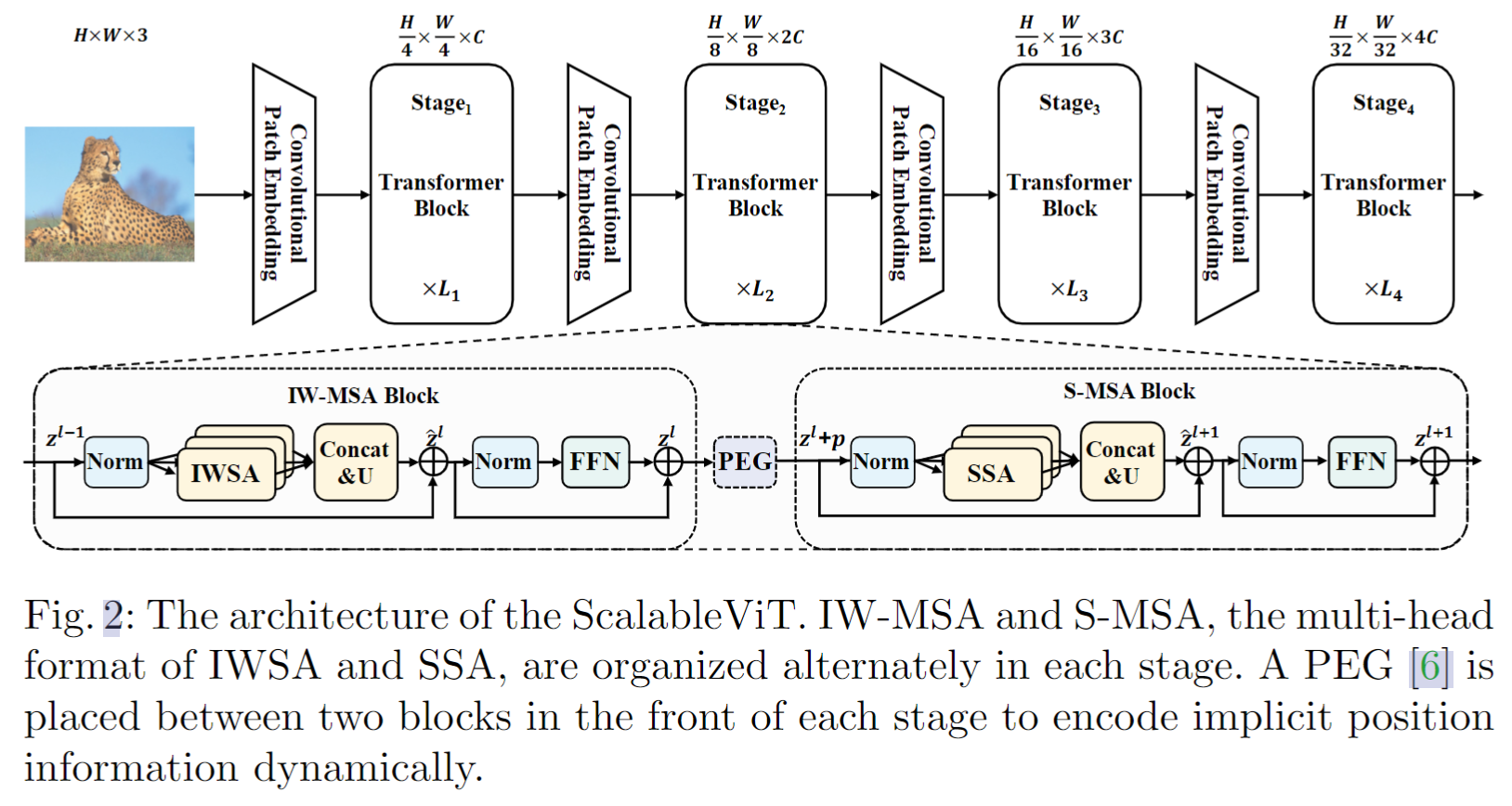
Interactive Window Self-Attention (IWSA)
IWSA框架如下图所示,首先在局部窗口中分别计算 attention,然后将得到的结果拼接起来,得到Z。各个windows经过 FC 层得到的 value,合并在一起,使用 depth-wise conv 处理(作者称之为 local interactive module),得到Y。将 Z与Y相加,得到输出。
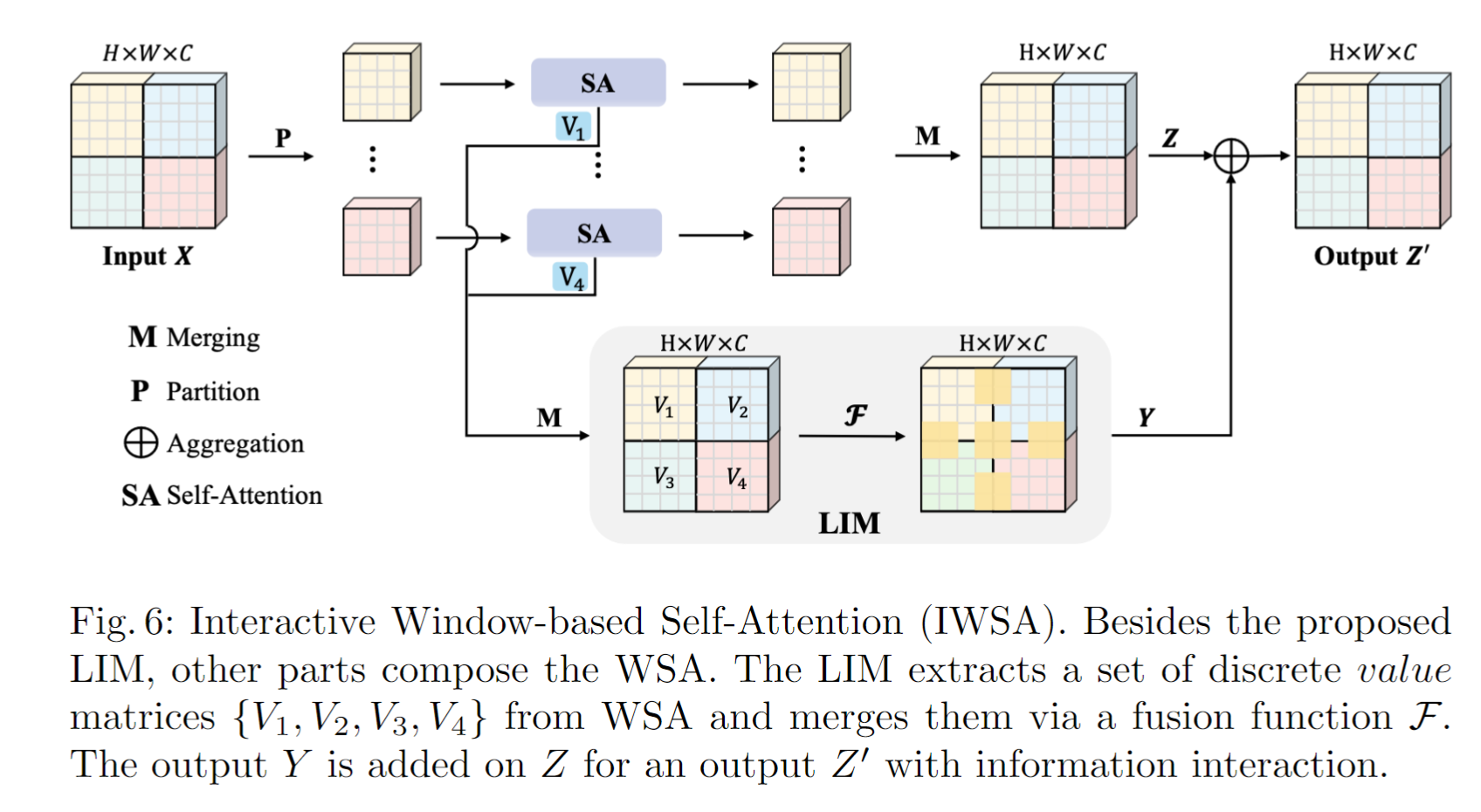
Scalable Self-Attention (SSA)
模块结构如下图所示,以前的PVT,只是对Q和K降维(spatial 降维)。在这里,作者不但对Q和K降维,还对V进行降维(channel降维),以达到 scalable 的目标。
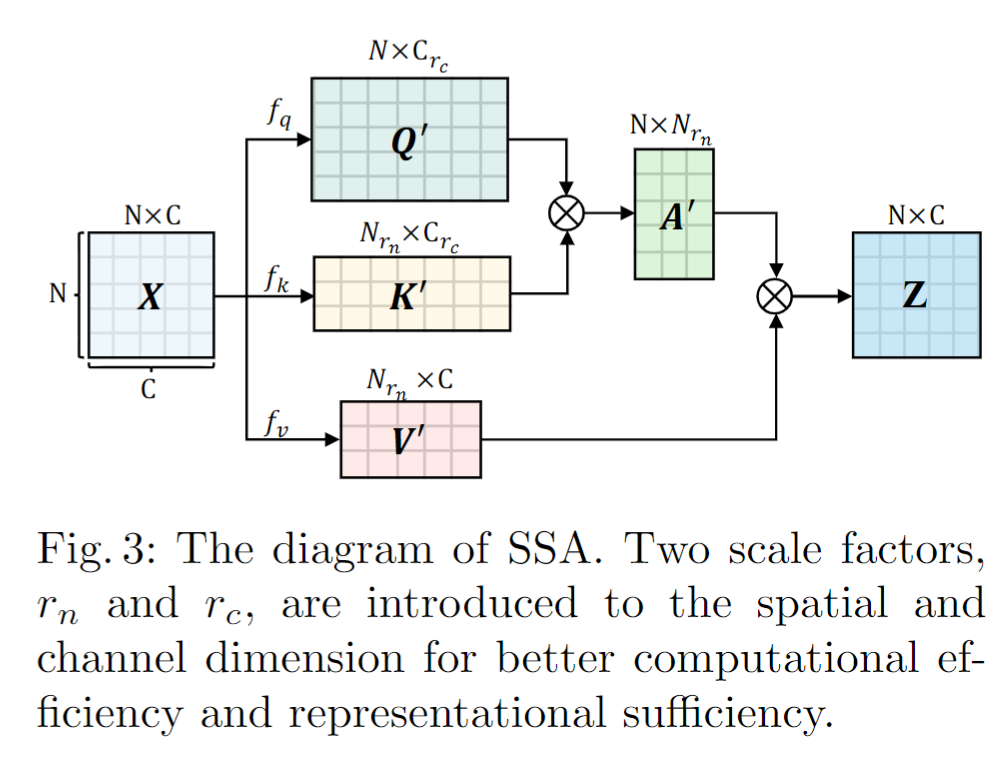
关键就是看这个缩放怎么取值了。比较有趣的是,作者说,随着网络加深,图像块减少,冗余程度在减少,因此 \(r_n\) 越往后越大。因为空间信息减少较多,需要通道增加来补偿,因此在 ScalableViT-S 和ScalableViT-B 中设置 \(r_c\ge1\),在 ScalableViT-L 中设置 \(r_c<1\)。具体如下表所示。