
【ECCV2022】DaViT: Dual Attention Vision Transformers
这个论文想法很自然也容易想到。Transformer都是在处理 PxC 二维的数据,其中 P 是token 的数量,C是特征的维度。普通的方法都是在P这个维度计算attention,那么是不是可以在C这个维度计算attention呢? 肯定是可以的。
因此,作者使用了两种 attention,如下图所示,分别是在token维度上进行计算最常规的 windows self-attention,和在 channel 维度上计算的 channel group self-attention。两种attention交替使用。
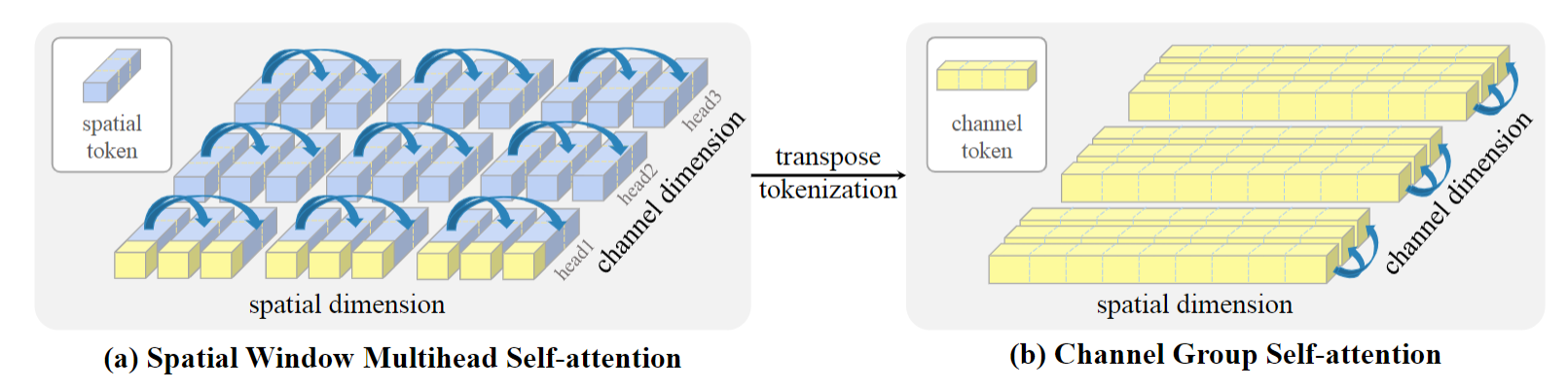
具体来说,作者提出了dual attention block,如下图所示。分别交替计算 spatial window mutlihead attention 和 channel group attention,这样模型可以 capture both local fine-grained and global image-level interactions.
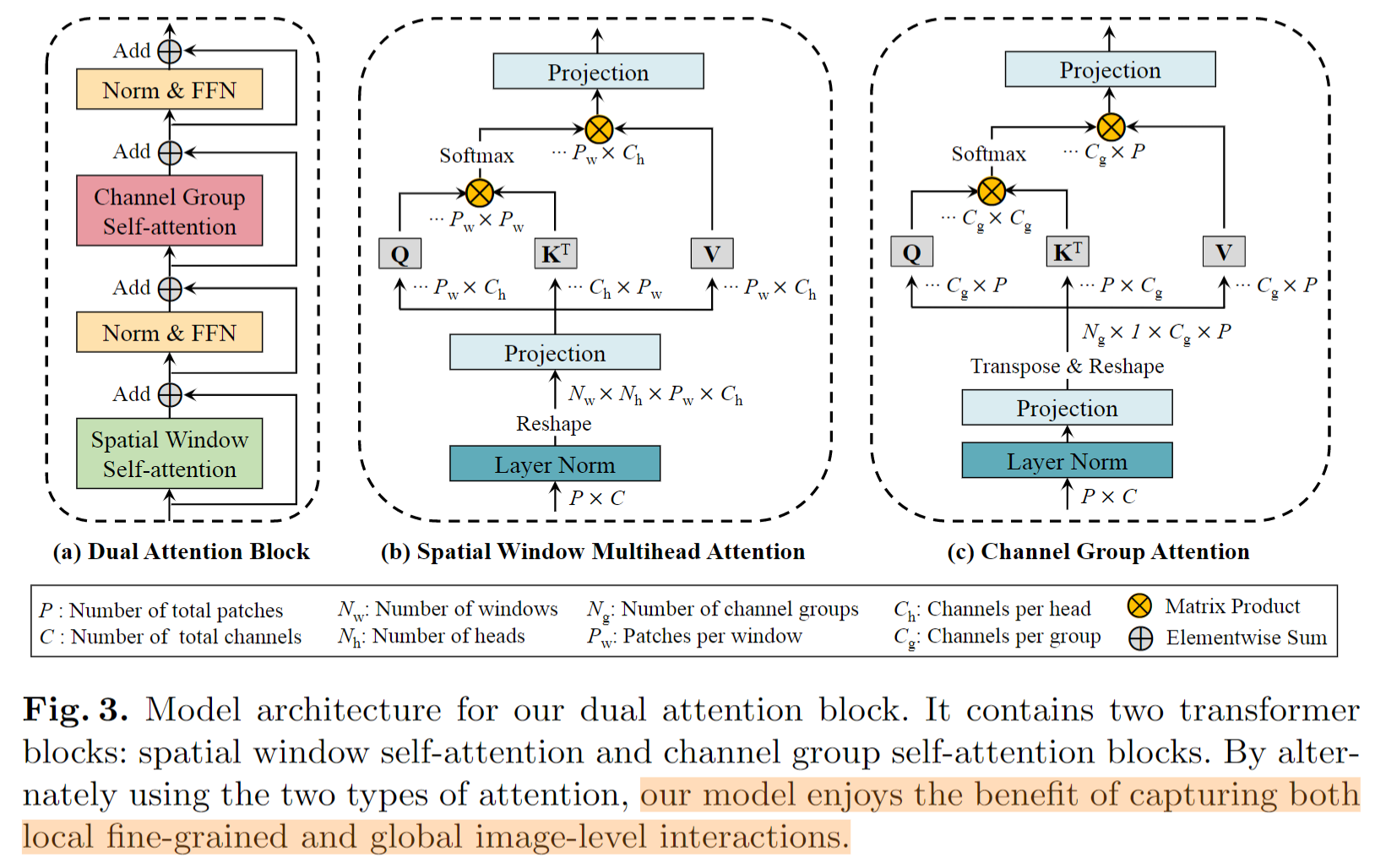
论文的核心思想就是这些了,和以往论文不同的是,论文写了一个 Analysis 章节,专门分析模型的特点。如下图所示,论文通过可视化专门分析 channel attention是如何聚集全局信息的。

此外,作者还做了可视化实验分析 channel group attention 的有效性。It shows strong global modeling capabilities by finding out fine-grained details of the main content in stage 1, and further focusing on some keypoints in stage 2. It then gradually refines the regions of interest from both global and local perspectives for final recognition.

消融实验中有趣的是两个 attention 模块的顺序,如下表所示。We can see that the three strategies achieve similar performance, with 'window attention first' slightly better
