1、Motivation
这个论文来自于清华大学鲁继文老师团队,核心是 attention 和 MLP-mixer 思想的结合。
建议用2分钟时间学习一下谷歌公司的 MLP-Mixer 「MLP-Mixer: An all-MLP Architecture for Vision」CVPR 2021
Vision Transformer模型最近非常流行,最后也出现了一些以 MLP-Mixer 为代表的完全由MLP组成的模型(下图展示了attention 和 MLP 模型的区别)。这篇论文分析了两个问题:which specific designs make self-attention more effective? Is there a more efficient way to learn the spatial mixing weights?

2、总体框架
作者对比了 vision transformer 和 MLPMixer 之间的区别,发现 vision transformer 有四个独特的地方:(1) the multihead scheme; (2) softmax; (3) V 的 projection 和 C 的 Projection; (4) query 和 key 之间的点积。
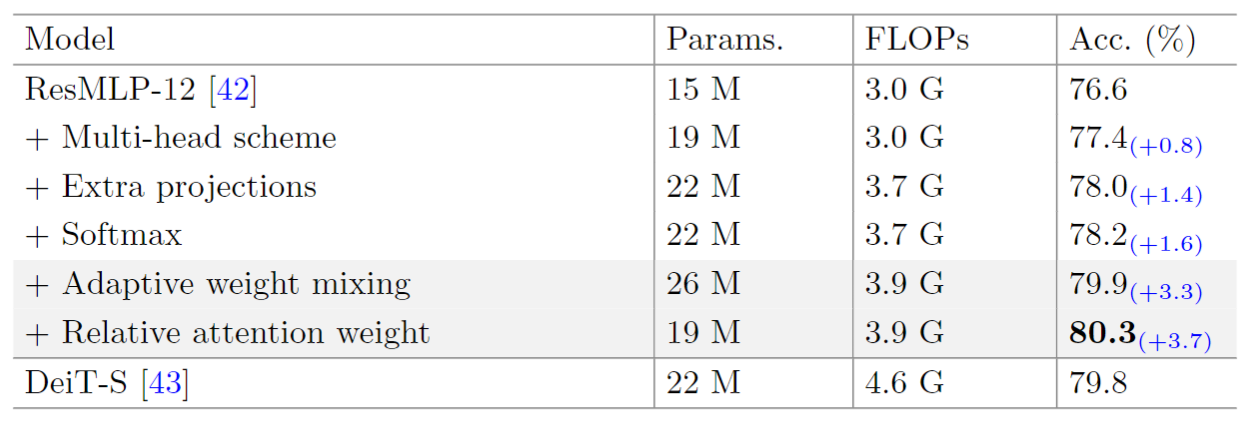
如下表所示,从 MLP 模型开始,往里面加一些模块,最终 Adaptive weight mixing 以更低的 FLOPs 和更少的参数量超越了 Transformer 模型。
通俗的来说,Adaptive weight mixing 可以实现与 self-attention 相似的功能。通过学习一个大小为B的weight bank,并预测每个token的mixing policy,以此自适应地生成相似性矩阵 M (类似于 attention 里 Q 和 K 计算得到的相似性矩阵)。最后该相似性矩阵与V相乘得到输出。

具体来说,包括下面几步:
- 第一步:使用MLP生成 mixing policy,图中是4个token,得到的 mixing policy 就是 Hx4xB 的矩阵。 H表示 head,B表示在 weight bank 中建立了一个 B维的线性空间。
- 第二步:mixing policy (Hx4xB) 与 weight bank (Bx4x4)相乘,得到 Hx4x4 的矩阵,Softmax归一化。
- 第三步:权重矩阵与 V相乘,得到输出。
通过调节B的值,可以实现 better trade-off between accuracy and complexity than vision Transformers and MLP models
下图中展示了各种权值生成方法,可以看出 Adaptive weight mixing 通过多头的混合策略实现了更多样化的权值。另外,f动态卷积只能生成空间共享的权值,而本文的方法可以为不同的空间位置产生特定的权值。本文的方法比使用MLP直接预测参数的方法,包括合成器和动态卷积,高效得多。

3、实验分析
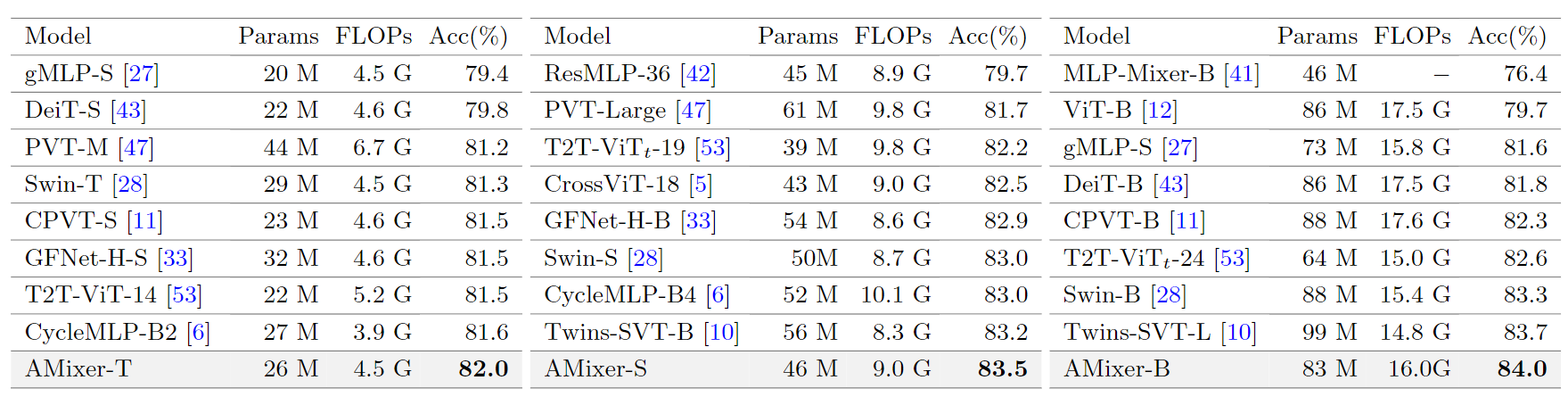
在ImageNet的实验结果可以看出,AMixer-DeiT-S所取得的准确率为80.8%,比DeiT-S的79.8%提高了1%。通过左右两图的灰色高亮部分还能看出,用Amixer比用MLP性能更优,左图相差1.6%,右图相差1.3%。