
这篇又长长长了!
\(8435\to 8375\to 9729\)
早就馋这篇了!终于学了(
压位 Trie 确实很好写啊 但是总感觉使用范围不是很广的样子
似乎是见的题少
原文里都在用 \(\log_2\),但我不是很习惯,所以还是用 \(\log\)。
不出意外的话下一篇是 EI 树。出了意外的话(指完全看不懂)就咕咕咕。
引言
数据结构!该学还是得学的,这给你讲讲亚 \(\log\) 的,挺nb!但是有些没用的就不说了,常数大还难写。这讲讲压位 Trie 和 vEB 树。
这玩意用来解决动态前趋问题(Dynamic Predecessor Problem)。我还给你测了测,反正你知道这玩意厉害就行了!这里是代码!
反正不要钱,多少看一点~
1 \(\text{Dynamic Predecessor Problem}\)
你需要写一种数据结构,维护一个数字集合。需要支持以下几种操作:
- 若原来不存在数 \(x\),插入数 \(x\);
- 若原来存在数 \(x\),删除数 \(x\);
- 求数 \(x\) 的前趋(前趋定义为小于 \(x\) 且最大的数,若不存在输出 \(-1\));
- 求数 \(x\) 的后继(后继定义为大于 \(x\) 且最小的数,若不存在输出 \(-1\));
假设操作数为 \(n\),保证 \(1\le n, x \le 10^7\)。
时间限制:\(\text{1s}\)
空间限制:\(\text{32MB}\)
常见解法
- 平衡树
不展开。卡时间还卡空间,它已经死力 - 树状数组
可以树状数组维护 01,树状数组上二分解决。
单次时间复杂度是 \(O(\log V)\),空间复杂度是 \(O(V)\)。常数小但是太慢了。 - 整型压位
适用于值域在 \(2^{64}\) 以内的情况。
可以使用 \(\text{ctz}\) 等函数和位运算在 \(O(1)\) 复杂度内解决。
2 压位 Trie
压位 Trie,又称 \(w\) 叉 Trie,常数小还好写。
各操作的复杂度均为 \(\log_{w} V\),并且具有较高的拓展性。这里的 \(w\) 常取 \(64\),使用 unsigned long long 压位。
2.1 结构
假设 \(c= \log w\)。
一棵大小为 \(2^k\) 的压位 Trie 可以维护一个值域为 \([0,2^k)\) 的集合。
如果 \(2^k \le w\),显然可以使用一个整型压位解决。下面只讨论 \(2^k > w\) 的情况。
我们定义 \(high(x) = \left\lfloor\frac {x}{2^{k-c}}\right\rfloor\),\(low(x) = x \bmod 2^{k-c}\)。两个函数的作用是取 \(x\) 的低 \(c\) 位与高位。
对于一棵大小为 \(2^k\) 的压位 Trie,其有 \(w\) 棵大小为 \(2^{k-c}\) 的子压位 Trie \(A_i(0\le i < w)\),其中 \(A_i\) 维护目前高位为 \(i\) 的值的低位组成的集合。每个节点维护一个 \(w\) 大小的 word 维护第 \(i\) 棵子树内是否维护了值。
论文里的图:
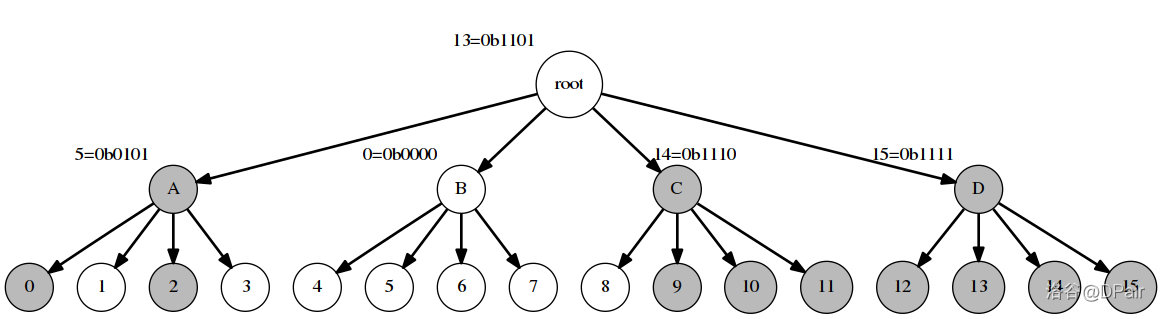
当 \(w = 4\) 的情况。这棵压位 Trie 维护了 \([0,2^4)\) 里的值,集合为 \(\{0,2,9,10,11,12,13,14,15\}\)。可以看到每一个节点的 word。
2.2 插入/删除
假设现在在一棵大小为 \(2^k\) 的压位 Trie 中插入元素 \(x\)。首先需要将 \(low(x)\) 插入 \(A_{high(x)}\) 中。然后递归。结束了!
删除同理。递推地删除掉只有 \(x\) 的子树对其父亲的标记即可。如果子树删后非空退出即可。
每次都会进入一个大小为原来的 \(\frac 1w\) 的压位 Trie 中,因此插/删的复杂度为 \(O(\log_w V)\) 的。
2.3 前趋/后继
假设现在在一棵大小为 \(2^k\) 的压位 Trie 中查询元素 \(x\) 的前趋。我们首先在 \(A_{high(x)}\) 里查询 \(low(x)\) 的前趋。查到了就退出。
到这了就是没查到。找一个 \(A_{j}\) 满足 \(0\le j < high(x)\) 而且里面有元素。如果存在就返回这个玩意里面的最大值,不存在返回 \(-1\)。
因为压位 Trie 是对称的,后继平凡。
复杂度还是 \(O(\log_w V)\) 的。
2.4 复杂度
发现所有操作都是 \(O(\log_ wV) = O(\frac{\log V} {\log w} )\) 的。一般取 \(w = O(\log V)\),所以有复杂度 \(O(\frac {\log V}{\log \log V})\)。
假设一棵大小为 \(2^k\) 的压位 Trie 的空间复杂度为 \(F(k)\)。容易发现 \(\forall \ 1\le 2^i \le w, \ F(i) = 1\),且 \(F(k) = wF(k - c) + 1\)。因此 \(F(k) = O(2^k)\)。调整第一层子压位 Trie 个数能做到 \(O(\frac {2^k} {w})\) 的空间复杂度。评价:奥妙重重。
2.5 具体实现
边看代码边说(
you wanna see code? click here!
#include <bits/stdc++.h>
#include "trie.h"
#define clz(x) __builtin_clzll(x)
#define ctz(x) __builtin_ctzll(x)
using namespace std;
using ull = unsigned long long;
ull _s1[1 << 24], _s2[1 << 18], _s3[1 << 12], _s4[1 << 6], _s5[1];
ull *t[] = {_s1, _s2, _s3, _s4, _s5};
ull a[1 << 6], b[1 << 6];
void ins(int x) {
for (int i = 0; i < 5; ++ i, x >>= 6) t[i][x >> 6] |= 1ull << (x & 63);
}
void del(int x) {
for (int i = 0; i < 5; ++ i, x >>= 6) if (t[i][x >> 6] &= ~(1ull << (x & 63))) return;
}
void assign(int x, int i) { i ? ins(x) : del(x); }
int pre(int x) {
int i, pre; ull tmp;
for (i = 0; ; i ++, x >>= 6) {
if (i == 5) return 0;
tmp = t[i][x >> 6] & a[x & 63];
if (tmp) {
pre = (63 ^ clz(tmp)) | (x & ~63);
break;
}
} for (; i; -- i) pre = pre << 6 | (63 ^ clz(t[i - 1][pre]));
return pre;
}
int nxt(int x) {
int i, nxt; ull tmp;
for (i = 0; ; i ++, x >>= 6) {
if (i == 5) return 0;
tmp = t[i][x >> 6] & b[x & 63];
if (tmp) {
nxt = ctz(tmp) | (x & ~63);
break;
}
} for (; i; -- i) nxt = nxt << 6 | ctz(t[i - 1][nxt]);
return nxt;
}
void init(int n) {
a[0] = 0, b[0] = ~1ull;
for (int i = 1; i < 64; ++ i)
a[i] = a[i - 1] << 1 | 1, b[i] = b[i - 1] << 1;
}
一个节点就是一个 word。为了空间可以写成五个数组+指针数组的形式,速度应该不是很差。
然后我们就可以从底向上更新了,常数会更小一点(确信
论文里说的关于删除和查询的剪枝都用了,就是,接下来再做操作没意义了就退出。但是这点我不会在插入上实现。想实现但是挂了www
经过少许卡常后是 infoj 的最优解。
2.6 拓展
改个操作。现在是 \(\text{Dynamic Prefix Problem}\) 了,我们需要支持插入删除和查询排名。
新的查询在原来的压位 Trie 结构上无法实现,因为我们无法快速查询前 \(k\) 个子树内总共有几个元素。然后改一下叉数。设现在叉数为 \(B\),每当一个节点的子树插入了 \(B\) 个元素后我们重构一次,计算出每个位置的子树内有多少元素,求前缀和后备用。现在只需要维护最近的 \(O(B)\) 个元素中有几个大于 \(x\) 的。
这段看不懂,直接粘了。如果有人会实现也可以给讲讲(
评价:奥妙重重。
$老师是怎么实现在 word 里插入一个 bit 的?
我们考虑使用一种新的方法存储每个子树中的新元素个数,我们使用 \(1\) 的个数表示数字的值,由于其存在 \(B\) 个子树,所以我们使用 \(B - 1\) 个 \(0\) 当做数据的间隔,因此一个子树中每个儿子有几个数我们就可以使用一个整型压缩存储。而对于修改操作,我们要快速找到第 \(k\) 个子树对应的位置,这个就需要我们快速查询一个二进制第 \(k\) 个 \(0\) 的位置。我们可以使用 Method of Four Russians 来优化,即打出一张表,存储每一个不同的查询的答案。对于查询,我们也只要找到第 \(k\) 个 \(0\) 就知道前面有几个 \(1\) 了,我们就可以 \(O(1)\) 支持一个子树元素个数加一,查询前 \(k\) 个子树的元素个数总和。如果我们取 \(B = \frac{\log n} 3\) ,那么预处理复杂度将小于 \(O(n)\),因此我们能以均摊 \(O(\frac {\log V}{\log \log n} )\) 的时间复杂度解决这个问题,我们也有一些手段将其变为严格 \(O(\frac {\log V}{\log \log n} )\)。
3 vEB 树
压位 Trie 的复杂度里 \(w\) 是在分母上的。所以叉数越大效率越高。但是如果你对 word 的操作复杂度不是 \(O(1)\),那就得不偿失了。
vEB 树(van-Emde Boas Tree)采用了一定的策略,使得其在叉数增加的情况下保证了时间复杂度,因此可以在 \(O(\log\log V)\) 的复杂度下支持每个操作。
3.1 结构
一棵大小为 \(2^k\) 的 vEB 树可以维护一个值域为 \([0,2^k)\) 的集合。
如果 \(k < 2\),显然可以使用 \(2^k\) 个布尔值维护。否则我们令 \(m = \left\lfloor\frac k2 \right\rfloor\)。我们维护 \(2^{k-m}\) 个 \(2^m\) 大小的子 vEB 树 \(A_i(0\le i < 2^{k-m})\)。
我们定义 \(high(x) = \left\lfloor\frac {x}{2^{m}}\right\rfloor\),\(low(x) = x \bmod 2^{m}\)。
对于一棵 vEB 树维护的集合,我们记录其 \(\max\) 和 \(\min\)(若集合为空则分别为 \(-\infty\) 和 \(\infty\))并将除了最小值的元素插入其子 vEB 树中。对于 \(x\),我们在 \(A_{high(x)}\) 中插入 \(low(x)\)。
为加速查找,我们再定义一个大小 \(2^{k-m}\) 的 vEB 树 \(B\),其维护出现的数的高位的集合。\(B\) 可以加速我们的查询。
3.2 边界
对于一棵空的 vEB 树,我们插入元素 \(x\) 时只需要将 \(\max\) 和 \(\min\) 都设为 \(x\)。
对于一棵 vEB 树,其集合大小为 \(1\) 当且仅当其的 \(\max = \min\)。
对于一棵集合大小为 \(1\) 的 vEB 树,我们删除元素时只需要将 \(\max\) 和 \(\min\) 初始化。
对于一棵大小为 \(2^k\) 的 vEB 树,假设子 vEB 树 \(A_x\) 中存在元素 \(y\),就说明本树中存在值为 \(2^m \times x + y\) 的元素。
这些操作都可以 \(O(1)\) 完成。
3.3 插入
假设我们要在一棵大小为 \(2^k\) 的 vEB 树中插入一个元素 \(x\)。
如果该树为空则直接按边界插入即可。
如果 \(x < \min\),交换 \(x\) 和 \(\min\) 后接着插入原来的 \(\min\)。如果 \(x > \max\),更新 \(\max\)。
首先我们需要在 \(A_{high(x)}\) 中插入 \(low(x)\),并在 \(B\) 中插入 \(high(x)\)。容易发现,当 \(A_{high(x)}\) 非空时,\(B\) 中一定已存在 \(high(x)\),所以我们只需要在 \(A_{high(x)}\) 中插入。否则 \(A_{high(x)}\) 为空,按边界插入即可。因此每次只会向一侧插入元素。
假设 \(T(k)\) 为在大小为 \(2^k\) 的 vEB 树中插入元素的时间复杂度,我们有 \(T(0) = T(1) = 1, T(k) = T(\left\lceil\frac k2\right\rceil) + O(1)\)。主定理得 \(T(k) = O(\log k)\),而 \(k = O(\log V)\),因此总时间复杂度为 \(O(\log \log V)\)。
3.4 删除
假设我们要在一棵大小为 \(2^k\) 的 vEB 树中插入一个元素 \(x\)。
如果该树为空则直接按边界删除即可。
如果 \(x = \min\),则我们需要在删除 \(\min\) 后求得新的 \(\min\)。新 \(\min\) 的高位必定是最小的,所以我们在 \(B\) 中找出高位最小值,并在高位对应的子 vEB 树中找到低位最小值,即可得到新的 \(\min\)。
然后我们需要在 \(A_{high(x)}\) 中删除 \(low(x)\)。删空了就在 \(B\) 中删除 \(high(x)\)。
如果 \(A_{high(x)}\) 维护的集合大小为 \(1\),则在 \(A_{high(x)}\) 中删除元素的复杂度为 \(O(1)\) 的,因此这里只会向 \(B\) 递归。反之我们不需要维护 \(B\)。因此每次只会向一侧删除元素。
复杂度同样是 \(O(\log \log V)\)。
3.5 前趋/后继
假设我们要在一棵大小为 \(2^k\) 的 vEB 树中查询元素 \(x\) 的前趋。
\(x\) 的前趋与 \(x\) 高位相同当且仅当 \(A_{high(x)}\) 的 \(\min\) 小于 \(low(x)\),因此可以 \(O(1)\) 判断其前趋是否在 \(A_{high(x)}\) 中。如果在的话直接查询 \(low(x)\) 的前趋。
否则,\(x\) 的前趋一定是 \(high(x)\) 的前趋,这个可以向 \(B\) 递归求得。递归回后取 \(high(x)\) 前趋对应子树的最大值即可。
后继镜像,不展开。总时间复杂度 \(O(\log \log V)\)。
对于前趋,如果 \(B\) 中的最小值大于等于 \(high(x)\),则前趋将是整棵 vEB 树的最小值。
对于后继,发现我们要取子树的最小值。需要注意的是,最小值不在 vEB 树的子结构中。
3.6 注意点
可以将维护集合大小为 \(64\) 的情况特殊判断,采用一个 unsigned long long 型的 word 维护。若 \(w = 64\),即便是维护一个大小为 \(2^{24}\) 的集合也只用递归两层,大大减小了常数。
这里注意$老师的模板中 vEB 树的 size 是 \(\frac k2\)
由于 vEB 树的结构复杂,因此可以采用 template 语法定义不同大小的 vEB 树,特化小型的 vEB 树也比较方便。
3.7 复杂度
可以发现单次操作的时间复杂度均为 \(O(\log \log V)\)。
对于空间复杂度,假设一棵大小为 \(2^k\) 的 vEB 树空间复杂度为 \(T(k)\)。容易得到 \(\forall \ 1\le 2^i \le w,\ T(i) = 1\)。同时有 \(T(k) = T(\left\lceil\frac k2\right\rceil) + 2^{\left\lceil\frac k2\right\rceil}T(\left\lfloor\frac k2\right\rfloor) + 2\)。
我们可以证明 \(T(k)\) 可能会达到 \(O(\frac {2^k}{\sqrt w})\),但可以通过调整 vEB 树的叉数得到 \(O(\frac {2^k}{w})\) 的空间复杂度。
在值域大的情况下可以考虑哈希表等方式降低 vEB 树的空间复杂度。
4 对于部分数据结构效率的一些测试

操作次数为 \(10^7\),值域范围为 \([0,2^{24})\)。
第一组数据是插入 \(10^7\) 个不同的数字。
第二组数据是插入 \(10^6\) 个不同的数字后进行 \(9\times10^6\) 次前趋/后继查询。
第三组数据是插入 \(10^5\) 个不同的数字后进行 \(99\times10^5\) 次前趋/后继查询。
第四组数据是插入 \(5\times 10^6\) 个不同的数字后随机地删除这 \(5\times 10^6\) 个数字。
从时间角度来说:可以发现 vEB 树和压位 Trie 在时间上还是远远快于其它两个 \(\log\) 数据结构,在集合数字比较稀疏的情况下的查询甚至比树状数组快了 \(10\) 倍多。相对来说,vEB 树的插入删除略慢于压位 Trie,但是其查询效率还是可以的。这仅仅是随机数据,在更加强力的数据下 vEB 树可能会有相对更高的查询效率。但是压位 Trie 已经完全能够满足我们的使用需求。
从空间角度来说:四个数据结构使用的空间分别为:455MB, 64MB, 2.06MB, 2.03MB。可以见压位 Trie 与 vEB 树在操作数和值域基本同阶的情况下,空间也是非常占优势的。而
树状数组的空间也相对来说较小。
从实现难度来说,笔者认为压位 Trie,vEB 树实现难度均在可接受范围之内,而压位 Trie 相对来说更加容易实现,且在很多情况下效率更高。
这段粘的。
5 例题
5.1 [北大集训 2018] ZYB 的游览计划
给定一棵 \(n\) 个节点的树,和一个 \(1\sim n\) 的排列 \(p\)。定义一个整数区间 \([l,r]\) 的权值为从 \(1\) 号节点出发遍历完 \(p_l, p_l+1,\cdots,p_r\)(无需按顺序)后回到 \(1\) 号节点需要经过的最小边数。
现在将 \([1,n]\) 划分成 \(k\) 个区间,问权值和的最大值。\(2\le k \le n\le n\times k \le 2\times 10^5\)。
时间限制:\(\text{7s}\)。
空间限制:\(\text{512MB}\)。
可以决策单调性,这里不提。
容易发现我们沿着 dfs 序从小到大遍历一定是最优的。因此我们需要维护一个有序集合中任意两个点的距离以及 \(1\) 号节点和 dfs 序最小/最大的点的距离。
插入一个点 \(b\):求出点的前趋 \(a\) 和后继 \(c\),答案变化 \(dis(a,b) + dis(b,c) - dis(a,c)\)。
删除一个点 \(b\):求出点的前趋 \(a\) 和后继 \(c\),答案变化 \(dis(a,c) - dis(a,b) - dis(b,c)\)。
使用 vEB 树或压位 Trie 实现可以做到 \(O(nk\log n\log \log n)\)。
使用压位 Trie 的实现经测试可以做到 150ms 左右。
5.2 [ZJOI2019] 语言
有一棵 \(n\) 个顶点的树,和 \(q\) 条树上的链 \((u_i, v_i)\)。对于一条链,链上的任意不同的两个点之间都可以展开贸易活动。
询问一共有多少点对之间可以开展贸易活动。
时间限制:\(\text{3s}\)
空间限制:\(\text{512MB}\)
动态开点压位 Trie 合并?
先叨叨原题做法。维护一些点的虚树大小,支持虚树合并。可以直接线段树合并。
然后现在有一个压位 Trie,拉过来考虑。
因为是动态开点压位 Trie,所以每个点需要维护所有子节点的编号。每次合并需要把一棵树的子节点编号扔到另一棵树上。根据线段树合并的启发式做法,这玩意的复杂度是 \(O(n \log_w n)\) 的。
但是空间复杂度有点问题,同一时刻最多是 \(O(nw\log_w n)\) 个节点,不太行。
考虑一个树启。我们直接拿原重儿子的压位 Trie 过来,任意时刻只有 \(O(\log n)\) 个压位 Trie,每个 Trie 只有 \(O(\frac nw)\) 个点,总空间复杂度为 \(O(n\log n)\)。
