Parallel Programming on Graphs
这些课主要讲了关于图并行算法,包括pagerank等算法。
PageRank
PageRank 算法可以见https://en.wikipedia.org/wiki/PageRank#math_2
\[R[i]=\frac{1-\alpha}{N}+\alpha \sum_{j \text { linksto } i} \frac{R[j]}{\text { Outlinks }[j]} \]graph lab实现
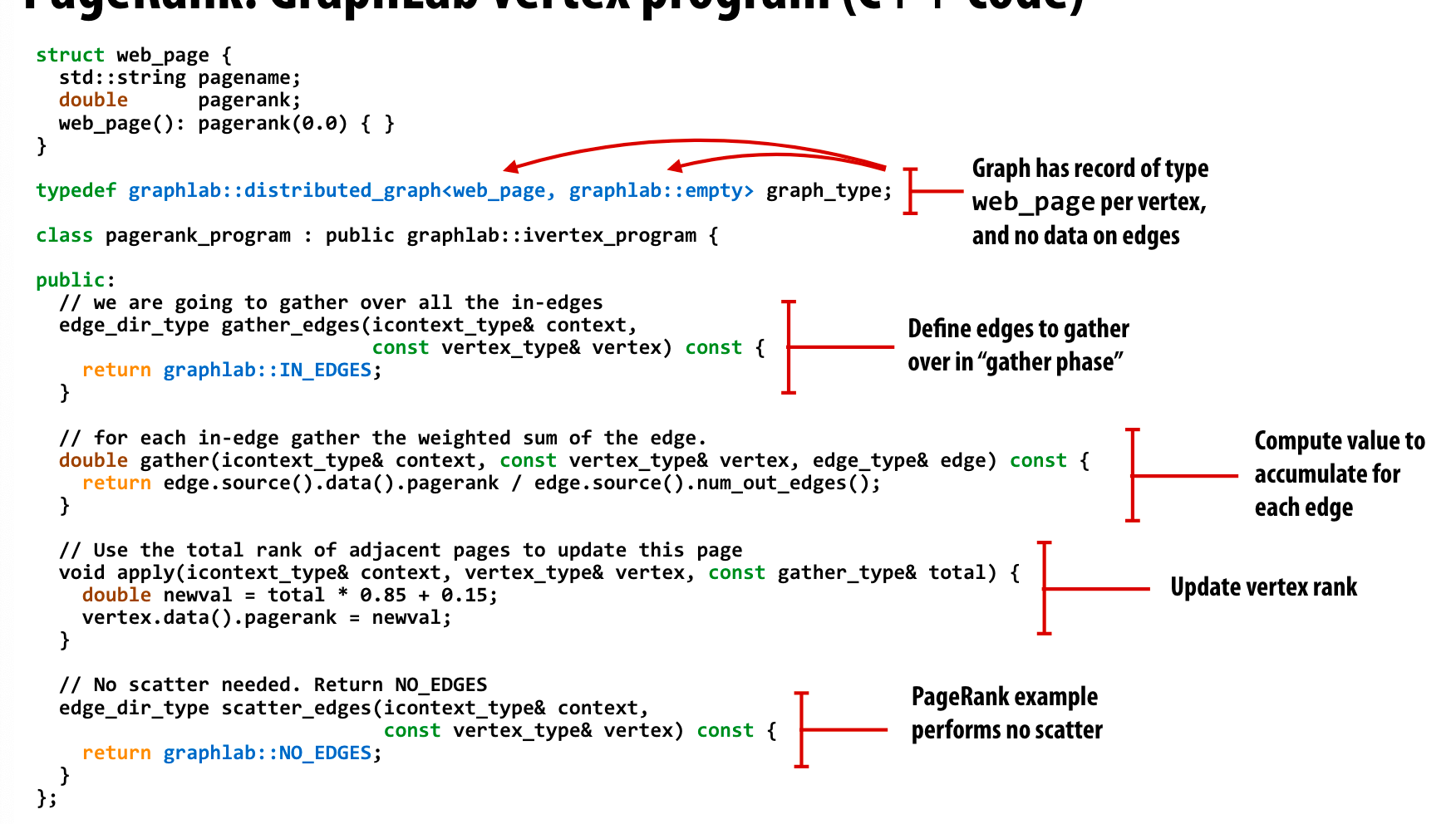
我没有使用过graphlab这个库,但是我猜测主要是,实现三个接口。
gather用于实现pagerank的正向计算,也就是计算某个vertex的所有入边能够提供的rank贡献。
apply用于更新当前点的rank值,也就是使用公式将gather的结果进行计算。
scatter有点类似于反向更新,即当前vertex的rank值更新之后,同时去更新其邻居的值。(这里scatter_edges 返回NO_EDGES,意味着不需要更新其邻居)
这个实现的算法如何收敛?教授抛出的这个问题,我开始想法是直接执行多轮迭代就是可以收敛吗?但是其实还有更好的办法。
graphLab还提供了这个signal的功能,意味着将当前vertex加入到任务池中,或者说工作队列中。
基于signal算法,可以将外圈的迭代放到算法的执行中。使用一个count标识执行的轮数。如果小于10轮,那么将当前点放入到工作队列中继续执行。

但是还可以利用scatter,如果某个点的rank值进行了更新,那么就将其邻居vertex进行signal加入到工作队列。

并行BFS
这里教授使用了Ligra作为了例子
我上github一看,这个项目基本上已经死了。还有腾讯开源的图计算框架柏拉图也死了,有点好奇,这些图计算框架是现在都不做了,还是大公司当做自己的商业机密不在开源?

每次利用frontier中的节点进行遍历,并行更新frontier,迭代执行EDGEMAP直到遍历所有点。
对于稀疏图算法

因为每个点都会加入一遍到result中,这样就会访问到所有点的记录,即所有出边。
对于稠密图算法

这里考虑的是出边,理想情况下,只需要执行一遍就可以遍历所有节点。
Graph sharding
如果对一个大图进行操作,可以无法将整张图完全放到内存中,这时候就需要对graph中sharding,这和数据库中的sharding思想很类似。
streaming graph computation
有一说一,这章节和我实习做的磁盘图索引优化工作关系挺大的。我们的需求也是当内存无法将图索引完全放入时候,就需要放入磁盘当中,因为ANNS的图算法的检索算法有点类似于BFS,这就会产生很多的4KB磁盘随机读,我们做的事情就是提升这个访问磁盘图索引的局部性。和这里教授提到的思想很接近,不过我们做的粒度更加小一点。
把一部分点的所有入边放到同一个shard中,并且按照source vertex ID进行排序。
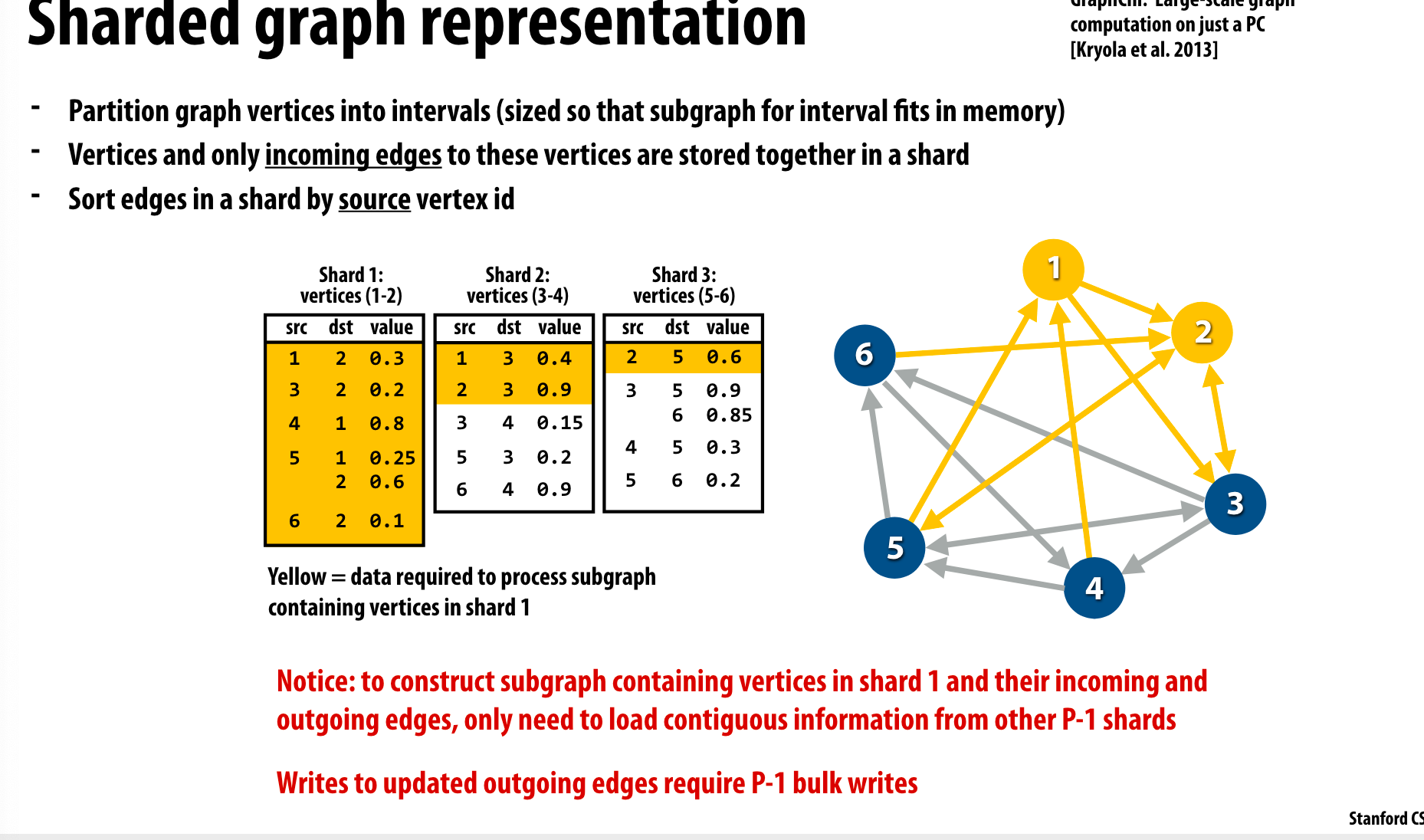
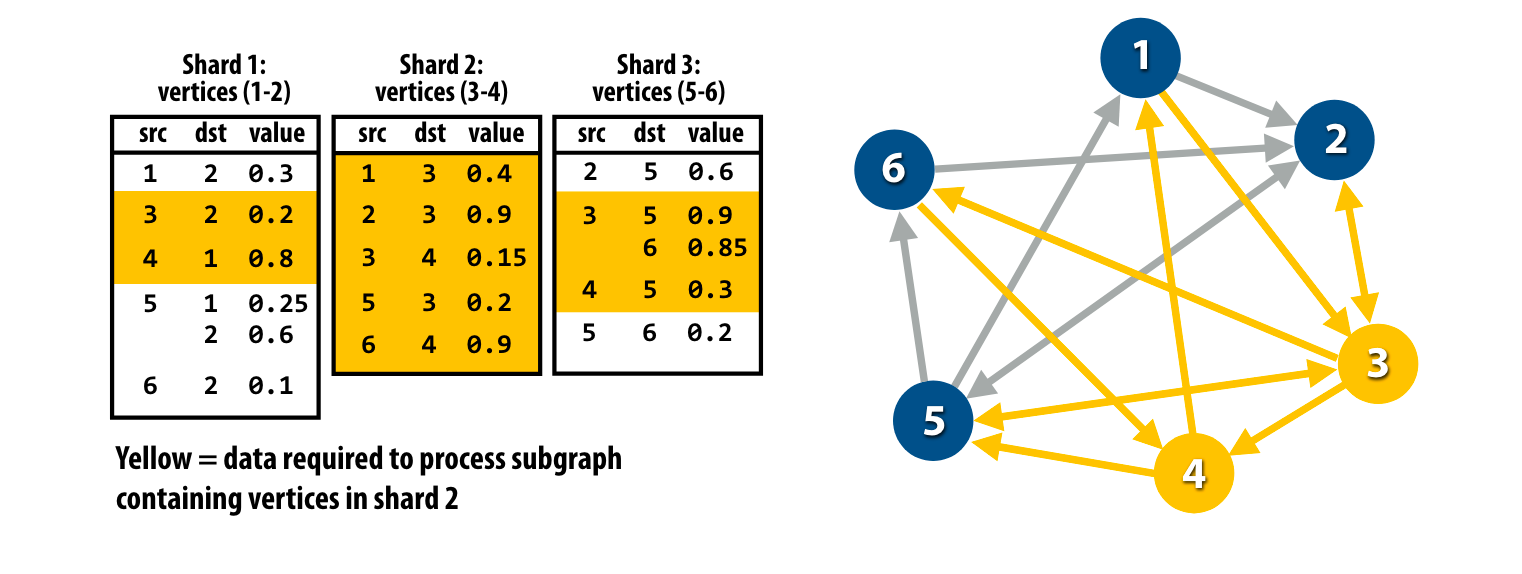
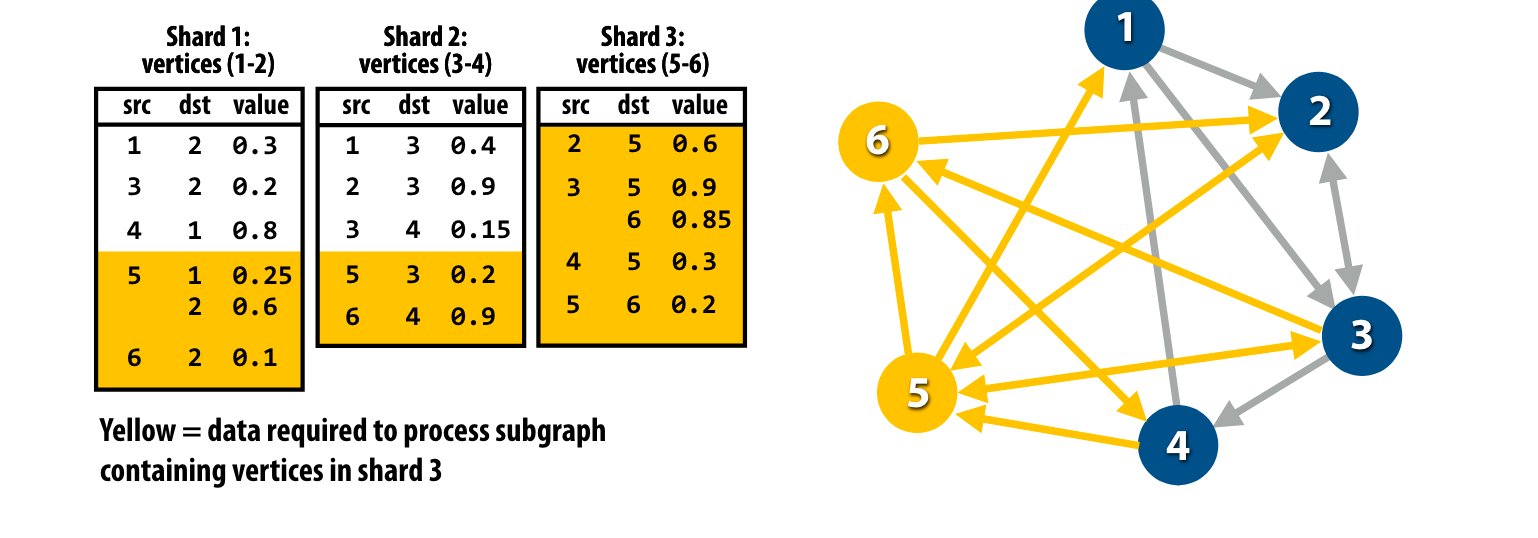
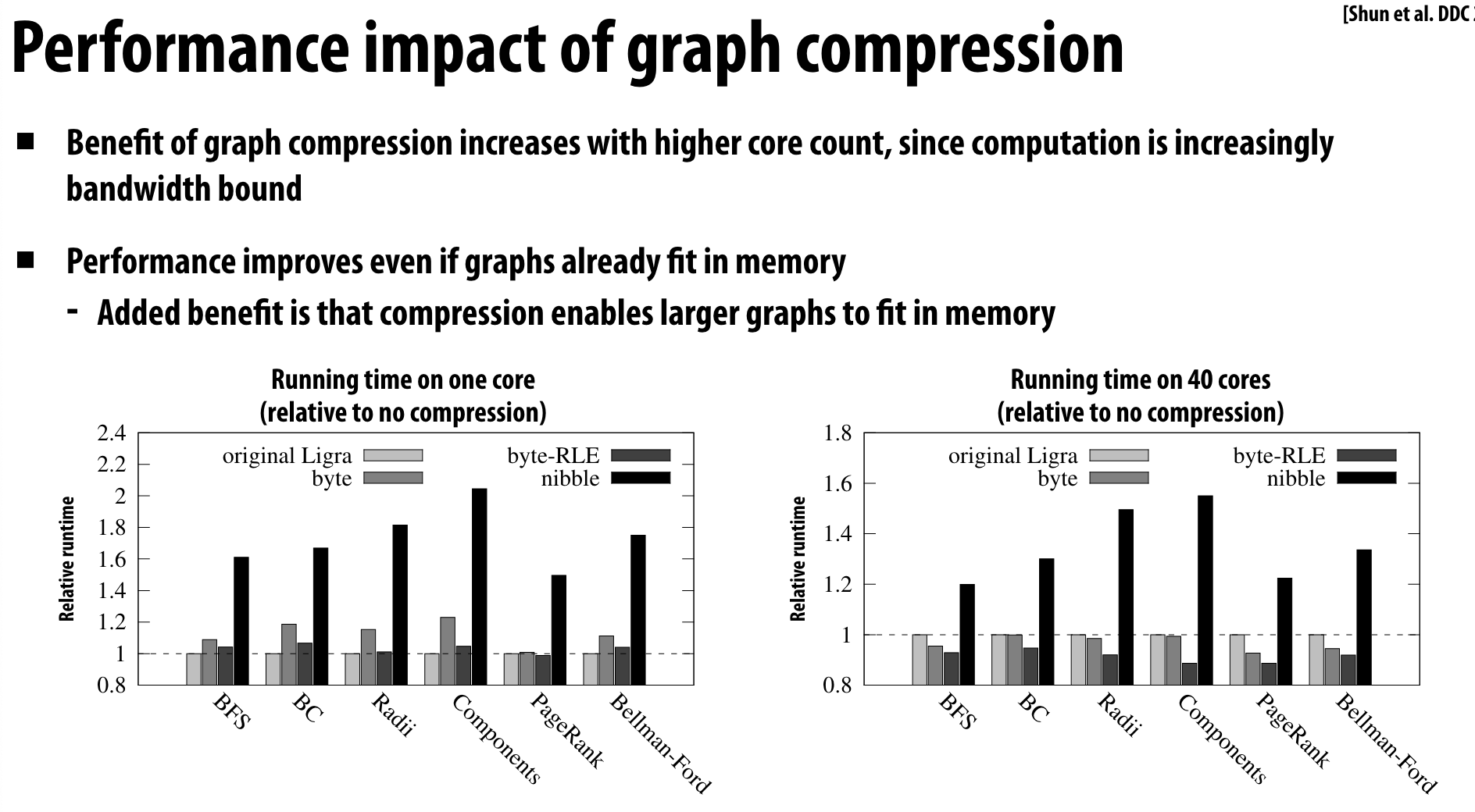
图压缩
即对邻接表进行压缩

我觉得不太靠谱。。。,但是教授说这样可以提高Cache的命中率,因为可以有更多数据放到cache中。