2022.10.28
明天 CSP-S 2022 ,八坂的神风护佑我 ( ˇωˇ)人 苗门

西西艾弗,我要把你出的题按在地上摩擦口牙!!
2022.10.29
哈哈嗨,来喽!
熟悉的海中,熟悉的 \(4\) 楼,熟悉的教室......怎么每年都在这里考啊 ( `д´)
来的有点晚,但是不用慌,先来看看 T1 ——
什么?分层图最长路?
当然那是不可能的,因为同一个节点可以经过多次。但是不用担心,我们还有记忆化搜索!当然每次要记录已经选择过的景点。
但是呢总不可能用 \(5\) 维 DP 罢!所以只在自变量中记录已经过节点就可以力!不要问我为什么,但是大样例过了就没关系!
哈哈嗨,下一题!
T2 什么玩意啊,没见过,下一题~
T3 题怎么这么长啊,算了仔细看看。
看完之后差不多有个 $ \Theta(n^2) $ 的思路了,然后打了出来。但是实现的时候似乎出了点问题,把判定 YES 的条件改成一个后反而好了?还过了大样例。
不管了,下一题~
T4 。
第一眼,简单~看我用倍增搞死它
第二眼,似乎有点不对劲,好像路径的长度还有限制?那我就不得不暴力了, $ \Theta(n^2) $ 走起~
他妈的一个输入我竟然调了差不多 20min ,太浪费时间了,赶紧搞
小样例过了,中样例过了,大样例过...啊咧?大样例怎么没过。
淦,怎么只剩 15min 了,算了不管了,直接交上去得了,摆烂。
估分估分!
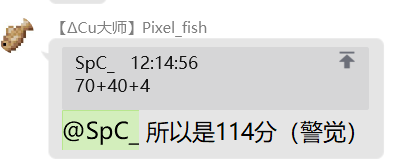
\[[20,100]+0+[20,40]+[0,20]=[40,160] \]好像也不咋地啊,算了还行吧。
赛后看看讨论区, T1 似乎写错了?有点慌。
不过吃饭才是第一位的!炒粉,炒面,烤↑冷↓面→,豆腐,生蚝,老盐柠檬......卧槽怎么这么咸啊,血压上来了(生理)
回到家,来自测力~
In Luogu:
哇↑
T1有90pts耶
哇↑
T3有40pts耶
哇↑
T4有4pts耶
In Jisuanke
哇↑
T1有85pts耶
哇↑
T3有40pts耶
哇↑
T4有4pts耶
In inf OJ
哇↑
T1有70pts耶
哇↑
T3有40pts耶
哇↑
T4有4pts耶
感觉还是不怎么样,算了等出分吧 ( ゚∀。)
.
.
.
.
.
什么? T2 比 T1 简单?
2022.11.8
出分力!
\[85+0+40+0=125 \]大概有个 1= ?但是还是太弱了,而且今年 HI 还有 200pts+ 的。
希望 NOIP 能有 200pts 。
经验/教训
痛啊,很痛啊!
这次的 CSP-S 2022 较去年有较大提高,其中很大一部分原因当然是因为我在这一年里水平有了一定的提升,但是这次的成绩仍然让我不太满意。经过思考过后,我总结出了几大原因:
- 做题策略错误
在这场比赛中,我做了一个让我悔恨终身的决定: 不写
T2。
当时我在比赛时,一看到这道题,就因为主观上感觉不熟悉跳过这道题而转战
T4,结果呢?
写
T4用时:1.75 h
思考
T2正解用时:15 min
写
T2用时: $ \leqslant$1.5 h
T4得分:0pts
T2(后来)得分:100pts
Rank 1\(\rightarrow\)Rank 16
归其根本,还是我个人竞赛经验不足,且缺乏一定的指导,导致了我这次的失败。
结合去年的
NOIP,我总结出了一个经验:
如果没有绝对的把握和充足的时间,或是前面的题都无法继续拿分,绝对不要碰最后一题。前面几题的难度可能并不递增,但是最后一题的难度一定是最难的。
在具备一定时间的情况下,即使打前几题的暴力解法也不要打最后一题的暴力解法,因为即使是暴力解法,在最后一题中也要花费较多时间完成,且正确率一般较小。
同时,在拿到题之后要花费一定时间读题并简化题意,选择自己最有把握的一道题去做。就算一道题初看没有头绪也要想一下,若
10 min内没有想到暴力解法才去写下一道题。
- 代码速度过慢
作为一名
OIer,难以置信地,我是一个 双指流!
比赛过后,我看到了 Alex_Wei 大佬的游记,并被他做题的神速震惊,明显感受到了双指流与多指流之间的差距,也感受到了自己在码力上的不足。
诚然,在我之前刷题的过程中,更多地在意思考的过程而非代码的实现。但是,我忽略了一点: 作为一名
OIer,无论怎样的奇思妙想,最终都要以代码的方式实现。如果代码速度过慢,就会导致一些已经有思路的题却因码力不足而无法在限定时间内实现,大大减小比赛时的优势。
看来要好好练一练打字了。
当然,足够的刷题量以及灵活的思维仍然是一个优秀 OIer 的必备素养。希望在 NOIP 时能够绝地翻盘,薄纱各位同省选手,直登 A 队队长宝座! $ \color{lightgray} \tiny \text{至少让我进队啊求求了} $
题解
- $ \texttt{Solution 1 } ( \Theta(nm+n^4) )$
显然地,题目要求我们找到一个包含四个点的路径,使得路径中每个直接连接的两点之间距离不超过 \((k+1)\) ,且路径的首尾两点与 \(1\) 号节点之间的距离均不超过 \((k+1)\) 。
更简洁地,题目要求找到一个包括 \(1\) 号节点的五元环,使得相邻两点间的距离不超过 \((k+1)\) 。
容易想到实现主要分为两步:处理出每个节点之间的距离以及找到合法的环。
对于第一步,可以用
Floyd-Warshall算法 $ \Theta(n^3) $ 求出任意两点间的最短路。
对于第二步,可以 $ \Theta(n^4) $ 枚举路径中的四个节点,并判断路径是否合法即可。
期望通过 $40 % $ 的数据。
- $ \texttt{Solution 2} ( \Theta(nm+n^2) )$
考虑对 $ \texttt{Solution 1} $ 进行优化。
首先对于第一步,发现边权只能为 \(1\) ,那么显然可以使用
BFS算法对于每一个节点, $ \Theta(n) $ 处理出其与其他任意节点之间的距离(实际上这个复杂度更小,因为当搜索到的距离大于 \((k+1)\) 时可以直接跳过),总时间复杂度为 $ \Theta(n^2) $ 。
发现其他的地方已经很难优化了,所以仔细分析题目的性质,试着使用贪心算法。
若设路径中的四个节点分别为 \(a \longrightarrow b \longrightarrow c \longrightarrow d\) ,且该路径合法,若依次枚举则很难快速找到答案,那么如果我们 只枚举中间的 \(b,c\) 两点 是否可行呢?
于是我们可以先设中间的 \(b,c\) 节点已知,而 \(a,d\) 节点未知,那么根据贪心思想,想要让答案合法且最大化,则 \(a,d\) 就要满足以下条件:
- 条件 \(1\) : \(a\) 与 \(1,b\) , \(d\) 与 \(c,1\) 节点之间的距离皆不超过 \((k+1)\)
- 条件 \(2\) : \(a,b\) 为所有满足条件 \(1\) 的 \(a,b\) 中权值和最大的两个节点
显然,在 \(b,c\) 节点已知的情况下, \(a,d\) 节点就很好得到了。
具体的实现流程分为两步:第一步为处理出每个节点 \(u\) 的 \(node_u\) , \(node_u\) 为一个点集,表示 所有与 \(u\) 和 \(1\) 节点的距离均不大于 \((k+1)\) 的节点 ,可以在
BFS的过程中同时求出。
第二步,枚举两个节点 \(b,c \in [2,n]\) ,并分别枚举每个 \(node_b\) 和 \(node_v\) 中的节点 \(a \in node_u,d \in node_v\) ,若 \(a \neq c,b \neq d,a \neq d\) ,则更新答案 $ans \leftarrow \max { ans,value_a+value_b+value_c+value_d } $ ,其中 \(value_u\) 表示节点 \(u\) 的点权。
此时的解法已经很接近正解了,大部分情况下第二步的时间复杂度远远小于 $ \Theta(n^3) $ ,但在一些特殊构造的图上(如菊花图)仍可能退化为 $ \Theta(n^3) $ 。
如果想要拿到满分还需要继续优化,而这时的优化策略已经一目了然了——我们只需要每次直接选择最小的 \(a,d\) 不就行了?只需要保存 \(node_u\) 的最大值,然后每次直接选出这个最大值即可。
不过事情没这么简单,因为还要保证 \(a \neq c,b \neq d,a \neq d\) 。这个也很好解决,只需要 保存前三大 就可以保证不冲突了。
所以每次在第一步更新点集 \(node_u\) 的时候,我们可以直接对这个集合按照点权排序,然后在第二步直接 $ \Theta(1) $ 选取合法的节点即可。
不过要注意每次进行排序后, 若 \(node_u\) 的大小大于 \(3\) ,就要立即排除第 \(3\) 大后面的节点 ,否则时间复杂度会退化为 $ \Theta(nm \log_2 n+n^2) $ 。
期望通过 $100 % $的数据。
#include <queue>
#include <cstdio>
#include <vector>
#include <cstring>
#include <algorithm>
#define lint long long
using namespace std;
struct Edge{int to,next;};
int n,m,k;
int total,dis[2505],head[2505];
lint ans,value[2505];
bool mark[2505][2505];
Edge edge[20005];
vector<int> node[2505];
inline int read()
{
int x=0,f=1;
char ch=getchar();
while(ch<'0'||ch>'9') {if(ch=='-') f=-1;ch=getchar();}
while(ch>='0'&&ch<='9') {x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}
return x*f;
}
inline void link(const int u,const int v) {edge[++total]=(Edge){v,head[u]},head[u]=total;}
inline bool cmp(const int A,const int B) {return value[A]>value[B];}
inline void BFS(const int root)
{
queue<int> q;
memset(dis,-1,sizeof(dis));
dis[root]=0,q.push(root);
while(!q.empty())
{
int u=q.front(); q.pop();
if(dis[u]>k+1) continue;
if(u!=root)
{
mark[root][u]=true;
if(root!=1&&mark[1][u])
{
node[root].push_back(u),sort(node[root].begin(),node[root].end(),cmp);
if(node[root].size()>3) node[root].pop_back();
}
}
for(int i=head[u],v;i;i=edge[i].next)
if(dis[v=edge[i].to]==-1) q.push(v),dis[v]=dis[u]+1;
}
}
int main()
{
n=read(),m=read(),k=read();
for(int i=2;i<=n;++i) scanf("%lld",&value[i]);
for(int i=1,u,v;i<=m;++i) u=read(),v=read(),link(u,v),link(v,u);
for(int i=1;i<=n;++i) BFS(i);
for(int u=2;u<=n;++u)
for(int v=2;v<=n;++v)
if(u!=v&&mark[u][v])
for(int i=0;i<node[u].size();++i)
for(int j=0;j<node[v].size();++j)
if(u!=node[v][j]&&v!=node[u][i]&&node[u][i]!=node[v][j]) ans=max(ans,value[u]+value[node[u][i]]+value[node[v][j]]+value[v]);
return printf("%lld",ans),0;
}
- $ \texttt{Solution 3 } ( \Theta(n^2+Tnm) ) $
然而作为一道思维题,这一道题的正解也是比较难想到的。
那么在比赛中,我们能否通过一些比较玄学的算法,快速地拿到大部分分呢?
在
OI赛事中,随机化是好文明。
考虑对 $ \texttt{Solution 1} $ 使用随机化。显然地,使用
BFS来求两点间的距离是很容易想到的,所以只考虑优化枚举五元环上的四个节点的过程即可。这个过程是 $ \Theta(n^4) $ 的,大部分数据都无法接受。
那么不妨人为地减少一些搜索量,比如就搜索个几百次。
这当然是可行的——很容易想到 每次对每个节点随机染色(取值范围为 \([1,4]\) ),并进行
DP,每步只能走到比当前节点的颜色大 \(1\) 的节点 。
由于在没有特殊构造图的情况下,符合条件的五元环相对较少,所以正确率大约为每次 $ \frac{2}{4^4} $ ,时间复杂度约为每次 $ \Theta(nm) $ ,可以进行差不多 \(200\) 次。
最终取每次
DP完后答案的最大值即可,时间复杂度为 $ \Theta(n^2+Tnm) $ ,其中 \(T\) 为进行DP的次数。
期望通过$ \text{玄学} % $ 的数据。
经过数次测试,得到平均得分为
82.5pts,且最低分不小于80pts,相当不错的成绩。
#include <queue>
#include <cstdio>
#include <vector>
#include <cstring>
#include <algorithm>
#define lint long long
using namespace std;
struct Edge{int to,next;};
int n,m,k;
int total,dis[2505],head[2505],color[2505];
lint ans,f[2505],value[2505];
bool mark[2505][2505];
Edge edge[20005];
vector<int> node[2505];
inline int read()
{
int x=0,f=1;
char ch=getchar();
while(ch<'0'||ch>'9') {if(ch=='-') f=-1;ch=getchar();}
while(ch>='0'&&ch<='9') {x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}
return x*f;
}
inline void link(const int u,const int v) {edge[++total]=(Edge){v,head[u]},head[u]=total;}
inline bool cmp(const int A,const int B) {return value[A]>value[B];}
inline void BFS(const int root)
{
queue<int> q;
memset(dis,-1,sizeof(dis));
dis[root]=0,q.push(root);
while(!q.empty())
{
int u=q.front(); q.pop();
if(dis[u]>k+1) continue;
if(u!=root) mark[root][u]=true,node[root].push_back(u);
for(int i=head[u],v;i;i=edge[i].next)
if(dis[v=edge[i].to]==-1) q.push(v),dis[v]=dis[u]+1;
}
}
inline void DFS(const int u,const int now)
{
if(f[u]!=-1) return;
if(now==4) {f[u]=(mark[1][u])?(value[u]):(-1); return;}
for(int i=0,v;i<node[u].size();++i)
if(color[v=node[u][i]]==now+1) DFS(v,now+1),f[u]=max(f[u],f[v]+value[u]);
}
int main()
{
srand(77777);
n=read(),m=read(),k=read();
for(int i=2;i<=n;++i) scanf("%lld",&value[i]);
for(int i=1,u,v;i<=m;++i) u=read(),v=read(),link(u,v),link(v,u);
for(int i=1;i<=n;++i) BFS(i);
for(int T=1;T<=200;++T)
{
for(int i=2;i<=n;++i) color[i]=rand()%4+1;
memset(f,-1,sizeof(f)),DFS(1,0),ans=max(ans,f[1]);
}
return printf("%lld",ans),0;
}
- $ \texttt{Solution 1 } ( \Theta(nmq) )$
容易看出每次询问实际上是要在 \([l_1,r_2]\) 中找到一个 \(i\) ,在 \([l_2,r_2]\) 中找到一个 \(j\) , 选择的 \(i\) 要考虑到可能选到的 \(j\) ,然后让 \(i\) 使得所有可能选到的 \((a_i \times b_j)\) 最大。
\[\max_{l_1 \leqslant i \leqslant r_1} \{ \min_{l_2 \leqslant j \leqslant r_2} \{ a_i \times b_j \} \} \]形式化地,题目要求每次询问求出
只需要对于每一个 \(i\) 枚举每一个 \(j\) ,并按照上述公式取最值即可。
期望通过 $60 % $ 的数据(所以我只需要打一个简单的暴力就能多
60pts?)。
- $ \texttt{Solution 2 } ( \Theta(n \log_2 n+m \log_2 m+q) / \Theta(n \log_2 n+m \log_2 m+q( \log_2 n+ \log_2 m) ) ) $
考后
15min想出的做法,我是傻逼。
模拟几个样例后发现,每次的答案都与选择的 \(a_i\) 和 \(b_j\) 的正负性有关。
考虑分类讨论,可分为以下几类:
- \(a_i\) 和 \(b_j\) 都只能为非负数
显然此时无论小 Q 选什么,最终得到的结果都只可能为非负数,所以他只能给结果乘上一个尽可能小的数,答案为 $ \max_{i=l_1}^{r_1} { a_i } \times \min_{j=l_2}^{r_2} { b_j } $
- \(a_i\) 和 \(b_j\) 都只能为负数
同上,可以看作是选绝对值,答案为 $ \min_{i=l_1}^{r_1} { a_i } \times \max_{j=l_2}^{r_2} { b_j } $
- \(a_i\) 只能为非负数, \(b_j\) 只能为负数
显然结果只会是非正数,那么小 L 只能让结果的绝对值尽可能小,而小 Q 会让绝对值尽可能大,答案为 $ \min_{i=l_1}^{r_1} { a_i } \times \min_{j=l_2}^{r_2} { b_j } $
- \(a_i\) 只能为负数, \(b_j\) 只能为非负数
同上,答案为 $ \max_{i=l_1}^{r_1} { a_i } \times \max_{j=l_2}^{r_2} { b_j } $
- \(a_i\) 既可能是非负数也可能是负数, \(b_j\) 只能为非负数
小 L 当然会让答案为非负数,且绝对值尽可能大,而小 Q 只能让绝对值尽可能小,所以答案为 $ \max_{i=l_1}^{r_1} { a_i } \times \min_{j=l_2}^{r_2} { b_j } $
- \(a_i\) 既可能是非负数也可能是负数, \(b_j\) 只能为负数
因为小 L 要是选正数的话就会被小 Q 把结果变成负数,所以小 L 会选绝对值尽可能大的负数,而小 Q 会选绝对值最小的 \(b_j\) ,答案为 $ \min_{i=l_1}^{r_1} { a_i } \times \max_{j=l_2}^{r_2} { b_j } $
- \(a_i\) 只能为非负数, \(b_j\) 既可能是非负数也可能是负数
显然小 L 怎么选结果都是负数,只能让绝对值尽可能小,而小 Q 会让绝对值尽可能大,所以答案为 $ \min_{i=l_1}^{r_1} { a_i } \times \min_{j=l_2}^{r_2} { b_j } $
- \(a_i\) 只能为负数, \(b_j\) 既可能是非负数也可能是负数
同上,答案为 $ \max_{i=l_1}^{r_1} { a_i } \times \max_{j=l_2}^{r_2} { b_j } $
- \(a_i\) 既可能是非负数也可能是负数, \(b_j\) 既可能是非负数也可能是负数
最麻烦的情况。
若小 L 选正数,那么小 Q 就会选负数来把结果变成负数,所以小 L 会让选的非负数绝对值尽可能小,而小 Q 会让选的负数绝对值尽可能大。
若小 L 选负数,那么小 Q 就会选正数来吧结果变成负数,同样小 L 会让选的负数绝对值尽可能小,而小 Q 会让选的正数绝对值尽可能大。
\[\max \{ x_1 \times y_2,x_2 \times y_1 \} \]设在区间 \([l_1,r_1]\) 中,最小的非负 \(a_i\) 为 \(x_1\) ,最大的负数 \(a_i\) 为 \(y_1\) ;在 \([l_2,r_2]\) 中,最大的非负 \(b_j\) 为 \(x_2\) ,最小的负数 \(b_j\) 为 \(y_2\) ,那么答案为
可以使用
ST表来维护区间最值,时间复杂度为 $ \Theta(n \log_2 n+m \log_2 m+q) $ ;也可以使用线段树 $ \Theta(n \log_2 n+m \log_2 m+q( \log_2 n+ \log_2 m) ) $ 达到同样的效果。
期望通过 $100 % $ 的数据。
\\不会线段树qwq
#include <cmath>
#include <cstdio>
#include <cstring>
#include <algorithm>
#define lint long long
using namespace std;
const lint inf=1e18;
int n,m,Q;
lint a[100005],b[100005],f[100005][20][2][2],g[100005][20][2][2];
inline signed read()
{
int x=0,f=1;
char ch=getchar();
while(ch<'0'||ch>'9') {if(ch=='-') f=-1;ch=getchar();}
while(ch>='0'&&ch<='9') {x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}
return x*f;
}
inline void init()
{
const int maxlog1=ceil(log2(n)),maxlog2=ceil(log2(m));
for(register int i=1;i<=n;++i)
{
if(a[i]>=0) f[i][0][0][0]=f[i][0][0][1]=a[i],f[i][0][1][0]=-inf,f[i][0][1][1]=inf;
if(a[i]<0) f[i][0][1][0]=f[i][0][1][1]=a[i],f[i][0][0][0]=-inf,f[i][0][0][1]=inf;
}
for(register int i=1;i<=m;++i)
{
if(b[i]>=0) g[i][0][0][0]=g[i][0][0][1]=b[i],g[i][0][1][0]=-inf,g[i][0][1][1]=inf;
if(b[i]<0) g[i][0][1][0]=g[i][0][1][1]=b[i],g[i][0][0][0]=-inf,g[i][0][0][1]=inf;
}
for(register int j=1;j<=maxlog1;++j)
for(register int i=1;i<=n-(1<<j)+1;++i)
{
f[i][j][0][0]=max(f[i][j-1][0][0],f[i+(1<<(j-1))][j-1][0][0]);
f[i][j][0][1]=min(f[i][j-1][0][1],f[i+(1<<(j-1))][j-1][0][1]);
f[i][j][1][0]=max(f[i][j-1][1][0],f[i+(1<<(j-1))][j-1][1][0]);
f[i][j][1][1]=min(f[i][j-1][1][1],f[i+(1<<(j-1))][j-1][1][1]);
}
for(register int j=1;j<=maxlog2;++j)
for(register int i=1;i<=m-(1<<j)+1;++i)
{
g[i][j][0][0]=max(g[i][j-1][0][0],g[i+(1<<(j-1))][j-1][0][0]);
g[i][j][0][1]=min(g[i][j-1][0][1],g[i+(1<<(j-1))][j-1][0][1]);
g[i][j][1][0]=max(g[i][j-1][1][0],g[i+(1<<(j-1))][j-1][1][0]);
g[i][j][1][1]=min(g[i][j-1][1][1],g[i+(1<<(j-1))][j-1][1][1]);
}
}
inline lint query(const int l,const int r,const int opt)
{
const int k=log2(r-l+1);
if(opt==1) return max(f[l][k][0][0],f[r-(1<<k)+1][k][0][0]);
if(opt==2) return min(f[l][k][0][1],f[r-(1<<k)+1][k][0][1]);
if(opt==3) return max(f[l][k][1][0],f[r-(1<<k)+1][k][1][0]);
if(opt==4) return min(f[l][k][1][1],f[r-(1<<k)+1][k][1][1]);
if(opt==5) return max(g[l][k][0][0],g[r-(1<<k)+1][k][0][0]);
if(opt==6) return min(g[l][k][0][1],g[r-(1<<k)+1][k][0][1]);
if(opt==7) return max(g[l][k][1][0],g[r-(1<<k)+1][k][1][0]);
if(opt==8) return min(g[l][k][1][1],g[r-(1<<k)+1][k][1][1]);
}
int main()
{
n=read(),m=read(),Q=read();
for(register int i=1;i<=n;++i) a[i]=read();
for(register int i=1;i<=m;++i) b[i]=read();
init();
while(Q--)
{
int l1=read(),r1=read(),l2=read(),r2=read();
lint maxa1=query(l1,r1,1),mina1=query(l1,r1,2),maxa2=query(l1,r1,3),mina2=query(l1,r1,4),
maxb1=query(l2,r2,5),minb1=query(l2,r2,6),maxb2=query(l2,r2,7),minb2=query(l2,r2,8);
if(maxa2==-inf&&mina2==inf&&maxb2==-inf&&minb2==inf) printf("%lld\n",maxa1*minb1);
if(maxa1==-inf&&mina1==inf&&maxb1==-inf&&minb1==inf) printf("%lld\n",mina2*maxb2);
if(maxa2==-inf&&mina2==inf&&maxb1==-inf&&minb1==inf) printf("%lld\n",mina1*minb2);
if(maxa1==-inf&&mina1==inf&&maxb2==-inf&&minb2==inf) printf("%lld\n",maxa2*maxb1);
if(maxa1!=-inf&&mina1!=inf&&maxa2!=-inf&&mina2!=inf&&maxb2==-inf&&minb2==inf) printf("%lld\n",maxa1*minb1);
if(maxa1!=-inf&&mina1!=inf&&maxa2!=-inf&&mina2!=inf&&maxb1==-inf&&minb1==inf) printf("%lld\n",mina2*maxb2);
if(maxa2==-inf&&mina2==inf&&maxb1!=-inf&&minb1!=inf&&maxb2!=-inf&&minb2!=inf) printf("%lld\n",mina1*minb2);
if(maxa1==-inf&&mina1==inf&&maxb1!=-inf&&minb1!=inf&&maxb2!=-inf&&minb2!=inf) printf("%lld\n",maxa2*maxb1);
if(maxa1!=-inf&&mina1!=inf&&maxa2!=-inf&&mina2!=inf&&maxb1!=-inf&&minb1!=inf&&maxb2!=-inf&&minb2!=inf) printf("%lld\n",max(mina1*minb2,maxa2*maxb1));
}
return 0;
}
- $ \texttt{Solution 1 } ( \Theta(nq) )$
对于比赛中的选手来说,做本题的第一个难点就是——读题!
面对一大串文字解题显然是困难的,我们尝试着把这一大段文字变成简洁的文字。
显然地,本题的四个操作分别对应有向图中的:
- 操作一:标记边 \((u,v)\) ,且保证该边未被标记
- 操作二:标记节点 \(u\) 的所有入边
- 操作三:取消标记 \((u,v)\) ,且保证该边已被标记
- 操作四:取消标记节点 \(u\) 的所有入边
同时,所有被标记的边均不贡献入度和出度,也不可通过。
同样,题中判断可以实现反击的条件为:
从任意节点出发, 均可以走到一个环内 。
而判断可以实现连续穿梭的条件为:
每个 节点的出度均为 \(1\) 。
每个操作的暴力实现显然容易想到且非常简单,这里不再赘述,主要来考虑判断是否可以反攻的条件。
对样例进行模拟(其实是同时判断两个条件错误后发现只判断一个条件反而正确)后,发现这道题有一个美妙的性质: 只要判断每个节点的出度是否均为 \(1\) 就可以判断是否可以反攻 。
在比赛中当然可以不进行证明,但实际上也容易发现 当可以实现反击时,整张图是一个基环树,而且是一个内向基环树 。
原因显然是因为此时整张图没有重边且有 \(n\) 个节点和 \(n\) 条边,而每条边都是出边,满足内向基环树的条件,而内向基环树满足从任意节点出发均可以走到一个环内,因为当每条边都是出边时,若要形成一个包含 \(n\) 条边的无环图至少需要 \((n+1)\) 个节点(一条简单路径),而整张图只有 \(n\) 个节点,所以最多走 \(n\) 步就会回到一个已经走过的节点上。
结论的充要性都已经被证明,剩下的是只是在每次操作后记录每个节点的出度并判断是否都为 \(1\) 即可,而这显然是非常容易实现的。
时间复杂度为 $ \Theta(nq) $ ,预计通过 $40 % \sim 50 % $ 的数据。
全部输出
NO能有45pts,有趣。
- $ \texttt{Solution 2 } ( \Theta(n+m+q) )$
考虑对 $ \texttt{Solution 1} $ 进行优化。
容易发现主要的时间是花在了操作 \(2\) 和操作 \(4\) ,以及判断每个节点的出度是否为 \(1\) 上。
而我们只需要能够快速知道在进行操作 \(2\) 和操作 \(4\) 的时候,被操作节点的被标记入边数量以及总入边数量就可以了。
而想要达到这个效果,我们就知道快速知道某个节点及其关联边的大体形状,而能够 $ \Theta(1) $ 查询图的形状的算法只有一个——那就是 哈希算法 !
具体地,我们 为每个节点 \(u\) 赋上一个随机的权值 \(value_u\) ,那么对于每个节点 \(u\) ,在未进行操作的情况下,它的每条入边对它的 总贡献为 \(sum_u= \sum_{(v,u) \in E} value_v\) ,也就是所有直接通向节点 \(u\) 的节点的权值之和。
然后对于每个操作,记录 当前节点 \(u\) 的状态 \(f(u)\) ,并对其进行修改:
- 操作一: \(f(v) \leftarrow f(v)-value_u\) ,代表节点 \(u\) 的权值已不再为节点 \(v\) 进行贡献。
- 操作二: \(f(u) \leftarrow 0\) ,代表此时节点 \(u\) 和所有可贡献的节点断开了联系。
- 操作三: \(f(v) \leftarrow f(v)+value_u\) ,代表节点 \(u\) 的权值对节点 \(v\) 恢复贡献。
- 操作四: \(f(v) \leftarrow sum_v\) ,代表此时节点 \(u\) 和所有可贡献的节点恢复了联系。
由于 保证进行操作一和操作三时的所有即将要标记/取消标记的节点均未被标记/已被标记 ,故无需判断每次操作的可行性。
那么如何判断是否可以反击呢?显然地,因为每个节点都有一条出边且无入边,则 每个节点都必定产生一次且仅产生一次贡献 。也就是说, 当 $ \sum_{u=1}^n f(u)= \sum_{u=1}^n value_u$ 时,可以实现反击 。
显然我们可以单独用一个变量快速维护 $ \sum_{u=1}^n f(u)$ 。
这种 通过记录每个节点关联节点(关联边)的权值和来表示图的形状的哈希方式被称为
Sum Hash。
时间复杂度为 $ \Theta(n+m+q) $ ,哈希算法正确率极高,期望通过 $100 % $ 的数据。
感觉没T1难
#include <cstdio>
#include <algorithm>
#define lint long long
using namespace std;
int n,m,q;
inline int read()
{
int x=0,f=1;
char ch=getchar();
while(ch<'0'||ch>'9') {if(ch=='-') f=-1;ch=getchar();}
while(ch>='0'&&ch<='9') {x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}
return x*f;
}
lint now,total,f[500005],sum[500005],value[500005];
int main()
{
srand(77777);
n=read(),m=read();
for(int i=1;i<=n;++i) value[i]=((rand()*rand())^rand()*i)%1000000000+1,total+=value[i];
for(int i=1,u,v;i<=m;++i) u=read(),v=read(),sum[v]+=value[u];
for(int i=1;i<=n;++i) f[i]=sum[i],now+=f[i];
q=read();
while(q--)
{
int opt=read(),u=read(),v;
if(opt==1) v=read(),now-=value[u],f[v]-=value[u];
if(opt==2) now-=f[u],f[u]=0;
if(opt==3) v=read(),now+=value[u],f[v]+=value[u];
if(opt==4) now+=sum[u]-f[u],f[u]=sum[u];
puts((now==total)?("YES"):("NO"));
}
return 0;
}
\