你是否遇到过数据集中有多个文本特性的情况?例如,根据消息的上下文正确地对消息进行分类,即理解前面的消息。比如说我们有下面的数据集,需要对其进行分类。

当只考虑message时,你可以看到它的情绪是积极的,因为“incredible”这个词。但是当考虑到背景时,我们可以看到它时消极的
所以对于上下文来说,我们需要知道更多的信息,例如:
- 是否值得将上下文作为一个单独的特征来考虑?
- 将两个文本特征集中在一起是否会提高模型的性能?
- 是否应该引入上下文和信息的权衡?如果是,合适的权重比例是多少?
本文有一个简单的实现,就是:将两个文本字段连接起来。与仅使用最新消息相比,它能给模型带来改进——但是我们应该深入研究两个文本的权重比例。所以可以创建一个神经网络,它有两种模式,每个模式上的密集层大小可调?这样,我们就能自动找到合适的权重!
这里我们介绍的TwoModalBERT支持在nn中查找两个文本模式的适当权重比例!让我们看看里面的神经网络是如何构建的。
TwoModalBERT体系结构
下面可以看到TwoModalBERT是如何构造的以及类参数
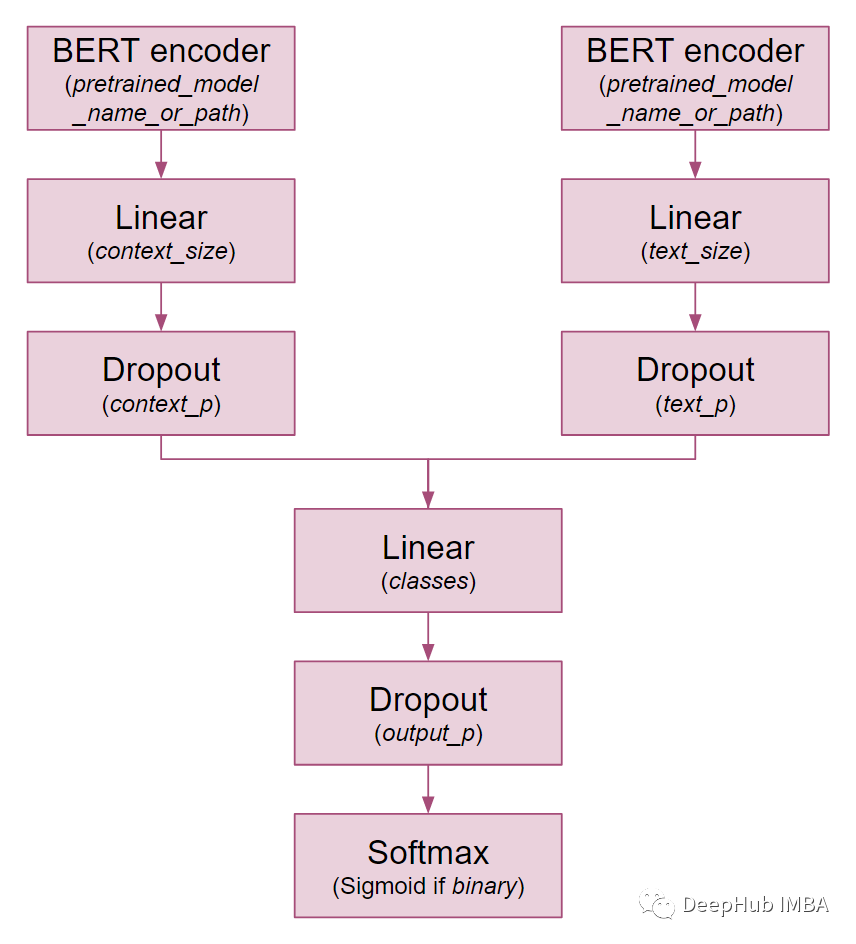
首先,在最后一个BERT层之上添加一个线性层。我们还是沿用BERT的配置,将其应用在CLS令牌之上。由于CLS令牌聚合了整个序列表示,它经常用于分类任务中。为了更好地理解,让我们看看相关的三行代码。
https://avoid.overfit.cn/post/30361ae7cee64dc993d8b08f5298b873
标签:文本,权重,角色,TwoModalBERT,分类,上下文,我们 From: https://www.cnblogs.com/deephub/p/16898530.html