页面解析之数据提取
一般来讲对我们而言,需要抓取的是某个网站或者某个应用的内容,提取有用的价值,内容一般分为两部分,非结构化的文本,或结构化的文本。
关于结构化的数据
JSON、XML
关于非结构化的数据
关于HTML文本(包含JavaScript代码)
HTML文本(包含JavaScript代码)是最常见的数据格式,理应属于结构化的文本组织,但因为一般我们需要的关键信息并非直接可以得到,需要进行对HTML的解析查找,甚至一些字符串操作才能得到,所以还是归类于非结构化的数据处理中。
把网页比作一个人,那么HTML便是他的骨架,JS便是他的肌肉,CSS便是它的衣服。
常见解析方式如下: XPath、CSS选择器、正则表达式
一段文本
例如一篇文章,或者一句话,我们的初衷是提取有效信息,所以如果是滞后处理,可以直接存储,如果是需要实时提取有用信息,常见的处理方式如下:
- 分词 根据抓取的网站类型,使用不同词库,进行基本的分词,然后变成词频统计,类似于向量的表示,词为方向,词频为长度。
- NLP 自然语言处理,进行语义分析,用结果表示,例如正负面等。
XPath 语言
XPath(XML Path Language)是XML路径语言,它是一种用来定位XML文档中某部分位置的语言。
学习目的
将HTML转换成XML文档之后,用XPath查找HTML节点或元素
比如用“/”来作为上下层级间的分隔,第一个“/”表示文档的根节点(注意,不是指文档最外层的tag节点,而是指文档本身)。
比如对于一个HTML文件来说,最外层的节点应该是"/html"。
XPath开发工具
-
开源的XPath表达式编辑工具:XMLQuire(XML格式文件可用)
-
chrome插件 XPath Helper
-
firefox插件 XPath Checker
XPath语法参考文档:
http://www.w3school.com.cn/xpath/index.asp
XPath语法
XPath 是一门在 XML 文档中查找信息的语言。
XPath 可用来在 XML 文档中对元素和属性进行遍历。
<?xml version="1.0" encoding="ISO-8859-1"?>
<bookstore>
<book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>
选取节点 XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。
下面列出了最有用的路径表达式:
| 表达式 | 描述 |
|---|---|
| / | 从根节点选取。 |
| nodename | 选取此节点的所有子节点。 |
| // | 从当前节点 选择 所有匹配文档中的节点 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
实例
在下面的表格中,我们已列出了一些路径表达式以及表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| /bookstore | 选取根元素 bookstore。注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| bookstore | 选取 bookstore 元素的所有子节点。默认从根节点选取 |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素。 |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置。 |
| //book/./title | 选取所有 book 子元素,从当前节点查找title节点 |
| //price/.. | 选取所有 book 子元素,从当前节点查找父节点 |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 |
| //@lang | 选取名为 lang 的所有属性。 |
- 谓语条件(Predicates)
- 谓语用来查找某个特定的信息或者包含某个指定的值的节点。
- 所谓"谓语条件",就是对路径表达式的附加条件
- 谓语是被嵌在方括号中,都写在方括号"[]"中,表示对节点进行进一步的筛选。
实例
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()❤️] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang=’eng’] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| //book[price] | 选取所有 book 元素,且被选中的book元素必须带有price子元素 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
- 选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点。 |
| @* | 匹配任何属性节点。 |
实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/* | 选取 bookstore 元素的所有子元素。 |
| //* | 选取文档中的所有元素。 |
| //title[@*] | 选取所有带有属性的 title 元素。 |
- 选取若干路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| //book/title | //book/price | 选取 book 元素的所有 title 和 price 元素。 |
| //title | //price | 选取文档中的所有 title 和 price 元素。 |
| /bookstore/book/title | //price | 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
XPath 高级用法
- 模糊查询 contains
目前许多web框架,都是动态生成界面的元素id,因此在每次操作相同界面时,ID都是变化的,这样为自动化测试造成了一定的影响。
<div class="eleWrapper" title="请输入用户名">
<input type="text" class="textfield" name="ID9sLJQnkQyLGLhYShhlJ6gPzHLgvhpKpLzp2Tyh4hyb1b4pnvzxFR!-166749344!1357374592067" id="nt1357374592068" />
</div>
解决方法 使用xpath的匹配功能,//input[contains(@id,'nt')]
- 测试使用的XML
<Root>
<Person ID="1001" >
<Name lang="zh-cn" >张城斌</Name>
<Email xmlns="www.quicklearn.cn" > cbcye@live.com </Email>
<Blog>http://cbcye.cnblogs.com</Blog>
</Person>
<Person ID="1002" >
<Name lang="en" >Gary Zhang</Name>
<Email xmlns="www.quicklearn.cn" > GaryZhang@cbcye.com</Email>
<Blog>http://www.quicklearn.cn</Blog>
</Person>
</Root>
- 查询所有Blog节点值中带有 cn 字符串的Person节点
Xpath表达式:
/Root//Person[contains(Blog,'cn')]
2.查询所有Blog节点值中带有 cn 字符串并且属性ID值中有01的Person节点
Xpath表达式:
/Root//Person[contains(Blog,'cn') and contains(@ID,'01')]
学习笔记
1.依靠自己的属性,文本定位
//td[text()='Data Import']
//div[contains(@class,'cux-rightArrowIcon-on')]
//a[text()='马上注册']
//input[@type='radio' and @value='1'] 多条件
//span[@name='bruce'][text()='bruce1'][1] 多条件
//span[@id='bruce1' or text()='bruce2'] 找出多个
//span[text()='bruce1' and text()='bruce2'] 找出多个
2.依靠父节点定位
//div[@class='x-grid-col-name x-grid-cell-inner']/div
//div[@id='dynamicGridTestInstanceformclearuxformdiv']/div
//div[@id='test']/input
3.依靠子节点定位
//div[div[@id='navigation']]
//div[div[@name='listType']]
//div[p[@name='testname']]
4.混合型
//div[div[@name='listType']]//img
//td[a//font[contains(text(),'seleleium2从零开始 视屏')]]//input[@type='checkbox']
5.进阶部分
//input[@id='123']/following-sibling::input 找下一个兄弟节点
//input[@id='123']/preceding-sibling::span 上一个兄弟节点
//input[starts-with(@id,'123')] 以什么开头
//span[not(contains(text(),'xpath'))] 不包含xpath字段的span
6.索引
//div/input[2]
//div[@id='position']/span[3]
//div[@id='position']/span[position()=3]
//div[@id='position']/span[position()>3]
//div[@id='position']/span[position()<3]
//div[@id='position']/span[last()]
//div[@id='position']/span[last()-1]
7.substring 截取判断
//*[substring(@id,4,5)='Every']/@id 截取该属性 定位3,取长度5的字符
//*[substring(@id,4)='EveryCookieWrap'] 截取该属性从定位3 到最后的字符
//*[substring-before(@id,'C')='swfEvery']/@id 属性 'C'之前的字符匹配
//*[substring-after(@id,'C')='ookieWrap']/@id 属性'C之后的字符匹配
8.通配符*
//span[@*='bruce']
//*[@name='bruce']
9.轴
//div[span[text()='+++current node']]/parent::div 找父节点
//div[span[text()='+++current node']]/ancestor::div 找祖先节点
10.孙子节点
//div[span[text()='current note']]/descendant::div/span[text()='123']
//div[span[text()='current note']]//div/span[text()='123'] 两个表达的意思一样
xpath提取多个标签下的text
在写爬虫的时候,经常会使用xpath进行数据的提取,对于如下的代码:
<div id="test1">大家好!</div>
使用xpath提取是非常方便的。假设网页的源代码在selector中:
data = selector.xpath('//div[@id="test1"]/text()').extract()[0]
就可以把“大家好!”提取到data变量中去。
然而如果遇到下面这段代码呢?
<div id="test2">美女,<font color=red>你的微信是多少?</font><div>
如果使用:
data = selector.xpath('//div[@id="test2"]/text()').extract()[0]
只能提取到“美女,”;
如果使用:
data = selector.xpath('//div[@id="test2"]/font/text()').extract()[0]
又只能提取到“你的微信是多少?”
可是我本意是想把“美女,你的微信是多少?”这一整个句子提取出来。
<div id="test3">我左青龙,<span id="tiger">右白虎,<ul>上朱雀,<li>下玄武。</li></ul>老牛在当中,</span>龙头在胸口。<div>
而且内部的标签还不固定,如果我有一百段这样类似的html代码,又如何使用xpath表达式,以最快最方便的方式提取出来?
使用xpath的string(.)
以第三段代码为例:
data = selector.xpath('//div[@id="test3"]')
info = data.xpath('string(.)').extract()[0]
这样,就可以把“我左青龙,右白虎,上朱雀,下玄武。老牛在当中,龙头在胸口”整个句子提取出来,赋值给info变量。
非结构化数据之lxml库
lxml 是一种使用 Python 编写的库,可以迅速、灵活地处理 XML ,支持 XPath (XML Path Language)
lxml python 官方文档
学习目的
利用上节课学习的XPath语法,来快速的定位 特定元素以及节点信息,目的是 提取出 HTML、XML 目标数据
如何安装
- Ubuntu :
sudo apt-get install libxml2-dev libxslt1-dev python-dev
sudo apt-get install zlib1g-dev
sudo apt-get install libevent-dev
sudo pip install lxml
利用 pip 安装即可
初步使用
首先我们利用lxml来解析 HTML 代码,先来一个小例子来感受一下它的基本用法。
使用 lxml 的 etree 库,然后利用 etree.HTML 初始化,然后我们将其打印出来。
from lxml import etree
text = '''
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
'''
#Parses an HTML document from a string
html = etree.HTML(text)
#Serialize an element to an encoded string representation of its XML tree
result = etree.tostring(html)
print result
所以输出结果是这样的
<html><body><div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</li></ul>
</div>
</body></html>
不仅补全了 li 标签,还添加了 body,html 标签。
XPath实例测试
- (1)获取所有的
<li>标签
print type(html)
result = html.xpath('//li')
print result
print len(result)
print type(result)
print type(result[0])
运行结果
<type 'lxml.etree._ElementTree'>
[<Element li at 0x1014e0e18>, <Element li at 0x1014e0ef0>, <Element li at 0x1014e0f38>, <Element li at 0x1014e0f80>, <Element li at 0x1014e0fc8>]
5
<type 'list'>
<type 'lxml.etree._Element'>
可见,每个元素都是 Element 类型;是一个个的标签元素,类似现在的实例
<Element li at 0x1014e0e18> Element类型代表的就是
<li class="item-0"><a href="link1.html">first item</a></li>
-
[注意]
Element类型是一种灵活的容器对象,用于在内存中存储结构化数据。
每个element对象都具有以下属性:
1. tag:string对象,标签,用于标识该元素表示哪种数据(即元素类型)。
2. attrib:dictionary对象,表示附有的属性。
3. text:string对象,表示element的内容。
4. tail:string对象,表示element闭合之后的尾迹。
-
实例
<tag attrib1=1>text</tag>tail 1 2 3 4result[0].tag result[0].text result[0].tail result[0].attrib -
(2)获取
<li>标签的所有 classhtml.xpath('//li/@class')运行结果
['item-0', 'item-1', 'item-inactive', 'item-1', 'item-0'] -
(3)获取
<li>标签下属性 href 为 link1.html 的<a>标签html.xpath('//li/a[@href="link1.html"]')运行结果
[<Element a at 0x10ffaae18>] -
(4)获取
<li>标签下的所有<span>标签注意这么写是不对的
html.xpath('//li/span')因为 / 是用来获取子元素的,而
<span>并不是<li>的子元素,所以,要用双斜杠html.xpath('//li//span')运行结果
[<Element span at 0x10d698e18>] -
(5)获取
<li>标签下的所有 class,不包括<li>html.xpath('//li/a//@class')运行结果
['blod'] -
(6)获取最后一个
<li>的<a>的 hrefhtml.xpath('//li[last()]/a/@href')运行结果
['link5.html'] -
(7)获取 class 为 bold 的标签名
result = html.xpath('//*[@class="bold"]') print result[0].tag运行结果
span
开始练习
通过以上实例的练习,相信大家对 XPath 的基本用法有了基本的了解
实战项目
以腾讯招聘网站为例
http://hr.tencent.com/position.php?&start=10
from lxml import etree
import urllib2
import urllib
import json
request = urllib2.Request('http://hr.tencent.com/position.php?&start=10#a')
response =urllib2.urlopen(request)
resHtml = response.read()
output =open('tencent.json','w')
html = etree.HTML(resHtml)
result = html.xpath('//tr[@class="odd"] | //tr[@class="even"]')
for site in result:
item={}
name = site.xpath('./td[1]/a')[0].text
detailLink = site.xpath('./td[1]/a')[0].attrib['href']
catalog = site.xpath('./td[2]')[0].text
recruitNumber = site.xpath('./td[3]')[0].text
workLocation = site.xpath('./td[4]')[0].text
publishTime = site.xpath('./td[5]')[0].text
print type(name)
print name,detailLink,catalog,recruitNumber,workLocation,publishTime
item['name']=name
item['detailLink']=detailLink
item['catalog']=catalog
item['recruitNumber']=recruitNumber
item['publishTime']=publishTime
line = json.dumps(item,ensure_ascii=False) + '\n'
print line
output.write(line.encode('utf-8'))
output.close()
CSS Selector
CSS(即层叠样式表Cascading Stylesheet),Selector来定位(locate)页面上的元素(Elements)。Selenium官网的Document里极力推荐使用CSS locator,而不是XPath来定位元素,原因是CSS locator比XPath locator速度快.
Beautiful Soup
- 支持从HTML或XML文件中提取数据的Python库
- 支持Python标准库中的HTML解析器
- 还支持一些第三方的解析器lxml, 使用的是 Xpath 语法,推荐安装。
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了
-
Beautiful Soup4 安装
官方文档链接:
https://www.crummy.com/software/BeautifulSoup/bs4/doc/
可以利用 pip来安装
pip install beautifulsoup4 -
安装解析器(上节课已经安装过)
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,其中一个是 lxml .根据操作系统不同,可以选择下列方法来安装lxml:
另一个可供选择的解析器是纯Python实现的 html5lib , html5lib的解析方式与浏览器相同,可以选择下列方法来安装html5lib:
pip install html5lib
下表列出了主要的解析器:
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(markup, "html.parser") | Python的内置标准库;执行速度适中;文档容错能力强 | Python 2.7.3 or 3.2.2前 的版本中文档容错能力差 |
| lxml HTML 解析器 | BeautifulSoup(markup, "lxml") | 速度快;文档容错能力强 ; | 需要安装C语言库 |
| lxml XML 解析器 | BeautifulSoup(markup, ["lxml-xml"]) BeautifulSoup(markup, "xml") | 速度快;唯一支持XML的解析器 | 需要安装C语言库 |
| html5lib | BeautifulSoup(markup, "html5lib") | 最好的容错性;以浏览器的方式解析文档;生成HTML5格式的文档 | 速度慢;不依赖外部扩展 |
推荐使用lxml作为解析器,因为效率更高. 在Python2.7.3之前的版本和Python3中3.2.2之前的版本,必须安装lxml或html5lib, 因为那些Python版本的标准库中内置的HTML解析方法不够稳定.
- 快速开始
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
使用BeautifulSoup解析这段代码,能够得到一个 BeautifulSoup 的对象,并能按照标准的缩进格式的结构输出:
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc,'lxml')
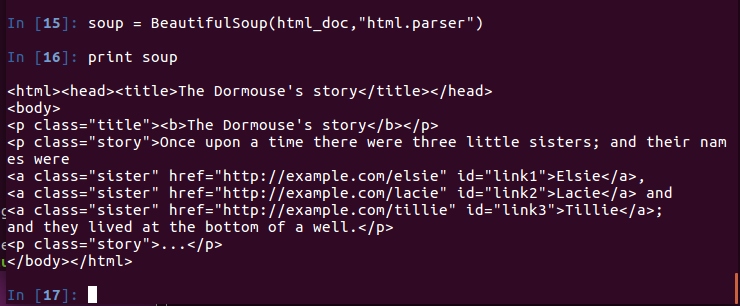
下面我们来打印一下 soup 对象的内容
print soup
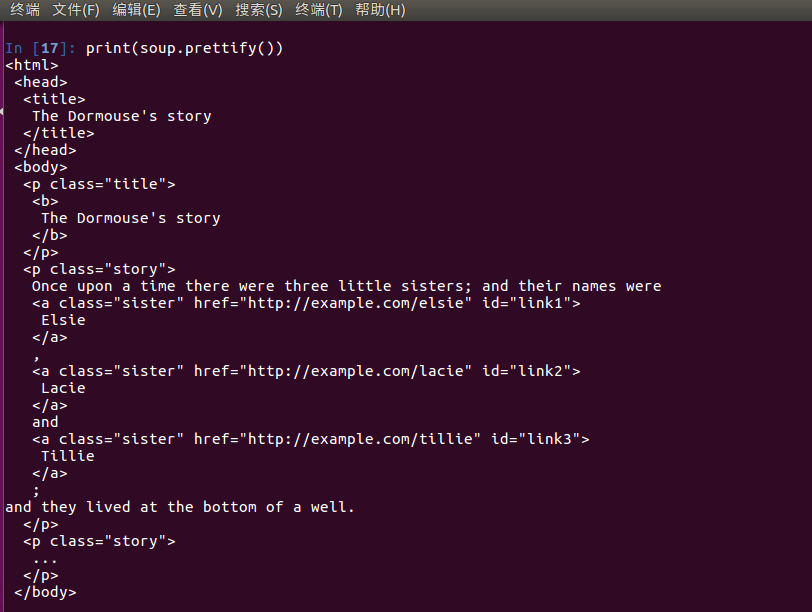
格式化输出soup 对象
print(soup.prettify())
CSS选择器
在写 CSS 时:
标签名不加任何修饰
类名前加点
id名前加 #
利用类似的方法来筛选元素,用到的方法是 soup.select(),返回类型是 list
-
通过标签名查找
print soup.select('title') #[<title>The Dormouse's story</title>] print soup.select('a') #[<a class="sister" href="http://example.com/elsie" id="link1"></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>] print soup.select('b') #[<b>The Dormouse's story</b>] -
通过类名查找
print soup.select('.sister') #[<a class="sister" href="http://example.com/elsie" id="link1"></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>] -
通过 id 名查找
print soup.select('#link1') #[<a class="sister" href="http://example.com/elsie" id="link1"></a>] -
直接子标签查找
print soup.select("head > title") #[<title>The Dormouse's story</title>] -
组合查找
组合查找即标签名与类名、id名进行的组合原理是一样的,例如查找 p 标签中,id 等于 link1的内容,
属性和标签不属于同一节点 二者需要用空格分开
print soup.select('p #link1') #[<a class="sister" href="http://example.com/elsie" id="link1"></a>] -
属性查找
查找时还可以加入属性元素,属性需要用中括号括起来
注意属性和标签属于同一节点,所以中间不能加空格,否则会无法匹配到
print soup.select('a[class="sister"]') #[<a class="sister" href="http://example.com/elsie" id="link1"></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>] print soup.select('a[href="http://example.com/elsie"]') #[<a class="sister" href="http://example.com/elsie" id="link1"></a>]同样,属性仍然可以与上述查找方式组合,不在同一节点的空格隔开,同一节点的不加空格
print soup.select('p a[href="http://example.com/elsie"]') #[<a class="sister" href="http://example.com/elsie" id="link1"></a>]以上的 select 方法返回的结果都是列表形式,可以遍历形式输出
用 get_text() 方法来获取它的内容。
print soup.select('title')[0].get_text() for title in soup.select('title'): print title.get_text()
Tag
Tag 是什么?通俗点讲就是 HTML 中的一个个标签,例如
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
print type(soup.select('a')[0])
输出:
bs4.element.Tag
对于 Tag,它有两个重要的属性,是 name 和 attrs,下面我们分别来感受一下
-
name
print soup.name print soup.select('a')[0].name输出:
[document] 'a'soup 对象本身比较特殊,它的 name 即为 [document],对于其他内部标签,输出的值便为标签本身的名称。
-
attrs
print soup.select('a')[0].attrs输出:
{'href': 'http://example.com/elsie', 'class': ['sister'], 'id': 'link1'}在这里,我们把 soup.select('a')[0] 标签的所有属性打印输出了出来,得到的类型是一个字典。
如果我们想要单独获取某个属性,可以这样,例如我们获取它的 class 叫什么
print soup.select('a')[0].attrs['class']输出:
['sister']
实战案例
我们还是以 腾讯招聘网站
http://hr.tencent.com/position.php?&start=10#a
from bs4 import BeautifulSoup
import urllib2
import urllib
import json
request = urllib2.Request('http://hr.tencent.com/position.php?&start=10#a')
response =urllib2.urlopen(request)
resHtml = response.read()
output =open('tencent.json','w')
html = BeautifulSoup(resHtml,'lxml')
result = html.select('tr[class="even"]')
result2 = html.select('tr[class="odd"]')
result+=result2
print len(result)
for site in result:
item={}
name = site.select('td a')[0].get_text()
detailLink = site.select('td a')[0].attrs['href']
catalog = site.select('td')[1].get_text()
recruitNumber = site.select('td')[2].get_text()
workLocation = site.select('td')[3].get_text()
publishTime = site.select('td')[4].get_text()
item['name']=name
item['detailLink']=detailLink
item['catalog']=catalog
item['recruitNumber']=recruitNumber
item['publishTime']=publishTime
line = json.dumps(item,ensure_ascii=False)
print line
output.write(line.encode('utf-8'))
output.close()
正则表达式
掌握了XPath、CSS选择器,为什么还要学习正则?
正则表达式,用标准正则解析,一般会把HTML当做普通文本,用指定格式匹配当相关文本,适合小片段文本,或者某一串字符(比如电话号码、邮箱账户),或者HTML包含javascript的代码,无法用CSS选择器或者XPath
了解正则表达式
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个"规则字符串",这个"规则字符串"用来表达对字符串的一种过滤逻辑。
正则表达式常见概念
-
边界匹配
^ -- 与字符串开始的地方匹配,不匹配任何字符;
$ -- 与字符串结束的地方匹配,不匹配任何字符;
str = "cat abdcatdetf ios" ^cat : 验证该行以c开头紧接着是a,然后是t ios$ : 验证该行以t结尾倒数第二个字符为a倒数第三个字符为c ^cat$: 以c开头接着是a->t然后是行结束:只有cat三个字母的数据行 ^$ : 开头之后马上结束:空白行,不包括任何字符 ^ : 行的开头,可以匹配任何行,因为每个行都有行开头\b -- 匹配一个单词边界,也就是单词和空格之间的位置,不匹配任何字符;
"er\b"可以匹配"never"中的"er",但不能匹配"verb"中的"er"。\B -- \b取非,即匹配一个非单词边界;
"er\B"能匹配"verb"中的"er",但不能匹配"never"中的"er"。 -
数量词的贪婪模式与非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪的则相反,总是尝试匹配尽可能少的字符。例如:
正则表达式"ab*"如果用于查找"abbbc",将找到"abbb"。而如果使用非贪婪的数量词"ab*?",将找到"a"。 -
反斜杠问题
与大多数编程语言相同,正则表达式里使用""作为转义字符,这就可能造成反斜杠困扰。
假如你需要匹配文本中的字符"",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。
Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\"表示。
同样,匹配一个数字的"\d"可以写成r"\d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
import re a=re.search(r"\\","ab123bb\c") print a.group() \ a=re.search(r"\d","ab123bb\c") print a.group() 1
Python Re模块
Python 自带了re模块,它提供了对正则表达式的支持。
match函数
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
下面是此函数的语法:
re.match(pattern, string, flags=0)
这里的参数的说明:
| 参数 | 描述 |
|---|---|
| pattern | 这是正则表达式来进行匹配。 |
| string | 这是字符串,这将被搜索匹配的模式,在字符串的开头。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。 |
匹配成功re.match方法返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
| 匹配对象的方法 | 描述 |
|---|---|
| group(num=0) | 此方法返回整个匹配(或指定分组num) |
| groups() | 此方法返回所有元组匹配的子组(空,如果没有) |
例子:
#!/usr/bin/python
import re
line = "Cats are smarter than dogs"
matchObj = re.match( r'(.*) are (.*?) .*', line, re.M|re.I)
if matchObj:
print "matchObj.group() : ", matchObj.group()
print "matchObj.group(1) : ", matchObj.group(1)
print "matchObj.group(2) : ", matchObj.group(2)
else:
print "No match!!"
当执行上面的代码,它产生以下结果:
matchObj.group() : Cats are smarter than dogs
matchObj.group(1) : Cats
matchObj.group(2) : smarter
正则表达式修饰符 - 选项标志
正则表达式字面可以包含一个可选的修饰符来控制匹配的各个方面。修饰符被指定为一个可选的标志。可以使用异或提供多个修饰符(|),如先前所示,并且可以由这些中的一个来表示:
| 修饰符 | 描述 |
|---|---|
| re.I(re.IGNORECASE) | 使匹配对大小写不敏感 |
| re.M(MULTILINE) | 多行匹配,影响 ^ 和 $ |
| re.S(DOTALL) | 使 . 匹配包括换行在内的所有字符 |
| re.X(VERBOSE) | 正则表达式可以是多行,忽略空白字符,并可以加入注释 |
findall()函数
re.findall(pattern, string, flags=0)
返回字符串中所有模式的非重叠的匹配,作为字符串列表。该字符串扫描左到右,并匹配返回的顺序发现
默认:
pattren = "\w+"
target = "hello world\nWORLD HELLO"
re.findall(pattren,target)
['hello', 'world', 'WORLD', 'HELLO']
re.I:
re.findall("world", target,re.I)
['world', 'WORLD']
re.S:
re.findall("world.WORLD", target,re.S)
["world\nworld"]
re.findall("hello.*WORLD", target,re.S)
['hello world\nWORLD']
re.M:
re.findall("^WORLD",target,re.M)
["WORLD"]
re.X:
reStr = '''\d{3} #区号
-\d{8}''' #号码
re.findall(reStr,"010-12345678",re.X)
["010-12345678"]
search函数
re.search 扫描整个字符串并返回第一个成功的匹配。
下面是此函数语法:
re.search(pattern, string, flags=0)
这里的参数说明:
| 参数 | 描述 |
|---|---|
| pattern | 这是正则表达式来进行匹配。 |
| string | 这是字符串,这将被搜索到的字符串中的任何位置匹配的模式。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。 |
匹配成功re.search方法返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
| 匹配对象的方法 | 描述 |
|---|---|
| group(num=0) | 此方法返回整个匹配(或指定分组num) |
| groups() | 此方法返回所有元组匹配的子组(空,如果没有) |
例子:
#!/usr/bin/python
import re
line = "Cats are smarter than dogs";
searchObj = re.search( r'(.*) are (.*?) .*', line, re.M|re.I)
if searchObj:
print "searchObj.group() : ", searchObj.group()
print "searchObj.group(1) : ", searchObj.group(1)
print "searchObj.group(2) : ", searchObj.group(2)
else:
print "Nothing found!!"
当执行上面的代码,它产生以下结果:
matchObj.group() : Cats are smarter than dogs
matchObj.group(1) : Cats
matchObj.group(2) : smarter
re.match与re.search的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
例子:
#!/usr/bin/python
import re
line = "Cats are smarter than dogs";
matchObj = re.match( r'dogs', line, re.M|re.I)
if matchObj:
print "match --> matchObj.group() : ", matchObj.group()
else:
print "No match!!"
searchObj = re.search( r'dogs', line, re.M|re.I)
if searchObj:
print "search --> searchObj.group() : ", searchObj.group()
else:
print "Nothing found!!"
当执行上面的代码,产生以下结果:
No match!!
search --> matchObj.group() : dogs
搜索和替换
Python 的re模块提供了re.sub用于替换字符串中的匹配项。
语法
re.sub(pattern, repl, string, max=0)
返回的字符串是在字符串中用 RE 最左边不重复的匹配来替换。如果模式没有发现,字符将被没有改变地返回。 可选参数 count 是模式匹配后替换的最大次数;count 必须是非负整数。缺省值是 0 表示替换所有的匹配。 实例:
例子
下面是一个爬虫做翻页面例子:
#!/usr/bin/python
import re
url = "http://hr.tencent.com/position.php?&start=10"
page = re.search('start=(\d+)',url).group(1)
nexturl = re.sub(r'start=(\d+)', 'start='+str(int(page)+10), url)
print "Next Url : ", nexturl
当执行上面的代码,产生以下结果:
Next Url : http://hr.tencent.com/position.php?&start=20
页面解析之结构化数据
结构化的数据是最好处理,一般都是类似JSON格式的字符串,直接解析JSON数据,提取JSON的关键字段即可。
JSON
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式;适用于进行数据交互的场景,比如网站前台与后台之间的数据交互
Python 2.7中自带了JSON模块,直接import json就可以使用了。
Json模块提供了四个功能:dumps、dump、loads、load,用于字符串 和 python数据类型间进行转换
1. json.loads()
实现:json字符串 转化 python的类型,返回一个python的类型
从json到python的类型转化对照如下:
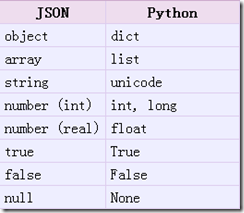
import json
a="[1,2,3,4]"
b='{"k1":1,"k2":2}'#当字符串为字典时{}外面必须是''单引号{}里面必须是""双引号
print json.loads(a)
[1, 2, 3, 4]
print json.loads(b)
{'k2': 2, 'k1': 1}
案例
import urllib2
import json
response = urllib2.urlopen(r'http://api.douban.com/v2/book/isbn/9787218087351')
hjson = json.loads(response.read())
print hjson.keys()
print hjson['rating']
print hjson['images']['large']
print hjson['summary']
2. json.dumps()
实现python类型转化为json字符串,返回一个str对象
从python原始类型向json类型的转化对照如下:
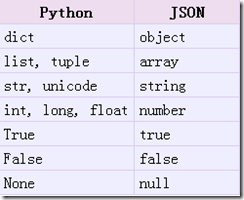
import json
a = [1,2,3,4]
b ={"k1":1,"k2":2}
c = (1,2,3,4)
json.dumps(a)
'[1, 2, 3, 4]'
json.dumps(b)
'{"k2": 2, "k1": 1}'
json.dumps(c)
'[1, 2, 3, 4]'
json.dumps 中的ensure_ascii 参数引起的中文编码问题
如果Python Dict字典含有中文,json.dumps 序列化时对中文默认使用的ascii编码
import chardet
import json
b = {"name":"中国"}
json.dumps(b)
'{"name": "\\u4e2d\\u56fd"}'
print json.dumps(b)
{"name": "\u4e2d\u56fd"}
chardet.detect(json.dumps(b))
{'confidence': 1.0, 'encoding': 'ascii'}
'中国' 中的ascii 字符码,而不是真正的中文。
想输出真正的中文需要指定ensure_ascii=False
json.dumps(b,ensure_ascii=False)
'{"name": "\xe6\x88\x91"}'
print json.dumps(b,ensure_ascii=False)
{"name": "我"}
chardet.detect(json.dumps(b,ensure_ascii=False))
{'confidence': 0.7525, 'encoding': 'utf-8'}
3. json.dump()
把Python类型 以 字符串的形式 写到文件中
import json
a = [1,2,3,4]
json.dump(a,open("digital.json","w"))
b = {"name":"我"}
json.dump(b,open("name.json","w"),ensure_ascii=False)
json.dump(b,open("name2.json","w"),ensure_ascii=True)
4. json.load()
读取 文件中json形式的字符串元素 转化成python类型
# -*- coding: utf-8 -*-
import json
number = json.load(open("digital.json"))
print number
b = json.load(open("name.json"))
print b
b.keys()
print b['name']
实战项目
获取 lagou 城市表信息
import urllib2
import json
import chardet
url ='http://www.lagou.com/lbs/getAllCitySearchLabels.json?'
request =urllib2.Request(url)
response = urllib2.urlopen(request)
print response.code
resHtml = response.read()
jsonobj = json.loads(resHtml)
print type(jsonobj)
print jsonobj
citylist =[]
allcitys = jsonobj['content']['data']['allCitySearchLabels']
print allcitys.keys()
for key in allcitys:
print type(allcitys[key])
for item in allcitys[key]:
name =item['name'].encode('utf-8')
print name,type(name)
citylist.append(name)
fp = open('city.json','w')
content = json.dumps(citylist,ensure_ascii=False)
print content
fp.write(content)
fp.close()
输出:
JSONPath
JSON 信息抽取类库,从JSON文档中抽取指定信息的工具
JSONPath与Xpath区别
JsonPath 对于 JSON 来说,相当于 XPATH 对于XML。
下载地址:
https://pypi.python.org/pypi/jsonpath/
安装方法:
下载jsonpath,解压之后执行'python setup.py install'
| XPath | JSONPath | Result |
|---|---|---|
/store/book/author |
$.store.book[*].author |
the authors of all books in the store |
//author |
$..author |
all authors |
/store/* |
$.store.* |
all things in store, which are some books and a red bicycle. |
/store//price |
$.store..price |
the price of everything in the store. |
//book[3] |
$..book[2] |
the third book |
//book[last()] |
$..book[(@.length-1)] $..book[-1:] |
the last book in order. |
//book[position()<3] |
$..book[0,1] $..book[:2] |
the first two books |
//book[isbn] |
$..book[?(@.isbn)] |
filter all books with isbn number |
//book[price<10] |
$..book[?(@.price<10)] |
filter all books cheapier than 10 |
//* |
$..* |
all Elements in XML document. All members of JSON structure. |
案例
还是以 http://www.lagou.com/lbs/getAllCitySearchLabels.json 为例,获取所有城市
import jsonpath
import urllib2
import chardet
url ='http://www.lagou.com/lbs/getAllCitySearchLabels.json'
request =urllib2.Request(url)
response = urllib2.urlopen(request)
print response.code
resHtml = response.read()
##detect charset
print chardet.detect(resHtml)
jsonobj = json.loads(resHtml)
citylist = jsonpath.jsonpath(jsonobj,'$..name')
print citylist
print type(citylist)
fp = open('city.json','w')
content = json.dumps(citylist,ensure_ascii=False)
print content
fp.write(content.encode('utf-8'))
fp.close()
XML
xmltodict模块让使用XML感觉跟操作JSON一样
Python操作XML的第三方库参考:
https://github.com/martinblech/xmltodict
模块安装:
pip install xmltodict
import xmltodict
bookdict = xmltodict.parse("""
<bookstore>
<book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>
""")
print bookdict.keys()
[u'bookstore']
print json.dumps(bookdict,indent=4)
输出结果:
{
"bookstore": {
"book": [
{
"title": {
"@lang": "eng",
"#text": "Harry Potter"
},
"price": "29.99"
},
{
"title": {
"@lang": "eng",
"#text": "Learning XML"
},
"price": "39.95"
}
]
}
}
数据提取总结
-
HTML、XML
XPath CSS选择器 正则表达式 -
JSON
JSONPath 转化成Python类型进行操作(json类) -
XML
转化成Python类型(xmltodict) XPath CSS选择器 正则表达式 -
其他(js、文本、电话号码、邮箱地址)
正则表达式