我记得大约在半年前,有个朋友问我一个问题,现在有一个选型:
一个性能敏感场景,有一个集合,需要确定某一个元素在不在这个集合中,我是用数组直接
Contains还是使用HashSet<T>.Contains?

大家肯定想都不用想,都选使用HashSet<T>,毕竟HashSet<T>的时间复杂度是O(1),但是后面又附加了一个条件:
这个集合的元素很少,就4-5个。
那这时候就有一些动摇了,只有4-5个元素,是不是用数组Contains或者直接遍历会不会更快一些?当时我也觉得可能元素很少,用数组就够了。
而最近在编写代码时,又遇到了同样的场景,我决定来做一下实验,看看元素很少的情况下,是不是使用数组优于HashSet<T>。
测试
我构建了一个测试,分别尝试在不同的容量下,查找一个元素,使用数组和HashSet的区别,代码如下所示:
[GcForce(true)]
[MemoryDiagnoser]
[Orderer(SummaryOrderPolicy.FastestToSlowest)]
public class BenchHashSet
{
private HashSet<string> _hashSet;
private string[] _strings;
[Params(1,2,4,64,512,1024)]
public int Size { get; set; }
[GlobalSetup]
public void Setup()
{
_strings = Enumerable.Range(0, Size).Select(s => s.ToString()).ToArray();
_hashSet = new HashSet<string>(_strings);
}
[Benchmark(Baseline = true)]
public bool EnumerableContains() => _strings.Contains("8192");
[Benchmark]
public bool HashSetContains() => _hashSet.Contains("8192");
}
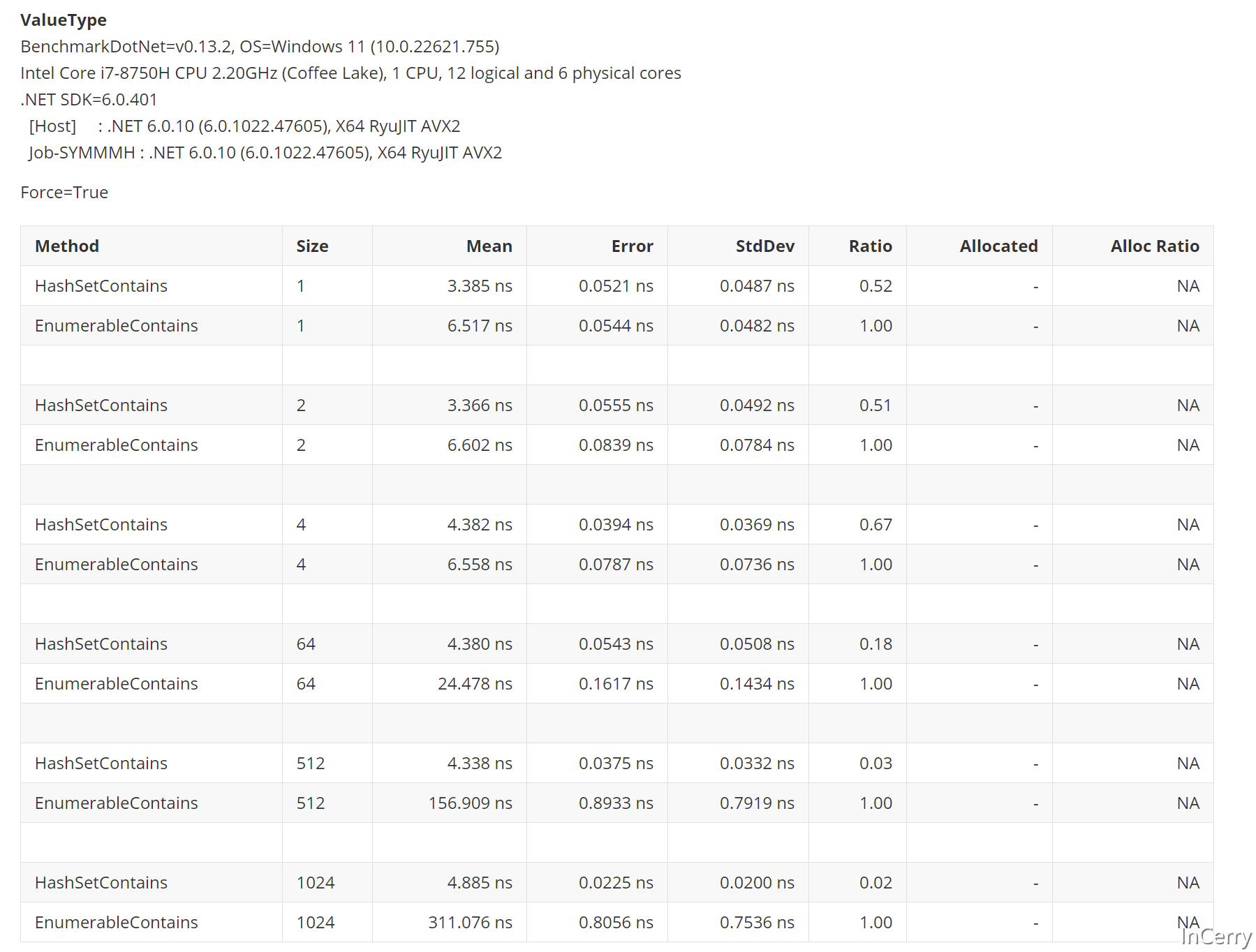
大家猜猜结果怎么样,就算Size只为1,那么HashSet也比数组Contains遍历快40%。

那么故事就这么结束了吗?所以无论如何场景我们都直接无脑使用HashSet就行了吗?大家看滑动条就知道,故事没有这么简单。
刚刚我们是引用类型的比较,那值类型怎么样?结论就是一样的结果,就算只有1个元素也比数组的Contains快。
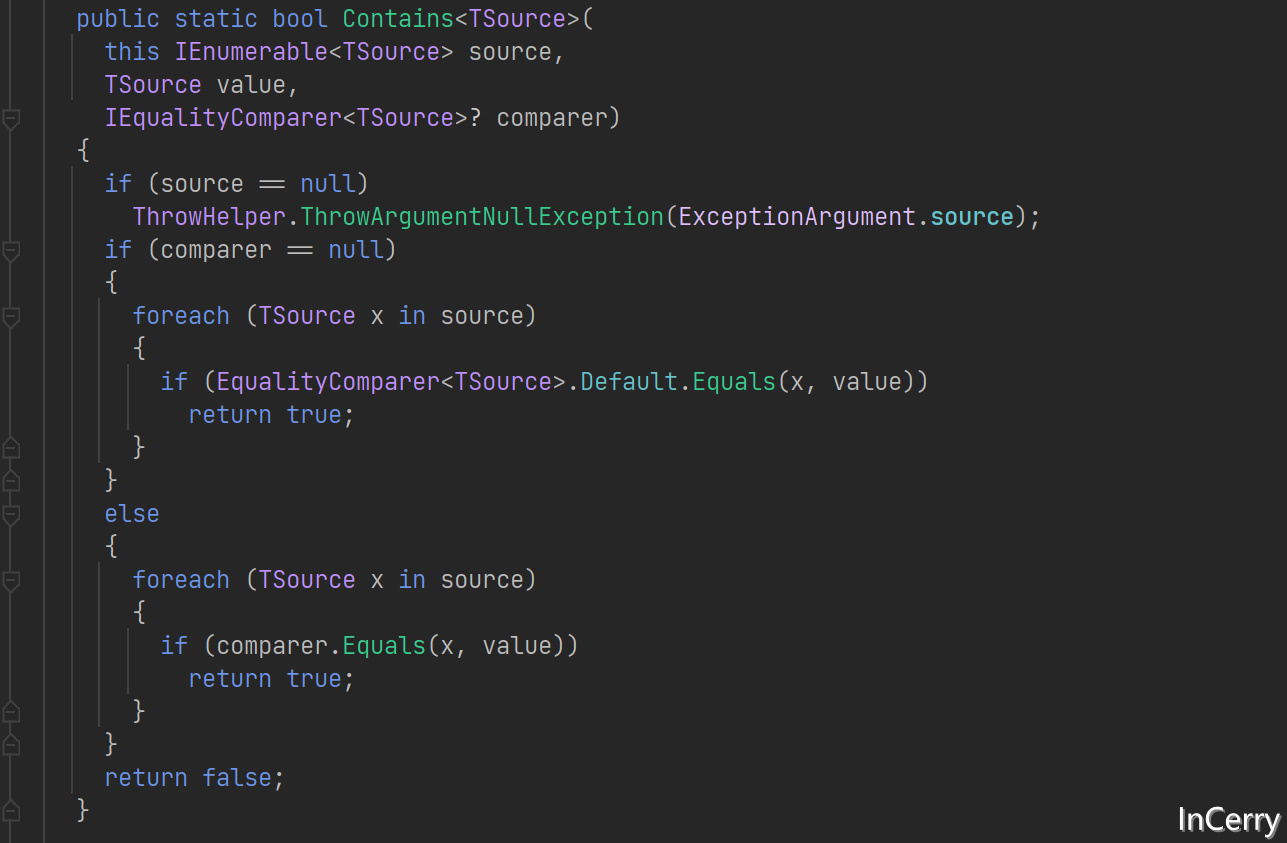
那么问题出在哪里?点进去看一下数组Contains方法的实现就清楚了,这个东西使用的是Enumerable迭代器匹配。
那么我们直接来个原始的,Array.IndexOf匹配和for循环匹配试试,于是有了如下代码:
[GcForce(true)]
[MemoryDiagnoser]
[Orderer(SummaryOrderPolicy.FastestToSlowest)]
public class BenchHashSetValueType
{
private HashSet<int> _hashSet;
private int[] _arrays;
[Params(1,4,16,32,64)]
public int Size { get; set; }
[GlobalSetup]
public void Setup()
{
_arrays = Enumerable.Range(0, Size).ToArray();
_hashSet = new HashSet<int>(_arrays);
}
[Benchmark(Baseline = true)]
public bool EnumerableContains() => _arrays.Contains(42);
[Benchmark]
public bool ArrayContains() => Array.IndexOf(_arrays,42) > -1;
[Benchmark]
public bool ForContains()
{
for (int i = 0; i < _arrays.Length; i++)
{
if (_arrays[i] == 42) return true;
}
return false;
}
[Benchmark]
public bool HashSetContains() => _hashSet.Contains(42);
}
接下来结果就和我们预想的差不多了,在数组元素小的时候,使用原始的for循环比较会快,然后HashSet就变为最快的了,在更多元素的场景中Array.IndexOf会比for更快:
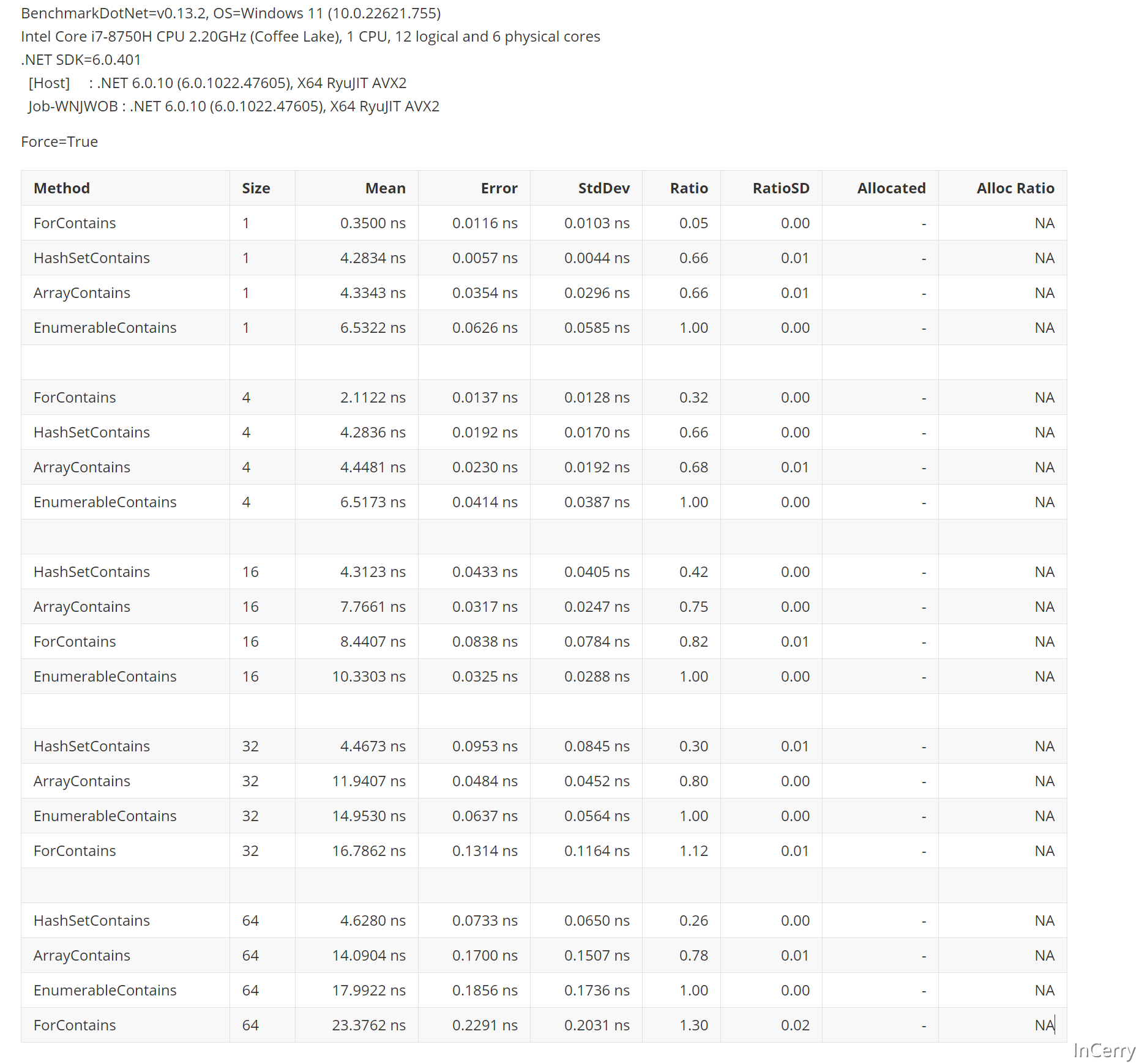
至于为什么在元素多的情况Array.IndexOf会比for更快,那是因为Array.IndexOf底层使用了SIMD来优化,在之前的文章中,我们多次提到了SIMD,这里就不赘述了。
既然如此我们再来确认一下,到底多少个元素以内用for会更快,可以看到16个元素以内,for循环会快于HashSet:
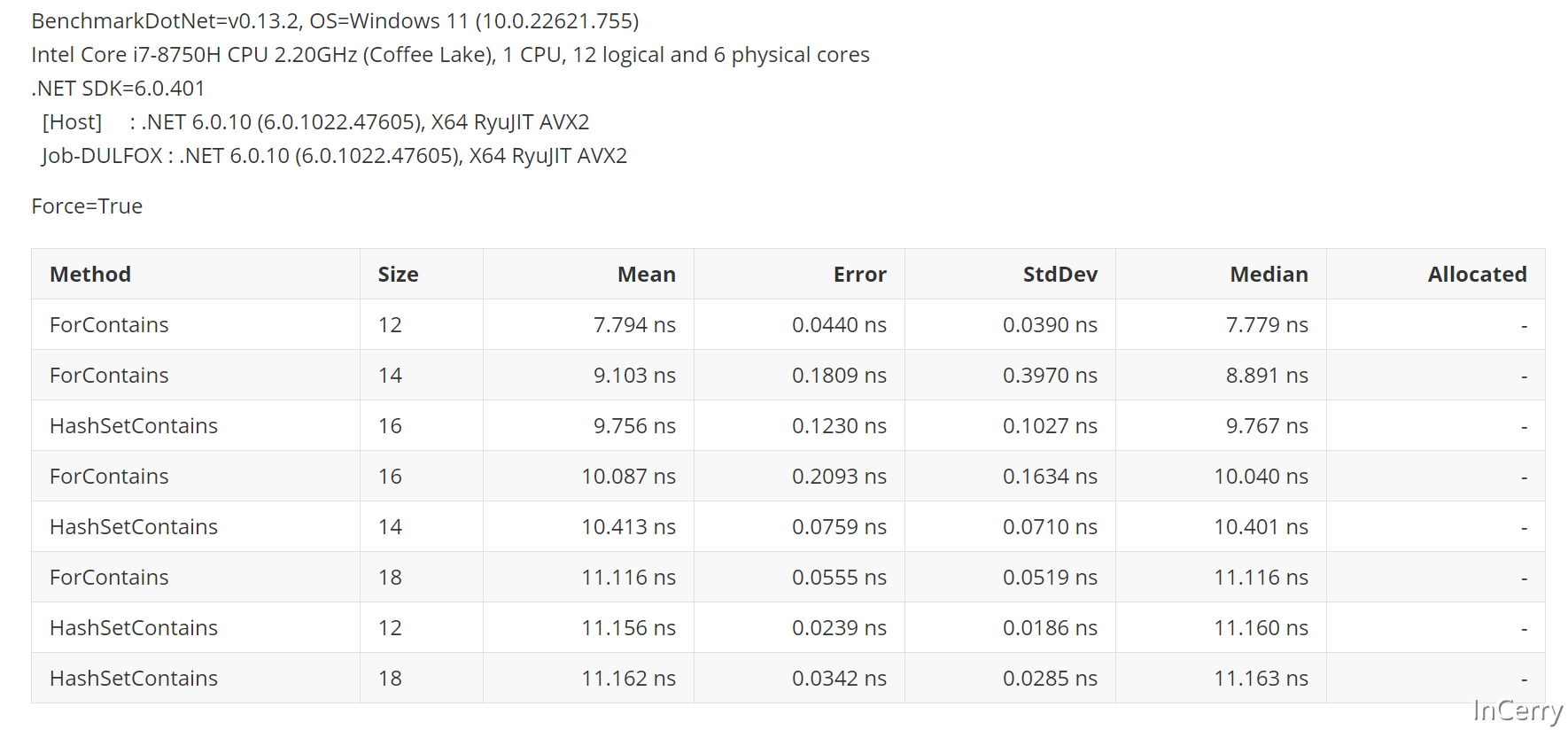
总结
所以我们应该选择HashSet<T>还是数组呢?这个就需要分情况简单的总结一下:
- 在小于16个元素场景,使用
for循环匹配会比较快。 - 16-32个元素的场景,速度最快是
HashSet<T>然后是Array.IndexOf、for、IEnumerable.Contains。 - 大于32个元素的场景,速度最快是
HashSet<T>然后是Array.IndexOf、IEnumerable.Contains、for。
从这个上面来看,大于32个元素就不合适直接用for比较了。不过这些差别都很小,除非是性能非常敏感的场景,可以忽略不计,本文解决了笔者的一些困扰,简单记录一下。