索引
适合建立索引
-
建立索引之后,在B+树中的记录是排序好的,所以频繁使用order by和group的字段可以建立索引,
-
同时唯一性限制的字段也适合建立索引,比如商品编码
-
经常用where查询条件的字段
不适合建立索引
-
频繁修改的字段,为了维护B+树的有序性,需要频繁的重建索引,比如余额
-
表数据太少
-
where,group by,order by中用不到的字段
创建表时的的默认操作
在创建表时,innoDB
-
有主键,默认使用主键作为聚簇索引的key
-
如果没有主键,选择第一个不含NULL的唯一列作为聚簇索引的key
-
上面都没有,自动生成一个隐式自增id列作为聚簇索引的key
其他索引都属于 二级索引和非聚簇索引
创建的主键索引和二级索引默认使用B+树
主键索引
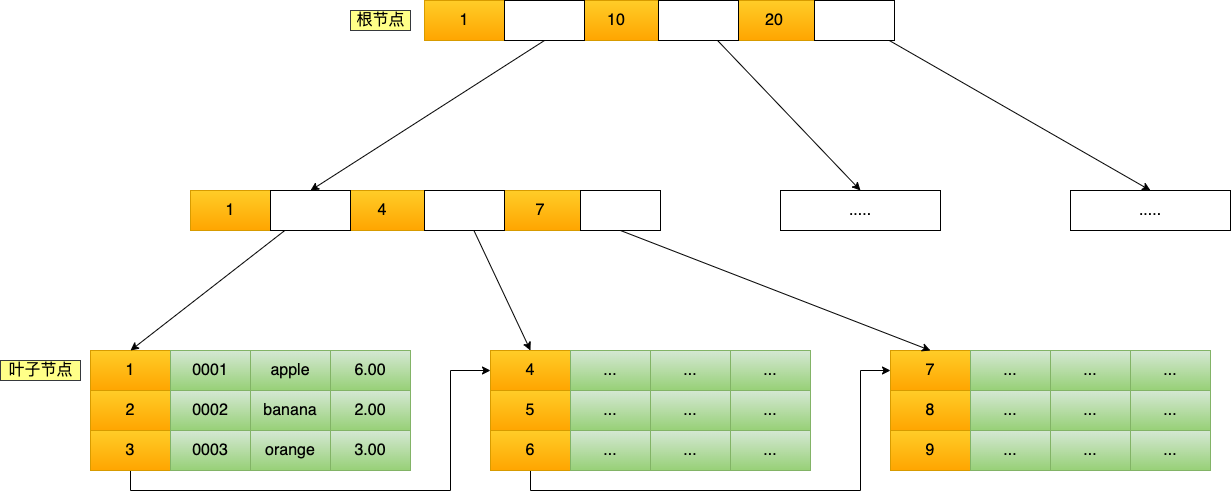
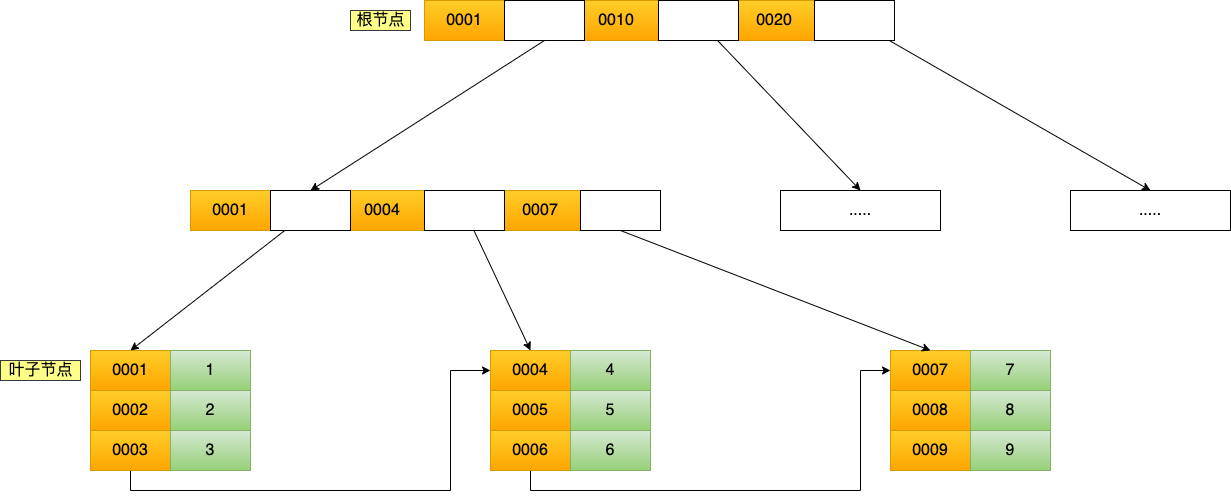
二级索引,叶子节点除了key值,存储的是主键值,通过查询主键,再去查询某行的数据,这个过程叫 回表,也就是说要差两个B+树才能查到数据
B+树和B树的比较
-
B树的非叶子节点也要存储数据,B+树只在叶子节点存储数据,所以B+树的高度更低,一个内部节点可以定位更多的叶子节点
-
b+树的叶子节点是双链表连接,适合MySQL中常见的基于范围查找
-
B+树叶子节点位于同一行,查找时间稳定
索引的分类
-
从数据结构的角度有B+,hash索引,full-text索引
-
从物理存储分类,有聚簇索引(主键索引)和二级索引(辅助索引)
-
从字段特性分类:主键索引(primary key),唯一索引(unique key),普通索引(index),前缀索引(也是index,针对字符类型字段前几个字符建立索 引,目的是为了减少索引占用的存储空间)
-
从字段个数分类:单列索引(如主键索引),联合索引(多个字段组合成一个索引)
索引的优化
-
前缀索引优化
-
使用某个字符串前几个字符建立索引,减小索引大小
-
有一定局限性,order by无法使用前缀索引(索引失效)
-
-
覆盖索引优化
-
主要是避免回表
-
比如要查询商品名称,价格,可以以[id,name,price]作为一个联合索引,查询的时候索引中存在这些数据,查询将不会再次检索主键索引,从而避免回表
-
索引失效
-
like %x或者%xx%这种,不知道从哪个索引值开始比较,所以只能进行全表扫描
-
对索引列做了数据处理(计算,函数,类型转换),索引保存的是索引字段的原始值,而不是表达式计算之后的值,无法查询索引
-
类型转换比如 where phone=130000001(phone是varchar类型)
-
-
联合索引最左匹配(因为联合索引是先排a,a相同的行再排b),下面两种都会失效
-
where a>1 and b>1
-
where b=2
-
-
where子句中or有非索引列字段,因为只要满足就可以查到,所以只查索引是肯定找不齐的,所以要查全表