本文分享自华为云社区《【华为云MySQL技术专栏】InnoDB大对象存储格式解析》,作者: GaussDB 数据库。
1. 背景
在 MySQL 中,大字段是经常使用到的对象,例如:字符类型,包括日志、博客内容以及二进制类型的视频文件等。在 InnoDB 中,大字段也叫大对象(Large Object,简称 LOB),通常认为不会高频全量访问。InnoDB 的数据是按照聚簇索引进行组织的,当聚簇索引的数据行中存在大对象时,InnoDB 为了提升聚簇索引 B+ 树中数据行的访问效率,会对数据行中大对象的存储格式进行优化。
本文将基于 MySQL 8.0.38 的代码,介绍 InnoDB 的 DYNAMIC 行格式中 LOB 的存储格式。
2. 大对象的存储形式
在 InnoDB 中,大对象的存储形式主要有两种:
1) 内联存储在 InnoDB 聚簇索引的行记录中;
2) 以链表的形式存在溢出页中,同时,根据不同的 LOB 大小,链表的格式也有差异。
2.1 大对象溢出页存储的条件
在 InnoDB 中,以 16KB 大小的页面为例,为了保证每个数据页面中至少有两条记录,每条记录的长度不能超过 8126 个字节。如果超过了,就需要对记录中的某些符合条件的字段采用溢出页(即数据并不是存储在聚簇索引中)的形式进行存储,这个判断过程如下:
步骤 1,若主键记录的物理长度大于 8126 个字节,则顺序遍历主键记录中的每一个字段;
步骤 2,接着找到一个新的、最长的且没有在溢出页的字段 (主要判断字段类型,例如:VARCHAR, TEXT 等),同时,能够满足以下条件的字段且不会存放在溢出页中:
a) 字段是固定长度;
b) 字段为 NULL;
c) 字段的长度小于等于 40 个字节;
d) 字段为非大对象类型。例如,VARCHAR 类型,且长度小于或者等于 255。
步骤 3,对满足条件的字段进行溢出页存储,存储后该字段在聚簇索引行记录中的长度更新为 20;
步骤 4,反之再次进入步骤 1,直到步骤 1 中的条件不满足或者步骤 2 中无法找到可存储到溢出页的字段。
以上过程在 InnoDB 中对应的核心函数 dtuple_convert_big_rec 如下:
big_rec_t *dtuple_convert_big_rec(dict_index_t *index, upd_t *upd,
dtuple_t *entry) {
...
while (page_zip_rec_needs_ext(
rec_get_converted_size(index, entry), dict_table_is_comp(index->table),
dict_index_get_n_fields(index), dict_table_page_size(index->table))) {
...
for (ulint i = dict_index_get_n_unique_in_tree(index);
i < dtuple_get_n_fields(entry); i++) {
ulint savings;
dfield = dtuple_get_nth_field(entry, i);
ifield = index->get_field(i);
/* Skip fixed-length, NULL, externally stored,
or short columns */
if (ifield->fixed_len || dfield_is_null(dfield) ||
dfield_is_ext(dfield) || dfield_get_len(dfield) <= local_len ||
dfield_get_len(dfield) <= BTR_EXTERN_LOCAL_STORED_MAX_SIZE) {
goto skip_field;
}
savings = dfield_get_len(dfield) - local_len;
/* Check that there would be savings */
if (longest >= savings) {
goto skip_field;
}
/* In DYNAMIC format, store locally any non-BLOB columns whose maximum length does not exceed 256 bytes.*/
if (!DATA_BIG_COL(ifield->col)) {
goto skip_field;
}
longest_i = i;
longest = savings;
skip_field:
continue;
}
/* 将longest_i对应的字段进行溢出页存储. */
...
}
2.2 大对象溢出页存储示例
示例 1:存在表 t1,其定义如下:
CREATE TABLE `t1` (
`a` int DEFAULT NULL,
`b` blob,
`c` blob,
`d` blob
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
CASE 1:
insert into t1 values(1,repeat('a',32768),repeat('a',8000),repeat('a',32768));b,d 字段会被存储到溢出页中,c 字段虽然有 8000 个字节,但因 b,d 字段优先被溢出页存储,因此,c 字段不会被溢出页存储。
CASE 2:
insert into t1 values(1,repeat('a',7000),repeat('a',8000),repeat('a',7000));b,c 字段会被存储到溢出页中,d 字段不会被溢出页存储。过程是这样的:首先,选择 c 进行溢出页存储,存储完毕后 c 字段长度变成 20,然后选择 b 字段进行溢出页存储,完毕后 b 字段长度为 20,d 字段保留在主键记录中。
示例 2:存在表 t1,其包括一个 INT 列和 32 个 VARCHAR (256) 类型的列。当向该表中插入一个满行(每个列的值都达到字段定义的长度)记录时,此时所有 VARCHAR 类型的字段总长度为 8192,但是如果一个字段被溢出页存储后,则总长度小于 8126。因此,该记录中第一个 VARCHAR (256) 的列会被溢出页存储,其他的字段都不会被溢出页存储。
从上述分析以及示例中可以看到,定义为大字段 (BLOB, TEXT 等)类型列的数据不一定会被溢出成底层的大对象存储,定义为 VARCHAR 类型的列的数据也可能会被缓存,这主要取决于行以及某些字段大小是否符合上述 InnoDB 的约束。
3. 大对象溢出页存储格式
3.1 大对象引用字段 (LOB reference,简称 LOB ref)
在主键记录中,当某字段被溢出页存储时,则在该字段中不会存储真正的数据,而是会写入大对象的引用,InnoDB 可以通过该大对象引用字段找到数据存储的真实位置。
LOB ref 有 20 个字节大小,其包含的内容如下:


图 1:LOB ref 结构
-
space_id (4):标识溢出页所属的表空间;
-
page_no (4):标识溢出页第一个页面的 page no;
-
version (4):标识当前 LOB 字段值的版本号,从 1 开始累加,主要用于 LOB 的多版本读,后续文章再详细介绍该字段的使用场景;
-
info bits:一些标识信息,一共 4 个字节,目前只用了 3 个 bit,主要是用于 LOB 的更新,包括:
a) BTR_EXTERN_OWNER_FLAG (128UL):标识该列的数据是否 “真正” 拥有溢出页,例如:在 InnoDB 中,一些 UPDATE 操作会被转换成 DELETE + INSERT,即先将旧的行记录打上 “删除” 的标签,然后插入新的行记录,如果这个 UPDATE 不涉及大对象的修改,那么我们可以让新行记录 “继承” 旧行记录的溢出页存储内容,这样一来,旧行记录将不再保留溢出页,即便该行依然拥有 LOB ref。在 Purge 的时候,被标记为 “删除” 的旧行指向的溢出页数据也不会被清理,后续文章会详细介绍该字段的使用;
b) BTR_EXTERN_INHERITED_FLAG (64UL):标识该列的数据溢出页内容,是否 “继承” 自其它行,如果是 “继承” 自其它行,则在回滚的时候不需要真正清理数据;
c) BTR_EXTERN_BEING_MODIFIED_FLAG (32UL):标识该字段是否正在被修改,这个主要用于 READ UNCOMMITED 隔离级别时防止读到中间状态的 LOB 内容;
- len:标识 LOB 对象的总长度。
LOB ref 的初始值如下:
/** A BLOB field reference has all the bits set to zero, except the "being
* modified" bit. */
const byte field_ref_almost_zero[FIELD_REF_SIZE] = {
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0x20, 0, 0, 0, 0, 0, 0, 0,
};
0x20 对应 32UL,表示该 LOB 正在被修改。
3.2 溢出页
在 InnoDB 8.0 中溢出页的格式主要包括两种,如果记录的总长度小于 2 个页面的长度,那么只需要链表即可 (这种场景比较简单,本文不介绍)。否则,InnoDB 会使用更复杂的数据结构来对 LOB 的内容进行组织,用于实现 LOB 的高效更新以及多版本查询,如下图 2 所示:

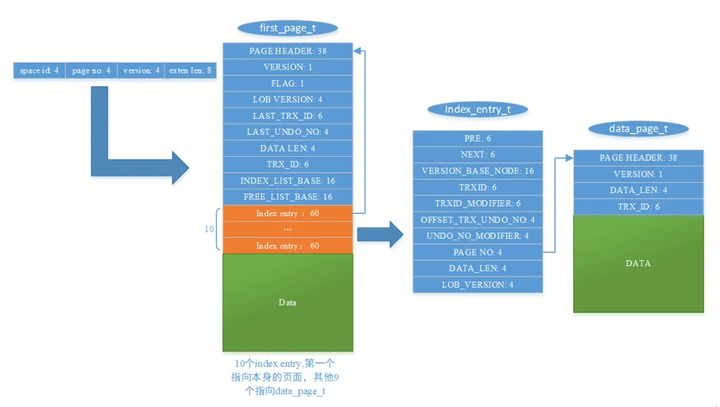
图 2:InnoDB 溢出页存储格式
在这种场景中,我们称溢出页的第一个页面为 first page (对应数据结构 first_page_t);其他的数据页面被称为 data page (对应数据结构 data_page_t),管理 data page 的页面被称为 index page (对应数据结构 node_page_t),其主要是通过 index entry 这种结构进行管理。
3.2.1 first page
first page 同正常的 InnoDB 数据页面一样,从 FIL_PAGE_DATA (38) 个字节开始写 first page 的真实内容,first page 除了存放真实数据以外,主要包括以下两部分内容:
1)对该页面数据的描述信息 (固定长度:58 个字节)
first page 的页面描述信息主要包括如下字段:
VERSION: 1 个字节,当前 LOB 格式的版本号,当前是 0;
FLAG: 1 个字节,但是目前只有一个 bit 位有使用,标记该字段是否允许 partial update,后续会详细介绍 JSON 的 partial update;
LOB VERSION: 4 个字节,当前页面数据的版本号,从 1 开始累加,和 blob ref 的 version 字段的作用类似;
LAST TRXID: 6 个字节,最后一次修改这个页面数据的事务 id;
LAST UNDO NO: 4 个字节,最后一次修改这个页面数据的事务 id 的 undo no;
DATA_LEN: 4 个字节,描述当前页面写入的数据长度;
TRX_ID: 6 个字节,创建该页面的事务 id,对应于 insert 或者非 partial update 操作;
INDEX_LIST:16 个字节,存放有正在使用数据页面的管理节点链表的首地址;
FREE_LIST_NODES:16 个字节,存放所有未使用的管理节点链接的首地址;
2)index entry 数组
在 first page 中一共有 10 个 index entry,其中第一个 index entry 指向自身,其他 9 个指向 9 个其他的数据页面 (假定数据足够大,需要使用 10 个以上的页面进行存储)。
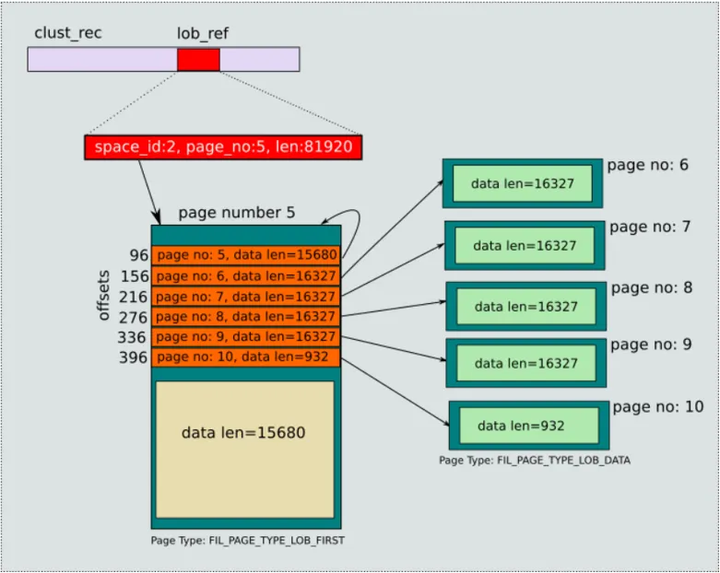
图 3:LOB 存储示例

图片来源:https://dev.mysql.com/blog-archive/mysql-8-0-innodb-introduces-lob-index-for-faster-updates/
如图 3 所示,如果一个 LOB 字段的内容长度为 81920,需要 6 个页面存储数据,每个数据页面均有一个 index entry 进行管理。因此,在 first page 中会有 6 个正在使用的 index entry。
第一个 index entry 指向 page 5,即 first page 本身,长度为 15680 个字节,故在 first page 中,除去 10 个 index entry 的空间,其他的 15680 个字节也可以存储数据。第二个到第五个 index entry 分别指向 page 6, 7, 8, 9,将这些 page 依次全部装满(16327 个字节)。第六个 index entry 指向 page 10,存储剩下的 932 个字节。first page 并不知道 data page 的位置,需要通过 index entry 进行遍历。
所有管理 data page 的 index entry 会通过双向链表串起来,其首地址存放在 first page 中 LOB_INDEX_LIST 中,所有空闲(即不存在 data page)的 index entry 也会通过双向链表串联起来,其首地址存放在 first page 的 LOB_INDEX_FREE_NODES。
index entry 主要包括以下字段:
PREV:6 个字节,前一个 index_entry 的表空间地址;
NEXT: 6 个字节,后一个 index_entry 的表空间地址;
VERSION: 16 个字节,当前页面的版本链双向链表,用于 LOB 的 MVCC,后续文章中介绍 partial update 操作会详细描述该字段;
TRXID:6 个字节,创建该 index entry 的事务 id;
TRX_UNDO_NO:4 个字节,创建该 index entry 的事务的 undo no;
TRXID_MODIFIER:6 个字节,修改该 index entry 的事务 id;
TRX_UNDO_NO_MODIFIER:4 个字节,修改该 index entry 的事务的 undo no;
PAGE_NO:4 个字节,该 index entry 对应的 data page 的 page no;
DATA_LEN: 4 个字节,该 index entry 对应的 data page 的数据长度;
LOB_VERSION:4 个字节,该 index entry 以及 data page 的版本,从 1 开始累加,LOB 的多版本的版本号指的就是这个。
TRXID 与 TRXID_MODIFIER 的使用和 LOB 的 update 有关系后续详细介绍。
3.2.2 data page 以及 index page
- data page
如上所述,每个 index entry 管理着一个 data page,data page 主要作用就是存储真实数据,除此之外,其页面内容前 11 个字节还存储以下 3 个字段:
VERSION:1 个字节长度,存储当前 data page 格式的版本号。当前是 0,为未来扩展 data page 的格式使用;
DATA_LEN:4 个字节长度,当前页面数据部分的长度;
TRX_ID:6 个字节长度,标识修改以及创建该页面的事务 id;
- index page
当 LOB 字段的长度超过 10 个页面时,first page 的 10 个 index entry 就不够用了,此时会新分配一个新的页面,该页面中的所有内容被划分为 index entry 来使用,如下图 4 所示:

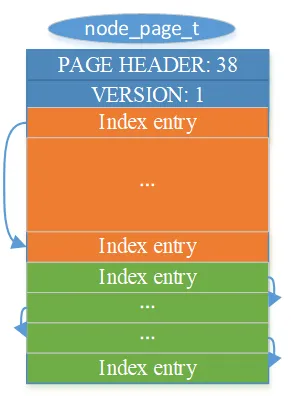
图 4 index page 格式
index page 只有一个额外的字段 VERSION,标识当前页面格式的版本。图 4 中红色的 index entry 表示已经被使用的,绿色的表示尚未使用的。
3.2.3 小结
溢出页作为 InnoDB 大对象的复杂存储机制,其 first page 是大对象访问的入口,通过其内部的 index entry 以及关联的 index page 来快速访问、更新存储数据的 data page。除此之外,为优化小数据量溢出的快速访问,first page 自身也保存 10 个 index entry,同时也能存小部分数据。
4. 总结
本文介绍了 InnoDB 大对象的存储格式,包括 InnoDB 会将数据行中的字段按照大对象格式进行存储的场景,InnoDB 大对象溢出页存储常见存储格式,并详细介绍了 InnoDB 对大对象的常见组织管理方式。后续文章中将结合 InnoDB 的大对象的存储格式,介绍大对象更新和查询方式。
标签:LOB,index,存储,entry,字节,InnoDB,MySQL,格式,page From: https://www.cnblogs.com/huaweiyun/p/18418091