目录
参考:
近似LRU(NearlyLRU):一种基于随机采样的缓存淘汰策略
1.Redis过期时间淘汰策略
为了避免内存不够用,所以Redis提供了这种key自动过期的方案。
过期时间淘汰策略(TTL,即Time To Live)是另一种缓存管理机制,用于自动移除那些已经达到过期时间的键。
Redis允许对每个键设置一个过期时间,当键的过期时间到达后,Redis会自动删除该键以释放内存。
常见设置过期时间的命令
# 设置过期时间:EXPIRE key seconds
EXPIRE mykey 60 # 设置 mykey 的过期时间为60秒
EXPIRE mykey 120 # 重新设置 mykey 的过期时间为 120 秒(覆盖)
# 同时设置过期时间和值:SETEX key seconds value(原子操作)
SETEX mykey 60 "value" # 过期时间为60s,值为"value"
那么,既然部分key存在过期时间,怎么删除掉这些过期的key呢?
| 方法 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| 惰性删除(Lazy Deletion) | 每当访问一个键时,检查该键是否已过期,过期则删除 | 仅在访问时检查和删除键,不增加系统额外开销 | 低访问频率的键可能未及时删除,占用内存 |
| 定期删除(Periodic Deletion) | 后台线程定期随机检查部分键并删除已过期的键 | 在不影响性能的情况下逐步清理过期键 | 大量键检查时可能对性能产生一定影响 |
| 主动过期扫描(Active Expiration Scanning) | 每次命令执行时额外进行部分过期键检查,动态调整频率和数量 | 确保在高负载情况下也能清理过期键 | 需要动态调整以适应系统负载 |
1.1 惰性删除
惰性删除策略是在每次访问一个键时,Redis会检查该键是否已过期。如果键已过期,Redis会立即删除它并返回nil或相应的错误。
-
优点:
- 资源效率高:只有在访问键时才进行检查和删除操作,不会增加系统额外的计算和内存开销。
- 简单直接:实现简单,逻辑清晰。
-
缺点:
- 低访问频率问题:对于很少访问的键,可能会存在过期键未被及时删除的问题,这些键会继续占用内存资源。
示例
SET mykey "value" EX 60 # 设置 mykey 的过期时间为 60 秒
GET mykey # 如果在60秒后访问,mykey 已过期,将返回 nil 并删除该键
1.2 定期删除
定期删除策略是由Redis后台线程定期随机检查一部分设置了过期时间的键,并删除那些已过期的键。
默认情况下,Redis每秒会进行10次检查,每次随机抽取一定数量的键进行过期检查和删除。
- 优点:
- 平衡负载:在不影响整体性能的情况下,逐步清理过期键。
- 自动化:后台线程定期执行,无需人工干预。
- 缺点:
- 性能影响:当需要检查的键数量较多时,可能对系统性能产生一定的影响。
实例
Redis的配置文件redis.conf中可以调整hz参数来控制定期删除操作的频率:
# 默认每秒进行10次检查
hz 10
好,这里的定期就有点东西了。如果我们自己搞,有2个主要的问题点。
- 定期,这个定期到底定多久?
- 删除,key那么多,遍历删,不要命啦?
1.3 主动扫描
主动过期扫描策略是在每次命令执行时,Redis会额外进行一部分过期键检查。
这种策略会根据系统负载动态调整检查频率和数量,以适应当前的负载情况。
通过这种方式,即使在高负载情况下,Redis也能及时清理过期键。
-
优点:
- 高效清理:确保在高负载情况下,也能有效清理过期键,维持系统性能。
- 动态调整:能够根据系统当前的负载情况,动态调整检查频率和数量,优化资源使用。
-
缺点:
- 复杂性:实现和配置较为复杂,需要根据具体负载情况进行调优。
2.Redis内存淘汰策略
内存实在是不够用了咋整?
Redis的淘汰策略(Eviction Policy)是当内存达到限制时,用于决定如何移除旧数据以腾出空间给新数据的方法。
官网说明:Redis Key Eviction
先来学习几个关键字:
- allkeys:表示所有键都可能被移除,无论它们是否设置了过期时间。这种策略适用于所有键。
- volatile:表示仅在设置了过期时间的键中选择移除。这种策略只会影响那些设置了TTL(过期时间)的键。
- Recently:adv.最近;新近;近来
- Frequently:adv.频繁地;经常地;时常
- LRU(Least Recently Used):最近最少使用策略,移除最近最少被访问的键。适用于缓存系统,确保频繁访问的数据保留。
- LFU(Least Frequently Used):最不经常使用策略,移除访问频率最低的键。适用于需要根据使用频率决定数据保留的场景。
- idle time:空闲时间
| 策略 | 描述 |
|---|---|
| noeviction | 内存达到限制时,不再保存新值,返回错误。 |
| allkeys-lru | 移除最近最少使用的键(LRU),保留最近使用的键。 |
| allkeys-lfu | 移除使用频率最低的键(LFU),保留频繁使用的键。 |
| volatile-lru | 在设置了过期时间的键中使用LRU策略移除。 |
| volatile-lfu | 在设置了过期时间的键中使用LFU策略移除。 |
| allkeys-random | 随机移除任意键。 |
| volatile-random | 随机移除设置了过期时间的键。 |
| volatile-ttl | 移除设置了过期时间的键中剩余生存时间最短的键。 |
额,这个表格怎么记忆。
首先,我们有拒绝写策略noeviction。然后有,移除最短ttl的。
接着,针对allkeys、volatile两个大类,我们都有lru、lfu以及random三种策略。
2.1最大内存配置
# redis.conf 中的示例
maxmemory 100mb
或者命令行操作
# 使用命令行设置
CONFIG SET maxmemory 100mb
默认值为0,表示没有内存限制:
- 64位系统:理论上没有设置内存限制。
- 32位系统:隐式内存限制为3 GB。
额,那为啥32位系统要说个隐式的3GB呢。
4 GB的限制源于32位系统的地址空间设计。
32位系统的内存地址由32个比特(位)表示,因此可以表示的地址总数是2的32次方,也就是4,294,967,296个字节,即4 GB。
- 地址空间:32位系统的地址空间总共4 GB。
- 内核空间:操作系统内核会保留一部分地址空间(通常是1 GB),供系统使用。
- 用户空间:剩下的3 GB地址空间供用户进程使用。
由于这部分限制,32位Redis实例实际上只能利用约3 GB的内存。
哈哈,那64咋就没说隐式多少G?我们看下2^64,换算下大概是17179869184GB,也就一百多亿吧。
2^64 = 18,446,744,073,709,551,616
64位真猛啊,真猛啊。
2.2 LRU 最近最少使用
Least Recently Used
如果一个数据在最近一段时间没有被访问到,那么在将来它被访问的可能性也很低。
嗯,反过来,如果一个key
例如下图这样:
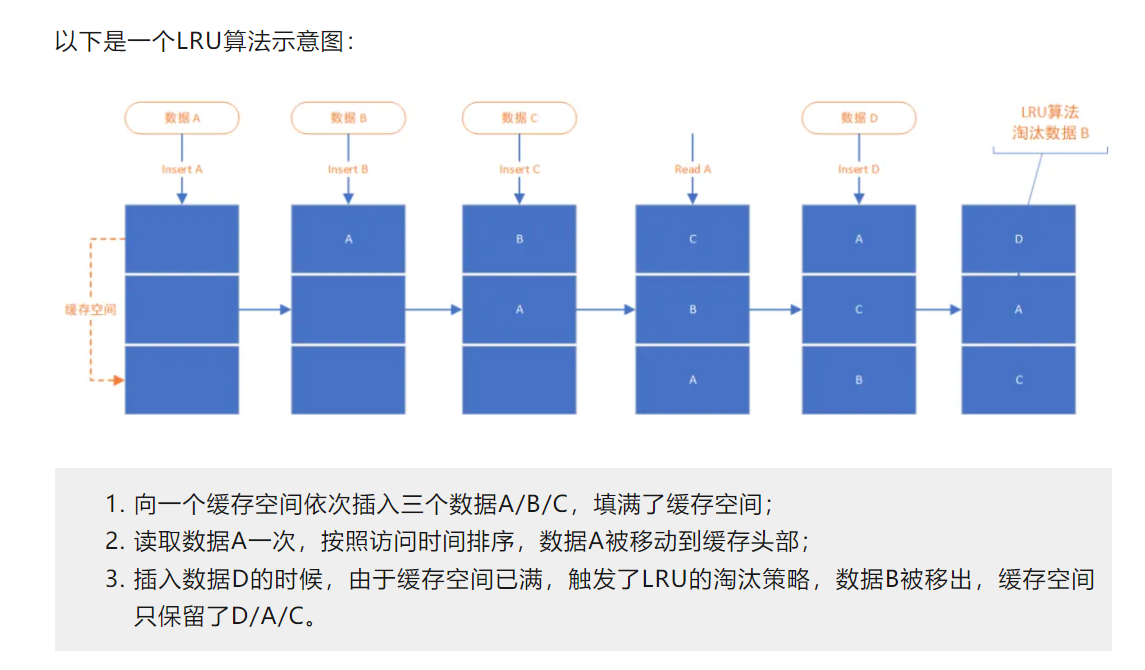
LRU 的核心就是将 keys 按照“最近一次被访问”的时间排序。
哇,排序,那用什么数据结构,咱又不懂。
不过,咱也有笨办法,不一定非得对时间排序。
简单一点,直接不记录时间,一个链表把数据串起来,每次访问到就移动到头节点,淘汰的时候直接选最尾端的淘汰。
2.2.1 传统LRU
一般而言,LRU算法的数据结构不会仅使用简单的队列或链表去缓存数据,而是会采用Hash表 + 双向链表的结构。
利用Hash表确保数据查找的时间复杂度是O(1),双向链表又可以使数据插入/删除等操作也是O(1)。
哇靠,哇靠,这里要注意!这里就是经验。
首先,我们容易知道,链表的查找是O(N),得走节点上一个个查下去才能找到元素。但是插入和删除很快,O(1)的,关键在于找到元素。
那么,有没有办法优化这个查找的O(N)?
可以在之前加上一层hash表,key是数据,value是地址。
我们再捋捋这种场景下的LRU
假设现在我要把节点A提前,按照前面我们的笨办法,我们链表一把梭时,得O(N)先找到A。
现在,我们有了hash表,直接hash一手,立马就有地址。
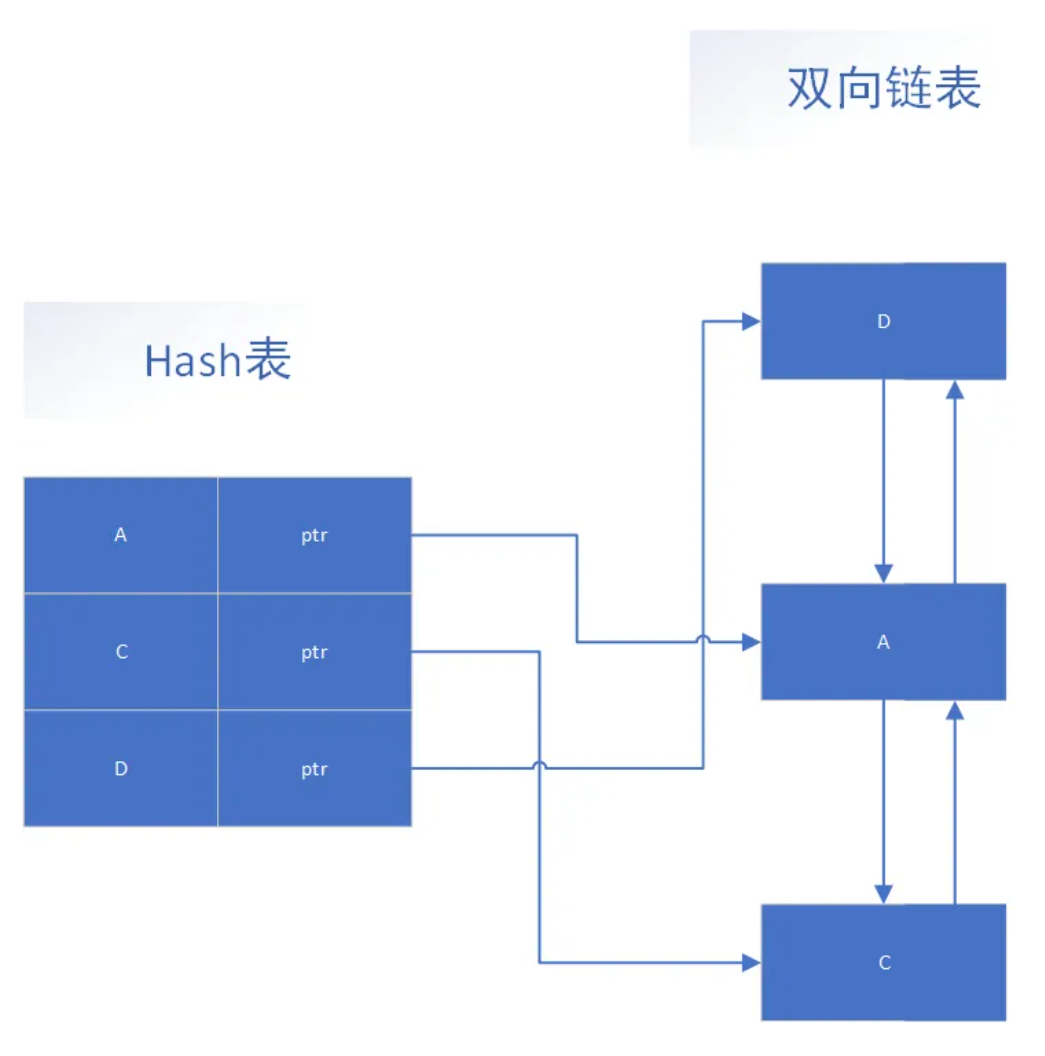
2.2.2 Redis中的LRU
Redis内部只使用Hash表缓存了数据,并没有创建一个专门针对LRU算法的双向链表。
就是没有按我们前文的思路,查一次数据,我就给你改到某个链表头上这种操作。
为啥呢,根据网上的意思,就是作者觉得这个Object类已经很好了,够用了,特意精简成这样。
嗯,大哥的意思就是,咱难不成在Object类中加两个前后指针的字段,这是浪费内存。
那它的lru怎么处理的,关注Object类中的lru:LRU_BITS这个字段。
typedef struct redisObject {
// type: 数据类型,占4位。
unsigned type:4;
// encoding: 编码方式,占4位。
unsigned encoding:4;
// LRU时间或LFU数据,占24位。
// LRU: 相对于全局lru_clock的时间。
// LFU: 最低8位为访问频率,最高16位为访问时间。
unsigned lru:LRU_BITS;
// refcount: 引用计数。
int refcount;
// ptr: 指向实际数据的指针。
void *ptr;
} robj;
lru字段解释:
-
LRU:当使用LRU策略时,
lru字段存储的是相对于全局LRU时钟的时间戳。 -
LFU:当使用LFU策略时,
lru字段的最低8位表示访问频率,最高16位表示访问时间。
好,注意,这里的24位时间戳,实际上不是时间戳,而是相对于Redis服务器全局时钟的偏移量。
好咯,反正主要关注的是最近用的,咱们的时钟偏移当成最近一次被访问时间也没问题的。
24位可以表示的范围是0到16,777,215,单位为s的时候,大概是194.18天,淘汰的场景够用了。
扯半天还是没说咋用的啊,没使用“提到链表头的操作”,咋实现待淘汰key的选择?
Redis的近似LRU算法:
Redis采用了一种近似算法,通过随机采样来达到效果。在保证性能的同时,接近真实的 LRU 行为。
好好好,又开始玄学了,采样都来了?
先看下具体的过程。
-
候选池:维护一个固定大小的候选池(例如 16 个键),用于存储最久未访问的键。
-
随机采样:每次随机抽取 N 个键(例如 5 个),检查它们的访问时间。
-
挑选最差的键:在这 N 个键中,选择最近一次访问时间最久远的键作为淘汰候选。
-
更新候选池:如果候选池未满,将键A直接放入池中。如果候选池已满,替换更差的键。
每次样本的数量可以在conf中调整,默认值是5。作者说5是在性能和准确性上权衡的值。
# 配置文件
maxmemory-samples 5
# 命令行
CONFIG SET MaxMemory-Samples<count>
大哥在官网放了图,说你看是差不多的(左上角是原始结果)。

什么,内存和效率你占完了,都让大哥美上了。问题是,我懵了啊,这啥玩意采样法?
这里我还没误到,根据各种数据看起来,在精度要求不高的情况下,它确实是个好的选择。
2.2.3 LRU的缺点
LRU算法仅关注数据的访问时间或访问顺序,忽略了访问次数的价值,在淘汰数据过程中可能会淘汰掉热点数据。
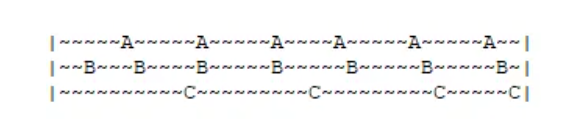
例如,这张图中,显示了某时间段内数据A、B、C的访问情况。
根据LRU的思想,关注时间,热点数据为:C>B>A
但是,结合实际角度来看,明显应该是B和A访问很频繁,即:B>A>C
基于这种问题,衍生除了LFU,通过频率来度量热点key。
2.3 访问频率最低
如果一个数据在近期被高频率地访问,那么在将来它被再访问的概率也会很高,而访问频率较低的数据将来很大概率不会再使用。
看6.3.2节,似乎数出现的次数就好了呀,实际上,咱们不能这样认为。
频率=次数/单位时间,在时间相同的情况下,是可以简单的数次数。
但是,咱们这个单位时间是不好把控的。
一年前,你爱打王者,最近两天玩了十来把第五人格,看似你已转战第五人格。其实我知道,你还是心心念念着王者。
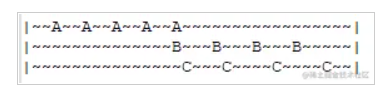
像这张图,A、B、C分别出现了5、4、4,但是如果考虑到时间,C和B离咱们更近,其实A、B、C三者的热点排序,不太好评估。
又例如:
假设有两个数据项A和B:
- 数据项A:过去的访问频率为100次,最近一次访问时间较早。
- 数据项B:过去的访问频率为2次,但最近一次访问时间较晚。
在LFU算法下,数据项B会被优先淘汰,因为它的访问频率低,即使最近一次访问时间较晚。
因此,LFU算法一般都会有一个时间衰减函数参与热度值的计算,兼顾访问时间的影响。
2.3.1 传统LFU
传统LFU算法实现的数据结构与LRU一样,也采用Hash表 + 双向链表的结构,数据在双向链表内按照热度值排序。
如果某个数据被访问,更新热度值之重新插入到链表合适的位置。
2.3.2 Redis的LFU
注意啊,这里是有历史的,咱们Redis是先有LRU,在4.0后引入了LFU。
Redis的LFU算法的实现,同样没有使用额外的数据结构,而是复用了redisObject数据结构的lru字段,把这24bit空间拆分成两部分去使用。
- 高16位:访问时间
- 低8位:访问频率
这里有2个注意点:
- 由于记录时间戳在空间被压缩到16bit,所以LFU改成以分钟为单位,大概45.5天会出现数值折返,比LRU时钟周期短。
- 低位的8bit用来记录热度值(counter),8bit空间最大值为255,直接用来记录该数据的访问总次数是明显不够用的。
看下Redis中热度值怎么计算的。
2.3.2.1 时间衰减函数
前面提到,这个热度值是跟时间有关系的。
Redis中LFUDecrAndReturn 函数用于根据时间衰减一个热度值
counter。
unsigned long LFUDecrAndReturn(robj *o) {
unsigned long ldt = o->lru >> 8;
unsigned long counter = o->lru & 255;
unsigned long num_periods = server.lfu_decay_time ? LFUTimeElapsed(ldt) / server.lfu_decay_time : 0;
if (num_periods)
counter = (num_periods > counter) ? 0 : counter - num_periods;
return counter;
}
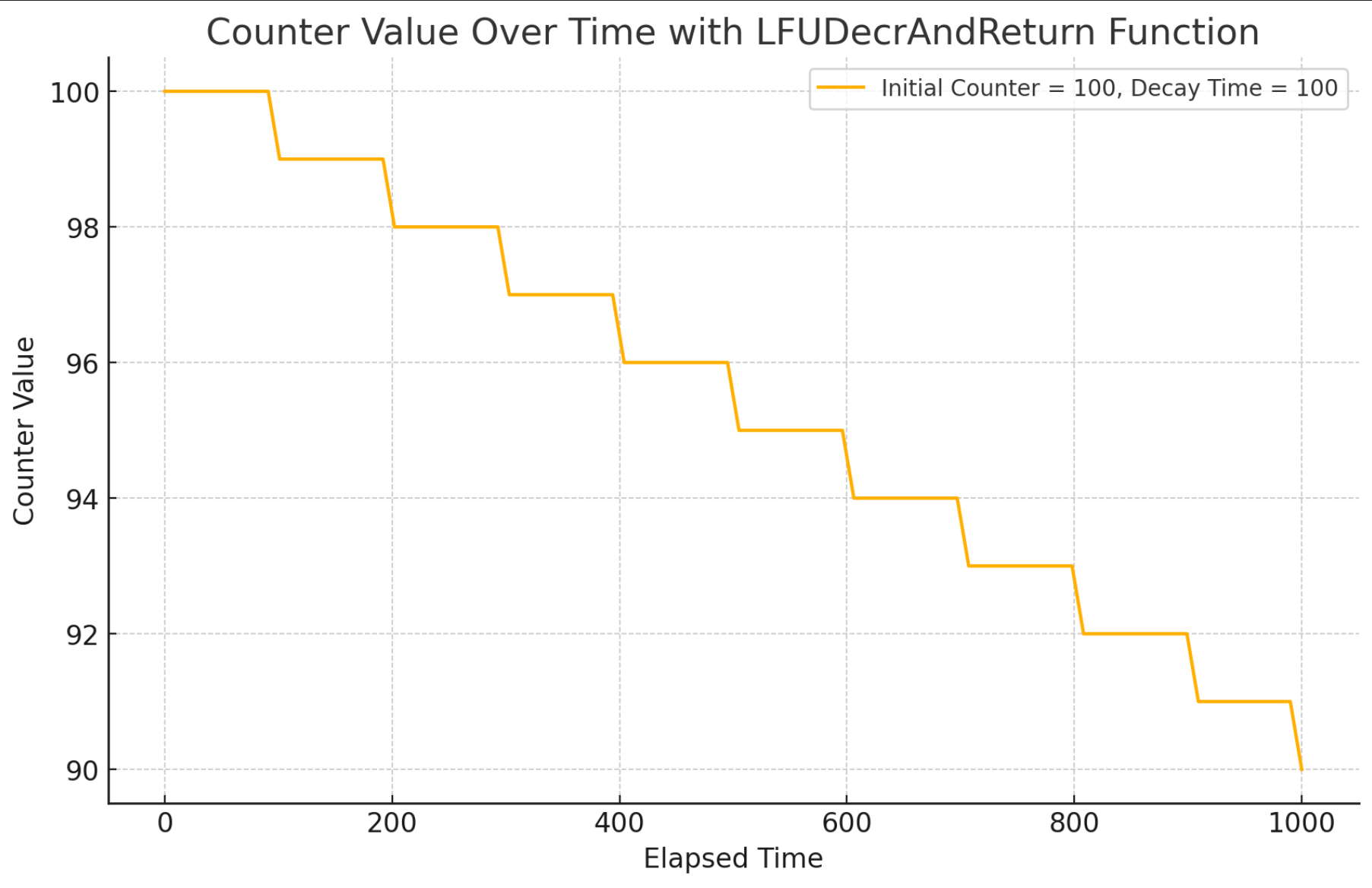
python绘图代码
import matplotlib.pyplot as plt
# Define the LFUDecrAndReturn function in a more general form for plotting
def lfu_decrement(counter, elapsed_time, lfu_decay_time):
num_periods = elapsed_time // lfu_decay_time if lfu_decay_time else 0
if num_periods:
counter = 0 if num_periods > counter else counter - num_periods
return counter
# Example parameters for the plot
lfu_decay_time = 100 # Example decay time
initial_counter = 100 # Example initial counter value
time_values = np.linspace(0, 1000, 100) # Time from 0 to 1000 in 100 steps
# Calculate the counter values over time
counter_values = [lfu_decrement(initial_counter, t, lfu_decay_time) for t in time_values]
# Plotting the function
plt.figure(figsize=(10, 6))
plt.plot(time_values, counter_values, label=f'Initial Counter = {initial_counter}, Decay Time = {lfu_decay_time}')
plt.xlabel('Elapsed Time')
plt.ylabel('Counter Value')
plt.title('Counter Value Over Time with LFUDecrAndReturn Function')
plt.legend()
plt.grid(True)
plt.show()
2.3.2.2 热度值函数
前面提到,由于只有8位,类加到255就不够用了,那么热度值怎么具体表示呢。
Redis实现了一个对数增量算法,当前计数器值越高,递增的概率就越小。
#define LFU_INIT_VAL 5
/* Logarithmically increment a counter. The greater is the current counter value
* the less likely is that it gets really implemented. Saturate it at 255. */
uint8_t LFULogIncr(uint8_t counter) {
if (counter == 255) return 255;
// 随机数r 0到1之间的浮点数
double r = (double)rand()/RAND_MAX;
// 当前计数器值 减去 初始值LFU_INIT_VAL
double baseval = counter - LFU_INIT_VAL;
// 小于0置为0
if (baseval < 0) baseval = 0;
// 计算概率 p
double p = 1.0/(baseval*server.lfu_log_factor+1);
// 随机数 r 小于概率 p,则递增计数器 counter。
if (r < p) counter++;
return counter;
}
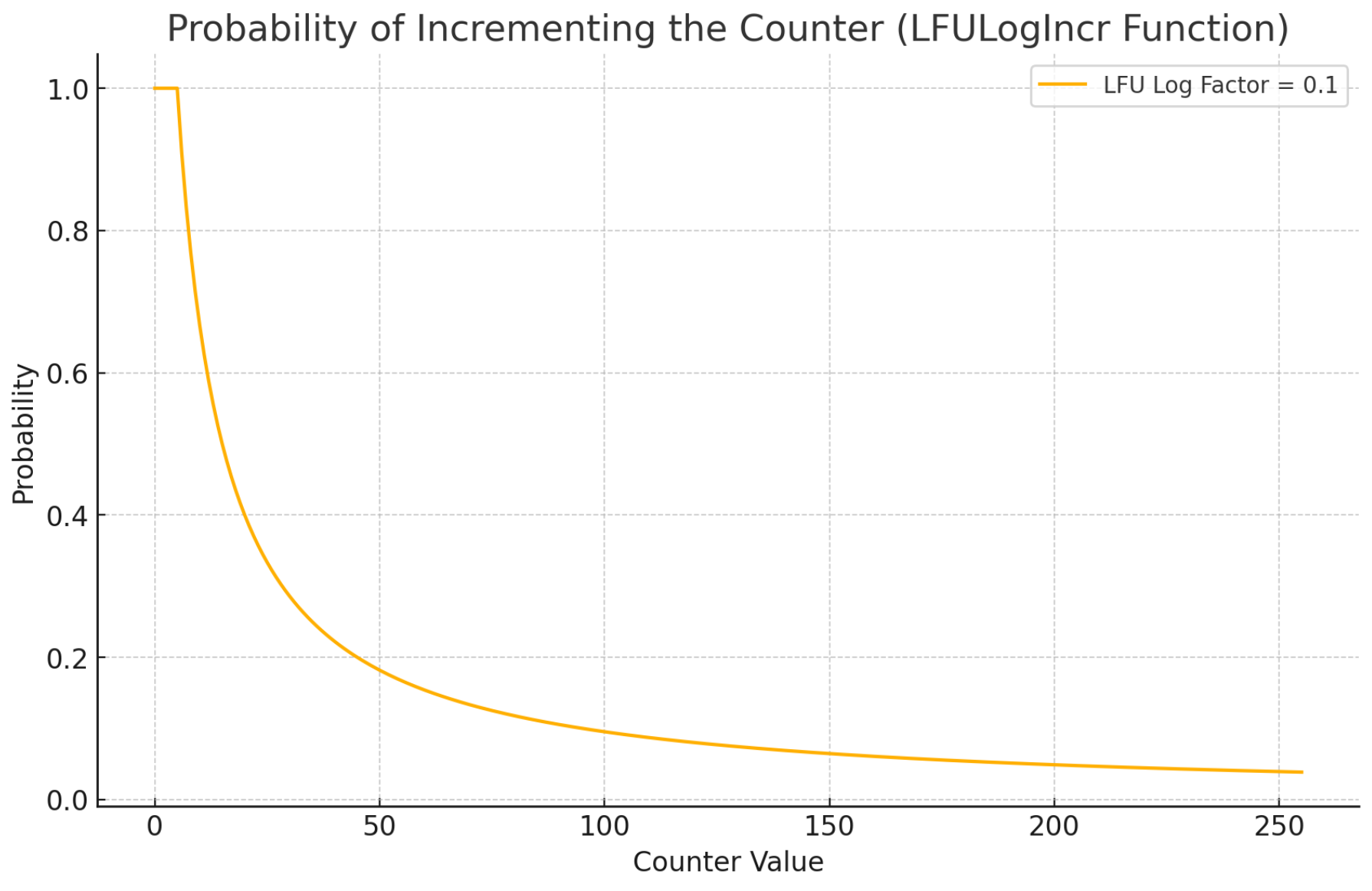
python绘图代码
import matplotlib.pyplot as plt
import numpy as np
# Define the function for probability
def calculate_probability(counter, lfu_log_factor):
LFU_INIT_VAL = 5
baseval = counter - LFU_INIT_VAL
if (baseval < 0):
baseval = 0
return 1.0 / (baseval * lfu_log_factor + 1)
# Generate x values (counter values) and y values (probability values)
counters = np.arange(0, 256)
lfu_log_factor = 0.1 # Example value for server.lfu_log_factor
probabilities = [calculate_probability(counter, lfu_log_factor) for counter in counters]
# Plotting the function
plt.figure(figsize=(10, 6))
plt.plot(counters, probabilities, label=f'LFU Log Factor = {lfu_log_factor}')
plt.xlabel('Counter Value')
plt.ylabel('Probability')
plt.title('Probability of Incrementing the Counter (LFULogIncr Function)')
plt.legend()
plt.grid(True)
plt.show()
2.3.2.3 总结
前面还是很抽象对不对,我们捋捋两个函数的作用。
- 热度值函数:热度值在低访问次数时迅速增长,而在高访问次数时增长速度减缓。
- 时间衰减函数:防止对象的热度值长期保持不变,通过定期减少对象的热度值来模拟对象热度的自然衰减。
2.4 区分LRU和LFU
所以,咱们怎么突然冒出来如此专业的两个词语,LRU和LFU?
这里的关键点是:热点数据
- LRU适合的是相对平稳的数据。比如会话管理,清除那些不再活跃的会话数据
- LFU适合的那种突然陡增的数据。比如某活动期间突然上升的xx热点数据。
| 策略 | 定义 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|---|
| LRU | 淘汰最近最少使用的缓存项 | - 用户访问记录 - 临时性数据缓存 - 会话管理 |
- 实现相对简单 - 保持热点数据 |
- 可能误淘汰将再次被频繁访问的缓存项 |
| LFU | 淘汰使用频率最少的缓存项 | - 长生命周期数据 - 数据统计 - 内容推荐 |
- 保留使用频率高的缓存项 - 避免误淘汰重要数据 |
- 实现较复杂 - 访问模式变化时响应慢 |