Redis持久化
1.1 为什么
Redis是基于内存的,不保存的话,应用停止了后数据就不在了。
持久化的诉求,主要是解决以下问题:
防止数据丢失
Redis 是一个内存数据库,数据主要存储在内存中。如果没有持久化机制,一旦服务器宕机或重启,内存中的所有数据都会丢失。通过持久化,Redis 可以在磁盘上保存数据的副本,在服务器重启后恢复数据,确保数据的完整性和连续性。
数据备份和恢复
持久化机制允许定期生成数据快照,并将其存储在磁盘上。这些快照可以用于备份和灾难恢复。当出现硬件故障、数据损坏或其他不可预见的问题时,可以从备份中恢复数据,减少数据丢失的风险。
数据迁移
通过持久化文件,可以方便地在不同的 Redis 实例之间迁移数据。例如,可以将 RDB 或 AOF 文件从一个服务器复制到另一个服务器,然后在新服务器上加载文件,实现数据的迁移。
高可用性和数据共享
持久化文件可以与其他数据存储系统共享,例如将 Redis 数据与其他数据库系统进行集成,或将数据导出到其他分析工具中进行处理。持久化确保了数据在不同系统间的可用性和一致性。
应对计划外重启
在进行服务器维护、软件升级或其他操作时,可能需要重启 Redis 实例。持久化机制保证了在这些情况下,重启后的数据可以快速恢复,减少系统停机时间,提高系统的可用性和可靠性。
应对计划外重启
持久化的日志文件(例如 AOF 文件)记录了所有的写操作。这些日志文件不仅可以用于数据恢复,还可以用于审计和分析。例如,分析日志文
Redis中的持久化,主要有3种方式。
| 持久化方式 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| RDB(Redis DataBase) | 在指定的时间间隔内生成数据集的快照,并将快照保存到磁盘 | - 文件紧凑高效,适合备份和灾难恢复 - 加载 RDB 文件速度快 |
- 可能丢失自上次快照以来的数据变化 - 生成快照时对性能有一定影响 |
| AOF(Append Only File) | 记录每个写操作到日志文件,并根据同步策略将日志同步到磁盘 | - 数据丢失窗口期短 - 文件格式易于理解和修改 |
- 文件通常比 RDB 大,恢复时间较长 - 写操作频繁时对性能有影响 |
| 混合持久化(RDB + AOF) | 结合 RDB 和 AOF 的优点,同时使用两种持久化方式 | - 提供完整快照和细粒度日志记录 - 减少数据丢失风险 |
- 需要更多的存储空间 - 复杂性增加 |
1.2 RDB(Redis DataBase)(默认)
Redis 的 RDB持久化机制是一种通过定期生成内存数据的快照(snapshot)并保存到磁盘的方法,以确保数据的持久性。
摄影的快照和慢照,强调的是快门的速度。
快照就相当于我们平时拍照片,立马就拍好了,记录的是一个瞬间的状态。
- Redis的快照文件通常以
dump.rdb的形式存储在磁盘中。 - Redis 会通过创建一个子进程来执行这个快照生成过程,以最小化对主进程的影响。
RDB的优点就是快和简单,但是缺点也很明显,因为快照不是时时刻刻都在记录。
不适合那些数据变更频繁、需要实时持久化的应用场景。
1.2.1 配置与命令
RDB 持久化机制默认是基于键的变化触发的。
如果xx秒内有xx个键变化,则触发一次全量快照。
1.2.1.1 命令行
- SAVE:同步执行快照生成,会阻塞 Redis 服务器,直到快照生成完成。
- BGSAVE:异步执行快照生成,不会阻塞 Redis 服务器。Redis 会立即返回 OK,然后fork 出一个子进程,快照生成过程在后台进行。
1.2.1.2 配置文件
# 保存快照的条件
# 自动触发bgsave命令创建快照
save 900 1 # 如果900秒内至少有1个key发生变化,则触发快照
save 300 10 # 如果300秒内至少有10个key发生变化,则触发快照
save 60 10000 # 如果60秒内至少有10000个key发生变化,则触发快照
# 指定快照文件的路径和名称
dir /var/lib/redis
dbfilename dump.rdb
redis启动的时候,会自动加载配置文件中的dump文件,重启自动恢复。
# 查看dump文件位置
cat /path/to/redis.conf | grep dir
嗯,既然是通过键触发的,我想搞成定时的咋办?
利用BGSAVE命令,比如cron脚本、应用代码等。
1.2.2 dump.rdb
这是个二进制文件,直接打开是乱码的。
有的字符可见,是因为Vim 默认情况下会尝试以 ASCII 或 UTF-8 格式打开文件。

嗯,具体的语法解析,可以使用python工具:redis-rdb-tools
或者,直接用redis-check-rdb命令,一般安装后就自带了,可以查看到一些dump文件的基本信息。
# redis-check-rdb dump.rdb
[offset 0] Checking RDB file dump.rdb # 从文件的第0字节开始检查RDB文件dump.rdb
[offset 26] AUX FIELD redis-ver = '7.0.8' # 辅助字段,表示生成RDB文件的Redis版本是7.0.8
[offset 40] AUX FIELD redis-bits = '64' # 辅助字段,表示Redis运行在64位架构上
[offset 52] AUX FIELD ctime = '1717123314' # 辅助字段,创建时间戳(Unix时间格式) 2024-05-31 02:41:54
[offset 67] AUX FIELD used-mem = '2178568' # 辅助字段,生成RDB文件时Redis使用的内存量为2178568字节(大约2.08MB)
[offset 79] AUX FIELD aof-base = '0' # 辅助字段,AOF文件的基准大小为0,可能是因为没有使用AOF持久化或AOF文件尚未生成
[offset 81] Selecting DB ID 0 # 选择数据库ID 0,开始解析数据库0的数据
[offset 329] Selecting DB ID 1 # 选择数据库ID 1,开始解析数据库1的数据
[offset 1031] Checksum OK # 校验和验证通过,RDB文件没有数据损坏
[offset 1031] \o/ RDB looks OK! \o/ # 成功信息,RDB文件结构和内容看起来都正常,没有检测到问题
[info] 10 keys read # 读取到10个键
[info] 0 expires # 没有键设置过期时间
[info] 0 already expired # 没有键已经过期
1.2.3 frok进程
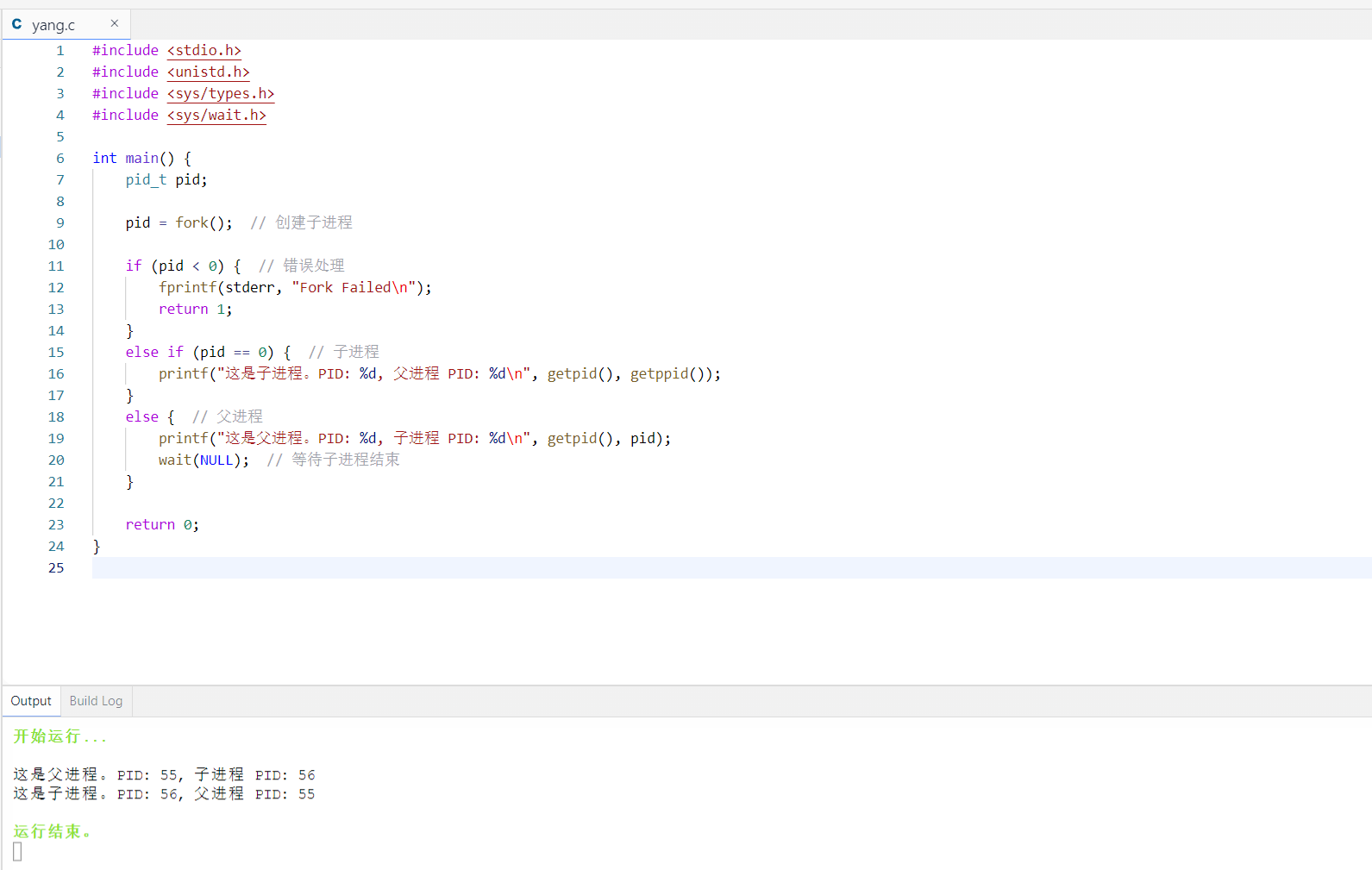
fork() 系统调用在操作系统中用于创建一个新进程,这个新进程被称为子进程。
fork() 进程实际上是对当前进程的一个复制,但有部分点要注意。
-
复制进程:
- 当一个进程调用
fork()时,操作系统会创建一个新进程(子进程),这个新进程是调用进程(父进程)的副本。 - 子进程会复制父进程的地址空间,包括代码段、数据段、堆和栈。子进程几乎完全与父进程相同,但有几个关键的区别。
- 当一个进程调用
-
独立的进程:
- 子进程与父进程是独立的进程,它们各自拥有自己的进程标识符(PID)。
- 子进程的 PID 与父进程不同,子进程的父进程 ID(PPID)是父进程的 PID。
-
返回值
fork()的返回值- 在父进程中,
fork()返回子进程的 PID。 - 在子进程中,
fork()返回 0。
- 在父进程中,
- 通过检查
fork()的返回值,程序可以确定当前正在运行的是父进程还是子进程
1.3 AOF(Append Only File)
AOF 是 Redis 提供的另一种持久化机制,通过将每一个写操作追加到日志文件中,确保数据的持久性。
AOF 文件记录了所有对数据库进行的写操作指令,这些指令可以用于在服务器启动时重新执行,从而重建数据库的状态。
与快照持久化相比,AOF 持久化的实时性更好。
默认情况下 Redis 没有开启 AOF(append only file)方式的持久化(Redis 6.0 之后已经默认是开启了)
1.3.1 配置与命令
1.3.1.1 配置文件
# 启用 AOF 持久化
appendonly yes
# AOF 文件名
appendfilename "appendonly.aof"
# 文件同步策略
appendfsync everysec # 每秒同步一次
# appendfsync always # 每次写操作都同步
# appendfsync no # 不主动同步,让操作系统决定何时同步
# 重写期间是否继续 fsync
no-appendfsync-on-rewrite no
# 自动重写配置:创建一个新的 AOF 文件
auto-aof-rewrite-percentage 100 # 当 AOF 文件大小增长到初始大小的百分比时触发重写
auto-aof-rewrite-min-size 64mb # 触发重写的最小文件大小
1.3.1.2 命令行
命令行,主要通过CONFIG SET的方式。
例如:
# 启用 AOF
CONFIG SET appendonly yes
# 修改同步策略
CONFIG SET appendfsync everysec
# 手动触发 AOF 重写
BGREWRITEAOF
# 可以使用 CONFIG GET 命令查看当前的 AOF 配置
CONFIG GET appendonly
CONFIG GET appendfilename
CONFIG GET appendfsync
CONFIG GET auto-aof-rewrite-percentage
CONFIG GET auto-aof-rewrite-min-size
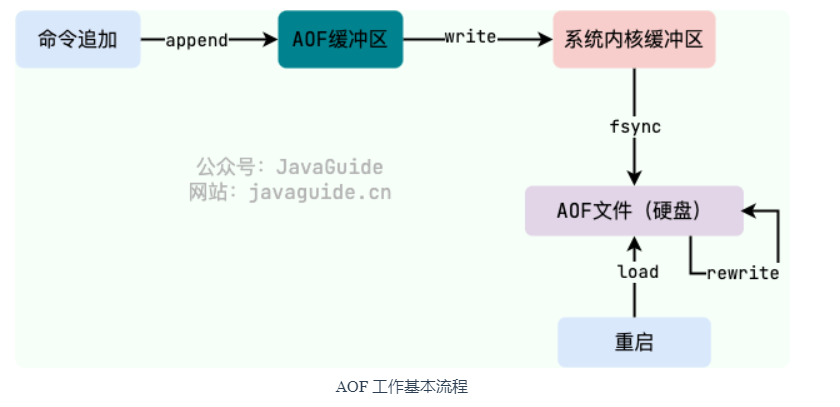
1.3.2 AOF执行过程
AOF缓冲区 -> 内核缓冲区 -> 磁盘
1.3.2.1 写入AOF缓冲区
每当 Redis 执行一条写操作命令(如 SET、INCR 等)时,这条命令会被记录到 AOF 缓冲区 server.aof_buf 中。
这个缓冲区在内存中,用于暂时存放待写入 AOF 文件的命令。
1.3.2.2 写入内核缓冲区(延迟写)
Redis 将 AOF 缓冲区中的命令写入到 AOF 文件中,这个过程是通过系统调用 write() 实现的。
注意啊,这里是延迟写,数据实际上是写入到系统内核的缓存区中,还没有真正写入到磁盘。
可以看看我这篇文章:Linux-文件写入和文件同步
1.3.2.3 写入AOF文件(刷盘)
只write的话,数据还在内核缓冲区。
什么时候将数据从系统内核缓存区同步到磁盘,取决于 AOF 的 fsync 策略配置,就是配置文件里的那个配置项。
| 配置选项 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| appendfsync always | 每次写操作都调用 fsync() 将数据同步到磁盘。这样可以确保每次写操作都被立即持久化,但性能开销较大。 |
最安全,数据丢失风险最低 | 性能开销最大,可能影响 Redis 性能 |
| appendfsync everysec | 每秒调用一次 fsync()。这种策略在性能和持久性之间取得了一个较好的平衡。如果在 fsync() 之前宕机,则可能丢失最近一秒内的数据。 |
性能和持久性之间的平衡 | 可能丢失最近一秒内的数据 |
| appendfsync no | 不主动调用 fsync(),由操作系统决定何时将数据从内核缓存区同步到磁盘。这种策略性能最好,但最不安全,因为数据丢失的窗口期最长。 |
性能最好,最小的写入开销 | 数据丢失的窗口期最长,最不安全 |
简单再总结下就是:
-
always
主线程调用
write执行写操作后,后台线程(aof_fsync线程)立即会调用fsync函数同步 AOF 文件(刷盘),fsync完成后线程返回,这样会严重降低 Redis 的性能(write+fsync)。 -
everysec
主线程调用
write执行写操作后立即返回,由后台线程(aof_fsync线程)每秒钟调用fsync函数(系统调用)同步一次 AOF 文件(write+fsync,fsync间隔为 1 秒) -
no
主线程调用
write执行写操作后立即返回,让操作系统决定何时进行同步,Linux 下一般为 30 秒一次(write但不fsync,fsync的时机由操作系统决定)。
1.3.3 为啥执行命令后再AOF
关系型数据库(如 MySQL)通常都是执行命令之前记录日志(方便故障恢复),而 Redis AOF 持久化机制是在执行完命令之后再记录日志。
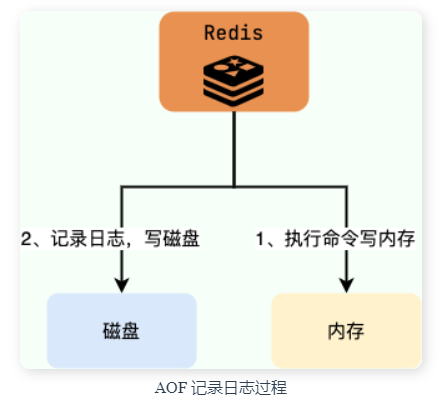
- 记录日志的时候可以不用再进行语法检查了
- 不会阻塞命令执行
- 易于恢复,AOF中的命令一定是成功执行过的
Redis
作为一个内存数据库,Redis的主要目标是提供极高的吞吐量和低延迟的读写操作。
因此,Redis优先保证命令的快速执行,并在执行后异步地将命令记录到AOF文件中,以确保整体性能。
MySQL
关系型数据库的设计目标之一是提供强一致性和事务支持,因此它们更注重数据的持久性和可靠性。
在执行命令之前记录日志(如MySQL的binlog)确保即使在系统崩溃时也能通过这些日志进行完整的事务恢复。
额,总结来说,就是redis的目标是快,舍弃了一致性,争取不阻塞。Mysql呢,强调的是数据一致性,阻塞了就阻塞了,数据安全最重要。
1.3.4 AOF重写
1.3.4.1 为什么需要AOF重写
Redis的AOF(Append Only File)重写机制(AOF rewrite)是为了防止AOF文件过度膨胀,从而优化Redis的启动时间和存储使用效率。
AOF 记录的是每个写操作的日志,因此如果对同一个键进行了多次写操作,这些操作都会被顺序地记录在 AOF 文件中,所以AOF(Append Only File)文件中可能包含一个键的多个历史操作信息,这个AOF文件肯定是比较大的。
我们多次对同一个键进行写操作,记录多条命令,可能只有最后一次操作的结果是有效的。
AOF重写的相关配置如下:
# 当现有 AOF 文件大小相对于上次重写后的大小增长超过一定百分比时触发重写。默认值是 100(即增长一倍
auto-aof-rewrite-percentage 100
# 最小 AOF 文件大小,以字节为单位,只有当 AOF 文件大小超过这个值时才会触发重写。默认值是 64MB。
auto-aof-rewrite-min-size 64mb
1.3.4.2 AOF重写是怎么做的
AOF 重写是一个有歧义的名字,实际上没有对原来的AOF文件进行操作。
AOF 重写子进程直接读取服务器现有的键值对,然后用一条命令去代替之前记录这个键值对的多条命令,生成一个新的文件后去替换原来的 AOF 文件,不涉及到原文件的读取。
我在执行重写的期间,也会有命令来呀?
AOF 文件重写期间,Redis 维护一个 AOF 重写缓冲区,该缓冲区会在子进程创建新 AOF 文件期间,记录服务器执行的所有写命令。
当子进程完成创建新 AOF 文件的工作之后,服务器会将重写缓冲区中的所有内容追加到新 AOF 文件的末尾,使得新的 AOF 文件保存的数据库状态与现有的数据库状态一致。
最后,服务器用新的 AOF 文件替换旧的 AOF 文件,以此来完成 AOF 文件重写操作。
1.3.4.3 AOF文件的格式
aof文件的格式是文本化的,可以直接看到key的变化,以键yang111为例。
增加string类型的key:yang111
set yang111 (null)
*3 # 表示有3个参数
$3 # 第1个参数长度为3
set # 第1个参数的具体值(命令也算参数)
$7 # 第2个参数长度为7
yang111 # 第2个参数的具体值
$0 # 第3个参数 这里最开始的时候没设置值 所以没有了
修改yang111的值为666
set yang111 666
*3
$3
set
$7
yang111
$3
666
删除键yang111
del yang111
*2
$3
del
$7
yang111
1.4 混合持久化
由于 RDB 和 AOF 各有优势,于是,Redis 4.0 开始支持 RDB 和 AOF 的混合持久化。
默认关闭,可以通过配置项开启。
# AOF前导rdb
aof-use-rdb-preamble yes
如果把混合持久化打开,AOF重写时直接把 RDB 的内容写到 AOF 文件开头。
所以,混合持久化的触发时机为AOF重写时。
- 优点
结合RDB和AOF 的优点,即可以RDB快速恢复,也降低了数据丢失的风险。
- 缺点
AOF 里面的 RDB 部分是压缩格式不再是 AOF 格式,可读性较差。
标签:文件,持久,AOF,Redis,RDB,进程,快照 From: https://www.cnblogs.com/yang37/p/18233452