最近在看面经,发现有很多跟B+树相关的问题,为此需要单独总结一下让自己形成一个体系。核心内容是为什么 MySQL 采用 B+ 树作为索引? | 小林coding 所以可以直接看小林code的讲解,很到位。
进入正题前,首先要对B树、B+树、二分查找树、自平衡二叉树、索引这些概念了初步解再分析具体问题。
二叉查找树
二分查找树(Binary Search Tree,简称BST),可以高效地管理和查询数据。
想象一下,你是一位图书管理员,你需要组织大量的图书,使得能够快速找到任何一本书。
用二分查找树的思想会怎么做呢?首先,我们选择一本书作为起始点,称之为“根”节点。在本例子中,我们选择一本书名在字母顺序中处于中间位置的书,比如书名为“M”的书。这样做的好处是,可以使得查找效率最高。
接下来,我们将图书按照字母顺序分成两部分:
- 一部分是所有书名字母在“M”之前的书,我们将这部分书放在“M”书的左边。
- 另一部分是所有书名字母在“M”之后的书,我们将这部分书放在“M”书的右边。
这样的排列形成了树的第一层。然后,我们对左边和右边的每一部分再次选择中间的书作为新的节点,同样地,将每部分再次分成两半,分别放到左右节点。这个过程一直重复,每个新选择的书都成为新的节点,直到所有的书都被加入到这棵树中。
例如,如果我们有书名分别为 A, C, E, G, I, K, M, O, Q, S, U, W, Y 的书,二分查找树可能看起来是这样的:
M
/ \
G S
/ \ / \
C K O W
/ \ / \ / \
A E I Q U Y
在这个树状结构中,每个节点的左子树包含的书名都比当前节点的书名字母顺序小,右子树包含的书名都比当前节点的书名字母顺序大。这种结构使得查找任何一本书都变得非常迅速。如果你要查找书名为"I"的书,你可以从根节点"M"开始,因为"I"小于"M",所以向左走到"G",然后因为"I"大于"G",所以向右走到"I",就找到了这本书。
自平衡二叉树
自平衡二叉树是一种特殊类型的二分查找树,它会在添加或删除节点后自动调整结构,以确保树的高度保持平衡。这样的设计可以避免树变得过于偏斜,从而保持操作的效率。
假设你在组织一个舞会,你需要让所有来宾排成一排,但是你希望这排人能尽量保持平衡,不要一边倾斜过多。为了实现这个目标,你决定每当有新的来宾加入时,都会检查排队的平衡,并在必要时通过让一些人交换位置来重新平衡队伍。
- 添加操作: 假设来宾的名字决定了他们站的位置,我们用他们名字的首字母来排序。开始时,我们有来宾A和来宾G。A在左边,G在右边。
- 添加更多来宾: 现在,来宾M想加入。按照字母顺序,M应该站在G的右边。这样排列后,从A到M的距离比从M到G的距离要短,排队开始变得不平衡。
A
\
G
\
M
- 自动平衡调整: 为了平衡排队,我们进行了一次“旋转”。这就像是让M前进到G的位置,然后G向右移动,A也向左移动,现在M处于中间位置,左边是A,右边是G。这样整个队伍就变得更加平衡了。
G
/ \
A M
这就是AVL树的工作原理。每当我们插入或删除节点时,AVL树都会检查各个节点的平衡因子(左子树高度与右子树高度的差),如果任何节点的平衡因子绝对值超过1(意味着不平衡),树就会通过旋转操作来重新平衡自己。
这些旋转操作有四种基本类型:
- 左旋:当右子树比左子树高,且不平衡节点的右子节点的右子树较高时进行。
- 右旋:当左子树比右子树高,且不平衡节点的左子节点的左子树较高时进行。
- 左-右旋:当左子树比右子树高,但不平衡节点的左子节点的右子树较高时先左旋该子节点,再对原节点进行右旋。
- 右-左旋:当右子树比左子树高,但不平衡节点的右子节点的左子树较高时先右旋该子节点,再对原节点进行左旋。
B树
依旧想象一下你在一个大图书馆里,有成千上万本书。图书馆的书架被设计得非常高效,以便你可以快速找到任何一本书。
- 节点的概念:你可以将每个书架看作是B树中的一个"节点",每个书架有多个层,每层可以放很多书。
- 分支的概念:如果某个书架满了,图书馆管理者可能会决定增加一个新的书架,这个过程类似于B树的"分裂"。书架间通过中间的引导,比如标签系统来引导你找到正确的书架。
- 平衡的概念:无论哪本书你需要,从图书馆的入口到这本书的路径大致长度相同,这就是B树保持"平衡"的体现。这意味着找到任何一本书的速度都差不多。
B树具体长什么样后面会说,此处只了解概念。
B+树
B+树在B树的基础上做了一些改进,使得它们在磁盘读取更加高效。
- 叶子节点的链接:在B+树中,所有的书籍信息(如书名、作者)只存在于最底层的书架(叶子节点),并且这些书架之间是相连的。这就像是在最底层的书架上,你可以从一端开始,一直走到另一端,中间不需要返回上层去找其他书。
- 非叶子节点的作用:上层的书架(非叶子节点)不存放书本,而只存放指向下一层书架的指示信息(比如书名的范围)。这有点像是每层书架上都有一个索引表,告诉你哪些书在哪个书架上。
- 搜索效率:当你查找一本书时,你先从最顶层的索引开始,逐层向下直到达到底层,然后沿着底层书架直接找到你的书。这种方式减少了在不同层之间的跳转,提高了查找效率。
索引
还是图书馆的例子,图书馆里有成千上万本书。如果读者想要找到一本特定的书,而图书馆没有任何排序或目录系统,那么找到这本书可能需要逐一检查每个书架上的每一本书,这将是非常耗时的。
在图书馆中,通常有一个图书索引系统,比如按照书名的字母顺序或者作者的名字排序的目录。当读者想找一本书时,他们可以先在图书目录中查找这本书的位置,然后直接去对应的书架和位置拿取书籍。这大大加快了查找过程,因为你不需要再逐本检查。
在MySQL数据库中,索引的工作原理类似于图书馆的图书目录。当你在数据库表中创建一个索引时,比如对用户表的“用户名”字段建立索引,数据库系统会维护一个内部的数据结构,这个结构会记录每个用户名的位置信息。
当你需要查询特定用户名的信息时,如果没有索引,数据库可能需要扫描整个表来找到这个用户名(这就像没有图书目录时逐一检查每本书)。但如果有了索引,数据库可以直接使用这个索引快速定位到含有该用户名的数据行,类似于你在图书目录中查找特定书名后直接找到那本书的过程。
分析比较
通过对索引的初步介绍,好处很多,那么用什么数据结构存储好呢?
数组
假设我们用数组存储索引,排好序,查找一个数据可以从头遍历,时间复杂度是O(n)。如果换用二分查找,时间复杂度变成了O(logn) ,现在看起来快了很多。但是用数组存储索引,要求索引是排序后的,所以要想插入新数据,有多麻烦想必是知道的。所以线性结构的数组pass掉了。
二叉查找树
既然二分查找速度上是值得肯定的,那么有没有一种数据结构非线性而且完美符合二分查找呢?就是二分查找树,特点就是一个节点的左子树的所有节点都小于该节点,右子树的所有节点都大于该节点。那么我们在查数据的时候,只需要将要查找的数据预节点数据进行比较就可以了,而且还免去了计算中间节点的开销。
除此之外,二叉查找树对插入新数据也很友好,可以在原本结构上放入任意符合其位置要求的地方。
目前来说,二叉查找树比线性数组好多了,但是存在一个极端情况,那就是如果每次插入的新元素都比之前的大或者小,这样就导致二叉查找树退化成了链表,查数的时间复杂度又降回了O(n) 。
自平衡二叉树
能不能在保留二叉查找树主体思想下还有办法解决极端情况退化成链表的问题?
这就引出了自平衡二叉树,常见有平衡二叉查找树(AVL树)和红黑树,我们以AVL树为例进行讲解,其本质上是在二叉查找树的基础上增加了约束:每个节点的左子树与右子树的高度差不能超过1。
现在可以拿来做索引的数据结构了吗?依旧不够。原因在于,不管哪种自平衡二叉树,本质上都是二叉树,一个节点最多只能有两个子节点,导致随着我们插入的元素越来越多,必然会让树的高度越来越高,意味着磁盘I/O操作次数还是很多,影响整体的数据查询效率。
B树
限制自平衡二叉树的点在于它是二叉树,如果解除这个限制,每个节点可以有M个子节点,那么就可以有效降低树的高度。
这就引出了B树,每个节点最多可以有M个子节点,所以B树是多叉树,M是B树的阶。
为什么 MySQL 采用 B+ 树作为索引? | 小林coding 在这部分讲得很通俗易懂,可以直接看这部分,还有动图演示。
关于B树的几个要点:
- 假设M=3,每个节点最多可以存(M-1)也就是2个数据,如果超过会建立新节点(上面例子中的一个书架可以存很多树)。
- 每个节点最多有M个子节点,如果超过会分类节点(例子中的,如果书架满了会建新的书架)。
小林code中对B树的缺陷是这么描述的:但是 B 树的每个节点都包含数据(索引+记录),而用户的记录数据的大小很有可能远远超过了索引数据,这就需要花费更多的磁盘 I/O 操作次数来读到「有用的索引数据」。,开始没有很理解,后来问了GPT,给了一个很生动的例子可以帮助理解:
想象你有一个大型的仓库,里面存放了很多不同的货物。每个货物都有一个标签(索引),上面写着货物的类型和位置,而货物本身(记录)则可能是一大箱物品。如果你只需要查找标签来确定货物的大致位置,这个过程会非常快。但如果每次查找标签你都必须搬运整箱货物来确认详细信息,这会非常耗时。
在B树的上下文中,如果每个节点(相当于一个货物位置)都存储了大量的数据记录,那么每次进行数据查找时,系统不仅需要读取索引信息,还可能读取那些并不需要的大量数据记录。这样存储的结果会导致1. 增加磁盘I/O操作:因为数据记录通常比索引大得多,所以读取含有数据记录的节点会占用更多磁盘I/O操作,即更多的读取时间。2. 效率下降:在查找过程中,大部分时间可能花在了读取并不立刻需要的数据上,这减慢了查询速度,尤其是在需要频繁遍历多个节点的情况下。
B+树
我们需要对B树进行优化,方向很明确:将索引和数据分离,仅在索引节点中存储必要的键和指向实际数据的指针(而非数据本身)。
单看文字都不知道B+树长什么样,借用一下小林code的图:
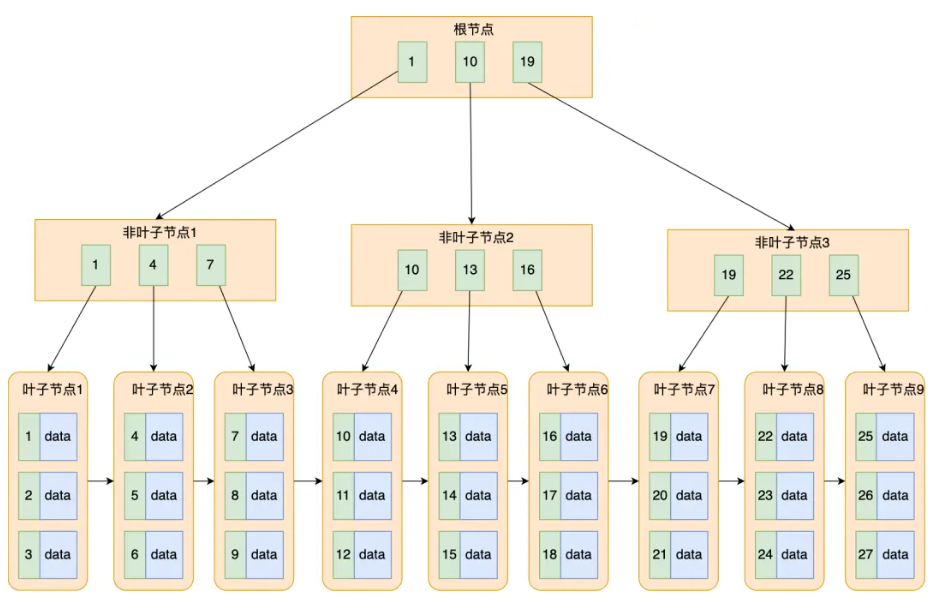
结合图,可以看出:
- 通常B+树的高度设计在3-4层,依旧可以存储大量上千万条数据,具体原因值得单独说,是一条单独的面经题。
- 叶子节点(最底部的节点)才会存放实际数据(索引+记录),非叶子节点只会存放索引。
- 所有索引都会在叶子节点出现,叶子节点之间构成一个有序链表。
- 非叶子节点的索引也会同时存在在子节点中,并且是在子节点中所有索引的最大(或最小)。
- 非叶子节点中有多少个子节点,就有多少个索引。
好了,我们从线性数组一步步优化到B+树,取其精华去其糟粕,到此B+树就可以用来做索引的数据结构了。
B树和B+树的比较
单点查询
“B+ 树的非叶子节点不存放实际的记录数据,仅存放索引,因此数据量相同的情况下,相比存储即存索引又存记录的 B 树,B+树的非叶子节点可以存放更多的索引,因此 B+ 树可以比 B 树更「矮胖」,查询底层节点的磁盘 I/O次数会更少。”
插入和删除
B+树在插入和删除节点的效率通常比B树高。主要原因是B+树的数据结构设计更统一和有序,特别是数据记录跟索引是分离的。
- 所有数据只在叶子节点
在B+树中,所有的数据记录仅存储在叶子节点中,而非叶子节点只存储索引。这种设计有几个好处:
- 统一的修改点:当需要插入或删除数据时,这些操作仅限于叶子节点。这意味着不需要修改内部节点中的数据,减少了修改的复杂度和潜在的错误。
- 叶子节点链接:B+树的叶子节点是相互链接的,这样的结构使得在叶子节点层进行的插入和删除操作可以很方便地通过链接进行调整,而不会影响到树的其它部分。
- 内部节点仅包含索引
由于内部节点不包含实际的数据,只包含指向子节点的索引,这减少了内部节点在数据插入或删除时的变动:
- 更少的数据移动:当一个节点需要分裂或合并时,仅涉及到索引的调整,而不需要移动大量数据。
- 更高的节点利用率:B+树的内部节点由于仅存储索引,可以包含更多的索引项,这意味着树更加紧凑,层次可能更少。
- 分裂和合并的简化
在B树中,由于数据和索引混杂在一起,当节点满时进行分裂,或者节点下溢时进行合并,都可能涉及到复杂的数据移动和重分配。相比之下,B+树因为所有数据都在叶子节点,且格式统一,所以:
- 分裂一致:叶子节点分裂时,仅涉及数据的均等分配和更新相邻节点的链接。
- 合并清晰:当叶子节点因删除操作而下溢时,可以与相邻节点进行数据重分配或合并,更新链接也比较直接。
范围查询
对于等值查询来说,B树和B+树原理一样,都是先从根节点查询,然后一层层比较查找到结果。
“在数据结构上,B+树在所有叶子节点间还有一个链表进行连接,这对范围查找很有帮助,比如说我们想知道 12 月 1 日和 12 月 12 日之间的订单,这个时候可以先查找到 12 月 1 日所在的叶子节点,然后利用链表向右遍历,直到找到 12 月12 日的节点,这样就不需要从根节点查询了,进一步节省查询需要的时间。”
“而 B 树没有将所有叶子节点用链表串联起来的结构,因此只能通过树的遍历来完成范围查询,这会涉及多个节点的磁盘 I/O 操作,范围查询效率不如 B+ 树。”
相关面经问题
- 待补充...