Redis集群方案
主从模式
一主多从,主节点负责写数据,从节点负责读数据,主节点定期把数据同步到从节点保证数据的一致性。避免单点故障,实现了读写分离。
优点:
- 主从结构具有读写分离、提高效率、数据备份、提供多个副本等优点。
缺点:
- 不具备恢复功能,如果主节点宕机,则不能提供服务,需要手动将从节点设置为主节点
- 主从复制主节点的写能力是单机的,能力有限
建立主从复制:
- 在配置文件中加入slaveof {masterHost} {masterPort} 随redis启动生效
- 在redis-server启动命令后加入—slaveof {masterHost} {masterPort}生效
- 直接使用命令:slaveof {masterHost} {masterPort}生效
哨兵模式
第一种主从同步模式当主服务器宕机后,需要手动将从服务器切换为主服务器,并修改客户端配置,还会造成一段时间服务不可用。哨兵模式的核心还是主从复制,但是它解决了redis主从切换需要人工干预的问题。
哨兵作用:
- 监控所有服务器是否正常运行:通过发送命令返回监控服务器的运行状态,除了监控主、从服务器外,哨兵之间也会相互监控。每一个哨兵都是一个独立的进程,独立运行。
- 故障切换:当哨兵监测到master当即,会自动将slave切换成master,然后通过发布订阅模式通知其他从服务器,修改配置文件,让他们切换master。当客户端试图连接失效的主服务器时,集群会向客户端返回新主服务器的地址。宕机的旧主在恢复后会作为新主的从节点。
哨兵原理:
哨兵在启动进程时,会读取配置文件的内容,通过如下的配置找出需要监控的主数据库:
sentinel monitor master-name ip port quorum
# master-name 是主数据库的名字
# ip 和 port是当前主数据库地址和端口号
# quorum 表示在执行故障切换操作前,需要多少哨兵节点同意
连接主节点之后,可以通过主节点的info命令,获取从节点信息,从而与从节点建立连接。
哨兵启动后会与主数据库建立两条连接:
- 订阅主数据库
_sentinel_:hello频道以获取同样监控该数据库的哨兵节点信息。 - 定期向主数据库发送info命令,获取主数据库本身的信息
跟主数据库建立连接后会定时执行一下三个操作:
- 每隔10s向master和slave发送info命令。作用是获取当前数据库信息,比如发现新增从节点时,会建立连接,并加入到监控列表中,当主从数据库的角色发生变化进行信息更新。
- 每隔 2 s 向主数据里和从数据库的
_sentinel_:hello频道发送自己的信息。作用是将自己的监控数据和哨兵分享。每个哨兵会订阅数据库的_sentinel:hello频道,当其他哨兵收到消息后,会判断该哨兵是不是新的哨兵,如果是则将其加入哨兵列表,并建立连接。 - 每隔 1 s 向所有主从节点和所有哨兵节点发送 ping 命令,作用是监控节点是否存活。
优点:
- 哨兵模式是基于主从模式的,解决了主从模式中master故障不可自动切换的问题。
缺点:
- 是一种中心化的集群实现方案,始终只有一个redis主机接收和处理写请求,写操作受单机瓶颈影响
- 集群里所有节点保存的都是全量数据,浪费内存空间,没有真正实现分布式存储。当数据量过大时,主从同步严重影响master的性能
- 主机宕机后,在哨兵投票选举出主节点之前,互相不知道谁是主从机,此时redis会开启保护机制,禁止写操作,直到选举出新主节点。
客户端分片
Redis在3.0版本前只支持单实例模式,在3.0版本发布之前,使用的是数据分片的集群方案,核心思想就是把数据分片(sharding)存储在多个redis实例中。
客户端分片是把分片的逻辑放在Redis客户端实现,(比如:Jedis已支持的Redis Sharding功能,即ShardedJedis),通过客户端预先定义好的路由规则(使用一致性哈希),把对key的访问转发到不同的redis实例中,查询时把返回结果汇集。
优点:
- 客户端 sharding 技术使用 hash 一致性算法分片的好处是所有的逻辑都是可控的,不依赖于第三方分布式中间件。服务端的 Redis 实例彼此独立,相互无关联,每个 Redis 实例像单服务器一样运行,非常容易线性扩展,系统的灵活性很强。
缺点:
- 服务端 Redis 实例群拓扑结构有变化时,每个客户端都需要更新调整。
Redis Cluster
Redis在3.0上加入了Cluster集群模式,实现了Redis的分布式存储,每台Redis节点上存储不同的数据。cluster模式为了解决单机Redis容量有限的问题,将数据按一定的规则分配到多台机器,内存/QPS不受限于单机。Redis Cluster是一种服务器Sharding技术(分片和路由都是在服务端实现),采用多主多从,每个分区都是由一个Redis主机和多个从机组成,片区和片区之间是互相平行的。Redis Cluster集群采用P2P模式,完全去中心化。
特点:
- 集群完全去中心化,采用多主多从;所有的 redis 节点彼此互联(PING-PONG 机制),内部使用二进制协议优化传输速度和带宽。
- 客户端与 Redis 节点直连,不需要中间代理层。客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
- 每一个分区都是由一个 Redis 主机和多个从机组成,分片和分片之间是相互平行的。
- 每一个 master 节点负责维护一部分槽,以及槽所映射的键值数据;集群中每个节点都有全量的槽信息,通过槽每个 node 都知道具体数据存储到哪个 node 上。
Redis Cluster 采用虚拟哈希槽分区而非一致性 hash 算法,预先分配一些卡槽,所有的键根据哈希函数映射到这些槽内,每一个分区内的 master 节点负责维护一部分槽以及槽所映射的键值数据。
数据分区原理
分布式数据存储首先要解决整个数据集如何按照分区规则划分到多个节点问题,每个节点负责整个数据集的子集。常见的分区规则有3种:哈希取余分区、一致性哈希算法分区和哈希槽分区。
哈希取余分区
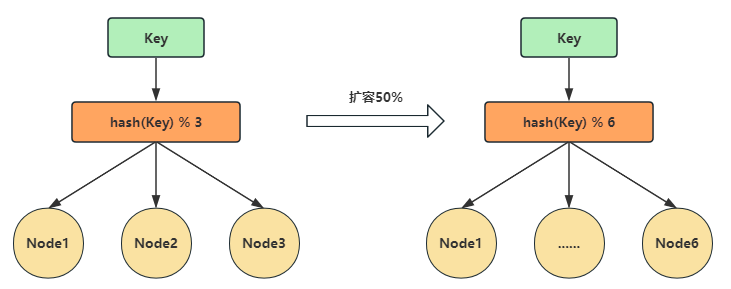
用数据的键(key)通过哈希函数得到一个哈希值,然后将哈希值与节点数量(N)取余,以确定数据属于哪个节点。公式:hash(key) % N
优点:
- 这种方式的优点是简单,一般采用预分区的方式,提前根据数据量规划好分区数,比如划分为
512或1024张表,保证可支撑未来一段时间的数据容量。扩容时通常采用翻倍扩容,避免数据映射全部被打乱,导致全量迁移的情况。常用于数据库的分库分表。
缺点:
- 当节点数量变化时,比如扩容、缩容、宕机节点,数据节点的映射关系需要重新计算,会导致数据的重新迁移
一致性哈希算法分区
一致性哈希算法就是将整个哈希值空间组织成一个虚拟的圆环,哈希函数的值空间为0 ~ 2^32 - 1。
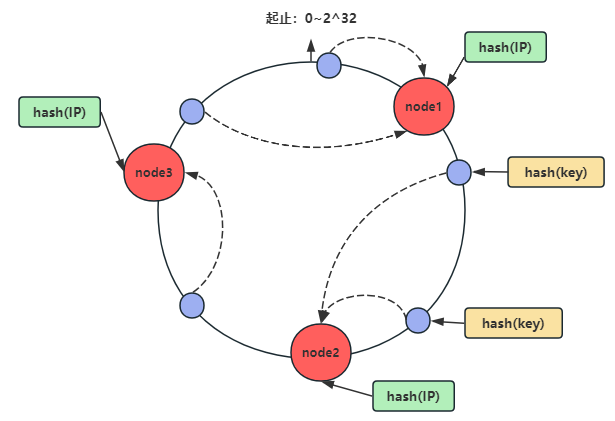
将node1、node2、node3服务器的IP作为唯一关键字,使用Hash(IP)进行哈希,这样每台机器就能确定其在哈希环上的位置。
key落键规则:当我们需要存储一个kv键值对时,首先计算key的hash值(hash(key))将这个key使用相同的哈希函数计算出哈希值,并确定此数据在换上的位置,从此位置沿环顺时针寻找,第一台遇到的服务器就是其应该定位到的服务器,并将该键值对存储在该节点上。
优点:
- 容错性:若node2挂掉,受影响的数据只有node1和node2之间的数据,且这些数据会转移到node3存储。
- 扩展性:若在node1和node2之间增加一台node4,受影响的数据只有node1和node4,重写把node1和node4的数据录入到node4即可,不会导致hash取余数据重新洗牌计算。
缺点:
- 数据倾斜:若节点太少且分布不均匀时,会造成大部分数据集中存放在某一台上的问题
哈希槽分区
为了解决数据倾斜的问题,Redis3.0中引入了哈希槽的概念。
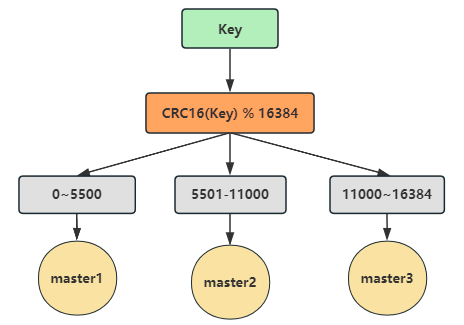
Redis集群有16384个哈希槽,集群会先给每个master节点分配一部分哈希槽。比如当前集群有3个master节点:
- master1节点包含0~5500号哈希槽
- master2节点包含5501~1000号哈希槽
- master3节点包含11001~16384号哈希槽
进行set操作时,每个key会通过CRC16校验后再对16384取模来决定放置在哪个槽,比如 CRC16(key) % 16384 = 777,那么这个key就会被分配到master1节点上,如下图: