https://developer.aliyun.com/article/283561
一、 游标的分类及共享游标
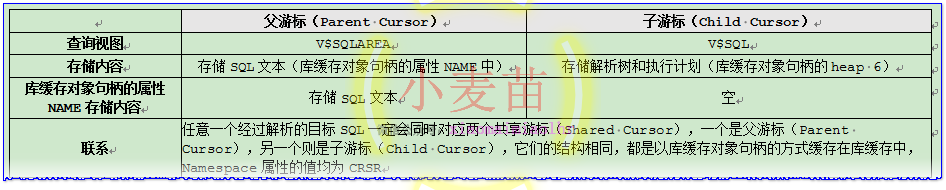
游标(Cursor)是Oracle数据库中SQL解析和执行的载体,它可以分为共享游标(Shared Cursor)和会话游标(Session Cursor)。共享游标可以细分为父游标(Parent Cursor)和子游标(Child Cursor),可以通过视图V$SQLAREA和V$SQL来查看当前缓存在库缓存(Library Cache)中的父游标和子游标,其中V$SQLAREA用于查看父游标,V$SQL用于查看子游标。父游标和子游标的结构是一样的,它们都是以库缓存对象句柄的方式缓存在库缓存中,Namespace属性的值均为CRSR。由于子游标对应的库缓存对象句柄的Name属性值为空,所以,只能通过父游标才能找到相应的子游标。综上所述,任意一个经过解析的目标SQL一定会同时对应两个共享游标(Shared Cursor),一个是父游标(Parent Cursor),另一个则是子游标(Child Cursor),父游标会存储该SQL的SQL文本,而该SQL真正的可以被重用的解析树和执行计划则存储在子游标中。
Oracle中游标的分类如下所示:
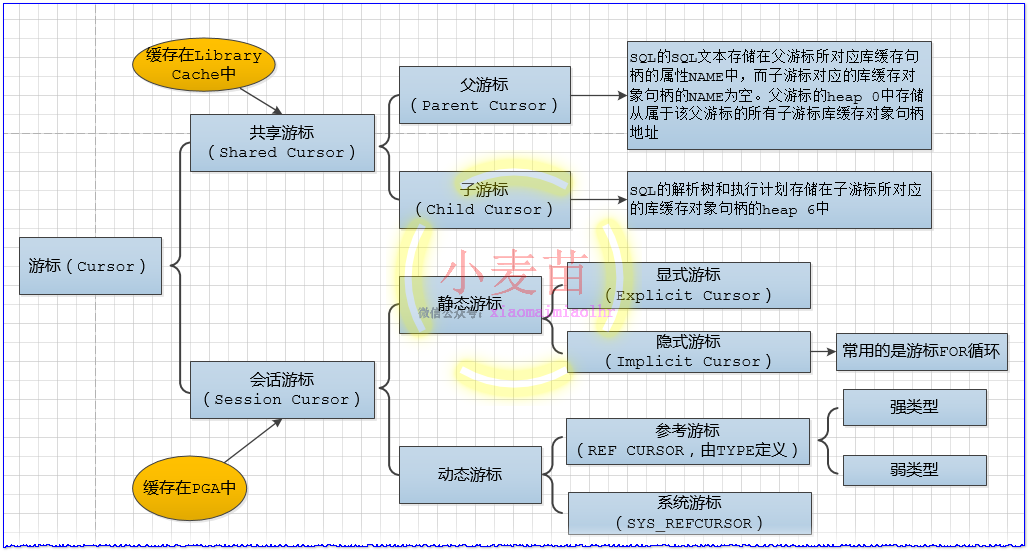
图 3-13 Oracle中的游标分类
父游标和子游标的对比如下表所示:
二、 会话游标
(一) 会话游标的含义
会话游标(Session Cursor)是当前会话(Session) 解析和执行 SQL 的载体, 即会话游标用于在当前会话(Session) 中解析和执行 SQL ,会话游标缓存在 PGA 中 ( Shared Cursor 是缓存在 SGA 的库缓存里) 。会话游标是以哈希表的方式缓存在 PGA 中 ,在缓存会话游标 的哈希表的对应 Hash Bucket 中, Oracle 会存储目标 SQL 对应的父游标的库缓存对象句柄地址,所以, Oracle 可以通过会话游标找到对应的父游标,进而就可以找到对应子游标中目标 SQL 的解析树和执行计划,然后 Oracle 就可以按照这个解析树和执行计划来执行目标 SQL 了。
会话游标在目标SQL的执行过程中实际上起到了一个承上启下的作用,Oracle依靠会话游标来将目标SQL所涉及的数据从Buffer Cache的对应数据块读到PGA里,然后在PGA里做后续的处理(如排序、表连接等),最后将最终的处理结果返回给用户,所以,会话游标是当前会话解析和执行SQL的载体的原因。
关于会话游标,需要注意以下几点:
① 会话游标(Session Cursor)与会话(Session)是一一对应的,不同会话的会话游标之间不能共享,这是与共享游标(Shared Cursor)的本质区别。
② 会话游标是有生命周期的,每个会话游标在使用的过程中都至少会经历一次Open、Parse、Bind、Execute、Fetch和Close中的一个或多个阶段,用过的会话游标不一定会缓存在对应会话的PGA中,这取决于参数SESSION_CACHED_CURSORS的值是否大于0。
共享游标和会话游标的对比如下表所示:

(二)会话游标的分类
会话游标的详细分类参考下表:
表 3-20 Oracle中会话游标的分类
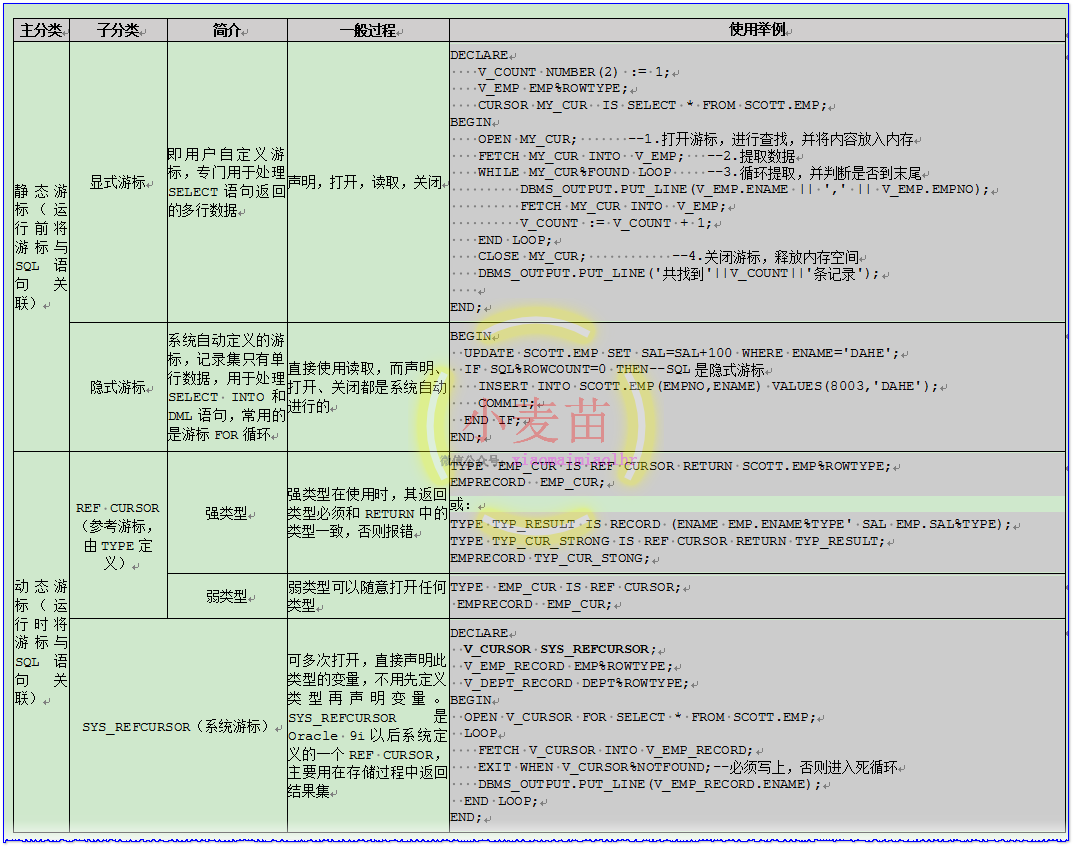
在上表中特别说明一下动态游标,动态游标是Oracle数据库中最灵活的一种会话游标,它的灵活性表现在:①动态游标的定义方式非常灵活,它可以有多种定义方式。②参考游标可以作为存储过程的输入参数和函数的输出参数。上表中的各种游标希望读者可以通过做大量的练习题来掌握,毕竟游标是存储过程开发过程中必不可少的内容。
(三)会话游标的属性
会话游标有4个属性,见下表:

当执行一条DML语句后,DML语句的结果保存在这四个游标属性中,这些属性用于控制程序流程或者了解程序的状态。当运行DML语句时,PL/SQL打开一个内建游标并处理结果。在这些属性中,SQL%FOUND和SQL%NOTFOUND是布尔值,SQL%ROWCOUNT是整数值。需要注意的是,若游标属于隐式游标,则在PL/SQL中可以直接使用上表中的属性,若游标属于显式游标,则上表中的属性里“SQL%”需要替换为自定义显式游标的名称。上表中的这4个属性对于动态游标依然适用。
(四)会话游标的相关参数
和会话游标相关的有2个重要参数,分别为OPEN_CURSORS和SESSION_CACHED_CURSORS,下面详细介绍这两个参数。
(1)参数OPEN_CURSORS用于设定单个会话中同时能够以OPEN状态并存的会话游标的总数,默认值为50。若该值为300,则表示单个会话中同时能够以OPEN状态并存的会话游标的总数不能超过300,否则Oracle会报错“ORA-1000:maximum open cursors exceeded”。视图V$OPEN_CURSOR可以用来查询数据库中状态为OPEN或者己经被缓存在PGA中的会话游标的数量和具体信息(例如,SQL_ID和SQL文本等)。当然,也可以从视图V$SYSSTAT中查到当前所有以OPEN状态存在的会话游标的总数。
LHR@orclasm > show parameter open_cursors
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
open_cursors integer 65535
SELECT USERENV('SID') FROM DUAL;
SELECT * FROM V$OPEN_CURSOR WHERE SID=16;
SELECT * FROM V$SYSSTAT D WHERE D.NAME ='opened cursors current';
(2)参数SESSION_CACHED_CURSORS用于设定单个会话中能够以Soft Closed状态并存的会话游标的总数,即用于设定单个会话能够缓存在PGA中的会话游标的总数。在Oracle 10g中默认为20(注意:在官方文档中该值默认为0,其实是20),11g中默认为50。
LHR@orclasm > show parameter session_cached_cursors
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
session_cached_cursors integer 50
从上述显示结果可以看出,SESSION_CACHED_CURSORS的值为50,意味着在这个库里,单个会话中同时能够以Soft Closed状态缓存在PGA中的会话游标的总数不能超过50。
Oracle会用LRU算法来管理这些已缓存的会话游标(从会话游标的dump文件中可以证实这一点),所以即便某个Session以Soft Closed状态缓存在PGA中的会话游标的总数己经达到了SESSION_CACHED_CURSORS所设置的上限也没有关系,LRU算法依然能够保证那些频繁反复执行的SQL所对应的会话游标的缓存命中率要高于那些不频繁反复执行的SQL。
这里需要注意的是,在Oracle 11gR2中,一个会话游标能够被缓存在PGA中的必要条件是该会话游标所对应的SQL解析和执行的次数要超过3次。Oracle这么做的目的是为了避免那些执行次数很少的SQL所对应的会话游标也被缓存在PGA里,这些SQL很可能只执行一次而且不会重复执行,所以把这些执行次数很少的SQL所对应的会话游标缓存在PGA中是没有太大意义的。
LHR@orclasm > alter system flush shared_pool;--生产库慎用
System altered.
--开始第1次执行
LHR@orclasm > SELECT D.SQL_ID,D.CURSOR_TYPE FROM V$OPEN_CURSOR D WHERE D.SID=USERENV('SID') AND D.SQL_TEXT LIKE 'SELECT /*test scc*/ COUNT(*)%' ;
no rows selected
LHR@orclasm > SELECT /*test scc*/ COUNT(*) FROM SCOTT.EMP;
COUNT(*)
----------
14
LHR@orclasm > SELECT D.SQL_ID,D.CURSOR_TYPE FROM V$OPEN_CURSOR D WHERE D.SID=USERENV('SID') AND D.SQL_TEXT LIKE 'SELECT /*test scc*/ COUNT(*)%' ;
no rows selected
开始第2次执行:
LHR@orclasm > SELECT /*test scc*/ COUNT(*) FROM SCOTT.EMP;
COUNT(*)
----------
14
LHR@orclasm > SELECT D.SQL_ID,D.CURSOR_TYPE FROM V$OPEN_CURSOR D WHERE D.SID=USERENV('SID') AND D.SQL_TEXT LIKE 'SELECT /*test scc*/ COUNT(*)%' ;
no rows selected
开始第3次执行:
LHR@orclasm > SELECT /*test scc*/ COUNT(*) FROM SCOTT.EMP;
COUNT(*)
----------
14
LHR@orclasm > SELECT D.SQL_ID,D.CURSOR_TYPE FROM V$OPEN_CURSOR D WHERE D.SID=USERENV('SID') AND D.SQL_TEXT LIKE 'SELECT /*test scc*/ COUNT(*)%' ;
SQL_ID CURSOR_TYPE
------------- ----------------------------------------------------------------
9r01dt51f46tf DICTIONARY LOOKUP CURSOR CACHED
从结果可以看到,虽然已经缓存到PGA中了,但是类型为“DICTIONARY LOOKUP CURSOR CACHED”,并不是“SESSION CURSOR CACHED”,所以下面开始第4次执行:
LHR@orclasm > SELECT /*test scc*/ COUNT(*) FROM SCOTT.EMP;
COUNT(*)
----------
14
LHR@orclasm > SELECT D.SQL_ID,D.CURSOR_TYPE FROM V$OPEN_CURSOR D WHERE D.SID=USERENV('SID') AND D.SQL_TEXT LIKE 'SELECT /*test scc*/ COUNT(*)%' ;
SQL_ID CURSOR_TYPE
------------- ----------------------------------------------------------------
9r01dt51f46tf SESSION CURSOR CACHED
LHR@orclasm > SELECT a.VERSION_COUNT,a.EXECUTIONS,a.PARSE_CALLS,a.LOADS FROM v$sqlarea a WHERE a.SQL_ID='9r01dt51f46tf';
VERSION_COUNT EXECUTIONS PARSE_CALLS LOADS
------------- ---------- ----------- ----------
1 4 3 1
从结果可以看到,在SQL语句“SELECT /*test scc*/ COUNT(*) FROM SCOTT.EMP;”第4次执行完毕后,Oracle已经将其对应的会话游标缓存在当前会话的PGA中了,而此时缓存的会话游标的类型为“SESSION CURSOR CACHED”。下面开始第5次执行:
LHR@orclasm > SELECT /*test scc*/ COUNT(*) FROM SCOTT.EMP;
COUNT(*)
----------
14
LHR@orclasm > SELECT D.SQL_ID,D.CURSOR_TYPE FROM V$OPEN_CURSOR D WHERE D.SID=USERENV('SID') AND D.SQL_TEXT LIKE 'SELECT /*test scc*/ COUNT(*)%' ;
SQL_ID CURSOR_TYPE
------------- ----------------------------------------------------------------
9r01dt51f46tf SESSION CURSOR CACHED
LHR@orclasm > SELECT a.VERSION_COUNT,a.EXECUTIONS,a.PARSE_CALLS,a.LOADS FROM v$sqlarea a WHERE a.SQL_ID='9r01dt51f46tf';
VERSION_COUNT EXECUTIONS PARSE_CALLS LOADS
------------- ---------- ----------- ----------
1 5 3 1
从结果看出,缓存的会话游标的类型依然为“SESSION CURSOR CACHED”,不再改变。
(五)会话游标的dump文件
会话游标的dump文件可以通过Level值为3的errorstack得到,获取过程如下所示:
SELECT COUNT(*) FROM SCOTT.EMP;--执行5次,让其缓存在PGA中
SELECT COUNT(*) FROM SCOTT.EMP;
SELECT COUNT(*) FROM SCOTT.EMP;
SELECT COUNT(*) FROM SCOTT.EMP;
ALTER SESSION SET EVENTS 'IMMEDIATE TRACE NAME ERRORSTACK LEVEL 3';
SELECT COUNT(*) FROM SCOTT.EMP;
ALTER SESSION SET EVENTS 'IMMEDIATE TRACE NAME ERRORSTACK OFF';
SELECT VALUE FROM V$DIAG_INFO;
三、 SQL的解析过程(硬解析、软解析、软软解析)
在Oracle中,每条SQL语句在执行之前都需要经过解析(Parse)。DDL语句是从来不会共享使用的,也就是说DDL语句每次执行都需要进行硬解析。但是,DML语句和SELECT语句会根据情况选择是进行硬解析,还是进行软解析或者进行软软解析。
Oracle对SQL的处理过程如下所示:
(1)语法检查(Syntax Check):检查此SQL的拼写是否正确。
(2)语义检查(Semantic Check):例如检查SQL语句中的访问对象是否存在及该用户是否具备相应的权限。
(3)对SQL语句进行解析(Parse):利用内部算法对SQL进行解析,生成解析树(Parse Tree)及执行计划(Execution Plan)。
(4)执行SQL,返回结果。
解析主要分为3种类型:硬解析(Hard Parse)、软解析(Soft Parse)和软软解析(Soft Soft Parse,也叫快速解析(Fast Parse)),它们的解析过程可以参考下图:
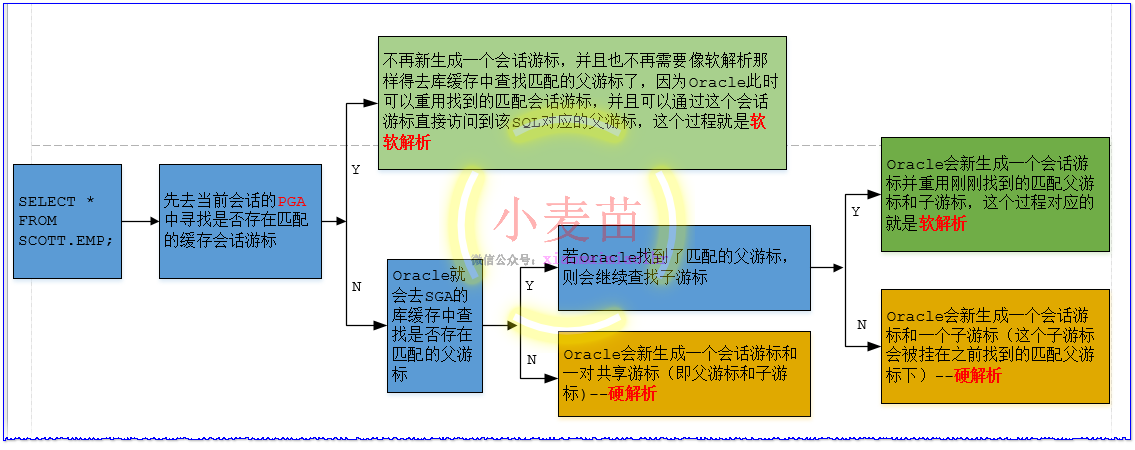
Oracle在解析和执行目标SQL时,会先去当前会话的PGA中查找是否存在匹配的缓存Session Cursor。当Oracle第一次解析和执行目标SQL时(显然是硬解析),当前Session的PGA中肯定不存在匹配的Session Cursor,这时Oracle会新生成一个Session Cursor和一对Shared Cursor(即Parent Cursor和Child Cursor),这其中的Shared Cursor会存储能被所有会话共享、重用的内容(比如目标SQL的解析树、执行计划等),而Session Cursor则会经历一次Open、Parse、Bind、Execute、Fetch和Close中的一个或多个阶段。
对会话游标(Session Cursor)和共享游标(Shared Cursor)之间的关联关系如下总结:
l 无论是硬解析、软解析还是软软解析,Oracle在解析和执行目标SQL时,始终会先去当前会话(Session)的PGA中寻找是否存在匹配的缓存会话游标。
l 如果在当前会话的PGA中找不到匹配的缓存会话游标,那么Oracle就会去SGA的库缓存(Library Cache)中查找是否存在匹配的父游标。如果在库缓存中找不到匹配的父游标,那么Oracle就会新生成一个会话游标和一对共享游标(即父游标和子游标);如果找到了匹配的父游标,但找不到匹配的子游标,那么Oracle就会新生成一个会话游标和一个子游标(这个子游标会被挂在之前找到的匹配父游标下)。无论哪一种情况,这两个过程对应的都是硬解析。
l 如果在当前会话的PGA中找不到匹配的缓存会话游标,但在库缓存中找到了匹配的父游标和子游标,那么Oracle会新生成一个会话游标并重用刚刚找到的匹配父游标和子游标,这个过程对应的就是软解析。
l 如果在当前会话的PGA中找到了匹配的缓存会话游标,那么此时Oracle就不再需要新生成一个会话游标,并且也不再需要像软解析那样得去SGA的库缓存中查找匹配的父游标了,因为Oracle此时可以重用找到的匹配会话游标,并且可以通过这个会话游标直接访问到该SQL对应的父游标,这个过程就是软软解析。
下面详解介绍硬解析(Hard Parse)、软解析(Soft Parse)和软软解析(Soft Soft Parse):
(一)硬解析(Hard Parse)
硬解析(Hard Parse)是指Oracle在执行目标SQL时,在库缓存(Library Cache)中找不到可以重用的解析树和执行计划,而不得不从头开始解析目标SQL并生成相应的父游标(Parent Cursor)和子游标(Child Cursor)的过程。
硬解析实际上有两种类型:一种是在库缓存中找不到匹配的父游标(Parent Cursor),此时Oracle会从头开始解析目标SQL,新生成一个父游标和一个子游标,并把它们挂在对应的HashBucket中;另外一种是找到了匹配的父游标但未找到匹配的子游标,此时Oracle也会从头开始解析该目标SQL,新生成一个子游标,并把这个子游标挂在对应的父游标下。
硬解析大致可以分为5个执行步骤:
(1)语法分析。
(2)权限与对象检查。
(3)在共享池中检查是否有完全相同的之前完全解析好的。如果存在,则直接跳过步骤(4)和步骤(5),运行SQL,此时算SOFT PARSE。
(4)选择执行计划。
(5)产生执行计划。
需要注意的是,创建解析树、生成执行计划对于SQL的执行来说是开销昂贵的动作,所以,应当极力避免硬解析,尽量使用软解析。这就是在很多项目中,倡导开发设计人员对功能相同的代码要努力保持代码的一致性,以及要在程序中多使用绑定变量的原因。
在硬解析时,需要申请闩的使用,而闩的数量在有限的情况下需要等待。大量的闩的使用由此造成需要使用闩的进程排队越频繁,性能则逾低下。具体来说,硬解析的危害性体现在以下几点上:
① 硬解析可能会导致Shared Pool Latch的争用。无论是哪种类型的硬解析,都至少需要新生成一个Child Cursor,并把目标SQL的解析树和执行计划载入该Child Cursor里,然后把这个Child Cursor存储在库缓存中。这意味着Oracle必须在Shared Pool中分配出一块内存区域用于存储上述Child Cursor,而在Shared Pool中分配内存这个动作是要持有Shared Pool Latch的(Oracle数据库中Latch的作用之一就是保护共享内存的分配),所以如果有一定数量的并发硬解析,可能就会导致Shared Pool Latch的争用,而一旦发生大量的Shared Pool Latch争用,系统的性能和可扩展性是会受到严重影响的(常常表现为CPU的占用率居高不下,接近100%)。
② 硬解析可能会导致库缓存相关Latch(如Library Cache Latch)和Mutex的争用。无论是哪种类型的硬解析,都需要扫描相关Hash Bucket中的库缓存对象句柄链表,而扫描库缓存对象句柄链表这个动作是要持有Library Cache Latch的(Oracle数据库中Latch的另外一个作用就是用于共享SGA内存结构的并发访问控制),所以如果有一定数量的并发硬解析,则也可能会导致Library Cache Latch的争用。和Shared Pool Latch一样,一旦发生大量的Library Cache Latch的争用,系统的性能和可扩展性也会受到严重影响。这里需要注意的是,从11gR1开始,Oracle用Mutex替换了库缓存相关Latch,所以在Oracle 11gR1及其后续的版本中,将不再存在库缓存相关Latch的争用,取而代之的是Mutex的争用(你可以简单地将Mutex理解成是一种轻量级的Latch,Mutex主要也是用于共享SGA内存结构的并发访问控制),Oracle也因此引入了一系列新的等待事件来描述这种Mutex的争用,比如“Cursor:pinS”、“Cursor:pinX”、“Cursor:pin S wait on X”、"Cursor:mutex S'、“Cursor:mutex X”、“Library cache:mutex X”等。
正是因为大量的硬解析可能会导致Shared Pool Latch、库缓存相关Latch/Mutex的争用,进而会严重影响系统的性能和可扩展性,所以才有“硬解析是万恶之源”这样的说法,但实际上,这种说法是不准确的。硬解析是非常不好,它的危害性也有目共睹,但硬解析是否会对系统造成损坏实际上取决于系统的类型,对于高并发的OLTP类型的系统而言,硬解析确实会严重影响系统的性能和可扩展性;但对于OLAP/DSS类型的系统而言,并发的数量很少,目标SQL也很少被并发重复执行,而且在执行目标SQL时硬解析所耗费的时间和资源与该SQL总的执行时间和资源消耗相比是微不足道的,这种情况下用硬解析是没问题的,此时硬解析对系统性能的影响微乎其微,可以忽略不计。所以更为准确的说法应该是一一对于OLTP类型的系统而言,硬解析是万恶之源!
(二)软解析(Soft Parse)
软解析(Soft Parse)是指Oracle在执行目标SQL时,在Library Cache中找到了匹配的父游标(Parent Cursor)和子游标(Child Cursor),并将存储在子游标中的解析树和执行计划直接拿过来重用而无须从头开始解析的过程。和硬解析相比,软解析的优势主要体现在如下这几个方面:
(1)软解析不会导致Shared Pool Latch的争用。因为软解析能够在库缓存中找到匹配的Parent Cursor和Child Cursor,所以它不需要生成新的Parent Cursor和Child Cursor.这意味着软解析根本就不需要持有Shared Pool Latch以便在Shared Pool中申请分配一块共享内存区域,既然不需要持有Shared Pool Latch,自然不会有Shared Pool Latch的争用,即Shared Pool Latch的争用所带来的系统性能和可扩展性的问题对软解析来说并不存在。
(2)软解析虽然也可能会导致库缓存相关Latch(如Library Cache Latch)和Mutex的争用,但软解析持有库缓存相关Latch的次数要少,而且软解析对某些Latch(如Library Cache Latch)的持有时间会比硬解析短,这意味着即使产生了库缓存相关Latch的争用,软解析的争用程度也没有硬解析那么严重,即库缓存相关Latch和Mutex的争用所带来的系统性能和可扩展性的问题对软解析来说要比硬解析少很多。我们在3.1.12节中己经介绍过:硬解析会先持有LibraryCacheLatch,并且在不释放LibraryCacheLatch的情况下持有Shared Pool Latch以便从Shared Pool中申请分配内存,成功申请后就会释放Shared Pool Latch,最后再释放Library Cache Latch。而软解析是不需要持有Shared Pool Latch的,所以与软解析比起来,硬解析持有Library Cache Latch的时间会更长,当然对Library Cache Latch争用的程度就会更严重。
正是基于上述两个方面的原因,如果OLTP类型的系统在执行目标SQL时能够广泛使用软解析,那么系统的性能和可扩展性就会比全部使用硬解析时有显著的提升,执行目标SQL时需要消耗的系统资源(主要体现在CPU上)也会显著降低。
(三)软软解析(Soft Soft Parse)
软软解析(Soft Soft Parse)是指若参数SESSION_CACHED_CURSORS的值大于0,并且该会话游标所对应的目标SQL解析和执行的次数超过3次,则此时该会话游标会被直接缓存在当前会话的PGA中的。若该SQL再次执行的时候,则只需要对其进行语法分析、权限对象分析之后就可以直接从当前会话的PGA中将之前缓存的匹配会话游标直接拿过来用就可以了,这就是软软解析。
当一个SQL语句以硬解析的方式解析和执行完毕后,这个目标SQL所对应的共享游标(Shared Cursor)就己经被缓存在库缓存中,它所对应的会话游标(Session Cursor)也已使用完毕,这时候会根据参数SESSION_CACHED_CURSORS的不同而存在如下这两种情况:
① 如果参数SESSION_CACHED_CURSORS的值等于0,那么会话游标就会正常执行Close操作。在这种情况下,当同一条目标SQL再次重复执行时(显然是软解析),此时是可以找到匹配的共享游标的,但依然找不到匹配的会话游标(因为之前硬解析时对应的会话游标己经被Close掉了),这意味着Oracle还必须为该SQL新生成一个会话游标,并且该会话游标还会再经历一次Open、Parse、Bind、Execute、Fetch和Close中的一个或多个阶段。
② 如果参数SESSION_CACHED_CURSORS的值大于0,并且该会话游标所对应的目标SQL解析和执行的次数超过3次,那么Oracle就不会对会话游标执行Close操作,而是会将其标记为Soft Closed,同时将其缓存在当前会话的PGA中。这样做的好处是,当目标SQL再次被重复执行时,此时共享游标和会话游标就都能够找到匹配记录了,这意味着Oracle己经不需要为该SQL再新生成一个会话游标,而是只需要从当前会话的PGA中将之前己经被标记为Soft Closed的匹配会话游标直接拿过来用就可以了。显然,和软解析比,此时Oracle就省掉了Open一个新的会话游标所需要耗费的资源和时间。另外,Close一个现有会话游标也不需要做了(只需要将其标记为Soft Closed,同时将其缓存在当前会话的PGA中就可以了)。当然,剩下的Parse、Bind、Execute、Fetch还是需要做的,这个过程就是所谓的“软软解析”。
从上述分析过程可以看出,软软解析与软解析比起来,其好处主要体现在如下两个方面:
① 和软解析比,软软解省去了OPEN一个新的会话游标和CLOSE一个现有会话游标所需要耗费的资源和时间。
② 和软解析比,软软解析在持有库缓存相关Latch的次数方面会更少。这是因为缓存在PGA中的会话游标所在的Hash Bucket中己经存储了目标SQL的父游标的库缓存对象句柄地址,Oracle根据这个库缓存对象句柄地址就可以直接去库缓存中访问对应的父游标了,而不再需要先持有库缓存相关Latch,再去库缓存的相应Hash Bucket的父游标所在的库缓存对象句柄链表中查找匹配的父游标了,所以软软解析在持有库缓存相关Latch的次数方面会比软解析要少。
如果要彻底搞懂硬解析、软解析和软软解析,那么请阅读崔华大师的书 《基于Oracle的SQL优化 》!!!小麦苗把里边的一些重点内容摘抄出来,共享给大家。
当客户端进程,将SQL语句通过监听器发送到Oracle时, 会触发一个Server process生成,来对该客户进程服务。Server process得到SQL语句之后,对SQL语句进行Hash运算,然后根据Hash值到library cache中查找,如果存在,则直接将library cache中的缓存的执行计划拿来执行,最后将执行结果返回该客户端,这种SQL解析叫做软解析;如果不存在,则会对该SQL进行解析parse,然后执行,返回结果,这种SQL解析叫做硬解析。
1. 硬解析 的步骤
硬解析一般包括下面几个过程:
1)对SQL语句进行 语法检查 ,看是否有语法错误。比如select from where 等的拼写错误,如果存在语法错误,则退出解析过程;
2)通过数据字典(row cache),检查SQL语句中涉及的 对象和列是否存在 。如果不存在,则退出解析过程。
3)检查SQL语句的用户是否对涉及到的对象 是否有权限 。如果没有则退出解析;
4)通过优化器创建一个最优的 执行计划 。这个过程会根据数据字典中的对象的统计信息,来计算多个执行计划的cost,从而得到一个最优的执行计划。这一步涉及到大量的数据运算,从而会消耗大量的CPU资源;(library cache最主要的目的就是通过软解析来减少这个步骤);
5)将该游标所产生的执行计划,SQL文本等 装载 进library cache中的heap中。
2. 软解析
所谓软解析,就是因为相同文本的SQL语句存在于library cache中,所以本次SQL语句的解析就可以去掉硬解析中的一个活多个步骤。从而节省大量的资源的耗费。
3. 软软解析
所谓的软软解析,就是不解析。当设置了 session_cached_cursors 参数时,当某个session第三次执行相同的SQL语句时,则会把该SQL语句的游标信息转移到该session的PGA中。这样,当该session在执行该SQL语句时,会直接从PGA中取出执行计划,从而跳过硬解析的所有步骤。
SQL> show parameter cursor;
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
cursor_sharing string EXACT
cursor_space_for_time boolean FALSE
open_cursors integer 300
session_cached_cursors integer 20
open_cursors设定每个session(会话)最多能够同时打开多少个cursors(游标)。
================================================
摘自:http://www.itpub.net/thread-796685-1-1.html
SESSION_CACHED_CURSORS的值就是说的是一个session可以缓存多少个cursor,让后续相同的SQL语句不再打开游标,从而避免软解析的过程来提高性能。(绑定变量是解决硬解析的问题),软解析同硬解析一样,比较消耗资源.所以这个参数非常重要。
oracle有一个概念,那就是session cursor cache,中文描述就是有一块内存区域,用来存储关闭了的cursor。当一个cursor关闭之后,oracle会检查这个cursor的request次数是否超过3次,如果超过了三次,就会放入session cursor cache,这样在下次parse的时候,就可以从session cursor cache中找到这个statement, session cursor cache的管理也是使用LRU。
session_cached_cursors这个参数是控制session cursor cache的大小的。session_cached_cursors定义了session cursor cache中存储的cursor的个数。这个值越大,则会消耗的内存越多。
另外检查这个参数是否设置的合理,可以从两个statistic来检查。
SQL> select name,value from v$sysstat where name like '%cursor%' ;
NAME VALUE
---------------------------------------------------------------- ----------
opened cursors cumulative 16439
opened cursors current 55
session cursor cache hits 8944
session cursor cache count 101
cursor authentications 353
SQL> select name,value from v$sysstat where name like '%parse%' ;
NAME VALUE
---------------------------------------------------------------- ----------
parse time cpu 0
parse time elapsed 0
parse count ( total ) 17211
parse count ( hard ) 1128
parse count (failures) 2
parse count(total)就是总的parse次数中,session cursor cache hits就是在session cursor cache中找到的次数,所占比例越高,性能越好。如果比例比较低,并且有剩余内存的话,可以考虑加大该参数。
Oracle 9i及以前,该参数缺省是0,10G上缺省是20,11g上默认为50
Oracle 硬解析与软解析
--=======================
-- Oracle 硬解析与软解析
--=======================
Oracle 硬解析与软解析是我们经常遇到的问题,什么情况会产生硬解析,什么情况产生软解析,又当如何避免硬解析?下面的描述将给出
软硬解析的产生,以及硬解析的弊端和如何避免硬解析的产生。
一、SQL语句的执行过程
当发布一条SQL或PL/SQL命令时,Oracle会自动寻找该命令是否存在于共享池中来决定对当前的语句使用硬解析或软解析。
通常情况下,SQL语句的执行过程如下:
a.SQL代码的语法(语法的正确性)及语义检查(对象的存在性与权限)。
b.将SQL代码的文本进行哈希得到哈希值。
c.如果共享池中存在相同的哈希值,则对这个命令进一步判断是否进行软解析,否则到e步骤。
d.对于存在相同哈希值的新命令行,其文本将与已存在的命令行的文本逐个进行比较。这些比较包括大小写,字符串是否一致,空格,注释
等,如果一致,则对其进行软解析,转到步骤f。否则到d步骤。红色字体描述有误应该转到步骤e(更正@20130905,谢网友keaihuilang指出)
e.硬解析,生成执行计划。
f.执行SQL代码,返回结果。
二、不能使用软解析的情形
1.下面的三个查询语句,不能使用相同的共享SQL区。尽管查询的表对象使用了大小写,但Oracle为其生成了不同的执行计划
select * from emp;
select * from Emp;
select * from EMP;
2.类似的情况,下面的查询中,尽管其where子句empno的值不同,Oracle同样为其生成了不同的执行计划
select * from emp where empno=7369
select * from emp where empno=7788
3.在判断是否使用硬解析时,所参照的对象及schema应该是相同的,如果对象相同,而schema不同,则需要使用硬解析,生成不同的执行计划
sys@ASMDB> select owner,table_name from dba_tables where table_name like 'TB_OBJ%';
OWNER TABLE_NAME
------------------------------ ------------------------------
USR1 TB_OBJ --两个对象的名字相同,当所有者不同
SCOTT TB_OBJ
usr1@ASMDB> select * from tb_obj;
scott@ASMDB> select * from tb_obj; --此时两者都需要使用硬解析以及走不同的执行计划
三、硬解析的弊端
硬解析即整个SQL语句的执行需要完完全全的解析,生成执行计划。而硬解析,生成执行计划需要耗用CPU资源,以及SGA资源。在此不
得不提的是对库缓存中闩的使用。闩是锁的细化,可以理解为是一种轻量级的串行化设备。当进程申请到闩后,则这些闩用于保护共享内存
的数在同一时刻不会被两个以上的进程修改。在硬解析时,需要申请闩的使用,而闩的数量在有限的情况下需要等待。大量的闩的使用由此
造成需要使用闩的进程排队越频繁,性能则逾低下。
四、硬解析的演示
下面对上面的两种情形进行演示
在两个不同的session中完成,一个为sys帐户的session,一个为scott账户的session,不同的session,其SQL命令行以不同的帐户名开头
如" sys@ASMDB> " 表示使用时sys帐户的session," scott@ASMDB> "表示scott帐户的session
sys@ASMDB> select name,class,value from v$sysstat where statistic#=331;
NAME CLASS VALUE
-------------------- ---------- ---------- --当前的硬解析值为569
parse count (hard) 64 569
scott@ASMDB> select * from emp;
sys@ASMDB> select name,class,value from v$sysstat where statistic#=331;
NAME CLASS VALUE
-------------------- ---------- ---------- --执行上一个查询后硬解析值为570,解析次数增加了一次
parse count (hard) 64 570
scott@ASMDB> select * from Emp;
sys@ASMDB> select name,class,value from v$sysstat where statistic#=331;
NAME CLASS VALUE
-------------------- ---------- ---------- --执行上一个查询后硬解析值为571
parse count (hard) 64 571
scott@ASMDB> select * from EMP;
sys@ASMDB> select name,class,value from v$sysstat where statistic#=331;
NAME CLASS VALUE
-------------------- ---------- ---------- --执行上一个查询后硬解析值为572
parse count (hard) 64 572
scott@ASMDB> select * from emp where empno=7369;
sys@ASMDB> select name,class,value from v$sysstat where statistic#=331;
NAME CLASS VALUE
-------------------- ---------- ---------- --执行上一个查询后硬解析值为573
parse count (hard) 64 573
scott@ASMDB> select * from emp where empno=7788; --此处原来empno=7369,复制错误所致,现已更正为7788@20130905
sys@ASMDB> select name,class,value from v$sysstat where statistic#=331;
NAME CLASS VALUE
-------------------- ---------- ---------- --执行上一个查询后硬解析值为574
parse count (hard) 64 574
从上面的示例中可以看出,尽管执行的语句存在细微的差别,但Oracle还是为其进行了硬解析,生成了不同的执行计划。即便是同样的SQL
语句,而两条语句中空格的多少不一样,Oracle同样会进行硬解析。
五、编码硬解析的改进方法
1.更改参数cursor_sharing
参数cursor_sharing决定了何种类型的SQL能够使用相同的SQL area
CURSOR_SHARING = { SIMILAR | EXACT | FORCE }
EXACT --只有当发布的SQL语句与缓存中的语句完全相同时才用已有的执行计划。
FORCE --如果SQL语句是字面量,则迫使Optimizer始终使用已有的执行计划,无论已有的执行计划是不是最佳的。
SIMILAR --如果SQL语句是字面量,则只有当已有的执行计划是最佳时才使用它,如果已有执行计划不是最佳则重新对这个SQL
--语句进行分析来制定最佳执行计划。
可以基于不同的级别来设定该参数,如ALTER SESSION, ALTER SYSTEM
sys@ASMDB> show parameter cursor_shar --查看参数cursor_sharing
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
cursor_sharing string EXACT
sys@ASMDB> alter system set cursor_sharing='similar'; --将参数cursor_sharing的值更改为similar
sys@ASMDB> select name,class,value from v$sysstat where statistic#=331;
NAME CLASS VALUE
-------------------- ---------- ---------- --当前硬解析的值为865
parse count (hard) 64 865
scott@ASMDB> select * from dept where deptno=10;
sys@ASMDB> select name,class,value from v$sysstat where statistic#=331;
NAME CLASS VALUE
-------------------- ---------- ---------- --执行上一条SQL查询后,硬解析的值变为866
parse count (hard) 64 866
scott@ASMDB> select * from dept where deptno=20;
sys@ASMDB> select name,class,value from v$sysstat where statistic#=331;
NAME CLASS VALUE
-------------------- ---------- ---------- --执行上一条SQL查询后,硬解析的值没有发生变化还是866
parse count (hard) 64 866
sys@ASMDB> select sql_text,child_number from v$sql -- 在下面的结果中可以看到SQL_TEXT列中使用了绑定变量:"SYS_B_0"
2 where sql_text like 'select * from dept where deptno%';
SQL_TEXT CHILD_NUMBER
-------------------------------------------------- ------------
select * from dept where deptno=:"SYS_B_0" 0
sys@ASMDB> alter system set cursor_sharing='exact'; --将cursor_sharing改回为exact
--接下来在scott的session 中执行deptno=40 和的查询后再查看sql_text,当cursor_sharing改为exact后,每执行那个一次
--也会在v$sql中增加一条语句
sys@ASMDB> select sql_text,child_number from v$sql
2 where sql_text like 'select * from dept where deptno%';
SQL_TEXT CHILD_NUMBER
-------------------------------------------------- ------------
select * from dept where deptno=50 0
select * from dept where deptno=40 0
select * from dept where deptno=:"SYS_B_0" 0
注意当该参数设置为similar,会产生不利的影响,可以参考这里:cursor_sharing参数对于expdp的性能影响
2.使用绑定变量
绑定变量要求变量名称,数据类型以及长度是一致,否则无法使用软解析
绑定变量(bind variable)是指在DML语句中使用一个占位符,即使用冒号后面紧跟变量名的形式,如下
select * from emp where empno=7788 --未使用绑定变量
select * from emp where empono=:eno --:eno即为绑定变量
在第二个查询中,变量值在查询执行时被提供。该查询只编译一次,随后会把查询计划存储在一个共享池(库缓存)中,以便以后获取
和重用这个查询计划。
下面使用了绑定变量,但两个变量其实质是不相同的,对这种情形,同样使用硬解析
select * from emp where empno=:eno;
select * from emp where empno=:emp_no
使用绑定变量时要求不同的会话中使用了相同的回话环境,以及优化器的规则等。
使用绑定变量的例子(参照了TOM大师的Oracle 9i&10g编程艺术)
scott@ASMDB> create table tb_test(col int); --创建表tb_test
scott@ASMDB> create or replace procedure proc1 --创建存储过程proc1使用绑定变量来插入新记录
2 as
3 begin
4 for i in 1..10000
5 loop
6 execute immediate 'insert into tb_test values(:n)' using i;
7 end loop;
8 end;
9 /
Procedure created.
scott@ASMDB> create or replace procedure proc2 --创建存储过程proc2,未使用绑定变量,因此每一个SQL插入语句都会硬解析
2 as
3 begin
4 for i in 1..10000
5 loop
6 execute immediate 'insert into tb_test values('||i||')';
7 end loop;
8 end;
9 /
Procedure created.
scott@ASMDB> exec runstats_pkg.rs_start
PL/SQL procedure successfully completed.
scott@ASMDB> exec proc1;
PL/SQL procedure successfully completed.
scott@ASMDB> exec runstats_pkg.rs_middle;
PL/SQL procedure successfully completed.
scott@ASMDB> exec proc2;
PL/SQL procedure successfully completed.
scott@ASMDB> exec runstats_pkg.rs_stop(1000);
Run1 ran in 1769 hsecs
Run2 ran in 12243 hsecs --run2运行的时间是run1的/1769≈倍
run 1 ran in 14.45% of the time
Name Run1 Run2 Diff
LATCH.SQL memory manager worka 410 2,694 2,284
LATCH.session allocation 532 8,912 8,380
LATCH.simulator lru latch 33 9,371 9,338
LATCH.simulator hash latch 51 9,398 9,347
STAT...enqueue requests 31 10,030 9,999
STAT...enqueue releases 29 10,030 10,001
STAT...parse count (hard) 4 10,011 10,007 --硬解析的次数,前者只有四次
STAT...calls to get snapshot s 55 10,087 10,032
STAT...parse count (total) 33 10,067 10,034
STAT...consistent gets 247 10,353 10,106
STAT...consistent gets from ca 247 10,353 10,106
STAT...recursive calls 10,474 20,885 10,411
STAT...db block gets from cach 10,408 30,371 19,963
STAT...db block gets 10,408 30,371 19,963
LATCH.enqueues 322 21,820 21,498 --闩的队列数比较
LATCH.enqueue hash chains 351 21,904 21,553
STAT...session logical reads 10,655 40,724 30,069
LATCH.library cache pin 40,348 72,410 32,062 --库缓存pin
LATCH.kks stats 8 40,061 40,053
LATCH.library cache lock 318 61,294 60,976
LATCH.cache buffers chains 51,851 118,340 66,489
LATCH.row cache objects 351 123,512 123,161
LATCH.library cache 40,710 234,653 193,943
LATCH.shared pool 20,357 243,376 223,019
Run1 latches total versus runs -- difference and pct
Run1 Run2 Diff Pct
157,159 974,086 816,927 16.13% --proc2使用闩的数量也远远多于proc1,其比值是.13%
PL/SQL procedure successfully completed.
由上面的示例可知,在未使用绑定变量的情形下,不论是解析次数,闩使用的数量,队列,分配的内存,库缓存,行缓存远远高于绑定
变量的情况。因此尽可能的使用绑定变量避免硬解析产生所需的额外的系统资源。
绑定变量的优点
减少SQL语句的硬解析,从而减少因硬解析产生的额外开销(CPU,Shared pool,latch)。其次提高编程效率,减少数据库的访问次数。
绑定变量的缺点
优化器就会忽略直方图的信息,在生成执行计划的时候可能不够优化。SQL优化相对比较困难
六、总结
1.尽可能的避免硬解析,因为硬解析需要更多的CPU资源,闩等。
2.cursor_sharing参数应权衡利弊,需要考虑使用similar与force带来的影响。
3.尽可能的使用绑定变量来避免硬解析。
父游标、子游标及共享游标
游标是数据库领域较为复杂的一个概念,因为游标包含了shared cursor和session cursor。两者有其不同的概念,也有不同的表现形式。共享游标的概念易于与SQL语句中定义的游标相混淆。本文主要描述解析过程中的父游标,子游标以及共享游标,即shared cursor,同时给出了游标(session cursor)的生命周期以及游标的解析过程的描述。
有关游标的定义,声明,与使用请参考:PL/SQL 游标
有关硬解析与软解析请参考:Oracle 硬解析与软解析
一、相关定义
shared cursor
也即是共享游标,是SQL语句在游标解析阶段生成获得的,是位于library cache中的sql或匿名的pl/sql等。其元数据被在视图V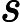

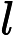
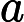
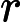
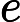 与
与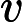 �������与�sql中具体化。如果library cache中的父游标与子游标能够被共享,此时则为共享游标。父游标能够共享即为共享的父游标,子游标能够共享极为共享的子游标。
�������与�sql中具体化。如果library cache中的父游标与子游标能够被共享,此时则为共享游标。父游标能够共享即为共享的父游标,子游标能够共享极为共享的子游标。
session cursor
即通过系统为用户分配缓冲区用于存放SQL语句的执行结果。用户可以通过这个中间缓冲区逐条取出游标中的记录并对其处理,直到所有的游标记录被逐一处理完毕。session cursor指的跟这个session相对应的server process的PGA里(准确的说是UGA)的一块内存区域(或者说内存结构)即其主要特性表现在记录的逐条定位,逐条处理。session cursor的元数据通过v$open_cursor视图来具体化。每一个打开或解析的SQL都将位于该视图。
二、游标的生命周期(session cursor)
session cursor需要从UGA中分配内存,因此有其生命周期。其生命周期主要包括:
打开游标(根据游标声明的名称在UGA中分配内存区域)
解析游标(将SQL语句与游标关联,并将其执行计划加载到Library Cache)
定义输出变量(仅当游标返回数据时)
绑定输入变量(如果与游标关联的SQL语句使用了绑定变量)
执行游标(即执行SQL语句)
获取游标(即获取SQL语句记录结果,根据需要对记录作相应操作。游标将逐条取出查询的记录,直到取完所有记录)
关闭游标(释放UGA中该游标占有的相关资源,但Library Cache中的游标的执行计划按LRU原则清除,为其游标共享提供可能性)
对于session cursor而言,可以将游标理解为任意的DML,DQL语句(个人理解,有待核实)。即一条SQL语句实际上就是一个游标,只不过session cursor分为显示游标和隐式游标,以及游标指针。由上面游标的生命周期可知,任何的游标(SQL语句)都必须经历内存分配,解析,执行与关闭的过程。故对隐式游标而言,生命周期的所有过程由系统来自动完成。对所有的DML和单行查询(select ... into ...)而言,系统自动使用隐式游标。多行结果集的DQL则通常使用显示游标。
二、游标的解析过程(产生shared cursor)
解析过程:
A、包含vpd的约束条件:
SQL语句如果使用的表使用了行级安全控制,安全策略生成的约束条件添加到where子句中
B、语法、语义、访问权限检查:
检查SQL语句书写的正确性,对象存在性,用户的访问权限
C、父游标缓存:
将该游标(SQL语句)的文本进行哈希得到哈希值并在library cache寻找相同的哈希值,如不存在则生存父游标且保存在library cache中,按顺序完成D-F步骤。如果此时存在父游标,则进一步判断是否存在子游标。若存在相同的子游标,则直接调用其子游标的执行计划执行该SQL语句,否则转到步骤D进行逻辑优化
D、逻辑优化:
使用不同的转换技巧,生成语义上等同的新的SQL语句(SQL语句的改写),一旦该操作完成,则执行计划数量、搜索空间将会相应增长。其主要目的未进行转换的情况下是寻找无法被考虑到的执行计划
E、物理优化:
为逻辑优化阶段的SQL语句产生执行计划,读取数据字典中的统计信息以及动态采样的统计信息,计算开销,开销最低的执行计划将被选中。
F、子游标缓存:
分配内存,生成子游标(即最佳执行计划),与父游标关联。可以在v �������,�sql得到具体游标信息,父子游标通过sql_id关联对于仅仅完成步骤A与B的SQL语句即为软解析,否则即为硬解析
�������,�sql得到具体游标信息,父子游标通过sql_id关联对于仅仅完成步骤A与B的SQL语句即为软解析,否则即为硬解析
三、shared cursor与session cursor的关系以及软软解析
关系:
一个session cursor只能对应一个shared cursor,而一个shared cursor却可能同时对应多个session cursor
四、父游标与子游标、共享游标
由游标的解析过程可知,父游标,子游标同属于共享游标的范畴。
父游标
是在进行硬解析时产生的,父游标里主要包含两种信息:SQL文本以及优化目标(optimizer goal),首次打开父游标被锁定,直到其他所有的session都关闭该游标后才被解锁。当父游标被锁定的时候是不能被LRU算法置换出library cache,只有在解锁以后才能置换出library cache,此时该父游标对应的所有子游标也同样被置换出library cache。v中的每一行代表了一个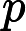
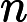
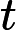
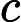
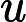
 ,
,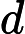 表示其内存地址。子游标当发生硬解析时,在产生父游标的同时,则跟随父游标会产生相应的子游标,此时
表示其内存地址。子游标当发生硬解析时,在产生父游标的同时,则跟随父游标会产生相应的子游标,此时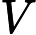 �������中的每一行代表了一个������������,�������表示其内存地址。子游标当发生硬解析时,在产生父游标的同时,则跟随父游标会产生相应的子游标,此时�SQL.CHILD_NUMBER的值为0。
�������中的每一行代表了一个������������,�������表示其内存地址。子游标当发生硬解析时,在产生父游标的同时,则跟随父游标会产生相应的子游标,此时�SQL.CHILD_NUMBER的值为0。
如果存在父游标,由于不同的运行环境,此时同样会产生新的子游标,新子游标的CHILD_NUMBER在已有子游标基础上以1为单位累计。
子游标包括游标所有相关信息,如具体的执行计划、绑定变量,OBJECT和权限,优化器设置等。子游标随时可以被LRU算法置换出library cache,当子游标被置换出library cache时,oracle可以利用父游标的信息重新构建出一个子游标来,这个过程叫reload。
v中中的每一行表示了一个
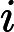 ,根据和与关联。有自己的,即���中中的每一行表示了一个�ℎ���������,根据ℎ��ℎ�����和�������与������������关联。�ℎ���������有自己的�������,即�sql.child_address。
,根据和与关联。有自己的,即���中中的每一行表示了一个�ℎ���������,根据ℎ��ℎ�����和�������与������������关联。�ℎ���������有自己的�������,即�sql.child_address。
确定一个游标的三个主要字段:address,hash_value,child_number,
五、演示父游标、子游标
[sql] view plain copy print ?- /************************************ 首先创建表 t **************************************/
- SQL> create table t as select empno,ename,sal from emp where deptno=10;
- Table created.
- *********************************** 对表进行查询 *****************************************/
- SQL> select * from t where empno=7782;
- EMPNO ENAME SAL
- ---------- ---------- ----------
- 7782 CLARK 2450
- SQL> SELECT * from t where empno=7782;
- EMPNO ENAME SAL
- ---------- ---------- ----------
- 7782 CLARK 2450
- SQL> SELECT * FROM t WHERE empno=7782;
- EMPNO ENAME SAL
- ---------- ---------- ----------
- 7782 CLARK 2450
- SQL> select * from t where empno=7782;
- EMPNO ENAME SAL
- ---------- ---------- ----------
- 7782 CLARK 2450
- /*********************由下面的查询(v$sqlarea)可知产生了3个父游标,其中一个父游标(2r6rbdp92kyh9)执行了2次 ************/
- /**************************************************/
- /* Author: Robinson Cheng */
- /* Blog: http://blog.csdn.net/robinson_0612 */
- /* MSN: [email protected] */
- /* QQ: 645746311 */
- /**************************************************/
- SQL> col sql_text format a40
- SQL> select sql_id,sql_text,executions from v$sqlarea
- 2 where sql_text like '%empno=7782%' and sql_text not like '%from v$sqlarea%';
- SQL_ID SQL_TEXT EXECUTIONS
- ------------- ---------------------------------------- ----------
- 4rs2136z084y1 SELECT * from t where empno=7782 1
- 84w067b4n91h5 SELECT * FROM t WHERE empno=7782 1
- 2r6rbdp92kyh9 select * from t where empno=7782 2
- /************上面3个父游标对应的子游标可以在v$sql中获得 *******************/
- SQL> select sql_id,hash_value,child_number,plan_hash_value,sql_text,executions from v$sql
- 2 where sql_text like '%empno=7782%' and sql_text not like '%from v$sql%';
- SQL_ID HASH_VALUE CHILD_NUMBER PLAN_HASH_VALUE SQL_TEXT EXECUTIONS
- ------------- ---------- ------------ --------------- ---------------------------------------- ----------
- 4rs2136z084y1 3187938241 0 1601196873 SELECT * from t where empno=7782 1
- 84w067b4n91h5 3376711173 0 1601196873 SELECT * FROM t WHERE empno=7782 1
- 2r6rbdp92kyh9 1378449929 0 1601196873 select * from t where empno=7782 2
- /******************调整optimizer_index_caching 参数并执行聚合查询 ************************/
- SQL> alter session set optimizer_index_caching=40;
- Session altered.
- SQL> select sum(sal) from t;
- SUM(SAL)
- ----------
- 8750
- SQL> alter session set optimizer_index_caching=100;
- Session altered.
- SQL> select sum(sal) from t;
- SUM(SAL)
- ----------
- 8750
- /***************相同的查询由于不同的运行环境导致产生了不同的子游标,optimizer_env_hash_value值不同 **************/
- /***************不同的子游标有不同的child_address 值 ****************************/
- SQL> select sql_id, child_number, sql_text,optimizer_env_hash_value oehv,child_address
- 2 from v$sql where sql_text like '%sum(sal)%' and sql_text not like '%from v$sql%';
- SQL_ID CHILD_NUMBER SQL_TEXT OEHV CHILD_ADDRESS
- ------------- ------------ ---------------------------------------- ---------- ----------------
- gu68ka2qzx3hh 0 select sum(sal) from t 3620536549 0000000093696D00
- gu68ka2qzx3hh 1 select sum(sal) from t 2687219005 0000000093767F58
- /********** 查询v$sql_shared_cursor可以跟踪是那些变化导致了子游标不能共享,此例为optimizer_mismatch *****************/
- SQL> SELECT child_number, optimizer_mismatch
- 2 FROM v$sql_shared_cursor
- 3 WHERE sql_id = '&sql_id';
- Enter value for sql_id: gu68ka2qzx3hh
- old 3: WHERE sql_id = '&sql_id'
- new 3: WHERE sql_id = 'gu68ka2qzx3hh'
- CHILD_NUMBER O
- ------------ -
- 0 N
- 1 Y
- /***********************观察父游标address,hash_value,sql_id ******************/
- /***********************观察子游标address,hash_value,child_number,sql_id,child_address ******************/
- /************************从Oracle 10g 之后,sql_id既可以唯一确定一个父游标,sql_id,child_number唯一确定一个子游标*****/
- SQL> SELECT address,hash_value,sql_id FROM v$sqlarea WHERE sql_id='gu68ka2qzx3hh';
- ADDRESS HASH_VALUE SQL_ID
- ---------------- ---------- -------------
- 000000009F8CBB58 2919140880 gu68ka2qzx3hh
- SQL> SELECT address,hash_value,child_number, sql_id,child_address
- 2 FROM v$sql WHERE sql_id='gu68ka2qzx3hh';
- ADDRESS HASH_VALUE CHILD_NUMBER SQL_ID CHILD_ADDRESS
- ---------------- ---------- ------------ ------------- ----------------
- 000000009F8CBB58 2919140880 0 gu68ka2qzx3hh 0000000093696D00
- 000000009F8CBB58 2919140880 1 gu68ka2qzx3hh 0000000093767F58
六、总结
1、硬解析通常是由于不可共享的父游标造成的,如经常变动的SQL语句,或动态SQL或未使用绑定变量等
2、解决硬解析的办法则通常是使用绑定变量来解决
3、与父游标SQL文本完全一致的情形下,多个相同的SQL语句可以共享一个父游标
4、SQL文本、执行环境完全一致的情形下,子游标能够被共享,否则如果执行环境不一致则生成新的子游标
怎么找出解析失败的SQL语句?
很多时候我们会有这样一个误区,语法错误或者对象不存在应该在语法语义检查这个步骤就结束了,怎么还会存在共享池里面呢?带着这个几个问题我们做几个简单的测试。
我们先了解下什么是解析失败的 SQL?
1、SQL语法错误
2、访问的对象不存在
3、没有权限
那么怎么证明有哪些解析失败的SQL
我们知道 SQL 语句必须至少是一个父游标一个子游标存在的,当然生产中很多情况下都是一父多子的情况。
父游标与子游标结构是一样的,区别在于sql解析相关信息存储在父游标对应的heap 0中,而sql的执行计划等信息存储在子
游标对应的库缓存对象heap 6内存空间中。另外父游标的 heap 0中存储着子游标的句柄地址。如果解析错误的SQL在共
享池中存储的话那么必然要产生一个父游标然后父游标里面存储的有相关的解析信息,但是子游标的?既然解析失败那么就
没有产生执行计划。
则利用这一点可以找到解析失败的语句。
父游标句柄对地址可以在 x$kglob 视图中查询到,KGLHDPAR=KGLHDADR 的记录为父游标,
而KGLHDPAR<>KGLHDADR为子游标
X$KGLOB
该视图定义为 [K]ernel[G]eneric [L]ibrary Cache Manager
KGLHDADR RAW(4|8) Address of kglhd for this object
可以看到:
KGLOBHD0 RAW(4|8) Address of heap 0 descriptor
KGLOBHD6 RAW(4|8) Address of heap 6 descriptor
SQL> select * from scott.emp;
SQL> col kglnaobj for a50;
SQL> select kglnaobj,kglnatim,kglhdpar,kglhdadr,KGLOBHD0,KGLOBHD6 from x$kglob where KGLNAOBJ='select * from scott.emp';
KGLNAOBJ KGLNATIM KGLHDPAR KGLHDADR KGLOBHD0 KGLOBHD6
-------------------------------------------------- ------------------- ---------------- ---------------- ---------------- ----------------
select * from scott.emp 2017-07-07 14:54:52 0000000096AE88B0 00000000958B9A40 0000000096AE85D8 000000007713C758
select * from scott.emp 2017-07-07 14:54:52 0000000096AE88B0 0000000096AE88B0 0000000095871858 00
x$kglcursor_child_sqlid (只包含子游标信息)
SQL> select kglnaobj,kglnatim,kglhdpar,kglhdadr,KGLOBHD0,KGLOBHD6 from x$kglcursor_child_sqlid where KGLNAOBJ='select * from scott.emp';
KGLNAOBJ KGLNATIM KGLHDPAR KGLHDADR KGLOBHD0 KGLOBHD6
-------------------------------------------------- ------------------- ---------------- ---------------- ---------------- ----------------
select * from scott.emp 2017-07-07 14:54:52 0000000096AE88B0 00000000958B9A40 0000000096AE85D8 000000007713C758
0000000096AE88B0 为select * from scott.emp; 父游标句柄地址,00000000958B9A40为子游标句柄地址
子游标heap 6(KGLOBHD6)的地址为000000007713C758,句柄中存储的也就是执行计划相关的信息。
通过以上测试我们很容易找到sql的父游标的句柄还有子游标的句柄在内存中的地址。
下面做另外一个简单的测试解析错误的SQL是否有父游标和子游标生成。
SQL> select * from test;
select * from test
*
ERROR at line 1:
ORA-00942: table or view does not exist
SQL> select kglnaobj,kglnatim,kglhdpar,kglhdadr,KGLOBHD0,KGLOBHD6 from x$kglob where KGLNAOBJ='select * from test';
KGLNAOBJ KGLNATIM KGLHDPAR KGLHDADR KGLOBHD0 KGLOBHD6
-------------------------------------------------- ------------------- ---------------- ---------------- ---------------- ----------------
select * from test 2017-07-07 15:06:28 0000000097DDC190 0000000097F941F8 00 00
select * from test 2017-07-07 15:06:28 0000000097DDC190 0000000097DDC190 000000009E035698 00
SQL> select kglnaobj,kglnatim,kglhdpar,kglhdadr,KGLOBHD0,KGLOBHD6 from x$kglcursor_child_sqlid where KGLNAOBJ='select * from test';
no rows selected
可以看到没有子游标生成,因为该SQL执行错误不会有执行计划相关信息。
从x$kglob 也可以查到 kglobhd0、kglobhd6 都为空(NULL)。
在 x
 视图也查不到任何信息的,����������ℎ���视图也查不到任何信息的,�sql v$sqlare 类似的视图也就查不到解析错误的 SQL 了。
视图也查不到任何信息的,����������ℎ���视图也查不到任何信息的,�sql v$sqlare 类似的视图也就查不到解析错误的 SQL 了。关于解析失败的SQL还是需要获取latch,其实从上面的测试已经证明了还是要获取 shared pool 的 latch的,因为生成了父游标。
通过以上测试说明解析失败的sql只生成了父游标,而没有生成子游标和执行计划信息。
也可以用一下sql查出当前数据库中所有解析失败的sql
select kglnaobj,kglnatim,kglhdpar,kglhdadr,KGLOBHD0,KGLOBHD6 from x$kglob where kglhdpar<>kglhdadr
and KGLOBHD6='00' and KGLOBHD0='00' order by kglnatim desc;
从整个过程来看即使解析失败父游标是需要分配空间的,如果没有使用绑定变量的情况下需要大量的分配
内存空间来保存这些解析失败语句的父游标,它不仅会持有latch:libary cache而且会持有latch:shared
pool.
最后猜测一下:
KGLNAOBJ KGLNATIM KGLHDPAR KGLHDADR KGLOBHD0 KGLOBHD6
-------------------------------------------------- ------------------- ---------------- ---------------- ---------------- ----------------
select * from scott.emp 2017-07-07 14:54:52 0000000096AE88B0 00000000958B9A40 0000000096AE85D8 000000007713C758
SQL> select ksmchptr,ksmchcom,ksmchcls,ksmchsiz from x$ksmsp where KSMCHPAR='0000000096AE85D8';
KSMCHPTR KSMCHCOM KSMCHCLS KSMCHSIZ
---------------- ------------------------------------------------ ------------------------ ----------
000000007713AFD8 KGLH0^31fa0cc recr 4096(chunk 大小)
如上:
KGLHDADR:应该为整个游标结构体(句柄)的虚拟内存地址其地址为00000000958B9A40
KGLHDPAR:为父游标构体(句柄的)的虚拟内存地址其地址为0000000096AE88B0
而父游标的KGLHDPAR和KGLHDADR相等,子游标KGLHDPAR为父游标构体(句柄的)的虚拟内存地址,KGLHDADR为自己的
游标构体(句柄的)的虚拟内存地址
在这个结构体中有一根指针指向void* p 指向heap 0 ds描述符的内存空间,虚拟内存地址为0000000096AE85D8
ds描述符:应该也是一个结构体其中又有一根指针void* p 指向heap 0实际的虚拟内存地址为000000007713AFD8
那么heap0实际的地址为000000007713AFD8
比如:
struct ds
{
KSMCHCOM;
KSMCHCLS;
KSMCHSIZ;
.........
void* p;
}
如果进行dump可以确实可以看到这根指针存储确实存储在内存中 标签:缓存,游标,转帖,会话,SQL,解析,select From: https://www.cnblogs.com/jinanxiaolaohu/p/17987283