什么是索引
- 索引是一种单独的、物理的对数据库表中一列或多列的值进行排序的一种存储结构, 为了优化数据库查询效率, 引入的数据结构,类似于书的目录
索引的分类
- 普通索引
-- 创建索引的基本语法
CREATE INDEX indexName ON table(column(length));
- 主键索引
- 联合索引
-- 创建索引的基本语法
CREATE INDEX indexName ON table(column1(length),column2(length));
- 唯一索引
有哪些数据结构可以作为索引
-
哈希表
-
把任意值(key)通过哈希函数变换为固定长度的 key 地址,通过这个地址进行具体数据的数据结构。
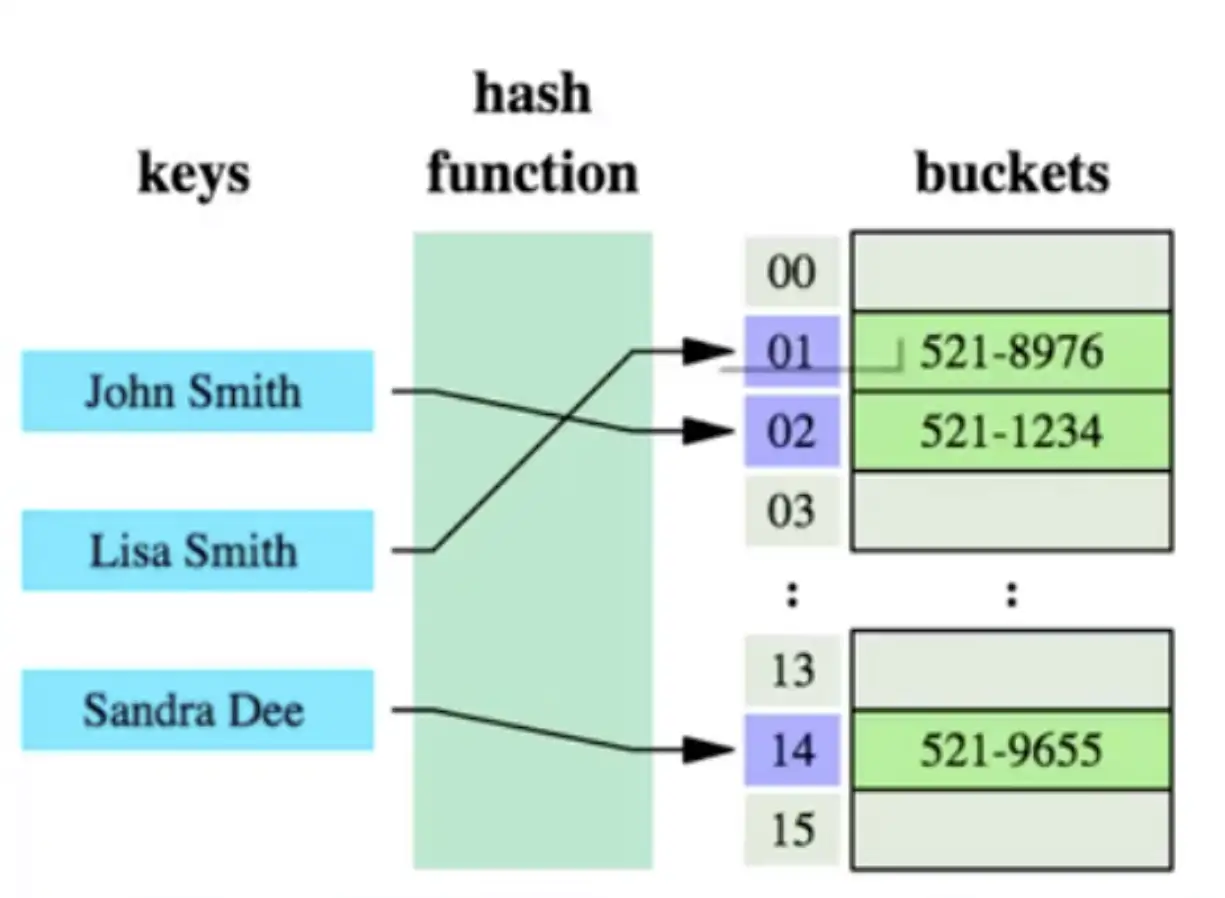
-
哈希算法首先计算存储 id=7 的数据的物理地址 addr=hash(7)=4231,而 4231 映射的物理地址是 0x77,0x77 就是 id=7 存储的额数据的物理地址,通过该独立地址可以找到对应 user_name='g'这个数据。这就是哈希算法快速检索数据的计算过程
-
但是哈希算法有个数据碰撞的问题,也就是哈希函数可能对不同的 key 会计算出同一个结果,比如 hash(7)可能跟 hash(199)计算出来的结果一样,也就是不同的 key 映射到同一个结果了,这就是碰撞问题。解决碰撞问题的一个常见处理方式就是链地址法,即用链表把碰撞的数据接连起来。计算哈希值之后,还需要检查该哈希值是否存在碰撞数据链表,有则一直遍历到链表尾,直达找到真正的 key 对应的数据为止
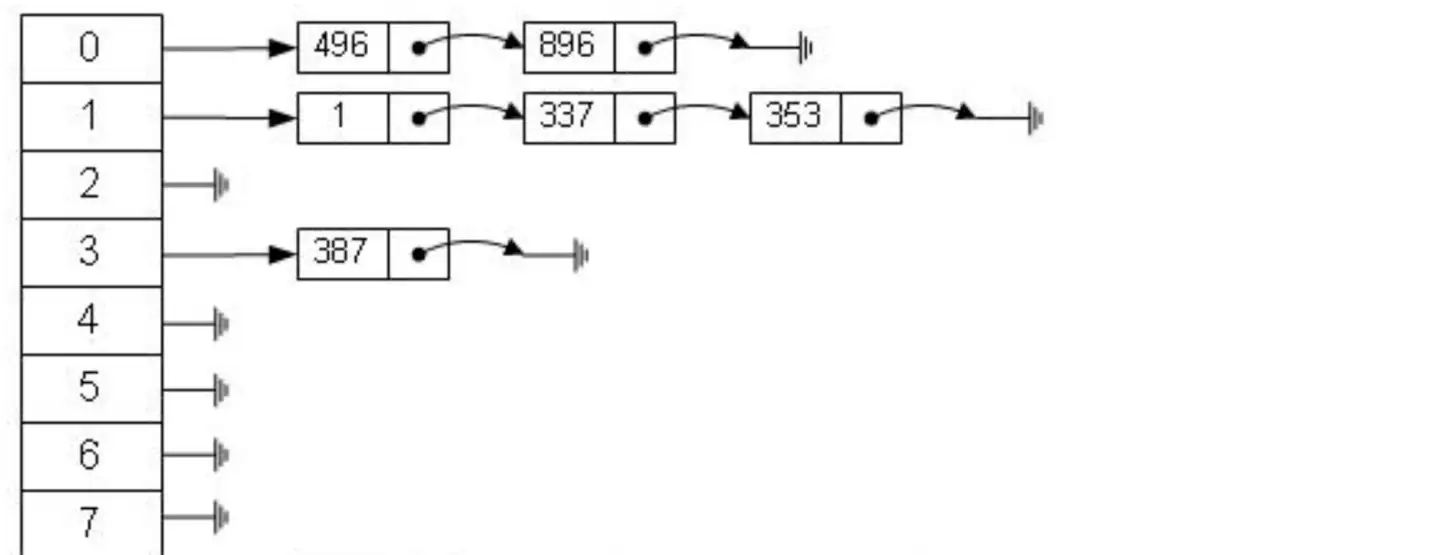
- 使用哈希算法实现的索引虽然可以做到快速检索数据,但是没办法做数据高效范围查找,因此哈希索引是不适合作为 Mysql 的底层索引的数据结构
-
-
二叉查找树
-
二叉查找树是一种支持数据快速查找的数据结构
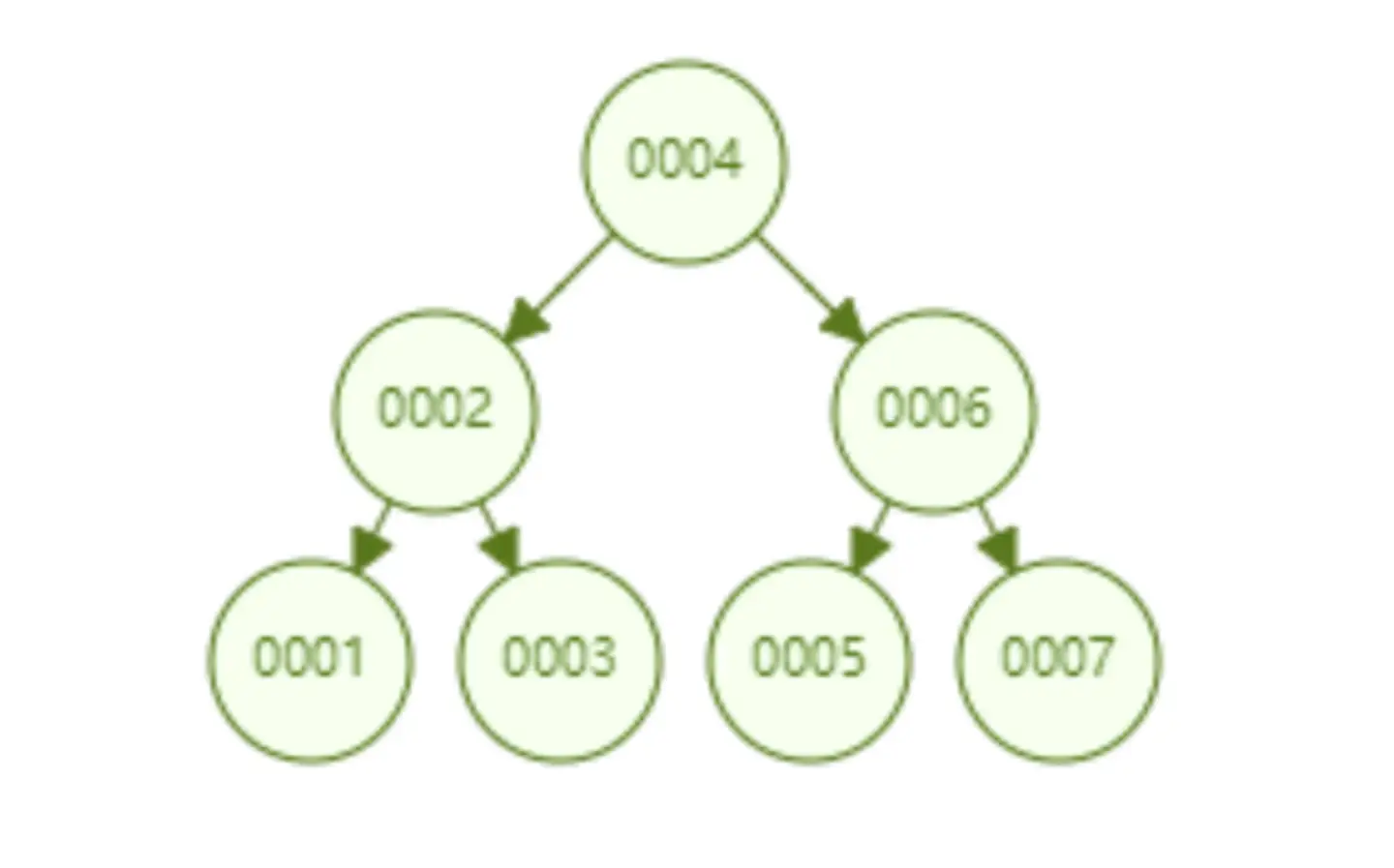
-
二叉查找树的时间复杂度是 O(lgn),比如针对上面这个二叉树结构,我们需要计算比较 3 次就可以检索到 id=7 的数据,相对于直接遍历查询省了一半的时间,从检索效率上看来是能做到高速检索的。此外二叉树的结构能不能解决哈希索引不能提供的范围查找功能呢?
-
答案是可以的。观察上面的图,二叉树的叶子节点都是按序排列的,从左到右依次升序排列,如果我们需要找 id>5 的数据,那我们取出节点为 6 的节点以及其右子树就可以了,范围查找也算是比较容易实现。
-
通的二叉查找树有个致命缺点:极端情况下会退化为线性链表,二分查找也会退化为遍历查找,时间复杂退化为 O(N),检索性能急剧下降。比如以下这个情况,二叉树已经极度不平衡了,已经退化为链表了,检索速度大大降低。此时检索 id=7 的数据的所需要计算的次数已经变为 7 了
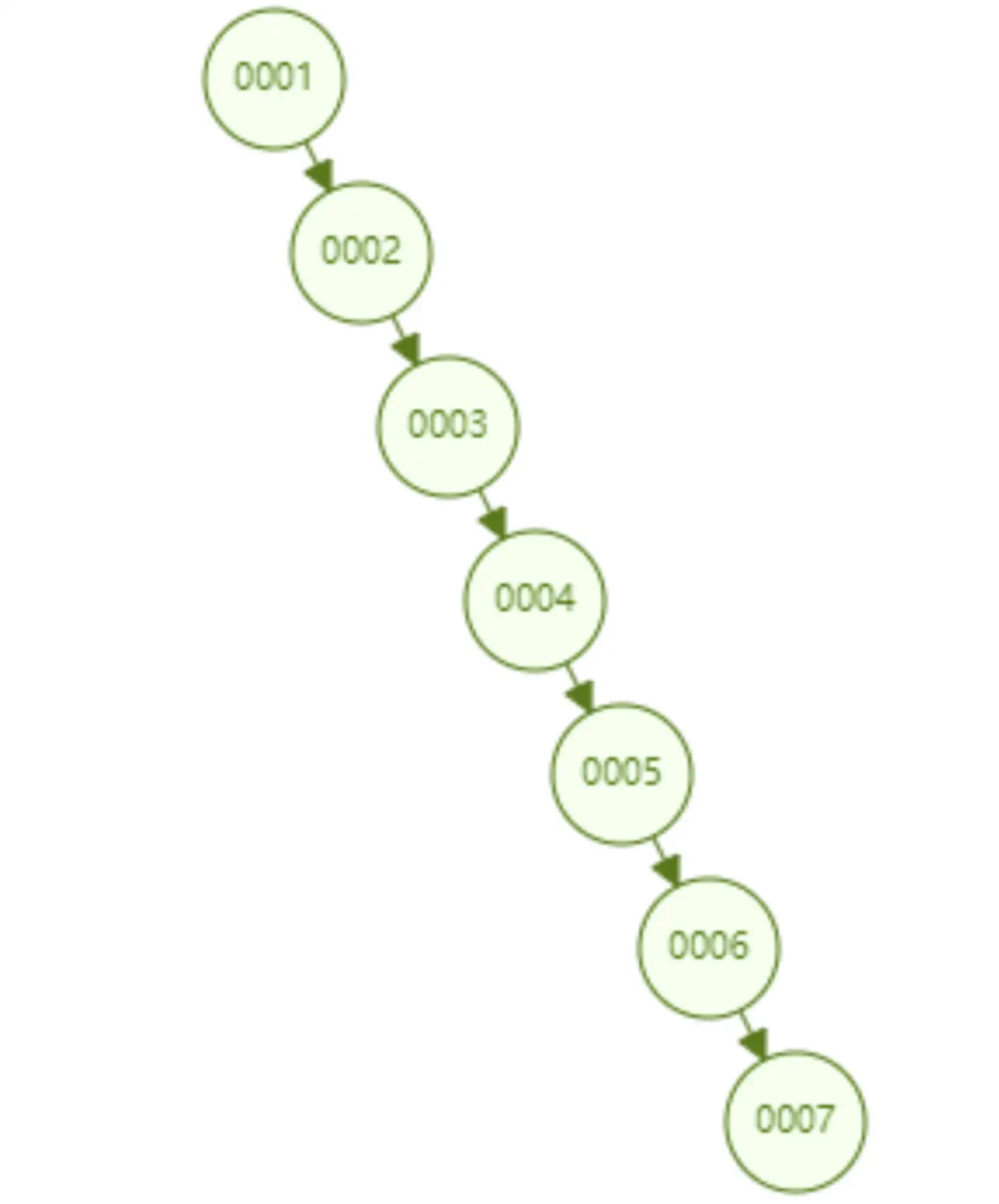
-
在数据库中,数据的自增是一个很常见的形式,比如一个表的主键是 id,而主键一般默认都是自增的,如果采取二叉树这种数据结构作为索引,那上面介绍到的不平衡状态导致的线性查找的问题必然出现。因此,简单的二叉查找树存在不平衡导致的检索性能降低的问题,是不能直接用于实现 Mysql 底层索引的
-
-
能调整平衡的树: 红黑树
-
当二叉树处于一个不平衡状态时,红黑树就会自动左旋右旋节点以及节点变色,调整树的形态,使其保持基本的平衡状态(时间复杂度为 O(logn)),也就保证了查找效率不会明显减低。比如从 1 到 7 升序插入数据节点,如果是普通的二叉查找树则会退化成链表,但是红黑树则会不断调整树的形态,使其保持基本平衡状态,如下图所示。下面这个红黑树下查找 id=7 的所要比较的节点数为 4,依然保持二叉树不错的查找效率。
-
红黑树拥有不错的平均查找效率,也不存在极端的 O(n)情况,那红黑树作为 Mysql 底层索引实现是否可以呢?其实红黑树也存在一些问题
-
观察下面这个例子: 红黑树顺序插入 1~7 个节点,查找 id=7 时需要计算的节点数为 4
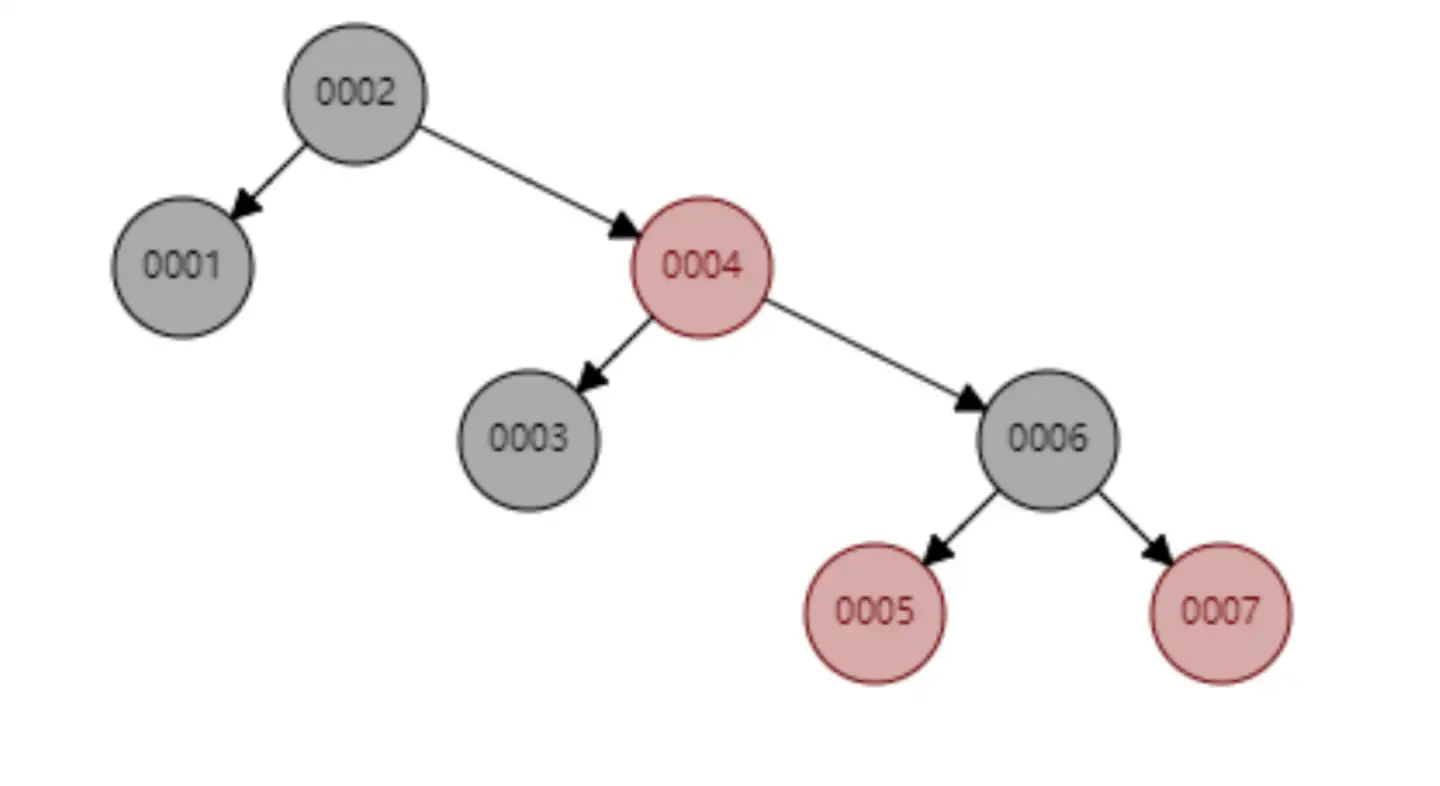
-
红黑树顺序插入 1~16 个节点,查找 id=16 需要比较的节点数为 6 次。观察一下这个树的形态,是不是当数据是顺序插入时,树的形态一直处于“右倾”的趋势呢?从根本上上看,红黑树并没有完全解决二叉查找树虽然这个“右倾”趋势远没有二叉查找树退化为线性链表那么夸张,但是数据库中的基本主键自增操作,主键一般都是数百万数千万的,如果红黑树存在这种问题,对于查找性能而言也是巨大的消耗,我们数据库不可能忍受这种无意义的等待的
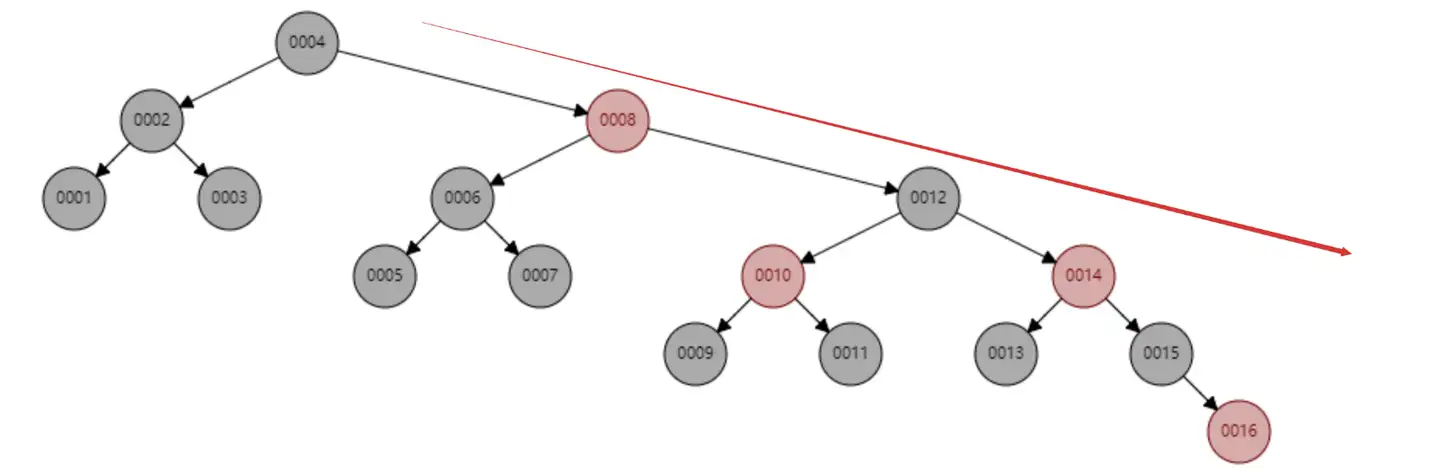
-
-
能调整平衡的树: 二叉平衡搜索树
-
AVL 树是个绝对平衡的二叉树,因此他在调整二叉树的形态上消耗的性能会更多
-
AVL 树顺序插入 1~7 个节点,查找 id=7 所要比较节点的次数为 3
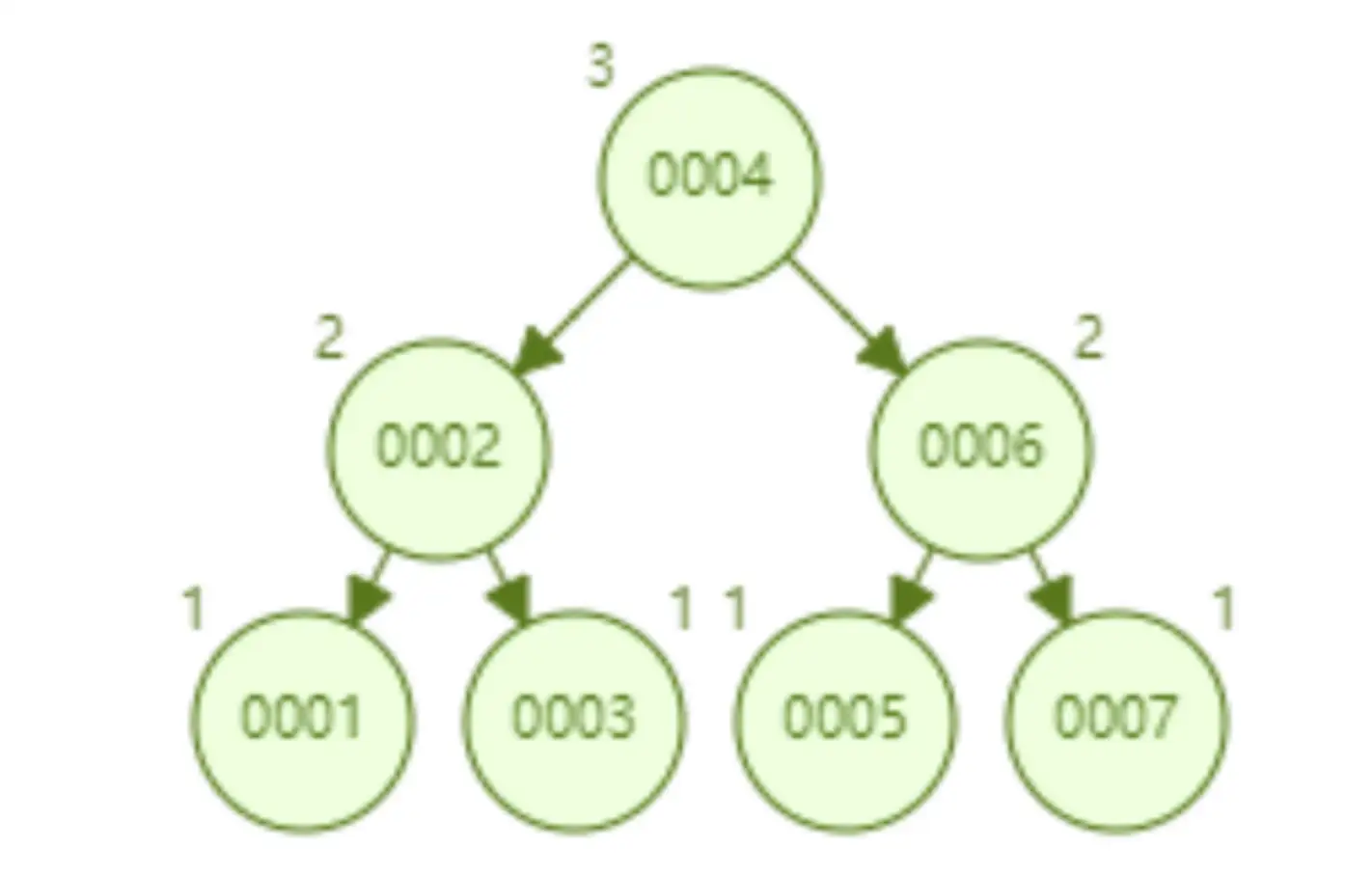
-
AVL 树顺序插入 1~16 个节点,查找 id=16 需要比较的节点数为 4。从查找效率而言,AVL 树查找的速度要高于红黑树的查找效率(AVL 树是 4 次比较,红黑树是 6 次比较)。从树的形态看来,AVL 树不存在红黑树的“右倾”问题。也就是说,大量的顺序插入不会导致查询性能的降低,这从根本上解决了红黑树的问题
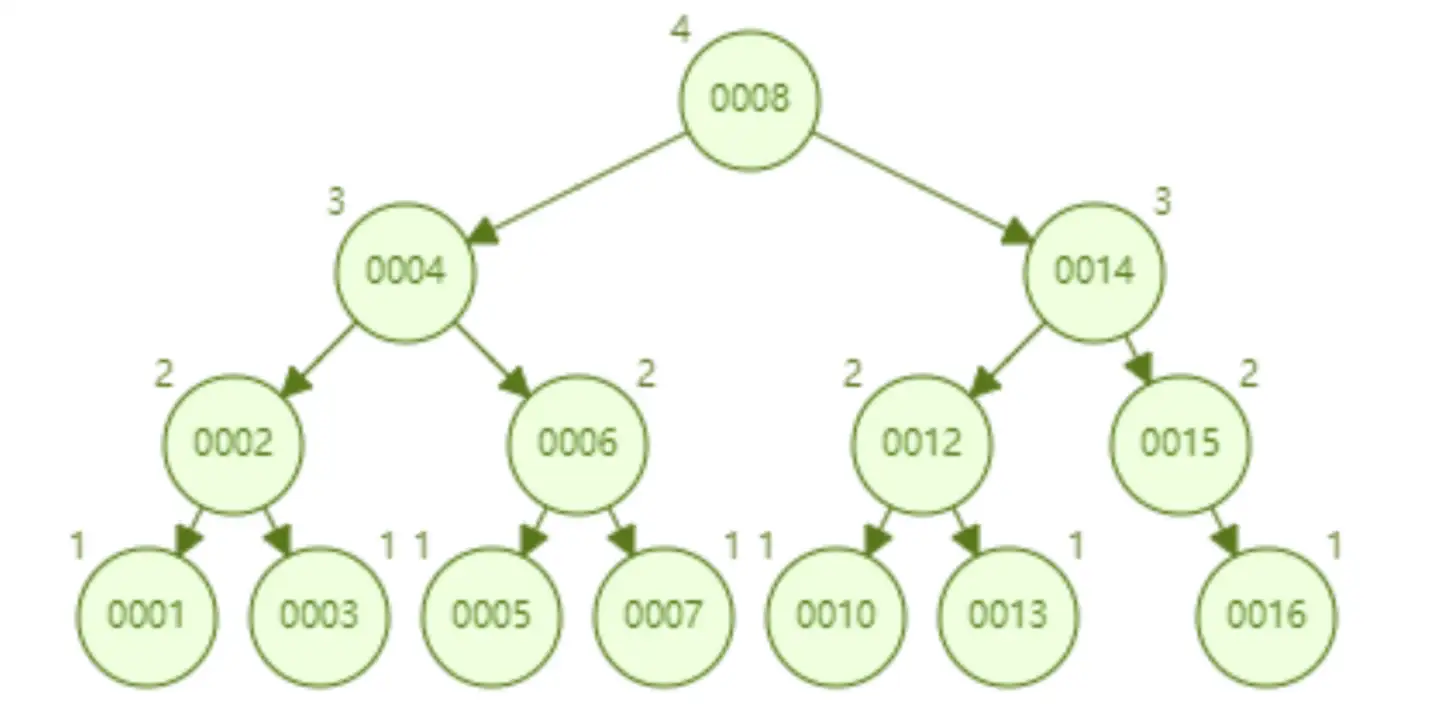
-
总结一下 AVL 树的优点:
不错的查找性能(O(logn)),不存在极端的低效查找的情况。
可以实现范围查找、数据排序。 -
但是 AVL 树并不适合做 Mysql 数据库的索引数据结构,因为考虑一下这个问题:
-
数据库查询数据的瓶颈在于磁盘 IO,如果使用的是 AVL 树,我们每一个树节点只存储了一个数据,我们一次磁盘 IO 只能取出来一个节点上的数据加载到内存里,那比如查询 id=7 这个数据我们就要进行磁盘 IO 三次,这是多么消耗时间的。所以我们设计数据库索引时需要首先考虑怎么尽可能减少磁盘 IO 的次数。
-
磁盘 IO 有个有个特点,就是从磁盘读取 1B 数据和 1KB 数据所消耗的时间是基本一样的,我们就可以根据这个思路,我们可以在一个树节点上尽可能多地存储数据,一次磁盘 IO 就多加载点数据到内存,这就是 B 树,B+树的的设计原理了。
-
-
-
B树: 平衡多路查找树
-
一个存储了 16 个数据的 B 树,查询 id=7 这个数据所要进行的磁盘 IO 为 2 次。相对于 AVL 树而言磁盘 IO 次数降低为一半

-
所以数据库索引数据结构的选型而言,B 树是一个很不错的选择。总结来说,B 树用作数据库索引有以下优点:
- 优秀检索速度,时间复杂度:B 树的查找性能等于 O(h*logn),其中 h 为树高,n 为每个节点关键词的个数;
- 尽可能少的磁盘 IO,加快了检索速度;
- 可以支持范围查找。
-
-
B+树: 平衡多路查找树PLUS
- 在B树的基础上 子节点用指针连接了起来, 并且B树是 节点上存储 指针和数据, B+树是 叶子节点存储 指针和数据, 非叶子节点只存储指针
- 这样有几个好处:
- 1、每次查询都要查询到子节点, 时间复杂度 稳定
- 2、范围查询只需要沿着子节点 往下找即可, 无需返回 上级再找 (查找某个范围的数据,只需在B+树的叶子节点链表中遍历即可,不需要像B 树那样挨个中序遍历比较大小)
- 3、非叶子节点中存放的元素不存放数据,所以每一层可以容纳更多的元素,也就是磁盘中的每一页可以存放更多元素。这样在查找时,磁盘IO的次数也会减少
-
模拟添加数据结构