1、需求描述
最近碰到了一个需求,是要统计各个团队的员工的销售金额,然后一级一级向上汇总。
![]() 编辑
编辑
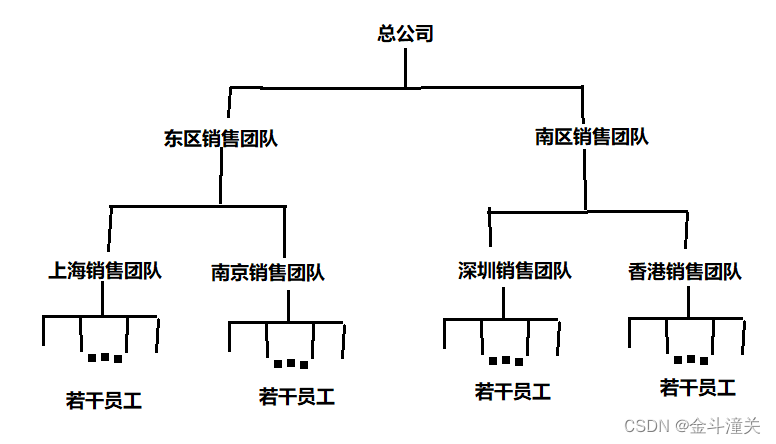
架构团队树是类似于这种样子的,需要先算出每个员工的销售金额,然后汇总成上一级的团队金额,然后各个团队的销售总金额再往上汇总成一个区域的销售金额,然后各个区域的金额再往上汇总成总公司的金额。当然我工作碰到的团队树要远比这个复杂许多,但反正差不多是这么个意思。
2、解决方法
2.1、方法一(不推荐)
持久层通过一些sql把团队树结构,以及各个员工的销售金额汇总拿到,然后在业务层通过代码去一层层拼起来。这是我一开始拿到这个需求时的思路,后来发现可以但是很复杂,代码可读性及可维护性很差。
2.2、方法二(推荐)
在sql里面计算汇总出来。
我这里是在测试环境建了几张Demo表来加以说明sql的逻辑。
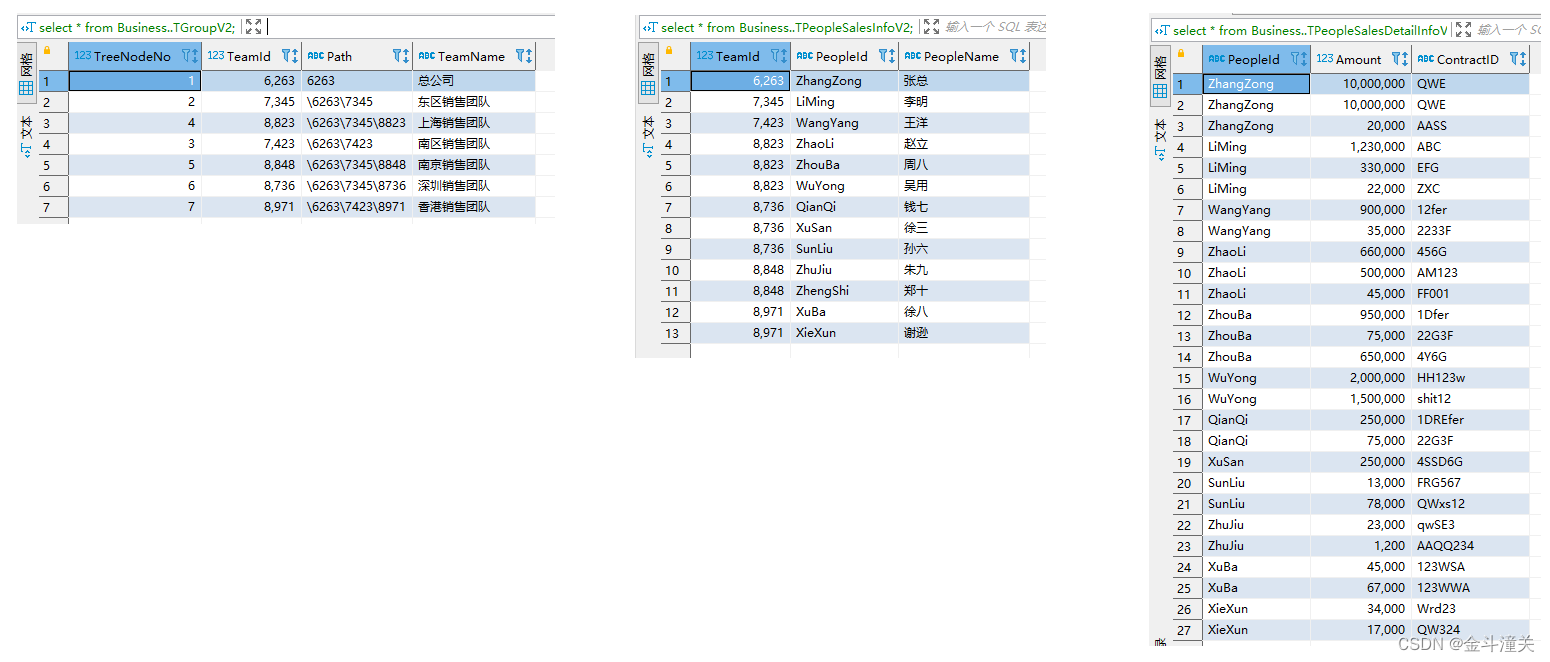
1、建表、
CREATE TABLE Business..TGroupV2(TreeNodeNo int,TeamId int,TeamName varchar(100),[Path] varchar(100));
CREATE TABLE Business..TPeopleSalesInfoV2(TeamId int,PeopleId varchar(100),PeopleName varchar(100));
CREATE TABLE Business..TPeopleSalesDetailInfoV2(PeopleId varchar(100),Amount Decimal(18,2),ContractID varchar(100));2、添加一些测试数据
![]() 编辑
编辑
3、SQL代码
--以团队为单位,汇总各个团队,子团队,父团队的销售金额
SELECT TB.TreeNodeNo,TB.TeamID,TB.TeamName,AA.Amount,'' as PeopleId ,'' as PeopleName FROM
(
SELECT A.ParentTeamID,SUM(A.Amount) as Amount FROM
(
SELECT
TT.*,TG2.TeamID as ParentTeamID,BB.Amount from
(
select T1.*,TG.[Path]
from Business..TPeopleSalesInfoV2 T1
left join Business..TGroupV2 TG on T1.TeamId=TG.TeamId
) AS TT
left join Business..TGroupV2 TG1 on TT.TeamId=TG1.TeamId
left join Business..TGroupV2 TG2 on
TG1.[Path] LIKE ('%\' + convert(varchar(50),TG2.TeamID))
or TG1.[Path] like ('%\' + convert(varchar(100),TG2.TeamID) + '\%')
or TG1.[Path] like (convert(varchar(50),TG2.TeamID) + '\%')
or TG1.[Path] = convert(varchar(50),TG2.TeamID)
LEFT JOIN
(select PeopleId,SUM(Amount) as Amount from Business..TPeopleSalesDetailInfoV2 group by PeopleId)
as BB on TT.PeopleId=BB.PeopleId
) A GROUP by ParentTeamID
) as AA LEFT JOIN Business..TGroupV2 TB on TB.TeamID=AA.ParentTeamID
UNION
--以员工为单位获取各个销售人员的销售金额
select TB.TreeNodeNo,TB.TeamID,TB.TeamName,SUM(TP.Amount) as Amount,TP.PeopleId,TPS.PeopleName from Business..TPeopleSalesDetailInfoV2 TP
LEFT JOIN Business..TPeopleSalesInfoV2 TPS on TPS.PeopleId=TP.PeopleId
LEFT JOIN Business..TGroupV2 TB on TB.TeamID=TPS.TeamID
group by TB.TreeNodeNo,TB.TeamID,TB.TeamName,TP.PeopleId,TPS.PeopleName
ORDER BY TreeNodeNo,PeopleId ASC 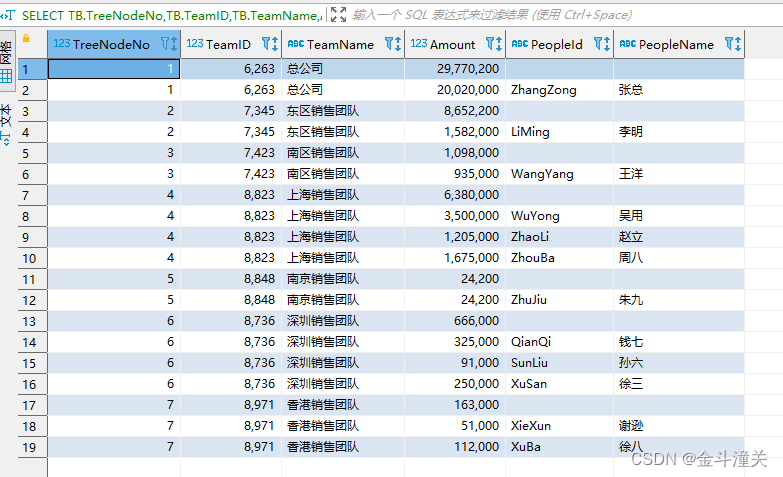
![]() 编辑
编辑
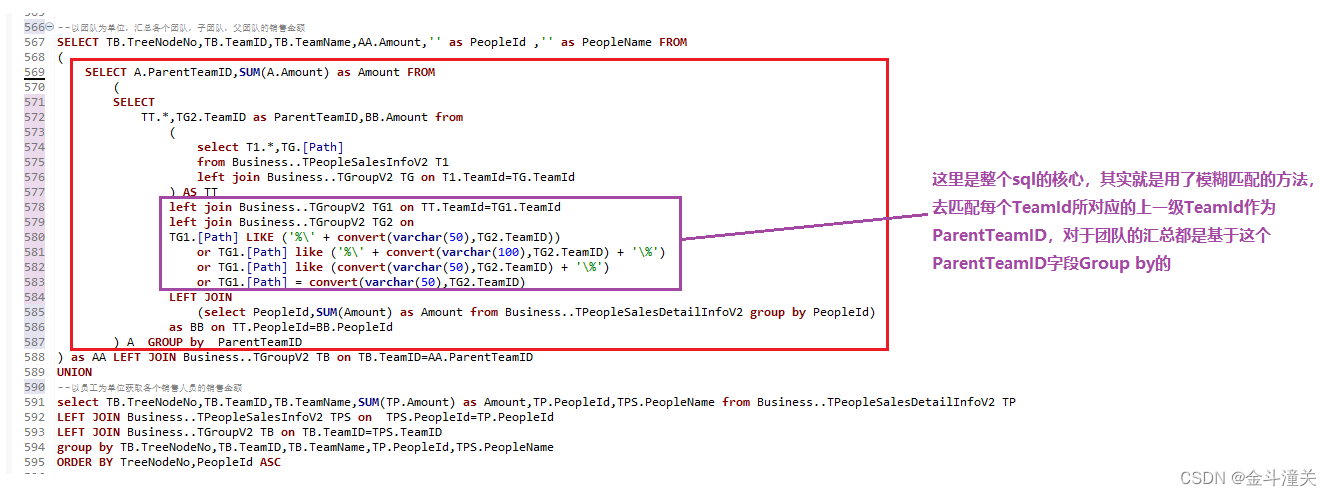
2.3、思路说明
![]() 编辑
编辑
3、总结
随着数据量增加一些老的sql查询性能太慢了,经常出现这种查询超时问题。

![]() 编辑
编辑
造成这种问题的原因有很多,一种是sql写的太烂了,业务层有循环查询。就像我方法一中的那种思想,不可避免你要循环查询出每个团队的金额再一级一级向上汇总。还有就是不合理的权限控制。比如你要查询团队的销售金额。因为团队的关系是一个树状结构嘛。假如你是东区的领导,你只能查询东区及其下所有子团队的数据,但在权限判断这块,其实是会东区下每个子团队,以及子团队的子团队.....都要判断一遍你有没有查询的权限。这样就增加了不必要的负担。不过这个是历史遗留问题,是因为之前的权限结构设计就不完善,也不太好改。
解决方法嘛,目前我就是通过存储过程取代select查询,因为存储过程是预编译的,所以执行起来开销比较小所以速度比较快。可以看下这篇详细了解下:为什么存储过程比sql语句效率高? - herizai - 博客园 (cnblogs.com)
因为原先的select查询关联了好多表以及视图,各种join的,可读性很差。我所要做的就是理清这些join之间的关系, 存储过程中用几个临时表把大的join拆成合并成小的join。再加一些注释什么的,虽然业务没有变,只是代码更容易理解了。速度确实快了一些,不在出现查询的超时的问题了。
4、参考资料
为什么要用存储过程,存储过程的优缺点。。_jokeylin的博客-CSDN博客
为什么存储过程比sql语句效率高? - herizai - 博客园 (cnblogs.com)
标签:一级,Business,汇总,TeamID,PeopleId,..,sql,团队,TB From: https://www.cnblogs.com/wlc-atlantide/p/17016458.html