从C过渡到C++——换一个视角深入数组[真的存在高效吗?](2)
C风格高效的数组遍历
在过渡到C++之前我还是想谈一谈如何书写高效的C的代码,这里的高效指的是C代码的高效,也就是在不开启编译器优化下,C层级的自由化,编译器优化固然很好,但是源代码的高效远远要胜于编译器的优化,因为在大多数情况下,你并不知道优化器到底干了什么。
数组名和指针
考虑如下声明:
int a;
int b[10];
我们把a通常称为一个标量,因为它是一个单一的值,这个变量的类型是一个整数。我们把变量b称为数组,因为它是一些值的集合。下标和数组名一起使用,用于标识该集合中某个特定的值。但是我们使用的时候都是这样的:
b[1]=10;
我们很少考虑一个问题就是b的类型是什么,我们知道b[1]的类型是一个int,这很好理解,你可能会说b是一整个数组,但实际上在c中并不是这样的,b应该是一个指针常量,且这个指针常量指向数组中第一个元素,为什么这样说呢?
例如我们可以实现如下的操作:
//test1
static int sta_var[]={0};
sta_var[0]++;
int *a = NULL;
a = sta_var;
printf("%d",sta_var);
我们在这里声明了一个指针,然后将数组名付给了它,输出结果如下:
同时上述语句更改为如下以后结果也是相同的:
a = &sta_var[0];
这里需要强调的是,指针和数组名并不是完全相同的,数组具有确定的元素数量,而指针只是一个标量值。编译器用数组名来记住这些属性。只有当数组名在表达式中使用的时候,编译器才会为它产生一个指针常量。
只有在两个场合下,数组名并不用指针常量来表示——当数组作为sizeof操作符或者单目操作符&的操作数的时候,sizeof返回整个数组中的长度,而不是指向数组的指针长度。取一个数组名的地址所产生的是一个指向数组的指针,关于指向数组的指针我们晚点再来讨论。
下标引用与指针
结合上边的讲解我们来看一个比较奇怪的东西:
*(sta_var+3)
首先我们知道sta是一个指针,指向整型,所以3这个值根据整型值的长度进行调整。加法运算的结果是另一个指向整形的指针,它所指向的是数组第一个元素向后移动3个整数长度的位置。其次,间接访问操作符访问这个新位置,或者取得那里的值(整型)。
这个东西由另一个常见的形式:
sta_var[3]
也就是下标引用和间接访问完全相同。
如果二者完全相同那么在运行效率上会有差别吗?我们应该使用哪一个呢?和往常一样,这里没有明确的答案,对于大多数人来说,下标更容易理解,尤其是在多维数组当中。所以在可读性方面,下标具有一定的优势。但这个选择可能会影响运行时的效率。
假设这两种方法都是正确的,下标绝对不会比指针更有效率,但指针有时会比下标更有效率。这也是本篇文章所讨论的内容。
为了理解这个问题,让让我们来研究两个循环:
//loop1
int array[10];
for(int a= 0 ; a< 10 ;a++)
array[a] = 1;
第二个loop:
//loop2
for(int *i=array; i < array+10 ;i++)
*i = 0;
对于第一个循环,为了求取下标的值,编译器在程序中插入指令,取得a的值,并把它与整形的长度相乘(整形长度是4)这个乘法需要花费一定的时间和空间,对于第二个循环, 尽管这里不存在下标,但是还是存在乘法运算,这个乘法运算在于每次for循环更新的时候就是指针i进行变化的时候,i++的时候这个1必须与整形的长度进行相乘然后再与指针相加,但是这个乘法有很大区别,乘法执行的是两个整数,也就是1和4,这个乘法在编译的时候只执行一次,程序在运行的时候直接使用这个4。
这里是默认情况未经过编译器优化的测试结果,我们让每一个循环跑10000000遍,看一看需要多久。
修改后两个代码如下:
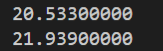
//loop1 21.8792s
start = clock();
for(int j=1;j<10000000;j++)
for(int a= 0 ; a< 1000 ;a++)
array[a] = 1;
stop = clock();
duration = ((double)(stop- start))/CLK_TCK;
printf("%.8f\n",duration);
//loop2
start = clock();
for(int j=1;j<10000000;j++)
{
for(int *i=array; i < array+1000 ;i++)
*i = 1;
}
stop = clock();
duration = ((double)(stop- start))/CLK_TCK;
printf("%.8f\n",duration);
我们在不开启优化的情况下运行时间如下:
我们在开启O优化的情况下:
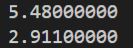
至于这里为什么下边运行效率会高一半我觉得是优化的问题,相同的操作只花费一般的时间,所有开启优化的结果都不能算数。
开启O2优化,就不用说了,他会直接变成0s,因为实际上做的操作是无用功。整个操作都被优化掉了。
我们看看二者的区别在哪里(以下是没有经过优化的代码):
jmp .L5
.L6:
mov eax, DWORD PTR 3916[rbp]
cdqe
mov DWORD PTR -96[rbp+rax*4], 123
add DWORD PTR 3916[rbp], 1
.L5:
cmp DWORD PTR 3916[rbp], 999
jle .L6
使用指针的汇编:
jmp .L5
.L6:
mov rax, QWORD PTR 3912[rbp]
mov DWORD PTR [rax], 123
add QWORD PTR 3912[rbp], 4
.L5:
lea rax, -96[rbp]
add rax, 4000
cmp QWORD PTR 3912[rbp], rax
jb .L6
按照上文的分析我们的数组使用指针效率不应该是更高吗?我们可以看到使用指针的汇编中并没有出现过使用乘法计算的内容:[rbp+rax*4],而是直接使用了4来替代:add QWORD PTR 3912[rbp], 4,那为啥实际上计算时间没有太大差异呢?甚至有些时候指针下标会慢于下标访问呢?
笨蛋的编译器,最重要的原因我觉得就在这里:
.L5:
lea rax, -96[rbp]
add rax, 4000
这里是唯一指针下标多出来的代码。我们的指针并没有将i < array+1000优化掉,即使我们这里所比较的内容是相同的,但是运算的时候为了防止array发生变化,这里又重新计算了一遍加法,也就是说这里在每次循环都要计算一遍加法,这是造成时间变化得最主要原因,所以我们可以这样说这样的写法只能保证:
指针效率≈下标访问的效率
这样的结果是编译器决定的,如果需要查看在某一个机器上的指针运行效率,建议还是查看一下具体的汇编代码,对于一般的for循环我们还是使用下标,这样对于别人来看你的代码的可读性会有很大的提升,如果真的需要大量的遍历或者各种情况,建议使用上文的方法来测量一下运行时间是否真的有一定的进步。
标签:视角,下标,int,C++,rbp,编译器,数组,指针 From: https://www.cnblogs.com/Jszszzy/p/16613982.html