注:码风较差,慎读
1.hash算法
相对于字符串,数字相对来说好处理一些,我们可以考虑把每一个字符串都对应一个数字,这样就可以非常简便地解决字符串的一些问题,而且效率还极高
字符串哈希,就是一种可以理解为将字符串映射到一个整数的方法。 比如BKDPHash是一种很好的哈希算法,假如字符串为a,则它对应的哈希值就为:
\(BKDPhash(a)=\sum_{i=1}^{a.length()}{a[i-1]\times P^{a.length()-i}} (mod Q)\)
怎么去理解这个哈希函数呢?可以发现,这其实是把字符串转换为了一个P进制的数的过程(所以也叫“进制哈希”),这样做可能会导致数字过大,导致溢出,所以转换完后要再对Q进行取余。
如何去计算哈希?可以采用递推的方法,采用一个数组记录字符串前i位的哈希值,例如,S="abcdefg",它的前缀有{a,ab,abc,abcd,…}。计算过程如下。
(1)计算前缀a的哈希值,得 \(H(a)\) ,计算时间为\(O(1)\)。
(2)计算前缀ab的哈希值。 \(H(ab)=H(a)\times P+H(b)\) ,计算时间为 \(O(1)\) 。
(3)计算前缀abc的哈希值。 \(H(abc)=H(ab)\times P+H(c)\) ,计算时间为 \(O(1)\),等等……
只需一个for 循环遍历S,就能在 \(O(n)\) 的时间内预处理所有前缀的哈希值。
计算出S的所有前缀的哈希值后,能以 \(O(1)\) 的复杂度查询它的任意子串的哈希值,如 \(H(de)=H(abcde)-H(abc)\times P^{2}\) 。求区间[L,R]的哈希值的代码可以这样写(其中 P[i]表示P的i次方):
ull get_hash(ull L,ull R){return H[R]-H[L-1]*P[R-L+1];}
很多字符串问题和前缀、后缀有关,如回文串问题、字符串匹配问题等。利用进制哈希,能以不错的时间复杂度求解。虽然效率比KMP、Manacher等经典算法差一些,占用空间也大一些,但是一般情况下够用。
最后要说明的是哈希碰撞,因为要对Q取余,所以有可能出现两个字符串哈希值一样的情况,这就叫哈希碰撞,虽然概率小,但是某些人喜欢卡掉用朴素方法实现的哈希。这个时候通常需要用双哈希一类的技巧。
双哈希,指的是对字符串应用两对不同的 P和Q得到不同的哈希值。只有这两个哈希值都对应相同,才判定两个字符串相同(相当于上了两重保障)。
另外朴素方法中为了有效避免哈希碰撞,进制P常用的数值有31,131,1313,13131,131313等。
还有要是一个题目中即使用hash也可能会被时间卡掉,这是因为取模会花费大量时间,可以使用unsigned long long的自然溢出(相当于对\(2^{64}\)取模)(但不会被时间卡的时候千万别写)。
P3763
题目:洛谷P3370,P3501,P4391P5270,P5537
2.Manacher算法
用于解决最大回文子串的有效算法。
回文串是从头到尾读与从尾到头读都相同的字符序列。一个回文串是“镜像对称”的,反转之后与原串相同。回文串有两种,一种长度为奇数,有一个中心字符,如"abcba"中的'c';一种长度为偶数,有两个相同的中心字符(也可以看作没有中心字符),如"abba"中的"bb"。
对于解决一个字符串的最大回文子串我们最低级的做法是暴力,中心扩展法是有效的,即依次以每个字符为中心向两边扩展。
可是这样肯定有很多浪费(因为重复检查)啊,于是Manacher算法就闪亮登场~
因为回文串有时最中间是一个数,有时中间是两个数,不方便操作,所以刚开始要对字符串进行一个小小的改进来更便捷的操作。在字符串的每个字符左右插入一个不属于此字符串的字符,如'#'。
如把"abcba"变成了"#a#b#c#b#a#",中心字符为'c';把"abba"变成了"#a#b#b#a#",中心字符为'#'。经过这样的变换,字符串S的新长度都是奇数,中心字符都只有一个。另外,为了编程方便,在字符串的首尾再加上两个奇怪字符防止越界,如把#a#b#b#a#"的首尾分别加上'@'和'&" 变成"@#a#b#b#a#&"。
然后我们定义数组P,其中P[i]是以字符s[i]为中心字符的最长回文子串的长度,设我们的字符串是S
设已经计算出了 \(P[0]\sim P[i-1]\) ,下一步继续计算 P。令R为 \(P[0]\sim P[i-1]\) 这些回文串中最大的右端点,C是这个R对应的回文串的中心点。也就是说,P[C]是已经求得的一个回文串,它的右端点是R,且R是所有已经求得的回文串的右端点最大值 \(R=C+P[C]\) 。在字符串S上,R左边的字符已经检查过,R右边的字符还未检查。
下面计算P[i]。设i是i关于C的镜像点,P[i]已经计算出来了。
若 \(i>R\) ,由于R右边的字符都没有检查过,只能初始化 \(P[i]=1\) ,然后用暴力中心护展法求 P[i]。
若 \(i<R\) ,细分为两种情况。
(1)i的回文串(i的虚线框部分)被C的回文串包含,即回文串的左端点比C回文串的左端点大,按照镜像原理,镜像i的回文不会越过C的右端点R,有 \(P[i]=P[j]\) 。根据 \((i+j)/2=C\) ,得 \(j=2C-i\) , \(P[i]=P[j]=P[2C-i]\) 。然后继续用暴力中心扩展法完成P[i]的计算,如图(a)所示。
(2)i的回文串(j的虚线框部分)不被C的回文串包含,即j回文串的左端点比C回文串的左端点小。i回文串的右端点比R大,但是由于R右边的字符还没有检查过,只能先让 P[i]被限制在R之内,有 \(P[i]=w=R-i=C+P[C]-i\) 。然后继续用暴力中心扩展法完成 P[i]的计算,如图(b)所示。

容易发现总复杂度为 \(O(n)\)
题目:洛谷P3805
3.KMP算法
对于在一个长字符串中找另一个短字符串(有可能多次出现,都要找到)通常叫做模式匹配,KMP算法是解决模式匹配问题的一个非常有效的算法。
先来看朴素的模式匹配算法,即为暴力,把长字符串一个一个扫过去,对于扫过的每一个字符,都逐个往后匹配短字符串的内容,复杂度最优能达到 \(O(n)\) (前面每一个刚开始都不匹配),最差能达到 \(O(nm)\)
如何进行改进?观察暴力法的过程,可以发现一些被浪费的时间,有些字符会被扫很多遍,以长字符串S="abababc",短字符串P="ababc"为例来分析我们如何进行优化:
刚开始扫描S,从第一个开始往后匹配,只能匹配到"abab",再往后便不能匹配,按照暴力算法就再从第二个往后匹配……
可是这样真的有必要吗?我们前面已经检查过了"abab",再继续就相当于重复检查。再观察可以发现下一个会匹配到的便是从S的第三个开始的"ababc",这里面中的"ab"在第一次检查是已经检查过了,为什么会这样?思考一下便知"ab"同时是"abab"的前缀和后缀,所以会被重复检查,同理,为了防止重复检查,只需在一次检查过后从同时是这次检查的字符串的前缀与后缀的字符串开始往后检查即可
好了,现在我们貌似是抓住了事情的关键,便是要知道一个字符串中同时是前缀与后缀的字符串是什么,这时,可以明确出border和前缀数组的概念:
- 一个字符串S的 border,是这样一个字符串 \(S_{0}\) ,满足 \(S_{0}\)既是S的前缀也是S的后缀,但\(S_{0}\ne S\)。
- 一个字符串可以有多个 border,也可以一个 border 都没有。
由此定义**前缀数组 **\(next[i]\) :
- \(next[i]\) 表示 的前缀 \(S[0...i-1]\) 的最长的 border 的长度。特别地,若不存在任何 border,则\(next[i]=0\)。
那么该如何计算前缀数组?从一个例子出发:
P="abcaab",前缀数组计算过程如下表所示,每行带下画线的子串是最长公共前后缀border。
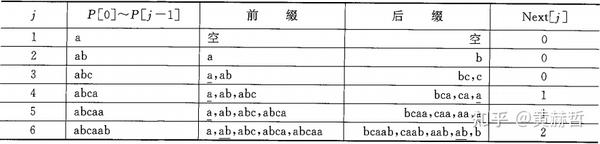
对于前缀数组,存在一种巧妙的递推关系,假设我们已经计算出了 \(next[1...i]\) ,便可以计算出 \(next[i+1]\) :
设此时上一个计算所对应的前缀最后的索引为j-1,则此时分为两种情况:
- \(P[i]=P[j]\) ,则next数组可以直接往下递推为 \(next[i+1]=next[i]+1\)
- \(P[i]\ne P[j]\) ,以下图来分析,说明后缀的“ \(阴影 w+P[i]\) ”与前缀的“ \(阴影 w+P[j]\) ”不匹配,只能缩小范围找新的交集。把前缀向后滑动,也就是通过减小j缩小前缀的范围,直到找到一个匹配的 \(P[i]=P[j]\) 为止。如何减小j?只能在w上继续找最大交集,这个新的最大交集是 $ Next[j]$ ,所以更新 \(j'=Next[j]\) 。图 (b)给出了完整的子串 $ P[0]\sim P[i]$ ,最后的字符 $ P[i]≠P[i]$ 。斜线阴影v是w上的最大交集,下一步判断:若 \(P[i]=P[j']\) ,则 \(Next[i+1]\) 等于v的长度加 1,即 $ Next[j']+1$ ; 若 \(P[i]≠P[j']\) ,继续更新 \(P[i]≠P[j']\) 。
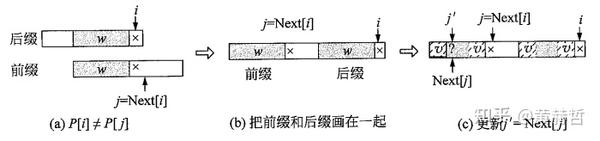
就这样重复操作,便可以计算出前缀数组
总复杂度为 \(O(n+m)\)
既然计算出了前缀数组,我们便可以进行较为简便的匹配,我们以一道题来说明模版代码和运用:
题目:洛谷P4824
简要说明一下题意:给定一个字符串S和一个子串T,删除S中第1次出现的T,把剩下的拼在一起,然后继续删除T,直到S中没有T,最后输出S剩下的部分。S中最多有 \(10^{6}\) 个字符。
本题的麻烦之处在于删除一个T之后两端的字符串有可能会拼接出一个新的T。例如,S="ababccy",T="abc",删除第1个T后,S="abcy",出现了一个新的T,继续删除,得S="v"
如何去解决这个问题呢?对KMP算法有深入理解了话可以明白完全不用每次删除完之后重复检查,我们只需开一个栈便可以解决它
按照寻常的KMP板子写,只不过要开一个和长字符串一样大的数组记录每一位所对应的j值,然后遍历长字符串时把每次的i值依次入栈,如果匹配到了,则把被匹配到的所有i值出栈,j值换为栈顶,最后输出栈里索引所对应的值即可。
#include<bits/stdc++.h>
#define N 1000010
using namespace std;
int la,lb,res;
char a[N],b[N];
int p[N],f[N];
int St[N],top;
int main()
{
int i,j;
scanf("%s",a+1);
scanf("%s",b+1);
la=strlen(a+1);
lb=strlen(b+1);
for(i=2,j=0;i<=lb;i++) {//计算前缀数组
while(j&&b[i]!=b[j+1])
j=p[j];
if(b[i]==b[j+1])
j++;
p[i]=j;
}
for(i=1,j=0;i<=la;i++) {//匹配过程
while(j&&a[i]!=b[j+1])
j=p[j];
if(a[i]==b[j+1])
j++;
f[i]=j//记录j只能;
St[++top]=i;//入栈
if(j==lb)
top-=lb,j=f[St[top]];//出栈
}
for(i=1;i<=top;i++)
printf("%c",a[St[i]]);//输出
return 0;
}
注:此题可以采用哈希+栈的方法解决
题目:洛谷P4391,P3375,P5410等
4.字典树
是这样的,字典树也被称为前缀树,它的每个结点用来维护字符串的前缀,形象的话可以用查字典来比喻,你一个一个词往后查正如正在深度优先搜索一颗树,每一个完整的词对应的都是从一个根节点的子节点的到另一个节点的完整的路径,例如ce,cee,bacd,bsa,cd,这些字符串的字典树可以构建为:
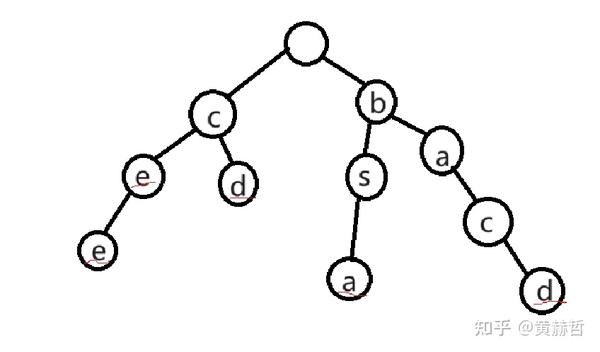
可以知道一些性质辣!
- 根结点不包含字符,其余结点都有字符
- 从根节点到某一个节点,路径上经过的字符连接起来,为该节点对应的字符串
- 一个完整的单词并不是存储在某个节点上,而是存储在一条链上;
- 一个节点的所有子节点都有相同的前缀
ok,知道了是啥,我们如何建树呢?
就是正常的建树步骤辣(废话逃),用图的邻接表来存储,然后就是依次插入字符串
插入字符串操作:
void insert(char str[]){
int p=0,len=strlen(str);
for(int i=0;i<len;i++){
int c=getnum(str[i]);
if(!t[p][c])
t[p][c]=++idx;
p=t[p][c];
cnt[p]++;
}
}
当把字符串插入完后,接下来便是应用
最常用的是查询。
以洛谷上的模版字典树P8306为例
可以看出要求是查询某字符串是多少字符串的前缀,于是我们可以写出查询函数,和插入函数很类似,只是遇到无法匹配时返回0以及一些别的细节:
int find(char str[]){
int p=0,len=strlen(str);
for(int i=0;i<len;i++){
int c=getnum(str[i]);
if(!t[p][c])
return 0;
p=t[p][c];
}
return cnt[p];
}
当然于此同时插入函数也得改一下(得顺便记录一下结点下有多少个字符串),然后完整代码给出:
#include<bits/stdc++.h>
using namespace std;
int T,q,n,t[3000005][65],cnt[3000005],idx;
char s[3000005];
int getnum(char x){
if(x>='A'&&x<='Z')
return x-'A';
else if(x>='a'&&x<='z')
return x-'a'+26;
else
return x-'0'+52;
}
void insert(char str[]){
int p=0,len=strlen(str);
for(int i=0;i<len;i++){
int c=getnum(str[i]);
if(!t[p][c])
t[p][c]=++idx;
p=t[p][c];
cnt[p]++;
}
}
int find(char str[]){
int p=0,len=strlen(str);
for(int i=0;i<len;i++){
int c=getnum(str[i]);
if(!t[p][c])
return 0;
p=t[p][c];
}
return cnt[p];
}
int main(){
scanf("%d",&T);
while(T--){
for(int i=0;i<=idx;i++)
for(int j=0;j<=122;j++)
t[i][j]=0;
for(int i=0;i<=idx;i++)
cnt[i]=0;
idx=0;
scanf("%d%d",&n,&q);
for(int i=1;i<=n;i++){
scanf("%s",s);
insert(s);
}
for(int i=1;i<=q;i++){
scanf("%s",s);
printf("%d\n",find(s));
}
}
return 0;
}
应用:
01 字典树:
当把一个整数用二进制表示后,它就可以看成一个由 01 组成的字符串(当然也可能是由别的什么进制)。多个整数放在一起,就可以放进一棵字典树里来。这种类型的题目通常会结合位运算、贪心。
把数拆成二进制的形式,然后每一位都只有两个字符:0或1,然后按照trie的方式存下来,以达到节省空间的效果。
如下图:
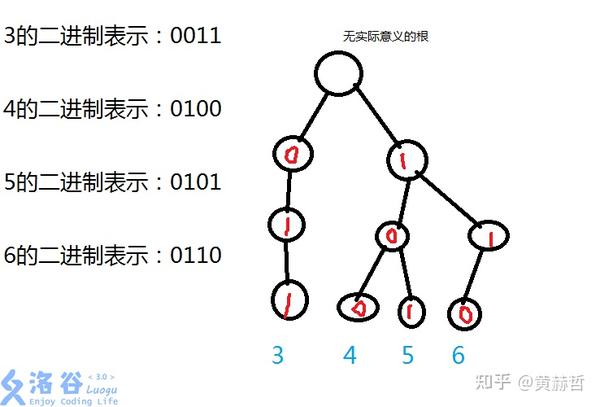
那就以一道题目为例吧:
洛谷P4551
题意:给定一棵 n个点的带权树,结点下标从1开始到 n。寻找 树中找两个结点,求最长的异或路径。异或路径指的是指两个结点之间唯一路径上的所有边权的异或。
首先看到这道题,其实我们可以容易的先推出这个结论:
任意两个节点的异或路径都可以表示为第一个节点到根节点的异或路径值再异或上第二个节点到根节点的异或路径值,这个是因为一个数两次异或上另一个数还是等于这个数,所以两个结点到根节点重复的地方直接就被忽略了
然后就可以有这样的思路:
- 求出根节点到每一个节点的异或路径
- 对每一个节点求出对于这个节点与别的节点的最大异或值
- 选出所有节点中最大的即是答案
我们的重点其实在第二步,求出谁和某个数异或最大,这时可以用到01字典树,一点一点往下遍历,对于数的每一位进行贪心,如果这一位有一个与它不同的,即异或后是1,那我们就顺着这条路往下走;否则就顺着原路往下走。
这样贪心为什么是对的呢?因为最高位越大数相对的越大~~
然后就解决这道题了
题目:洛谷P3879,P2292
5.EX KMP
扩展 KMP(EXKMP,Z 函数)是一种求字符串的每个后缀与原串的最长公共前缀的算法。
最长公共前缀(LCP):最大的 k 满足两个字符串 a, b 长度为 k 的前缀相等。
我们来考虑如何去计算Z函数,采取递推的方法,依次计算 \(z_0\sim z_n\) 的值,假设我们要计算 \(z_i\) , \(r\) 为当前前面算出来的使得 \(r+z[r]\) 最大的值(即以\(r\)为开头的后缀的lcp右端点最后的点)
如果 \(i\leq r+z[r]\) ,那么就说明 \(s[i\sim n]\) 的一段前缀与前面的 \(s[i-r\sim r+z[r]-r]\) 相同(结合Z函数定义理解),这就可以说明出 \(z[i]\) 的值就至少为 \(min(z[i-r],r+z[r]-i+1)\) (注意这里是把\(s[i-r\sim r+z[r]-r]\) 的z函数转移到了i),然后 \(z[i]\) 往后暴力扩展即可
如果\(i> r+z[r]\),直接使用朴素算法即可,暴力比较
中间还要注意要根据\(r+z[r]\)不断更新r值
于是求Z函数的线性算法就出来了
代码如下
void z(){
int l=0,r=-1;//注意r的初始值,理由是玄学
z[0]=m;//特殊处理
for(int i=1;i<m;i++){
if(i<=r) z[i]=min(z[i-l],r-i+1);//分讨
while(i+z[i]<m&&b[i+z[i]]==b[z[i]]) z[i]++;//朴素
if(r<i+z[i]-1) l=i,r=i+z[i]-1;//更新
}
}
后缀树/数组/自动机等待续