一、简要介绍
 论文研究了自深度学习出现以来,预训练语言模型的算法的改进速度。使用Wikitext和Penn Treebank上超过200个语言模型评估的数据集(2012-2023年),论文发现达到设定性能阈值所需的计算大约每8个月减半一次,95%置信区间约为5到14个月,大大快于摩尔定律下的硬件增益。论文估计了增强的scaling law,这使论文能够量化算法的进展,并确定scaling模型与训练算法中的创新的相对贡献。尽管算法的快速发展和transformer等新架构的发展,在这段时间内,计算量的增加对整体性能的提高做出了更大的贡献。虽然受到有噪声的基准数据的限制,但论文的分析量化了语言建模的快速进展,揭示了计算和算法的相对贡献。
二、方法论
2.1模型定义 论文希望估计更新的语言模型能够比旧的模型更有效地达到一定性能水平的速率。论文通过拟合一个模型,满足两个关键需求: (1)该模型必须与之前关于神经scaling law的工作广泛一致,和(2)该模型应该允许分解对提高性能的主要贡献者,例如改进模型中的数据或自由参数的使用效率。
论文研究了自深度学习出现以来,预训练语言模型的算法的改进速度。使用Wikitext和Penn Treebank上超过200个语言模型评估的数据集(2012-2023年),论文发现达到设定性能阈值所需的计算大约每8个月减半一次,95%置信区间约为5到14个月,大大快于摩尔定律下的硬件增益。论文估计了增强的scaling law,这使论文能够量化算法的进展,并确定scaling模型与训练算法中的创新的相对贡献。尽管算法的快速发展和transformer等新架构的发展,在这段时间内,计算量的增加对整体性能的提高做出了更大的贡献。虽然受到有噪声的基准数据的限制,但论文的分析量化了语言建模的快速进展,揭示了计算和算法的相对贡献。
二、方法论
2.1模型定义 论文希望估计更新的语言模型能够比旧的模型更有效地达到一定性能水平的速率。论文通过拟合一个模型,满足两个关键需求: (1)该模型必须与之前关于神经scaling law的工作广泛一致,和(2)该模型应该允许分解对提高性能的主要贡献者,例如改进模型中的数据或自由参数的使用效率。


 2.2估算方法 2.2.1模型选择 论文在语言模型评估数据集上估计了公式(3)中提出的增广scaling law的变量。论文执行广泛的交叉验证练习,以确定最适合数据的模型的变体。本练习的目的是考虑捕获不同效果的不同模型(例如,不同模型架构之间的不同scaling行为、不同形式的算法进展等)。
2.2估算方法 2.2.1模型选择 论文在语言模型评估数据集上估计了公式(3)中提出的增广scaling law的变量。论文执行广泛的交叉验证练习,以确定最适合数据的模型的变体。本练习的目的是考虑捕获不同效果的不同模型(例如,不同模型架构之间的不同scaling行为、不同形式的算法进展等)。

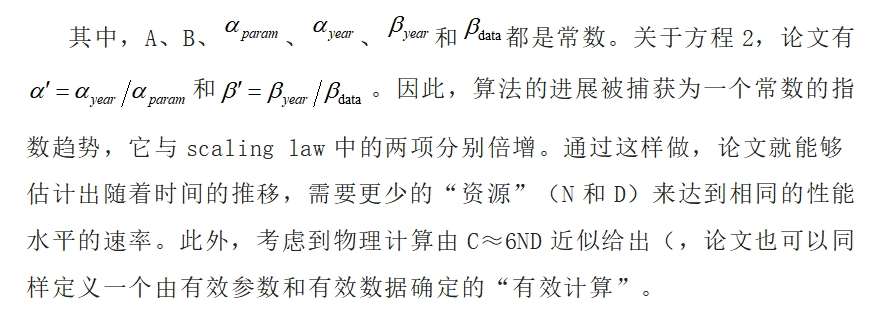
 论文试图在交叉验证分析中解释这种可能性。特别地,论文引入了三个模型(模型13到15),它们解释了不同类型的scaling指数,包括指数随时间变化的可能性。论文选择的主模型(模型7)在交叉验证中优于这些模型,但这些替代方案也表现出同样的效果,通常R2在0.88到0.91之间。这个分析在附录J中有更详细的描述。 论文还考虑了其他可能影响测量的困惑的因素,从而测量算法进展的速度。例如,在某些情况下,预处理过程中不同的标记化方案可以改善WT103的困惑,多个epoch的训练模型是提高性能的常见方法。论文发现,当改变这些自由度时,论文的核心结果是大致相同的——论文在附录中提供了关于这些实验的更多细节。 最后,为了解释模型规范中的不确定性,论文比较了在交叉验证分析中考虑的不同模型的模型预测。 2.2.2数据 论文的数据集包含超过400种语言模型,在 WikiText-103 (WT103), WikiText-2 (WT2), Penn Treebank (PTB)上评估,其中大约60%作者可以在论文的分析中使用。特别是,作者从大约200篇不同的论文中检索到了相关信息,以及使用Gao,Tow等人2021年的框架对自己执行的25个模型的评估。然后,论文考虑数据的子集,其中包含拟合论文提出的模型结构所需的信息:令牌级测试困惑(它决定交叉熵损失)、发布日期、模型参数数量和训练数据集大小。这就给论文留下了大约231个模型可供分析。
论文试图在交叉验证分析中解释这种可能性。特别地,论文引入了三个模型(模型13到15),它们解释了不同类型的scaling指数,包括指数随时间变化的可能性。论文选择的主模型(模型7)在交叉验证中优于这些模型,但这些替代方案也表现出同样的效果,通常R2在0.88到0.91之间。这个分析在附录J中有更详细的描述。 论文还考虑了其他可能影响测量的困惑的因素,从而测量算法进展的速度。例如,在某些情况下,预处理过程中不同的标记化方案可以改善WT103的困惑,多个epoch的训练模型是提高性能的常见方法。论文发现,当改变这些自由度时,论文的核心结果是大致相同的——论文在附录中提供了关于这些实验的更多细节。 最后,为了解释模型规范中的不确定性,论文比较了在交叉验证分析中考虑的不同模型的模型预测。 2.2.2数据 论文的数据集包含超过400种语言模型,在 WikiText-103 (WT103), WikiText-2 (WT2), Penn Treebank (PTB)上评估,其中大约60%作者可以在论文的分析中使用。特别是,作者从大约200篇不同的论文中检索到了相关信息,以及使用Gao,Tow等人2021年的框架对自己执行的25个模型的评估。然后,论文考虑数据的子集,其中包含拟合论文提出的模型结构所需的信息:令牌级测试困惑(它决定交叉熵损失)、发布日期、模型参数数量和训练数据集大小。这就给论文留下了大约231个模型可供分析。
 在某些情况下,从同一篇论文中检索到多个模型,即使它们构成了类似的算法创新。这可能会给自相关带来问题,这可能导致低估论文单个参数估计的不确定性。因此,在接下来的主要分析中,每篇论文最多只包含三个模型,这导致大约50个模型被排除。为了验证这种方法的稳健性,论文还考虑了另一种技术,直接解释自相关,它产生与论文的主要结果一致的加倍时间和置信区间估计(见附录I)。
三、实验结果 3.1模型大约每8个月需要的计算减少2倍
在某些情况下,从同一篇论文中检索到多个模型,即使它们构成了类似的算法创新。这可能会给自相关带来问题,这可能导致低估论文单个参数估计的不确定性。因此,在接下来的主要分析中,每篇论文最多只包含三个模型,这导致大约50个模型被排除。为了验证这种方法的稳健性,论文还考虑了另一种技术,直接解释自相关,它产生与论文的主要结果一致的加倍时间和置信区间估计(见附录I)。
三、实验结果 3.1模型大约每8个月需要的计算减少2倍


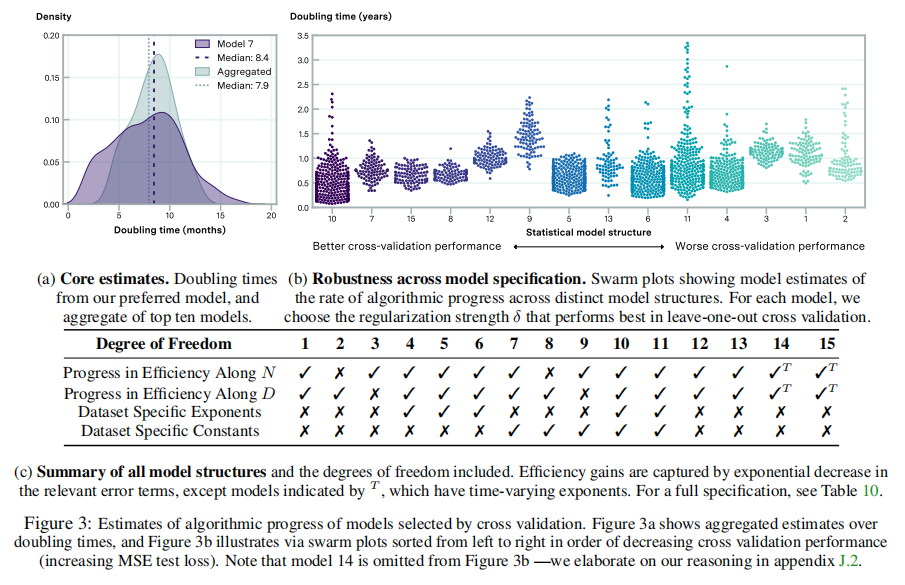 通过观察来自不同模型的预测,论文进一步检验了这个结果的稳健性。特别是,因为论文使用留一交叉验证来执行模型选择,所以论文可以将论文的首选模型的预测与论文所考虑的其他模型的预测进行比较。根据论文的交叉验证练习,连接前10个模型的倍增时间估计数,论文发现中位倍增时间为7.8个月[95%CI:1.5-17.6个月],这与论文所首选的模型相似。 另一种方法依赖于计算方案,而不是倍增时间的封闭解。论文首先计算通过加倍计算预算来实现的损失∆L的减少,假设N和D在估计的模型下是最优的。然后,论文确定了算法改进所需的时间,以产生等效的损失∆L减少。结果表明,这些方法产生的结果几乎相同,中位数的倍增时间为8.6个月,95%的置信区间为4.5-14.5个月。本程序在附录G中有更详细的说明。 该估计在计算机视觉算法进展率(Erdil和Besiroglu 2022)、强化学习的样本效率改进(Dorner 2021)以及特定输入大小下常见算法家族的估计速率的置信区间范围内。总的来说,论文的研究结果表明,语言模型的算法进展与之前研究的领域中算法和软件的进展速度相当,而且可能更快(见图1)。
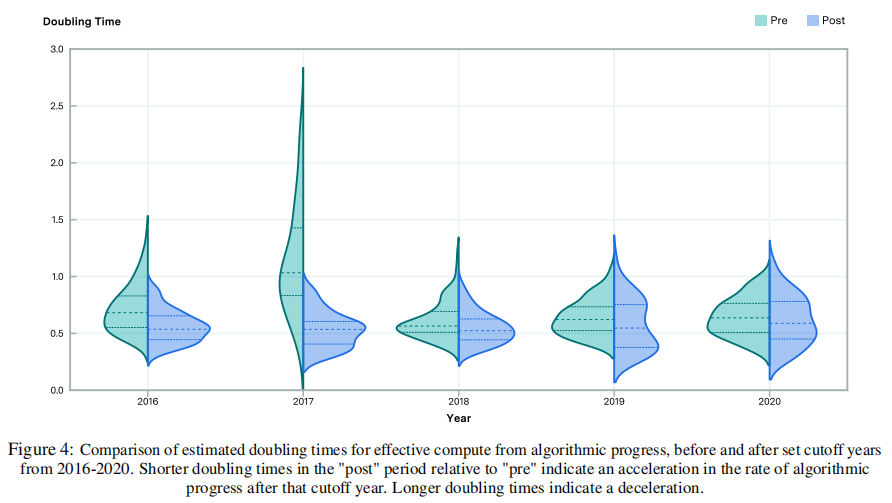
虽然论文的模型的结构不适合分析算法改进速度上的细粒度加速或减速,但论文仍然可以测试增长率在整个时间段内一次性增加或减少的可能性。为此,论文考虑了论文的首选模型(模型7)的一个变体,其中引入了一个虚拟变量——对于在某一年开始之前发布的任何模型,这都等于0,否则为1。这允许论文考虑在某一年的截止时间前后倍增时间(例如2017年),论文对几个这样的截止时间进行分析。 其结果如图4所示。在这里,论文可以看到,2017年初前后估计的倍增时间的差异非常明显,但截止年份的其他选择并非如此。在每一年,截止年开始后,中位数的倍增时间都要快,但通常只是略快。总的来说,这并没有提供算法进步的急剧加速的有力证据。这并不排除效应量较弱的可能性,因为论文的方法在统计上的动力不足。
通过观察来自不同模型的预测,论文进一步检验了这个结果的稳健性。特别是,因为论文使用留一交叉验证来执行模型选择,所以论文可以将论文的首选模型的预测与论文所考虑的其他模型的预测进行比较。根据论文的交叉验证练习,连接前10个模型的倍增时间估计数,论文发现中位倍增时间为7.8个月[95%CI:1.5-17.6个月],这与论文所首选的模型相似。 另一种方法依赖于计算方案,而不是倍增时间的封闭解。论文首先计算通过加倍计算预算来实现的损失∆L的减少,假设N和D在估计的模型下是最优的。然后,论文确定了算法改进所需的时间,以产生等效的损失∆L减少。结果表明,这些方法产生的结果几乎相同,中位数的倍增时间为8.6个月,95%的置信区间为4.5-14.5个月。本程序在附录G中有更详细的说明。 该估计在计算机视觉算法进展率(Erdil和Besiroglu 2022)、强化学习的样本效率改进(Dorner 2021)以及特定输入大小下常见算法家族的估计速率的置信区间范围内。总的来说,论文的研究结果表明,语言模型的算法进展与之前研究的领域中算法和软件的进展速度相当,而且可能更快(见图1)。
虽然论文的模型的结构不适合分析算法改进速度上的细粒度加速或减速,但论文仍然可以测试增长率在整个时间段内一次性增加或减少的可能性。为此,论文考虑了论文的首选模型(模型7)的一个变体,其中引入了一个虚拟变量——对于在某一年开始之前发布的任何模型,这都等于0,否则为1。这允许论文考虑在某一年的截止时间前后倍增时间(例如2017年),论文对几个这样的截止时间进行分析。 其结果如图4所示。在这里,论文可以看到,2017年初前后估计的倍增时间的差异非常明显,但截止年份的其他选择并非如此。在每一年,截止年开始后,中位数的倍增时间都要快,但通常只是略快。总的来说,这并没有提供算法进步的急剧加速的有力证据。这并不排除效应量较弱的可能性,因为论文的方法在统计上的动力不足。
 3.2最近的下一个令牌预测的性能提高都来自于计算scaling 天真地推断论文估计的倍增时间表明,在2014年到2023年之间,预训练算法的进步使性能提高了大约22000倍的计算。与此同时,自深度学习开始以来,物理计算预算大约每6个月就增加一倍,包括语言模型。这表明,物理计算增长了大约100万倍。这描绘了一幅程式化的画面,自2014年以来,“有效计算”增长了约220亿倍,几乎三分之二的规模是由于实际物理计算资源的使用增加。
3.2最近的下一个令牌预测的性能提高都来自于计算scaling 天真地推断论文估计的倍增时间表明,在2014年到2023年之间,预训练算法的进步使性能提高了大约22000倍的计算。与此同时,自深度学习开始以来,物理计算预算大约每6个月就增加一倍,包括语言模型。这表明,物理计算增长了大约100万倍。这描绘了一幅程式化的画面,自2014年以来,“有效计算”增长了约220亿倍,几乎三分之二的规模是由于实际物理计算资源的使用增加。
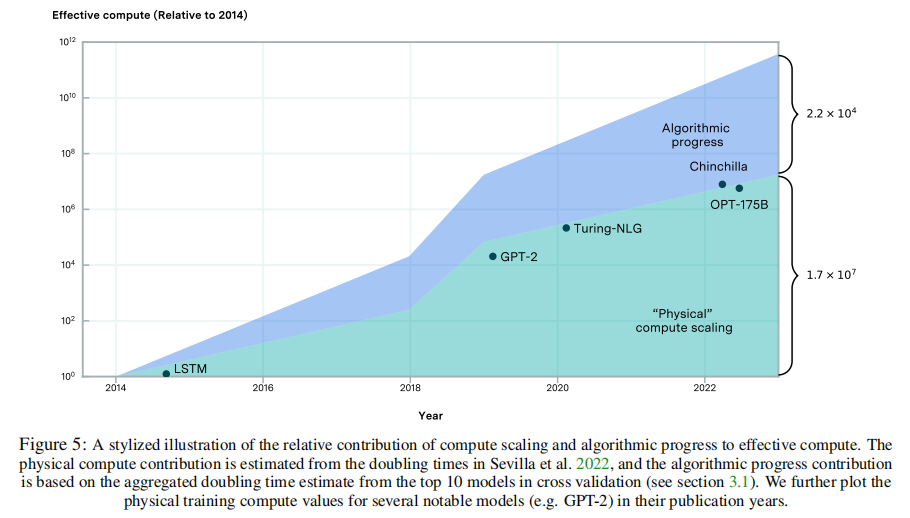 论文有理由对这种幼稚的推理保持谨慎。首先,论文并没有在数据集中的任何地方直接观察到22,000倍(甚至10,000倍)的增益。然而,考虑到早期的研究人员不太可能用大量的计算来训练语言模型,因此论文不太可能在分析的时间段内观察到如此大的下降。然而,缺乏这样的观察结果仍然提出了关于在长时间的多年时期之间推断这些趋势的可靠性的问题。 值得注意的一个具体原因是,推理法忽略了算法创新的规模依赖性。随着时间的推移,随着模型在更大的计算规模上进行训练,一些算法创新可能会变得过时——例如,特定标记器或超参数设置的有效性可能会降低,使它们对未来更大的模型不那么有用。相反,最近的创新在更小的规模上实施时,比现在的模型可能无法产生很大的或任何好处。例如,从scaling law中获得的收益与所使用的计算规模有关(见附录B),而较老的体系结构,如LSTM和卷积网络,可以在相对于transformer的小尺度上表现出更高的效率。 虽然倍增时间的简单外推预测了计算需求的大幅减少,但论文的工作并没有提供令人信服的证据,证明论文可以在当前或未来通过应用完整的现代创新来训练非常小的模型来实现更大的模型的性能。算法改进的规模依赖性,以及在论文的数据集中缺乏对如此大的效率提高的直接观察,这表明需要进一步的研究和更全面的数据来验证这些外推。 除了倍增时间外,论文还可以分解算法的相对贡献,并通过直接评估论文估计的模型来计算比例。鉴于论文的模型是非线性的,因此不可能简单地将性能改进归因于计算、数据的扩展和基于系数比的算法的改进。因此,论文使用Shapley值分析,其中论文估计了每个因素在减少预测困惑方面的平均预期边际贡献。这一分析微弱地支持了上面的程式化图,即自2014年以来,计算scaling在解释性能改进方面比算法的进步更重要。 研究结果表明,算法进步对性能改进的相对贡献随着时间的推移而减少,至少在历史上接近最先进技术的模型数据集中是如此。这一观察结果与图5中的程式化表示以及Erdil和Besiroglu对计算机视觉的发现一致,在计算机视觉中,计算随着时间的推移,scaling显示出越来越重要。 对算法进步的相对贡献不断减少的一种解释是,对扩大物理计算的投资已经大幅增加,超过了算法改进的速度。
相对于基本算法或架构的变化,这一框架在过去几年中与对大型语言模型的重视相一致,特别是自2019年引入GPT-2以来。图5说明了这一观点的一个程式化版本,描述了2018-2019年前后物理计算比例的急剧增加,随后恢复到之前的计算比例增长率。 还有其他可能的解释——例如,transformer架构可能是一个关键的创新(见第3.3节),而随后的算法进步则不那么重要。另外,这一观察结果也可以用算法创新速度的长期下降来解释。然而,论文发现这两种解释不如图4的结果令人信服,在图4中,算法的进展速度并没有明显下降(例如2018年截止)。如果说有什么不同的话,那就是概率略有上升,这与这两种解释所预测的相反。
论文有理由对这种幼稚的推理保持谨慎。首先,论文并没有在数据集中的任何地方直接观察到22,000倍(甚至10,000倍)的增益。然而,考虑到早期的研究人员不太可能用大量的计算来训练语言模型,因此论文不太可能在分析的时间段内观察到如此大的下降。然而,缺乏这样的观察结果仍然提出了关于在长时间的多年时期之间推断这些趋势的可靠性的问题。 值得注意的一个具体原因是,推理法忽略了算法创新的规模依赖性。随着时间的推移,随着模型在更大的计算规模上进行训练,一些算法创新可能会变得过时——例如,特定标记器或超参数设置的有效性可能会降低,使它们对未来更大的模型不那么有用。相反,最近的创新在更小的规模上实施时,比现在的模型可能无法产生很大的或任何好处。例如,从scaling law中获得的收益与所使用的计算规模有关(见附录B),而较老的体系结构,如LSTM和卷积网络,可以在相对于transformer的小尺度上表现出更高的效率。 虽然倍增时间的简单外推预测了计算需求的大幅减少,但论文的工作并没有提供令人信服的证据,证明论文可以在当前或未来通过应用完整的现代创新来训练非常小的模型来实现更大的模型的性能。算法改进的规模依赖性,以及在论文的数据集中缺乏对如此大的效率提高的直接观察,这表明需要进一步的研究和更全面的数据来验证这些外推。 除了倍增时间外,论文还可以分解算法的相对贡献,并通过直接评估论文估计的模型来计算比例。鉴于论文的模型是非线性的,因此不可能简单地将性能改进归因于计算、数据的扩展和基于系数比的算法的改进。因此,论文使用Shapley值分析,其中论文估计了每个因素在减少预测困惑方面的平均预期边际贡献。这一分析微弱地支持了上面的程式化图,即自2014年以来,计算scaling在解释性能改进方面比算法的进步更重要。 研究结果表明,算法进步对性能改进的相对贡献随着时间的推移而减少,至少在历史上接近最先进技术的模型数据集中是如此。这一观察结果与图5中的程式化表示以及Erdil和Besiroglu对计算机视觉的发现一致,在计算机视觉中,计算随着时间的推移,scaling显示出越来越重要。 对算法进步的相对贡献不断减少的一种解释是,对扩大物理计算的投资已经大幅增加,超过了算法改进的速度。
相对于基本算法或架构的变化,这一框架在过去几年中与对大型语言模型的重视相一致,特别是自2019年引入GPT-2以来。图5说明了这一观点的一个程式化版本,描述了2018-2019年前后物理计算比例的急剧增加,随后恢复到之前的计算比例增长率。 还有其他可能的解释——例如,transformer架构可能是一个关键的创新(见第3.3节),而随后的算法进步则不那么重要。另外,这一观察结果也可以用算法创新速度的长期下降来解释。然而,论文发现这两种解释不如图4的结果令人信服,在图4中,算法的进展速度并没有明显下降(例如2018年截止)。如果说有什么不同的话,那就是概率略有上升,这与这两种解释所预测的相反。
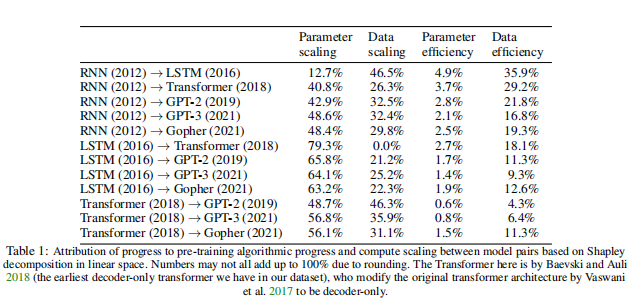 3.3transformer架构的意义 自2017年推出以来,transformer架构已成为语言建模中的主导算法架构,形成了多个著名系统的基础。transformer也被广泛应用于视觉模型中,并且有丰富的现有文献评估了transformer架构与其他视觉架构相比的优点。 论文试图根据“计算等效增益”来量化transformer体系结构对数据集中其他体系结构(lstm、rnn、state space model等)的贡献。这类似于戴维森等人2023年中概述的方法——在这种情况下,计算等效增益是必须调整训练计算以提高基准性能的量,与引入transformer的相同的量。例如,Eernandeds和T. Brown 2020发现transformer(2017)在WMT-14-EN-FR基准上实现了与Seq2Seq(2014)模型相同的性能,计算量少61倍。 为了获取transformer所代表的改进,论文修改了论文的核心模型如下:
3.3transformer架构的意义 自2017年推出以来,transformer架构已成为语言建模中的主导算法架构,形成了多个著名系统的基础。transformer也被广泛应用于视觉模型中,并且有丰富的现有文献评估了transformer架构与其他视觉架构相比的优点。 论文试图根据“计算等效增益”来量化transformer体系结构对数据集中其他体系结构(lstm、rnn、state space model等)的贡献。这类似于戴维森等人2023年中概述的方法——在这种情况下,计算等效增益是必须调整训练计算以提高基准性能的量,与引入transformer的相同的量。例如,Eernandeds和T. Brown 2020发现transformer(2017)在WMT-14-EN-FR基准上实现了与Seq2Seq(2014)模型相同的性能,计算量少61倍。 为了获取transformer所代表的改进,论文修改了论文的核心模型如下:
 其中,σ: R→(0,1)为sigmoid函数,由σ(x) = 1/(1 + e−x)给出。γT是一个常数,所有其他术语都具有与原始模型中相同的含义。关键的直觉是,transformer可以使论文能够比它之前的架构更有效地使用计算(或数据)。 经过预处理后,论文的数据集包含103个transformer模型和127个非transformer模型,主要由循环网络组成,如LSTM。根据该数据拟合模型表明,transformer结构通常可按比例降低4.6% [95% CI: 3.0%,7.0%]。 论文可以用“计算等效增益”来计算其贡献:论文首先计算具有N和D的transformer的预测损耗,以及具有相同输入的非transformer的预测损耗。然后,论文确定N和D的减少,以匹配损失的差异。然后计算近似,如C≈6ND。简而言之,如果一个创新将实现特定损失所需的计算量减少一半,那么该创新的计算等效增益为2。 基于100次自举,论文获得了transformer的计算等效增益的中值估计为7.2×[95%CI:3.3×,45.7×]。这一可观的增益表明,transformer架构提供的效率约相当于log (7)/ log(2e4),占过去9年算法总增益的20%,或该领域近2年的算法进步。此外,如果transformer架构还提供了一种方便的工具,通过它可以有效地传输计算,从而通过计算的scaling促进了一些增益,这些增益很可能主导了论文最近看到的总体增益。 这里需要注意的是,transformer的测量显著性可能取决于如何评估它。例如,transformer可能比循环网络更能适应长上下文,并且使用更长上下文(如>1000个token)可能表明transformer比使用更短的上下文的评估有更大的改进。论文在这里没有明确地控制上下文长度,论文在附录E.2.1中更详细地讨论了这个假设的潜在影响。
四、讨论和结论
4.1对论文的发现的总结
本文对2012-2023年语言模型预训练的算法进展进行了全面的实证分析。通过在 WikiText 和Penn Treebank基准上管理超过200种语言模型评估的数据集,论文量化了计算scaling和算法效率提高对总体性能增益的相对贡献。论文的主要发现如下:
首先,论文估计,自2012年以来,达到集合语言建模性能水平所需的计算量平均每8-9个月减少了一半。这一速度大大超过了摩尔定律的硬件收益,并使语言建模与计算机视觉和强化学习一起成为算法进步最快的领域之一。这支持了一种普遍的直觉,即语言建模是计算机科学中一个异常快速发展的领域。
其次,论文的工作表明,最近在语言建模方面的大部分进展更多地来自于scaling模型和数据集,而不是来自于预训练的算法创新。基于Shapley值的分析表明,60-95%的性能提高来自于计算scaling,而算法仅贡献了5-40%。
第三,2017年引入的transformer架构是算法的重大进步,计算等效增益为3倍到46倍,占过去十年预训练语言模型中算法创新的10%以上。这突出了transformer作为该领域的一个关键框架突破的意义。
4.2限制
虽然论文的分析是量化算法进展方面的进步,但一些限制降低了论文的精度,降低了论文估计的信心:
缺乏对特定创新所获得的收益的估计。论文的模型被指定用来量化算法在相对较大的时间段内(例如在几年)的进展。然而,它无法提供可靠的细粒度信息,如在较短的时间尺度内取得的进展,或特定创新的重要性。实验工作更适合于估计特定算法创新的效率增益。
高质量数据的可用性有限。论文在分析中使用的方法在很大程度上依赖于多年来的数据样本。这被证明是非常具有挑战性的,原因有很多——例如,模型并不总是在同一基准上进行评估,2017年之前的数据相对稀疏,论文可能不报告相关信息,如参数量。在其他原因中,这可能导致论文的估计非常嘈杂,产生广泛的置信区间。此外,算法的改进和scaling历来是同时引入的,在论文的数据集中,这两者之间的相关性使得很难理清它们对总体有效计算增长的相对贡献。
模型训练和评估中的不一致。评估中的不一致是众所周知的。虽然论文已经从数据集中排除了非标准评估,但论文的数据集跨越了具有不同标记化方案、文本预处理、步长和其他细节的模型。这在论文对算法进展的估计中引入了噪声和潜在的偏差,因为随着时间的推移,研究人员可能会采用更有利的评估方案。然而,论文估计算法改进的困惑减少很大;可能比评估程序的变化所能解释的要大。论文将在附录E.2.3中扩展一下这些点。
无法在数据使用中区分数据质量和效率。论文在本文中定义效率改进的方式是,随着时间的推移,减少达到一定性能水平所需的资源数量。然而,在数据效率的情况下,这遇到了一个问题——论文测量到的数据需求的减少是由于数据质量的提高,还是由于算法使用数据的能力的改进?这不是一个论文的模型能回答的问题。因此,值得注意的是,论文测量的计算需求的减少与算法改进和数据质量改进有关,它们的相对贡献可能是未来研究的一个主题。
依赖于Chinchilla scaling law。论文的模型推导出的scaling law适用于遵循GPT-3架构的密集transformer。论文使用这个scaling law来建模不同transformer架构、递归神经网络等的算法改进。未来的算法也可能遵循不同的scaling law。然而,论文相信论文的核心结果很可能仍然成立:首先,神经scaling并不是一种局限于transformer的现象。论文发现广泛的统计模型结构提供一致的估计,和替代方法估计预训练算法进展也给类似的结果(见附录),所以很可能论文的核心结果是鲁棒的。
对未来进展的了解有限。虽然本文的结果可以用来告知语言建模的未来进展,但论文的论文的重点是历史的改进。未来的进展速度可能会更慢,但它们也可能会更快(例如,由于研究兴趣和投资的增加)。对未来进展的期望需要考虑到这些因素,论文大部分没有深入讨论。
4.3结论
使用Wikitext 和 Penn Treebank上2012-2023年的200多个语言模型评估数据集,论文发现达到固定性能阈值所需的计算大约每8个月减少一半。这比摩尔定律和许多其他计算领域的速率要快得多。虽然算法创新发生迅速,但计算规模在同一时期扩展了100万倍,超过了算法的收益,构成了近年来性能改进的主要来源。
总的来说,论文的工作提供了一个对语言建模的快速发展速度的定量估计。它还揭示了计算规模对最近的收益的起主导作用而不是算法进步。未来的工作可以受益于将这种分析扩展到额外的、具体的基准,并更仔细地检查数据质量改进的影响和其他具体创新的成果。尽管有其局限性,但这项研究证明了可以从对机器学习结果的广泛数据集的详细统计分析中获得的有价值的见解。通过确定绩效改进的主要驱动因素,这项工作为进一步探索和理解该领域的这些趋势奠定了基础。
其中,σ: R→(0,1)为sigmoid函数,由σ(x) = 1/(1 + e−x)给出。γT是一个常数,所有其他术语都具有与原始模型中相同的含义。关键的直觉是,transformer可以使论文能够比它之前的架构更有效地使用计算(或数据)。 经过预处理后,论文的数据集包含103个transformer模型和127个非transformer模型,主要由循环网络组成,如LSTM。根据该数据拟合模型表明,transformer结构通常可按比例降低4.6% [95% CI: 3.0%,7.0%]。 论文可以用“计算等效增益”来计算其贡献:论文首先计算具有N和D的transformer的预测损耗,以及具有相同输入的非transformer的预测损耗。然后,论文确定N和D的减少,以匹配损失的差异。然后计算近似,如C≈6ND。简而言之,如果一个创新将实现特定损失所需的计算量减少一半,那么该创新的计算等效增益为2。 基于100次自举,论文获得了transformer的计算等效增益的中值估计为7.2×[95%CI:3.3×,45.7×]。这一可观的增益表明,transformer架构提供的效率约相当于log (7)/ log(2e4),占过去9年算法总增益的20%,或该领域近2年的算法进步。此外,如果transformer架构还提供了一种方便的工具,通过它可以有效地传输计算,从而通过计算的scaling促进了一些增益,这些增益很可能主导了论文最近看到的总体增益。 这里需要注意的是,transformer的测量显著性可能取决于如何评估它。例如,transformer可能比循环网络更能适应长上下文,并且使用更长上下文(如>1000个token)可能表明transformer比使用更短的上下文的评估有更大的改进。论文在这里没有明确地控制上下文长度,论文在附录E.2.1中更详细地讨论了这个假设的潜在影响。
四、讨论和结论
4.1对论文的发现的总结
本文对2012-2023年语言模型预训练的算法进展进行了全面的实证分析。通过在 WikiText 和Penn Treebank基准上管理超过200种语言模型评估的数据集,论文量化了计算scaling和算法效率提高对总体性能增益的相对贡献。论文的主要发现如下:
首先,论文估计,自2012年以来,达到集合语言建模性能水平所需的计算量平均每8-9个月减少了一半。这一速度大大超过了摩尔定律的硬件收益,并使语言建模与计算机视觉和强化学习一起成为算法进步最快的领域之一。这支持了一种普遍的直觉,即语言建模是计算机科学中一个异常快速发展的领域。
其次,论文的工作表明,最近在语言建模方面的大部分进展更多地来自于scaling模型和数据集,而不是来自于预训练的算法创新。基于Shapley值的分析表明,60-95%的性能提高来自于计算scaling,而算法仅贡献了5-40%。
第三,2017年引入的transformer架构是算法的重大进步,计算等效增益为3倍到46倍,占过去十年预训练语言模型中算法创新的10%以上。这突出了transformer作为该领域的一个关键框架突破的意义。
4.2限制
虽然论文的分析是量化算法进展方面的进步,但一些限制降低了论文的精度,降低了论文估计的信心:
缺乏对特定创新所获得的收益的估计。论文的模型被指定用来量化算法在相对较大的时间段内(例如在几年)的进展。然而,它无法提供可靠的细粒度信息,如在较短的时间尺度内取得的进展,或特定创新的重要性。实验工作更适合于估计特定算法创新的效率增益。
高质量数据的可用性有限。论文在分析中使用的方法在很大程度上依赖于多年来的数据样本。这被证明是非常具有挑战性的,原因有很多——例如,模型并不总是在同一基准上进行评估,2017年之前的数据相对稀疏,论文可能不报告相关信息,如参数量。在其他原因中,这可能导致论文的估计非常嘈杂,产生广泛的置信区间。此外,算法的改进和scaling历来是同时引入的,在论文的数据集中,这两者之间的相关性使得很难理清它们对总体有效计算增长的相对贡献。
模型训练和评估中的不一致。评估中的不一致是众所周知的。虽然论文已经从数据集中排除了非标准评估,但论文的数据集跨越了具有不同标记化方案、文本预处理、步长和其他细节的模型。这在论文对算法进展的估计中引入了噪声和潜在的偏差,因为随着时间的推移,研究人员可能会采用更有利的评估方案。然而,论文估计算法改进的困惑减少很大;可能比评估程序的变化所能解释的要大。论文将在附录E.2.3中扩展一下这些点。
无法在数据使用中区分数据质量和效率。论文在本文中定义效率改进的方式是,随着时间的推移,减少达到一定性能水平所需的资源数量。然而,在数据效率的情况下,这遇到了一个问题——论文测量到的数据需求的减少是由于数据质量的提高,还是由于算法使用数据的能力的改进?这不是一个论文的模型能回答的问题。因此,值得注意的是,论文测量的计算需求的减少与算法改进和数据质量改进有关,它们的相对贡献可能是未来研究的一个主题。
依赖于Chinchilla scaling law。论文的模型推导出的scaling law适用于遵循GPT-3架构的密集transformer。论文使用这个scaling law来建模不同transformer架构、递归神经网络等的算法改进。未来的算法也可能遵循不同的scaling law。然而,论文相信论文的核心结果很可能仍然成立:首先,神经scaling并不是一种局限于transformer的现象。论文发现广泛的统计模型结构提供一致的估计,和替代方法估计预训练算法进展也给类似的结果(见附录),所以很可能论文的核心结果是鲁棒的。
对未来进展的了解有限。虽然本文的结果可以用来告知语言建模的未来进展,但论文的论文的重点是历史的改进。未来的进展速度可能会更慢,但它们也可能会更快(例如,由于研究兴趣和投资的增加)。对未来进展的期望需要考虑到这些因素,论文大部分没有深入讨论。
4.3结论
使用Wikitext 和 Penn Treebank上2012-2023年的200多个语言模型评估数据集,论文发现达到固定性能阈值所需的计算大约每8个月减少一半。这比摩尔定律和许多其他计算领域的速率要快得多。虽然算法创新发生迅速,但计算规模在同一时期扩展了100万倍,超过了算法的收益,构成了近年来性能改进的主要来源。
总的来说,论文的工作提供了一个对语言建模的快速发展速度的定量估计。它还揭示了计算规模对最近的收益的起主导作用而不是算法进步。未来的工作可以受益于将这种分析扩展到额外的、具体的基准,并更仔细地检查数据质量改进的影响和其他具体创新的成果。尽管有其局限性,但这项研究证明了可以从对机器学习结果的广泛数据集的详细统计分析中获得的有价值的见解。通过确定绩效改进的主要驱动因素,这项工作为进一步探索和理解该领域的这些趋势奠定了基础。