什么是线程复用
在Java中,我们正常创建线程执行任务,一般都是一条线程绑定一个Runnable执行任务。而Runnable实际只是一个普通接口,真正要执行,则还是利用了Thread类的run方法。这个rurn方法由native本地方法start0进行调用。我们看Thread类的run方法实现
/* What will be run. */
private Runnable target;
/**
* If this thread was constructed using a separate
* <code>Runnable</code> run object, then that
* <code>Runnable</code> object's <code>run</code> method is called;
* otherwise, this method does nothing and returns.
* <p>
* Subclasses of <code>Thread</code> should override this method.
*
* @see #start()
* @see #stop()
* @see #Thread(ThreadGroup, Runnable, String)
*/
@Override
public void run() {
if (target != null) {
target.run();
}
}很明显,Thread类的run方法就是使用构造Thread类传入来的Runnable对象,执行Runnable的run方法。这样可以很好的将任务和Thread类解耦,如果继承Thread类再去重写run方法当然也是可以,但却耦合了,并且Java是单继承,所以继承Thread类这种方式通常不会使用,没有任何好处。
现在问题是,一个线程只能执行一个Runnable对象,那么这条线程它就是不能复用的,完成任务它就该Terminated了。如果系统任务很多,频繁创建线程带来的开销大,线程数量不可控导致系统处于一种不安全的状况,系统随时可能被大量线程搞跨,于是线程池就出现了。线程池要解决的问题就是用少量线程处理更多的任务,这样一来,线程池首先要实现的就是线程复用。不能说还是一条线程只处理一个Runnable任务,而是一条线程处理无数Runnable任务。最容易想到的方案就是将Runnable对象放到队列中,在Thread类的run方法中不断从队列中拉取任务执行,这样一来就实现了线程复用。当然,实际线程池也差不多是这么干的,下面我们详细看一下线程池实现线程复用的原理。
线程池处理任务的过程
在线程池原理解析1中有详述线程池创建线程及处理任务的过程。这里再次简单看一下流程图以方便理解下面的线程复用原理解析。
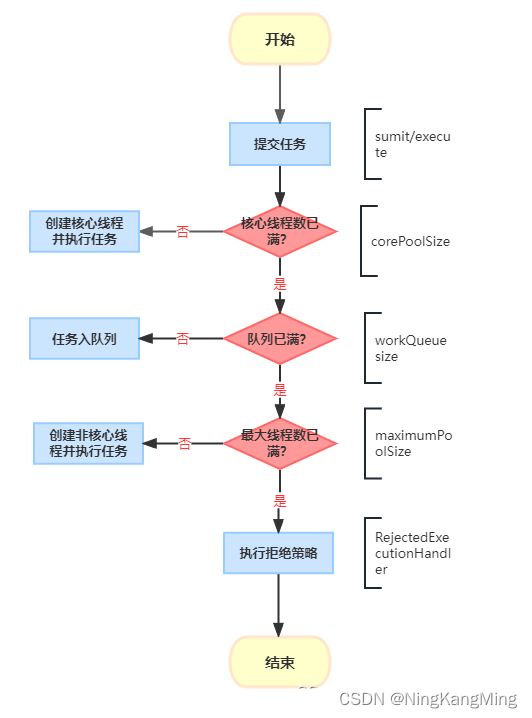
线程复用原理解析
线程处理任务过程源码解析
首先我们看看线程池是怎么使用的
import cn.hutool.core.thread.ThreadFactoryBuilder;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.ThreadFactory;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
/**
* @author kangming.ning
* @date 2023-02-24 16:27
* @since 1.0
**/
public class CustomThreadPool1 {
private static ThreadFactory threadFactory = new ThreadFactoryBuilder().setNamePrefix("线程池-").build();
private static ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(
Runtime.getRuntime().availableProcessors(),
Runtime.getRuntime().availableProcessors() * 2,
60L,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(10),
threadFactory, new ThreadPoolExecutor.CallerRunsPolicy());
public static void main(String[] args) throws InterruptedException {
Runnable r = () -> {
System.out.println(Thread.currentThread().getName() + " is running");
};
for (int i = 0; i < 35; i++) {
Thread.sleep(1000);
threadPoolExecutor.submit(r);
}
}
}可见,threadPoolExecutor的sumit方法就是用来提交任务的,于是,从这个方法开始分析源码,把源码的关注点放在线程复用部分。
/**
* @throws RejectedExecutionException {@inheritDoc}
* @throws NullPointerException {@inheritDoc}
*/
public Future<?> submit(Runnable task) {
if (task == null) throw new NullPointerException();
RunnableFuture<Void> ftask = newTaskFor(task, null);
execute(ftask);
return ftask;
}第一句只是用来包装一下有返回值的任务,不必关注,重点看execute(ftask)这句。
/**
* Executes the given task sometime in the future. The task
* may execute in a new thread or in an existing pooled thread.
*
* If the task cannot be submitted for execution, either because this
* executor has been shutdown or because its capacity has been reached,
* the task is handled by the current {@code RejectedExecutionHandler}.
*
* @param command the task to execute
* @throws RejectedExecutionException at discretion of
* {@code RejectedExecutionHandler}, if the task
* cannot be accepted for execution
* @throws NullPointerException if {@code command} is null
*/
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
/*
* Proceed in 3 steps:
*
* 1. If fewer than corePoolSize threads are running, try to
* start a new thread with the given command as its first
* task. The call to addWorker atomically checks runState and
* workerCount, and so prevents false alarms that would add
* threads when it shouldn't, by returning false.
*
* 2. If a task can be successfully queued, then we still need
* to double-check whether we should have added a thread
* (because existing ones died since last checking) or that
* the pool shut down since entry into this method. So we
* recheck state and if necessary roll back the enqueuing if
* stopped, or start a new thread if there are none.
*
* 3. If we cannot queue task, then we try to add a new
* thread. If it fails, we know we are shut down or saturated
* and so reject the task.
*/
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}代码量不多,信息量极大。注释的内容就是在解释线程池执行任务的处理过程,这个看上面的流程图即可。任务如果为空直接抛空指针异常。下面看第一个if语句
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}如果worker数量少于核心线程数,则通过addWorker(command, true)方法添加一个worker。这里要注意,线程池把每一条线程都封装成了Worker的实例。
addWorker方法的作用是在线程池中创建一个线程并执行第一个参数传入的任务,它的第二个参数是个boolean值,如果传入 true 则代表增加线程时判断当前线程是否少于 corePoolSize,小于则增加新线程,大于等于则不增加;如果传入false则使用maximumPoolSize来判断是否增加新线程。
接下来看下面第二个if的代码
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}执行到这里说明核心线程数已满或者说addWorker失败了。此时先检查线程池是否为运行状态,是的话直接把任务放队列,这跟上面的流程图是一致的,核心线程数满则放队列。当然当任务提交成功后还是会重新检查线程池的状态,如果线程池没在跑则会移除任务并且执行拒绝策略。再看里面的else if分支
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);进入else if分支说明线程池是在运行的,这里是检查一下是否有线程可供使用,虽说上面已经检查过目前的线程数已大于核心线程数,但不排除核心线程数设置为0 这种情况,这样一来,任务添加后缺没线程去执行,这种情况是不允许的。
再往下看最后一句else if代码
else if (!addWorker(command, false))
reject(command);能执行到这里,说明要么是线程池不在运行中,要么就是核心线程和队列都满了,此时需要开启线程池的后备力量,尝试添加非核心线程直到线程数达到最大线程数限制,注意到addWorker方法第二个参数传了false,正是添加线程时使用最大线程数限制来判断是否添加新线程。假设添加失败意味着最大线程数也达到了最大值并且没空闲线程去执行当前任务,此时执行reject拒绝策略。
线程复用源码解析
通过上面的解析我们可以看到,添加线程以执行任务的核心方法是addWorker,大概看一下Worker的代码
/**
* Class Worker mainly maintains interrupt control state for
* threads running tasks, along with other minor bookkeeping.
* This class opportunistically extends AbstractQueuedSynchronizer
* to simplify acquiring and releasing a lock surrounding each
* task execution. This protects against interrupts that are
* intended to wake up a worker thread waiting for a task from
* instead interrupting a task being run. We implement a simple
* non-reentrant mutual exclusion lock rather than use
* ReentrantLock because we do not want worker tasks to be able to
* reacquire the lock when they invoke pool control methods like
* setCorePoolSize. Additionally, to suppress interrupts until
* the thread actually starts running tasks, we initialize lock
* state to a negative value, and clear it upon start (in
* runWorker).
*/
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable
{
/**
* This class will never be serialized, but we provide a
* serialVersionUID to suppress a javac warning.
*/
private static final long serialVersionUID = 6138294804551838833L;
/** Thread this worker is running in. Null if factory fails. */
final Thread thread;
/** Initial task to run. Possibly null. */
Runnable firstTask;
/** Per-thread task counter */
volatile long completedTasks;
/**
* Creates with given first task and thread from ThreadFactory.
* @param firstTask the first task (null if none)
*/
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
/** Delegates main run loop to outer runWorker */
public void run() {
runWorker(this);
}
// Lock methods
//
// The value 0 represents the unlocked state.
// The value 1 represents the locked state.
protected boolean isHeldExclusively() {
return getState() != 0;
}
protected boolean tryAcquire(int unused) {
if (compareAndSetState(0, 1)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
}
protected boolean tryRelease(int unused) {
setExclusiveOwnerThread(null);
setState(0);
return true;
}
public void lock() { acquire(1); }
public boolean tryLock() { return tryAcquire(1); }
public void unlock() { release(1); }
public boolean isLocked() { return isHeldExclusively(); }
void interruptIfStarted() {
Thread t;
if (getState() >= 0 && (t = thread) != null && !t.isInterrupted()) {
try {
t.interrupt();
} catch (SecurityException ignore) {
}
}
}
}可见,Worker对Thread进行了封装,它本身也是一个Runnable对象,内部的Thread对象则是真正用来执行任务的线程对象。因此添加Worker实则就是在线程池中添加运行任务的线程,可以看出在Worker的构造函数中新建了一条线程并且把引用赋值给了thread对象。而在上面的addWorker方法中start了这条线程,而这条线程的Runnable对象正是Worker对象自身。
/**
* Creates with given first task and thread from ThreadFactory.
* @param firstTask the first task (null if none)
*/
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}既然addWorker方法执行了线程的start方法,因此Worker类里面的run方法将被系统调度
/** Delegates main run loop to outer runWorker */
public void run() {
runWorker(this);
}里面只有一个runWorker方法,并且把Worker对象传了进去,明显,runWorker是实现线程复用的方法 。
/**
* Main worker run loop. Repeatedly gets tasks from queue and
* executes them, while coping with a number of issues:
*
* 1. We may start out with an initial task, in which case we
* don't need to get the first one. Otherwise, as long as pool is
* running, we get tasks from getTask. If it returns null then the
* worker exits due to changed pool state or configuration
* parameters. Other exits result from exception throws in
* external code, in which case completedAbruptly holds, which
* usually leads processWorkerExit to replace this thread.
*
* 2. Before running any task, the lock is acquired to prevent
* other pool interrupts while the task is executing, and then we
* ensure that unless pool is stopping, this thread does not have
* its interrupt set.
*
* 3. Each task run is preceded by a call to beforeExecute, which
* might throw an exception, in which case we cause thread to die
* (breaking loop with completedAbruptly true) without processing
* the task.
*
* 4. Assuming beforeExecute completes normally, we run the task,
* gathering any of its thrown exceptions to send to afterExecute.
* We separately handle RuntimeException, Error (both of which the
* specs guarantee that we trap) and arbitrary Throwables.
* Because we cannot rethrow Throwables within Runnable.run, we
* wrap them within Errors on the way out (to the thread's
* UncaughtExceptionHandler). Any thrown exception also
* conservatively causes thread to die.
*
* 5. After task.run completes, we call afterExecute, which may
* also throw an exception, which will also cause thread to
* die. According to JLS Sec 14.20, this exception is the one that
* will be in effect even if task.run throws.
*
* The net effect of the exception mechanics is that afterExecute
* and the thread's UncaughtExceptionHandler have as accurate
* information as we can provide about any problems encountered by
* user code.
*
* @param w the worker
*/
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
while (task != null || (task = getTask()) != null) {
w.lock();
// If pool is stopping, ensure thread is interrupted;
// if not, ensure thread is not interrupted. This
// requires a recheck in second case to deal with
// shutdownNow race while clearing interrupt
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task);
Throwable thrown = null;
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}代码不多,注释很多,核心意思就是这是一个死循环,不断从队列获取任务进行执行。通过上面代码可以清晰的看出,一开始将firstTask赋值给task Runnable对象,然后下面有个while死循环,不断的从队列获取task进行执行,里面的核心逻辑就是task.run(),Runnable对象的run方法由这条Worker线程像调用普通方法一样的调用,这个就是线程复用的原理。将Runnable对象放队列,然后在一个主循环里面不断从队列里获取任务进行执行。
最后看一下getTask方法
/**
* Performs blocking or timed wait for a task, depending on
* current configuration settings, or returns null if this worker
* must exit because of any of:
* 1. There are more than maximumPoolSize workers (due to
* a call to setMaximumPoolSize).
* 2. The pool is stopped.
* 3. The pool is shutdown and the queue is empty.
* 4. This worker timed out waiting for a task, and timed-out
* workers are subject to termination (that is,
* {@code allowCoreThreadTimeOut || workerCount > corePoolSize})
* both before and after the timed wait, and if the queue is
* non-empty, this worker is not the last thread in the pool.
*
* @return task, or null if the worker must exit, in which case
* workerCount is decremented
*/
private Runnable getTask() {
boolean timedOut = false; // Did the last poll() time out?
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
// Are workers subject to culling?
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}可见,里面就是从队列里面获取一个Runnable对象进行返回而已。
标签:Runnable,Java,thread,复用,task,线程,run,null From: https://blog.csdn.net/u012882823/article/details/139698289