近年来,深度学习一直在时间序列预测中追赶着提升树模型,其中新的架构已经逐渐为最先进的性能设定了新的标准。
这一切都始于2020年的N-BEATS,然后是2022年的NHITS。2023年,PatchTST和TSMixer被提出,最近的iTransformer进一步提高了深度学习预测模型的性能。
这是2024年4月《SOFTS: Efficient Multivariate Time Series Forecasting with Series-Core Fusion》中提出的新模型,采用集中策略来学习不同序列之间的交互,从而在多变量预测任务中获得最先进的性能。
在本文中,我们详细探讨了SOFTS的体系结构,并介绍新的STar聚合调度(STAD)模块,该模块负责学习时间序列之间的交互。然后,我们测试将该模型应用于单变量和多变量预测场景,并与其他模型作为对比。
SOFTS介绍
SOFTS是 Series-cOre Fused Time Series的缩写,背后的动机来自于长期多元预测对决策至关重要的认识:
首先我们一直研究Transformer的模型,它们试图通过使用补丁嵌入和通道独立等技术(如PatchTST)来降低Transformer的复杂性。但是由于通道独立性,消除了每个序列之间的相互作用,因此可能会忽略预测信息。
iTransformer 通过嵌入整个序列部分地解决了这个问题,并通过注意机制处理它们。但是基于transformer的模型在计算上是复杂的,并且需要更多的时间来训练非常大的数据集。
另一方面有一些基于mlp的模型。这些模型通常很快,并产生非常强的结果,但当存在许多序列时,它们的性能往往会下降。
所以出现了SOFTS:研究人员建议使用基于mlp的STAD模块。由于是基于MLP的,所以训练速度很快。并且STAD模块,它允许学习每个序列之间的关系,就像注意力机制一样,但计算效率更高。
SOFTS架构
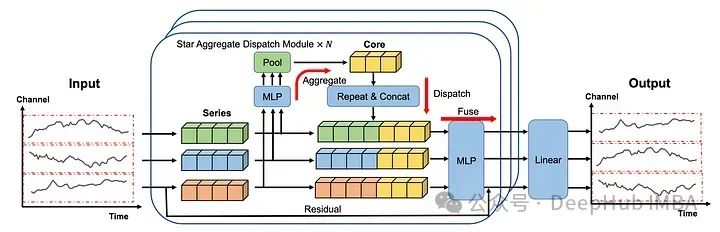
在上图中可以看到每个序列都是单独嵌入的,就像在iTransformer 中一样。
然后将嵌入发送到STAD模块。每个序列之间的交互都是集中学习的,然后再分配到各个系列并融合在一起。
最后再通过线性层产生预测。
这个体系结构中有很多东西需要分析,我们下面更详细地研究每个组件。
https://avoid.overfit.cn/post/6254097fd18d479ba7fd85efcc49abac
标签:预测,示例,Python,Series,模型,STAD,序列,SOFTS From: https://www.cnblogs.com/deephub/p/18249084