前言
最近在看《剑来》小说,但是kindle在线看不方便,而且我在网上找到的只有600多章,目前最新已经更新到了1200章,为了确保后面有书可读,同时也为了巩固下python技能,于是我找到一个免费的网站,然后通过python获取书籍内容,最终将获取到的内容,生成epub电子书,核心内容如下:
- 获取电子书的内容:通过
requests和parsel获取内容 - 生成
epub电子书:通过ebooklib生成电子书
获取电子书
这里主要是通过requests来获取页面内容,并通过parsel来解析页面内容,下面我们介绍下具体操作方法和原理。具体过程仅供参考学习,各位小伙伴请不要搞事情。
安装依赖
这里我们首先安装requests和parsel的依赖:
pip install requests
pip install parsel
获取网页内容
requests我不打算详细讲了,这个库很常用,文档也很多,使用方法本身也不复杂,简单看下文档就可以上手了,这里直接给出一个请求示例:
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Linux; Android 13; MEIZU 18s Build/TKQ1.221114.001) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.5563.116 Mobile Safari/537.36"
}
response = requests.get(url='https://www.baidu.com', headers=headers, verify=False)
response.encoding='gbk'
# 打印页面内容,这里拿到的就是html页面的内容
print(response.text)
解析页面
parsel是也是一个特别常用的三方库,我们可以使用XPath和CSS选择器(可选地与正则表达式结合)的方式,从HTML和XML提取数据的库,官方地址如下:
https://pypi.org/project/parsel/
这里我主要分享css选择器的方式,通过这个库,我们可以像前端jquery的方式解析html,这里给出一个示例,例如我们需要获取如下html中a标签的href和tetxt:
import parsel
html_content = '''
<div class="detail detail-side">
<ul class="myui-vodlist__text col-pd clearfix">
<li>
<a href="/voddetail/129832.html" title="逆天邪神">
<span class="pull-right text-muted" style="color:;">30集全</span> <span class="badge badge-first">1</span>逆天邪神
</a>
</li>
</ul>
</div>
'''
selector1 = parsel.Selector(html_content)
a_selector = contents = selector1.css('.detail li')[0]
href = a_selector.css('a::attr(href)').get()
# 结果:/voddetail/129832.html
print(href)
text = a_selector.css('a::text').getall()
# 打印结果:['\n ', ' \t\t', '逆天邪神 \n ']
print(text)
这里简单介绍下上面的代码:
parsel.Selector(html_content):初始化一个选择器,传入网页内容即可,也可以直接传入response.textselector1.css('.detail li'):这里就是通过css的方式获取页面元素,.detail就对应前端的class,这个和jquery是一样的语法,如果是id方式获取则是#id。我们这里的写法是获取class="detail"下面所有的li标签的元素(子或者孙元素),如果像获取直接子元素这样写:selector1.css('.detail > li > a'):这个就表示选择.detail直接子标签li下面的直接子标签a
a::attr(href)表示获取a标签href的值,也就是标签上的属性,比如style,src,href等a::text表示获取a标签内的内容,由于当前a标签有多个内容,所以通过getall()来获取,get()默认就是获取第一个。
注意:执行过get或者getall之后的对象因为已经不是选择器对象了,所以是不能调用css方法的
完整代码
完整代码如下,隐去了具体网址,再次说明,代码仅供参考,各位小伙伴学习下就行了,不要搞事情。
import requests
import parsel
import urllib3
import os
urllib3.disable_warnings()
requests.packages.urllib3.disable_warnings()
def get_pages(base_url):
results = []
for page in range(4):
page_url =f'{base_url}/jianlai/index{page + 1}.html'
datas = get_page_info(url=page_url, base_url=base_url)
if len(datas) > 0:
results += datas
return results
def get_page_info(url, base_url):
headers = {
"User-Agent": "Mozilla/5.0 (Linux; Android 13; MEIZU 18s Build/TKQ1.221114.001) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.5563.116 Mobile Safari/537.36"
}
response = requests.get(url=url, headers=headers, verify=False)
response.encoding='gbk'
selector1 = parsel.Selector(response.text)
datas = []
contents = selector1.css('.chapter9 > div')
for content in contents:
href = base_url + content.css('a::attr(href)').get()
title = content.css('a::text').get()
datas.append((href, title))
return datas
def get_single_page(url):
headers = {
"User-Agent": "Mozilla/5.0 (Linux; Android 13; MEIZU 18s Build/TKQ1.221114.001) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.5563.116 Mobile Safari/537.36"
}
response = requests.get(url=url, headers=headers, verify=False)
response.encoding='gbk'
selector1 = parsel.Selector(response.text)
contents = selector1.css('#content').get()
return contents
if __name__ == "__main__":
base_url = "https://www.1111.com"
url = f"{base_url}/jianlai/index1.html"
results = get_pages(base_url=base_url)
print(results)
path = './剑来'
if not os.path.exists(path):
os.mkdir(path)
index = 1
for result in results:
with open(f'{path}/{index} {result[1]}.txt', 'w+', encoding='utf-8') as f:
content = get_single_page(result[0])
f.write(content)
index += 1
最终运行的效果是在本地生成如下文件:

生成epub电子书
安装依赖
首先安装ebooklib库,EbokLib是一个用于管理EPUB2/EPUB3和Kindle文件的Python库。它能够以编程方式读取和写入EPUB文件(Kindle支持正在开发中)。
pip install ebooklib
库的仓库地址:
https://github.com/aerkalov/ebooklib
生成电子书
这个三方库我也是第一次使用,还在摸索中,遇到问题各位小伙伴自行搜索。
# 创建EPUB书籍对象
book = epub.EpubBook()
# 设置书籍的元数据
book.set_identifier('id123456') # 书籍的唯一标识符
# 封面
book.set_cover(cover_image, open(cover_image, 'rb').read())
book.set_title(book_title) # 书籍的标题
book.set_language('zh') # 书籍的语言
book.add_author(author) # 书籍的作者
# 创建 CSS 样式
css_text = '''
@namespace epub "http://www.idpf.org/2007/ops";
body { font-family: "Times New Roman", Times, serif; }
p { text-indent: 2em; /* 设置段落首行缩进 */ margin-top: 0; margin-bottom: 1em; }
'''
# 创建一个 CSS 文件对象
style = epub.EpubItem(uid="style", file_name="style/style.css", media_type="text/css", content=css_text)
# 将 CSS 文件添加到 EPUB 书籍中
book.add_item(style)
# 创建前言页面
c1 = epub.EpubHtml(title='前言', file_name='intro.xhtml', lang='zh')
c1.content = f'<html><head></head><body><h1>{book_title}</h1><p>作者:{author}</p><p>{update}</p><p>简介:{introduction}</p></body></html>'
book.add_item(c1)
# 初始化书脊
spine = ['nav', c1]
# 添加章节
for index in sorted(chapters_content.keys()): # 按键排序
chapter = chapters_content[index]
title = chapter['title']
content = chapter['content'] # 将内容包裹在 <p> 标签中
# 创建 EPUB 格式的章节
epub_chapter = epub.EpubHtml(title=title, file_name=f'chapter_{index + 1}.xhtml', lang='zh')
epub_chapter.content = f'<html><head><style type="text/css">{css_text}</style></head><body><h2>{title}</h2>{content}</body></html>'
book.add_item(epub_chapter)
spine.append(epub_chapter)
# 设置书脊
book.spine = spine
# 创建目录列表,开始时包括前言链接
toc = [epub.Link('intro.xhtml', '前言', 'intro')]
# 对于每个章节,添加一个章节链接到目录列表中
for index in sorted(chapters_content.keys()):
chapter = chapters_content[index]
title = chapter['title']
# 创建章节的链接对象
chapter_link = epub.Link(f'chapter_{index + 1}.xhtml', title, f'chapter_{index + 1}')
toc.append(chapter_link)
# 最后,将目录列表设置为书籍的 TOC
book.toc = tuple(toc)
# 添加必要的 EPUB 文件
book.add_item(epub.EpubNcx())
book.add_item(epub.EpubNav())
# 保存 EPUB 文件
epub_path = f'{book_title}.epub'
epub.write_epub(epub_path, book, {})
print(f"EPUB 文件已创建: {epub_path}")
上面注释很详细,需要特殊说明的是,在实际测试过程中,发现css_text并不生效,所以最后我直接把css的样式(比如段落缩进)写在了p标签上。
css样式的调试有个技巧,epub其实是一种压缩文件,所以我们可以通过7-zip直接打开,然后调试其中的xhtml文件即可:
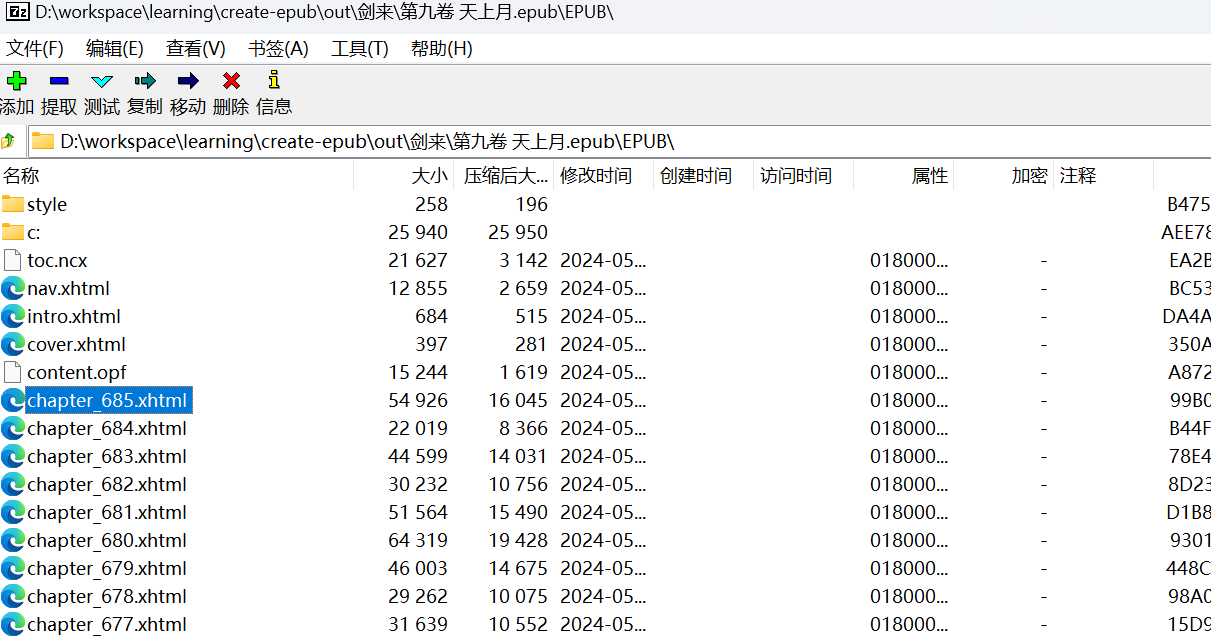
最终,生成的效果如下:

晚点让我试下kindle能否正常打开。
好了,到这里我们今天的内容就结束了,感兴趣的小伙伴自己动手吧
结语
最近写了好多类似的脚本,有搞视频的,搞文档的,还有今天这个搞小说的,最大的体会是要学好python,还是要应用起来,用起来会遇到很多问题,解决问题就会成长,这就是一个孰能生巧的过程。