前言
最近做了一个全文检索的项目,项目之前的架子是别人搭建的,部署方式是docker-compose,到后期这个同事基本上不参与了,后面发布测试的时候,我们觉得这种方式不适合测试环境和线上发版(当然也可能是我们不熟悉,有点不专业了),于是就在他开发的基础上,做了一些调整:
- 修改
Dockerfile:把依赖打进基础镜像中,他之前的基础镜像是ubuntu,然后安装一堆依赖 - 修改配置方式:我们改成
apollo获取,apollo的地址作为环境变量,通过k8s配置。改的时候才发现es的配置竟然是写死的
下面给各位小伙伴分享下具体的优化过程。
解决过程
构建镜像
之前的基础镜像是这样的,很臃肿,也很繁琐:
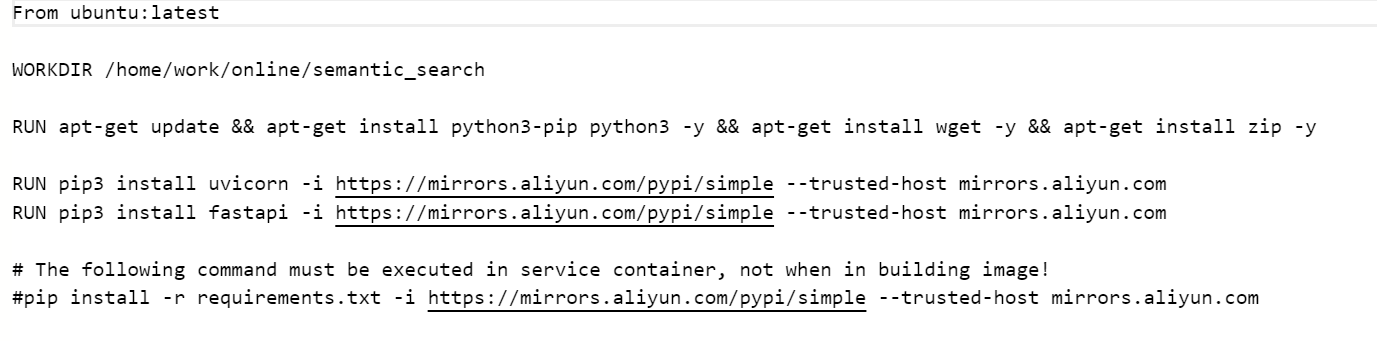
优化之后我们分为两步,第一步先打基础镜像,Dockerfile是这样写的:
# 基于pyhon基础镜像
FROM python:3.10-slim
RUN pip install uvicorn -i https://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.com --no-cache-dir
RUN pip install fastapi -i https://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.com --no-cache-dir
# The following command must be executed in service container, not when in building image!
RUN pip install elasticsearch==6.3 -i https://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.com --no-cache-dir
RUN pip install pandas -i https://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.com --no-cache-dir
RUN pip install uuid -i https://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.com --no-cache-dir
RUN pip install joblib -i https://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.com --no-cache-dir
这里依赖的是python-slim,这个版本的好处是体积小,如果不加slim打出来有好几GB,其余的都是项目的依赖。然后把这个打成一个基础镜像,在我们项目中引用这个镜像:
FROM syske.hubor.cn/common/semantic_search_base:1.0.2
# 创建code文件夹
RUN mkdir /semantic_search
# 将run.sh脚本复制到code文件夹下
COPY ./run.sh /semantic_search
# 将arduino-index.py脚本复制到code文件夹下
COPY ./index.py /semantic_search
COPY ./mylog.py /semantic_search
COPY ./retrieve.py /semantic_search
COPY ./config.py /semantic_search
COPY ./api_search.py /semantic_search
COPY ./searcher /semantic_search/searcher
COPY ./apollo /semantic_search/apollo
# 设置code文件夹为工作目录
WORKDIR /semantic_search
RUN cd /semantic_search
EXPOSE 8989
# 执行启动命令
CMD ["/bin/bash", "run.sh"]
我们的run.sh中写了项目的启动命令:
uvicorn api_search:app --port 8989 --host 0.0.0.0 --workers 2
至此,项目的镜像算是构建完了,然后开始接入apollo的改造
引入Apollo
首先,我们需要引入Apollo的客户端,这里我图方便直接从其他项目复制了,这个客户端代码很简单,就是通过requests来调用apollo的接口获取配置信息,具体我没有做深入研究,我只把apollo的地址和namespace透传进来,方便调用。
import json
import logging
import sys
import threading
import time
import requests
class ApolloClient(object):
def __init__(self, app_id, cluster='default', config_server_url='http://localhost:8080', interval=60, ip=None):
self.config_server_url = config_server_url
self.appId = app_id
self.cluster = cluster
self.timeout = 60
self.interval = interval
self.init_ip(ip)
self._stopping = False
self._cache = {}
self._notification_map = {'application': -1}
def init_ip(self, ip):
if ip:
self.ip = ip
else:
import socket
try:
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
s.connect(('8.8.8.8', 53))
ip = s.getsockname()[0]
finally:
s.close()
self.ip = ip
def get_value(self, key, default_val=None, namespace='application', auto_fetch_on_cache_miss=False):
if namespace not in self._notification_map:
self._notification_map[namespace] = -1
logging.getLogger(__name__).info("Add namespace '%s' to local notification map", namespace)
if namespace not in self._cache:
self._cache[namespace] = {}
logging.getLogger(__name__).info("Add namespace '%s' to local cache", namespace)
self._long_poll()
if key in self._cache[namespace]:
return self._cache[namespace][key]
else:
if auto_fetch_on_cache_miss:
return self._cached_http_get(key, default_val, namespace)
else:
return default_val
def start(self):
if len(self._cache) == 0:
self._long_poll()
t = threading.Thread(target=self._listener)
t.start()
def stop(self):
self._stopping = True
logging.getLogger(__name__).info("Stopping listener...")
def _cached_http_get(self, key, default_val, namespace='application'):
url = '{}/configfiles/json/{}/{}/{}?ip={}'.format(self.config_server_url, self.appId, self.cluster, namespace, self.ip)
r = requests.get(url)
if r.ok:
data = r.json()
self._cache[namespace] = data
logging.getLogger(__name__).info('Updated local cache for namespace %s', namespace)
else:
data = self._cache[namespace]
if key in data:
return data[key]
else:
return default_val
def _uncached_http_get(self, namespace='application'):
url = '{}/configs/{}/{}/{}?ip={}'.format(self.config_server_url, self.appId, self.cluster, namespace, self.ip)
r = requests.get(url)
if r.status_code == 200:
data = r.json()
self._cache[namespace] = data['configurations']
logging.getLogger(__name__).info('Updated local cache for namespace %s release key %s: %s',
namespace, data['releaseKey'],
repr(self._cache[namespace]))
def _long_poll(self):
url = '{}/notifications/v2'.format(self.config_server_url)
notifications = []
for key in self._notification_map:
notification_id = self._notification_map[key]
notifications.append({
'namespaceName': key,
'notificationId': notification_id
})
r = requests.get(url=url, params={
'appId': self.appId,
'cluster': self.cluster,
'notifications': json.dumps(notifications, ensure_ascii=False)
}, timeout=self.timeout)
logging.getLogger(__name__).debug('Long polling returns %d: url=%s', r.status_code, r.request.url)
if r.status_code == 304:
# no change, loop
logging.getLogger(__name__).debug('No change, loop...')
return
if r.status_code == 200:
data = r.json()
for entry in data:
ns = entry['namespaceName']
nid = entry['notificationId']
logging.getLogger(__name__).info("%s has changes: notificationId=%d", ns, nid)
self._uncached_http_get(ns)
self._notification_map[ns] = nid
else:
logging.getLogger(__name__).warn('Sleep...')
time.sleep(self.timeout)
def _listener(self):
logging.getLogger(__name__).info('Entering listener loop...')
while not self._stopping:
self._long_poll()
time.sleep(self.interval)
logging.getLogger(__name__).info("Listener stopped!")
之后在原有配置代码中使用apollo客户端:
from .pyapollo import ApolloClient
class ApolloData(object):
def __init__(self, config_server_url= "https://apollo.coolcollege.cn:8080", namespace = 'application'):
if namespace == None:
namespace = 'application'
app_id = "semantic-search"
client = ApolloClient(app_id=app_id, config_server_url=config_server_url, cluster='default', interval=10)
#如果是关联空间的值,必须使用namespace ,指定空间名称
# get config from apollo
self.es_host = client.get_value("ES.HOST", namespace=namespace)
self.es_pwd = client.get_value("ES.PASS", namespace=namespace)
self.es_user = client.get_value("ES.USER", namespace=namespace)
def get_es_host(self):
return self.es_host
def get_es_user(self):
return self.es_user
def get_es_pwd(self):
return self.es_pwd
这两个文件在同一个目录下,在具体使用配置的地方,获取apollo的环境变量,这样我们就可以获取apollo的配置了:
apollo_meta_config_server_url = os.getenv("config_server_url")
namespace = os.getenv("namespace")
apolloData = ApolloData(config_server_url=apollo_meta_config_server_url, namespace=namespace)
es_host = apolloData.get_es_host()
至此,配置代码层面的改造业也完成了,下面看下k8s的操作。
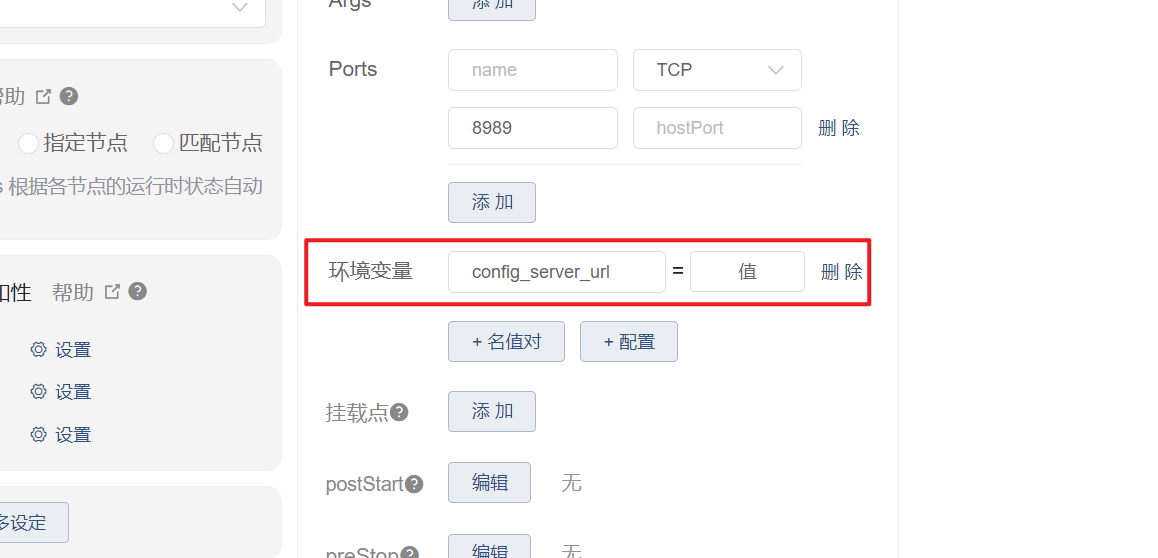
k8s设置环境变量
直接在环境变量那里增加对应的配置,并指定环境变量的值,这样项目运行时就可以通过os.getenv()方法来获取对应的配置
至此,整个流程搞完了。
结语
其实,以上内容在看的时候,感觉没有特别难,包括我现在看也是这样的感觉,但最开始我没有任何思路,一边找方案,一边各种尝试,用了各种apollo的客户端,踩了很多坑,折腾了好久,最终发现都不行,过程也是很艰辛的,当然最后几经尝试,问题终于一个一个被解决,当这条路跑通的时候,那会也是真的开心,虽然那天加班了,但是解决问题的感觉还是很爽的,这可能就是我觉得工作最有趣的地方~
所以说,问题本身既是挑战,也是快乐,希望你也能享受解决问题的过程,找到自己的快乐源泉
标签:__,python,解决方案,self,cache,namespace,url,._,k8s From: https://www.cnblogs.com/caoleiCoding/p/18196798