集合进阶(二)
Collection的其他相关知识
前置知识:可变参数
就是一种特殊形参,定义在方法、构造器的形参列表里,格式是:数据类型...参数名称。
特点
- 可以不传数据给它;可以传一个或者同时传多个数据给它;也可以传一个数组给它。
作用
常常用来灵活地接收数据。
注意事项
- 可变参数在方法内部就是一个数组。
- 一个形参列表中可变参数只能有一个。
- 可变参数必须放在形参列表的最后面。
Collections
是一个用来操作集合的工具类。
Collections提供的常用静态方法
| 方法名称 | 说明 |
|---|---|
| public static <T> boolean addAll(Collection<? super T> c, T... elements) | 给集合批量添加元素 |
| public static void shuffle(List<?> list) | 打乱List集合中的元素顺序 |
| public static <T> void sort(List<T> list) | 对List集合中的元素进行升序排序 |
| public static <T> void sort(List<T> list,Comparator<? super T> c) | 对List集合中元素,按照比较器对象指定的规则进行排序 |
Collections只能支持对List集合进行排序
- 排序方式1:
| 方法名称 | 说明 |
|---|---|
| public static <T> void sort(List<T> list) | 对List集合中元素按照默认规则排序 |
注意:本方法可以直接对自定义类型的List集合排序,但自定义类型必须实现了Comparable接口,指定了比较规则才可以。
- 排序方式2:
| 方法名称 | 说明 |
|---|---|
| public static <T> void sort(List<T> list,Comparator<? super T> c) | 对List集合中元素,按照比较器对象指定的规则进行排序 |
Map集合
- Map集合称为双列集合,格式:{key1=value1 , key2=value2 , key3=value3 , ...}, 一次需要存一对数据做为一个元素。
- Map集合的每个元素“key=value”称为一个键值对/键值对对象/一个Entry对象,Map集合也被叫做“键值对集合”。
- Map集合的所有键是不允许重复的,但值可以重复,键和值是一一对应的,每一个键只能找到自己对应的值。
Map集合在什么业务场景下使用
需要存储一一对应的数据时,就可以考虑使用Map集合来做。
Map集合体系
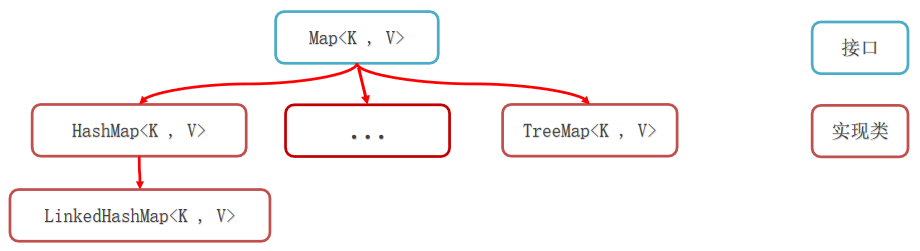
Map集合体系的特点
注意:Map系列集合的特点都是由键决定的,值只是一个附属品,是不做要求的。
- HashMap(由键决定特点):无序、不重复、无索引。(用的最多)
- LinkedHashMap (由键决定特点):有序、不重复、无索引。
- TreeMap (由键决定特点):按照大小默认升序排序、不重复、无索引。
当添加元素的键与之前的重复时,这个键对应的值会被更新。
经典代码:
Map<String, Integer> map = new HashMap<>();
Map的常用方法
Map是双列集合的祖宗,它的功能是全部双列集合都可以继承过来使用的。
| 方法名 | 说明 |
|---|---|
| public V put(K key,V value) | 添加元素 |
| public int size() | 获取集合的大小 |
| public void clear() | 清空集合 |
| public boolean isEmpty() | 判断集合是否为空,为空返回true , 反之返回false |
| public V get(Object key) | 根据键获取对应值 |
| public V remove(Object key) | 根据键删除整个元素 |
| public boolean containsKey(Object key) | 判断是否包含某个键 |
| public boolean containsValue(Object value) | 判断是否包含某个值 |
| public Set<K> keySet() | 获取全部键的集合 |
| public Collection<V> values() | 获取Map集合的全部值 |
| public void putAll(Map<? extends K, ? extends V> m) | 将指定映射中的所有映射复制到此映射(把m中的全部数据倒入主调映射中) |
Map集合的遍历方式
键找值
先获取Map集合全部的键,再通过遍历键来找值。
步骤:
- 使用
public Set<K> keySet()获取所有键的集合。 - 遍历1得到的集合,使用
public V get(Object key)来获取键对应的值。
键值对
把“键值对“看成一个整体进行遍历。需要用到以下方法:
| Map提供的方法 | 说明 |
|---|---|
| Set<Map.Entry<K, V>> entrySet() | 获取所有“键值对”的集合 |
| Map.Entry提供的方法 | 说明 |
|---|---|
| K getKey() | 获取键 |
| V getValue() | 获取值 |
步骤:
- 使用
Set<Map.Entry<K, V>> entrySet()获取所有键值对的集合。 - 遍历1得到的集合,使用
K getKey()和V getValue()来获取所有键值对的数据。
Lambda表达式
使用Lambda表达式来进行遍历,JDK1.8开始之后的新技术。需要用到以下方法:
| 方法名称 | 说明 |
|---|---|
| default void forEach(BiConsumer<? super K, ? super V> action) | 结合lambda遍历Map集合 |
格式:
map.forEach((k , v) -> {
System.out.println(k + "----->" + v);
});
HashMap
HashMap集合的底层原理
HashMap跟HashSet的底层原理是一模一样的,都是基于哈希表实现的。
实际上:Set系列集合的底层就是基于Map实现的,只是Set集合中的元素只要键数据,不要值数据而已。
HashMap集合的特点
- HashMap集合是一种增删改查数据性能都较好的集合。
- HashMap是无序,不能重复,没有索引支持的(由键决定特点)。
- HashMap的键依赖hashCode()方法和equals()方法保证键的唯一。
- 如果键存储的是自定义类型的对象,可以通过重写hashCode()和equals()方法,这样可以保证多个对象内容一样时,HashMap集合就能认为是重复的。
LinkedHashMap
LinkedHashMap集合的原理
底层数据结构依然是基于哈希表实现的,只是每个键值对元素又额外的多了一个双链表的机制记录元素顺序(保证有序)。
实际上:原来学习的LinkedHashSet集合的底层原理就是LinkedHashMap。
HashMap集合的特点
- LinkedHashMap集合是一种增删改查数据性能都较好的集合。
- HashMap是有序(增加了空间占用来达到有序的目的),不能重复,没有索引支持的(由键决定特点)。
TreeMap
TreeMap集合的原理
TreeMap跟TreeSet集合的底层原理是一样的,都是基于红黑树实现的排序。
TreeMap集合的特点
不重复、无索引、可排序(按照键的大小默认升序排序,只能对键排序)
TreeMap集合同样也支持两种方式来指定排序规则
- 让类实现Comparable接口,重写比较规则。
- TreeMap集合有一个有参数构造器,支持创建Comparator比较器对象,以便用来指定比较规则。
集合的嵌套
集合中的元素又是一个集合,这就叫集合的嵌套。
JDK8新特性:Stream
认识Stream
Stream也叫Stream流,是Jdk8开始新增的一套API (java.util.stream.*),可以用于操作集合或者数组的数据。
Stream流的优势
Stream流大量的结合了Lambda的语法风格来编程,提供了一种更加强大,更加简单的方式操作集合或者数组中的数据,代码更简洁,可读性更好。
Stream流的使用步骤
- 获取Stream流:Stream流代表一条流水线,并能与数据源建立连接
- 处理Stream流:调用流水线的各种方法对数据进行处理、计算。
- 终结Stream流:获取处理的结果,遍历、统计、收集到一个新集合中返回。
Stream流的常用方法
获取Stream流
- 获取集合的Stream流:
| Collection提供的如下方法 | 说明 |
|---|---|
| default Stream<E> stream() | 获取当前集合对象的Stream流 |
- 获取数组的Stream流:
| Arrays类提供的如下方法 | 说明 |
|---|---|
| public static <T> Stream<T> stream(T[] array) | 获取当前数组的Stream流 |
| Stream提供的如下方法 | 说明 |
|---|---|
| public static <T> Stream<T> of(T... values) | 获取当前接收数据的Stream流 |
处理Stream流
处理Stream流会用到一些中间方法。中间方法指的是调用完成后会返回新的Stream流,可以继续使用(支持链式编程)。
| Stream提供的常用中间方法 | 说明 |
|---|---|
| Stream<T> filter(Predicate<? super T> predicate) | 用于对流中的数据进行过滤 |
| Stream<T> sorted() | 对元素进行升序排序 |
| Stream<T> sorted(Comparator<? super T> comparator) | 按照指定规则排序 |
| Stream<T> limit(long maxSize) | 获取前几个元素 |
| Stream<T> skip(long n) | 跳过前几个元素 |
| Stream<T> distinct() | 去除流中重复的元素(若希望自定义对象的内容一样就重复, 则需要重写hashCode()和equals()方法) |
| <R> Stream<R> map(Function<? super T,? extends R> mapper) | 对元素进行加工,并返回对应的新流 |
| static <T> Stream<T> concat(Stream a, Stream b) | 合并a和b两个流为一个流 |
终结Stream流
终结Stream流会用到一些终结方法。终结方法指的是调用完成后,不会返回新Stream了,没法继续使用流了。
输出Stream流
| Stream提供的常用终结方法 | 说明 |
|---|---|
| void forEach(Consumer action) | 对此流运算后的元素执行遍历 |
| long count() | 统计此流运算后的元素个数 |
| Optional<T> max(Comparator<? super T> comparator) | 获取此流运算后的最大值元素 |
| Optional<T> min(Comparator<? super T> comparator) | 获取此流运算后的最小值元素 |
收集Stream流
Stream流只是方便操作集合/数组的手段;集合/数组才是开发中的目的。收集Stream流就是把Stream流操作后的结果转回到集合或者数组中去返回。
| Stream提供的常用终结方法 | 说明 |
|---|---|
| R collect(Collector collector) | 把流处理后的结果收集到一个指定的集合中去 |
| Object[] toArray() | 把流处理后的结果收集到一个数组中去 |
| Collectors工具类提供的具体的收集方式 | 说明 |
|---|---|
| public static <T> Collector toList() | 把元素收集到List集合中 |
| public static <T> Collector toSet() | 把元素收集到Set集合中 |
| public static Collector toMap(Function keyMapper , Function valueMapper) | 把元素收集到Map集合中,不能去重 |
注意:类似于迭代器,流只能收集一次。
标签:第十六,Java,Stream,Map,元素,笔记,获取,集合,public From: https://www.cnblogs.com/zgg1h/p/18075361