最小生成树(Kruskal和Prim算法)
部分资料来源于:最小生成树(Kruskal算法)_kruskal算法求最小生成树-CSDN博客、【算法】最小生成树——Prim和Kruskal算法-CSDN博客
关于图的几个概念定义:
连通图:在无向图中,若任意两个顶点vi与vj都有路径相通,则称该无向图为连通图。
强连通图:在有向图中,若任意两个顶点vi与vj都有路径相通,则称该有向图为强连通图。
连通网:在连通图中,若图的边具有一定的意义,每一条边都对应着一个数,称为权;权代表着连接连个顶点的代价,称这种连通图叫做连通网。
生成树:一个连通图的生成树是指一个连通子图,它含有图中全部n个顶点,但只有足以构成一棵树的n-1条边。一颗有n个顶点的生成树有且仅有n-1条边,如果生成树中再添加一条边,则必定成环。
最小生成树:在连通网的所有生成树中,所有边的代价和最小的生成树,称为最小生成树。
1.Kruskal算法
此算法可以称为“加边法”,初始最小生成树边数为0,每迭代一次就选择一条满足条件的最小代价边,加入到最小生成树的边集合里。
把图中的所有边按代价从小到大排序;
把图中的n个顶点看成独立的n棵树组成的森林;
按权值从小到大选择边,所选的边连接的两个顶点ui,vi,应属于两颗不同的树,则成为最小生成树的一条边,并将这两颗树合并作为一颗树。
重复(3),直到所有顶点都在一颗树内或者有n-1条边为止。
| parent | 1 | 5 | 8 | 7 | 7 | 8 | 7 | 0 | 6 |
|---|---|---|---|---|---|---|---|---|---|
例子:
输入
第1行:2个数N,M中间用空格分隔,N为点的数量,M为边的数量。(2 <= N <= 1000, 1 <= M <= 50000) 第2 - M + 1行:每行3个数S E W,分别表示M条边的2个顶点及权值。(1 <= S, E <= N,1 <= W <= 10000)
输出
输出最小生成树的所有边的权值之和。
输入示例
9 14
1 2 4
2 3 8
3 4 7
4 5 9
5 6 10
6 7 2
7 8 1
8 9 7
2 8 11
3 9 2
7 9 6
3 6 4
4 6 14
1 8 8
输出示例
7->8 权重:1
6->7 权重:2
3->9 权重:2
1->2 权重:4
3->6 权重:4
3->4 权重:7
1->3 权重:8
1->5 权重:9
总权重:37
代码示例:
#include <iostream>
#include <algorithm>
using namespace std;
const int MAXN = 5000 + 5;
const int MAXM = 200000 + 5;
const int INF = 0x3fffffff;
struct edge {
int u;
int v;
int w;
} e[MAXM];
int f[MAXN],cnt,m,n,ans;
bool cmp(edge x,edge y)//根据权重排序
{
return x.w<y.w;
}
int find(int x)//查找并查集
{
if(f[x]==x) {
return x;
} else {
f[x]=find(f[x]);//路径压缩
return f[x];
}
}
void Kruskal()
{
sort(e+1,e+m+1,cmp);
for(int i=1; i<=m; i++) {
int u = find(e[i].u);
int v = find(e[i].v);
if(u==v)continue;//判断两个点是否在同一颗树,同一棵树则成环跳过
ans+=e[i].w;
printf("%d->%d 权重:%d\n",u,v,e[i].w);
f[v]=u;//v点的父亲为u,意思为(u,v)这条边加入
cnt++;
if(cnt==n-1)break;//所有的点构成构成一棵树
}
}
int main()
{
printf("输入点的数目:");
cin>>n;
printf("输入边的数目:");
cin>>m;
for(int i=1; i<=n; i++) {//初始化,开始时每一个点都在各自的集合
f[i]=i;
}
printf("输入边:\n");
for(int i=1; i<=m; i++) {
cin>>e[i].u>>e[i].v>>e[i].w;
}
Kruskal();
printf("总权重:%d",ans);
return 0;
}
再来个例子:
原题链接:P3366 【模板】最小生成树 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
题目描述
如题,给出一个无向图,求出最小生成树,如果该图不连通,则输出 orz。
输入格式
第一行包含两个整数 \(N, M\) ,表示该图共有 \(N\) 个结点和 \(M\) 条无向边。
接下来 \(M\) 行每行包含三个整数 \(X_{i}, Y_{i}, Z_{i}\) ,表示有一条长度为 \(Z_{i}\) 的无向边连接结点 \(X_{i}, Y_{i}\) 。
输出格式
如果该图连通,则输出一个整数表示最小生成树的各边的长度之和。如果该图不连通则输出 orz。
输入输出样例
输入 #1
4 5
1 2 2
1 3 2
1 4 3
2 3 4
3 4 3
输出 #1
7
说明/提示
数据规模:
对于 \(20 \%\) 的数据, \(N \leq 5 , M \leq 20\) 。
对于 \(40 \%\) 的数据, \(N \leq 50 , M \leq 2500\) 。
对于 \(70 \%\) 的数据, \(N \leq 500, M \leq 10^{4}\) 。
对于 \(100 \%\) 的数据: \(1 \leq N \leq 5000 , 1 \leq M \leq 2 \times 10^{5} , 1 \leq Z_{i} \leq 10^{4}\) 。
样例解释:
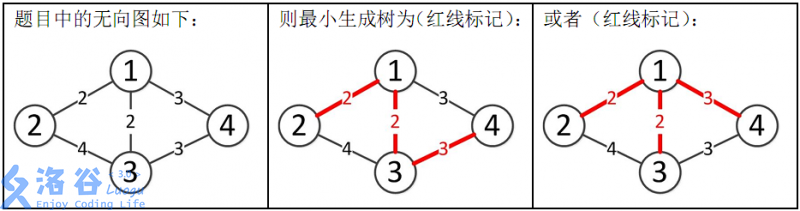
所以最小生成树的总边权为 2+2+3=72+2+3=7。
代码示例:
#include<iostream>
#include<algorithm>
using namespace std;
const int N = 1e6 + 10;
int fa[N];
int sum, u, v, w,n,m;
int tot;
struct node```cpp
#include<iostream>
#include<algorithm>
using namespace std;
const int N = 1e6 + 10;
int fa[N];
int sum, u, v, w,n,m;
int tot;
struct node
{
int x, y, z;
}e[N];
bool cmp(node a, node b)
{
return a.z < b.z;
}
void init(int n)
{
for (int i = 1; i <= n; i++)
{
fa[i] = i; // 初始化并查集,每个节点的父节点为自己
}
}
int find(int u)
{
if (u == fa[u]) // 如果节点的父节点就是自己,则返回该节点
return u;
else
return fa[u] = find(fa[u]); // 否则递归查找父节点,并路径压缩
}
int main()
{
cin >> n >> m; // 输入节点数和边数
init(n); // 初始化并查集
for (int i = 1; i <= m; i++)
{
cin >> e[i].x >> e[i].y >> e[i].z; // 输入边的起点、终点和权重
}
sort(e + 1, e + m + 1, cmp); // 对边按权重从小到大进行排序
for (int i = 1; i <= m; i++)
{
int q = find(e[i].x); // 查找起点所在集合的代表元素
int p = find(e[i].y); // 查找终点所在集合的代表元素
if (q != p) // 如果起点和终点不在同一个集合
{
fa[q] = p; // 将起点所在集合合并到终点所在集合
sum += e[i].z; // 累加权重
tot++; // 记录边的数量
}
else
continue;
}
if (tot == n - 1) // 如果最小生成树的边数为n-1,则输出最小生成树的权重
cout << sum << endl;
else
cout << "orz" << endl; // 否则输出"orz"
return 0;
}
Prim算法:
Prim算法解释
是采用从点方面考虑来构建MST的一种算法,Prim 算法在稠密图中比Kruskal优,通常步骤如下
1.从源点出发,将所有与源点连接的点加入一个待处理的集合中
2.从集合中找出与源点的边中权重最小的点,从待处理的集合中移除标记为确定的点
3.将找到的点按照步骤1的方式处理
4.重复2,3步直到所有的点都被标记
Prim算法的正确性证明
- 源点单独一个点时,可以作为MST
- 在与源点相连的点中找出权重最小的加入,显然加入MST后仍然成立
- 将所有的点一个一个加入,如果成环,如果新的边权重更小,则替代权重大的,得到的仍然是MST
- 综上Prim算法中,MST总不被破坏,所以Prim算法总是正确的
图解
作为坚信图比文字更容易理解,接下来我们将通过例题,更直观的了解Prim算法,给定下图,要我们求出从V1点出发的最小生成树

第一步,我们首先将源点V1点加入,并把所有相连的点都加入带处理的集合
惯例的我们将处理完的点标记为红点,待处理的点几位蓝点,如下图

接下来从待处理的点中找出权重最小的边,将所连的点标记为红色,并且重复第一步得到,在找到(V4,V3)边的时候,因为V4->V3的权重小于V1->V3的权重,所以这里V1->V3这个边可以扔了

同理对其他的点都进行上诉操作,最后得到总权重和为16

Prim算法和Dijkstra算法极其相似,特别注意的是:
-
Dijkstra算法的dist数组存的是该点到起点的距离
-
Prim算法的dist数组存的是该点到"树"的集合的距离
就造成了细微的差别,其中该语句:
Prim算法中是这样的:
for (int j = 1; j <= n; j++) // 更新距离数组
dist[j] = min(dist[j], g[t][j]);
而Dijkstra算法中是这样的:
for (int j = 1; j <= n; j++) // 更新距离数组
dist[j] = min(dist[j], dis[t]+g[t][j]);
代码示例:
#include<iostream>
#include<algorithm>
#include<cstring>
using namespace std;
const int N = 5100;
int n, m;
int a, b, c;
int dist[N];
const int INF = 0x3f3f3f3f; // 定义一个极大值
bool st[N];
int g[N][N]; // 存储图的邻接矩阵
int prim()
{
memset(dist, INF, sizeof dist); // 将距离数组初始化为极大值
int res = 0; // 记录最小生成树的权值和
for (int i = 0; i < n; i++) // 进行 n 次循环,每次找到一个新节点加入最小生成树
{
int t = -1; // t 表示当前距离最小的节点编号
for (int j = 1; j <= n; j++) // 在所有未加入最小生成树的节点中,找到距离最小的节点
{
if(!st[j]&&(t==-1||dist[t]>dist[j]))
t=j;
}
if(i&&dist[t]==INF) // 如果当前加入的节点距离为极大值,说明无法到达该节点,返回极大值表示无解
return INF;
if (i)
res += dist[t]; // 将当前加入节点的距离加入最小生成树的权值和
for (int j = 1; j <= n; j++) // 更新距离数组
dist[j] = min(dist[j], g[t][j]);
st[t] = true; // 标记该节点已加入最小生成树
}
return res; // 返回最小生成树的权值和
}
int main()
{
cin >> n >> m;
memset(g, INF, sizeof g); // 初始化邻接矩阵为极大值
while (m--)
{
cin >> a >> b >> c;
g[a][b] = g[b][a] = min(g[a][b], c); // 如果有重边,取最小值
}
int t = prim(); // 求最小生成树的权值和
if (t == INF)
cout << "orz" << endl;
else
cout << t << endl;
return 0;
}
四.总结
以上就是最小生成树的其中的两个最经常使用的算法了,两种各有优劣,Kruskal算法容易理解,编写容易,但是在稠密图时间效率比Prim算法差,但Prim算法又相对于Kruskal难理解,代码量也要多些。
标签:Prim,权重,int,Kruskal,最小,生成,算法 From: https://www.cnblogs.com/KAI040522/p/17859926.html