一、介绍
花朵识别系统,使用Python作为主要编程语言进行开发,使用TensorFlow搭建卷积神经网络算法模型,并基于多种花朵数据集进行模型训练,最后得到一个精度较高的h5模型文件。并基于Django框架搭建网页端可视化操作界面。实现用户上传一张花朵图片,识别其名称。
二、效果图片展示

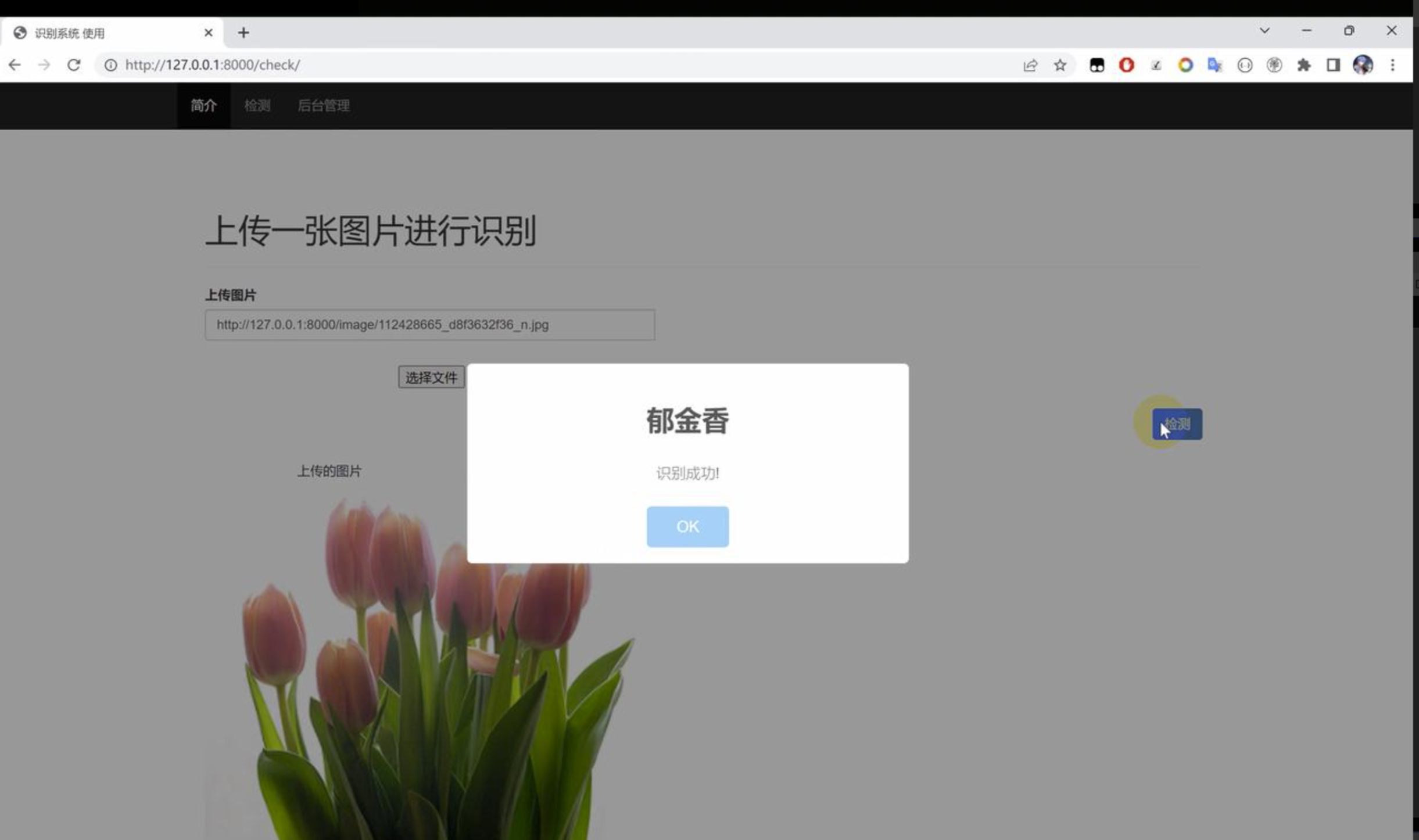
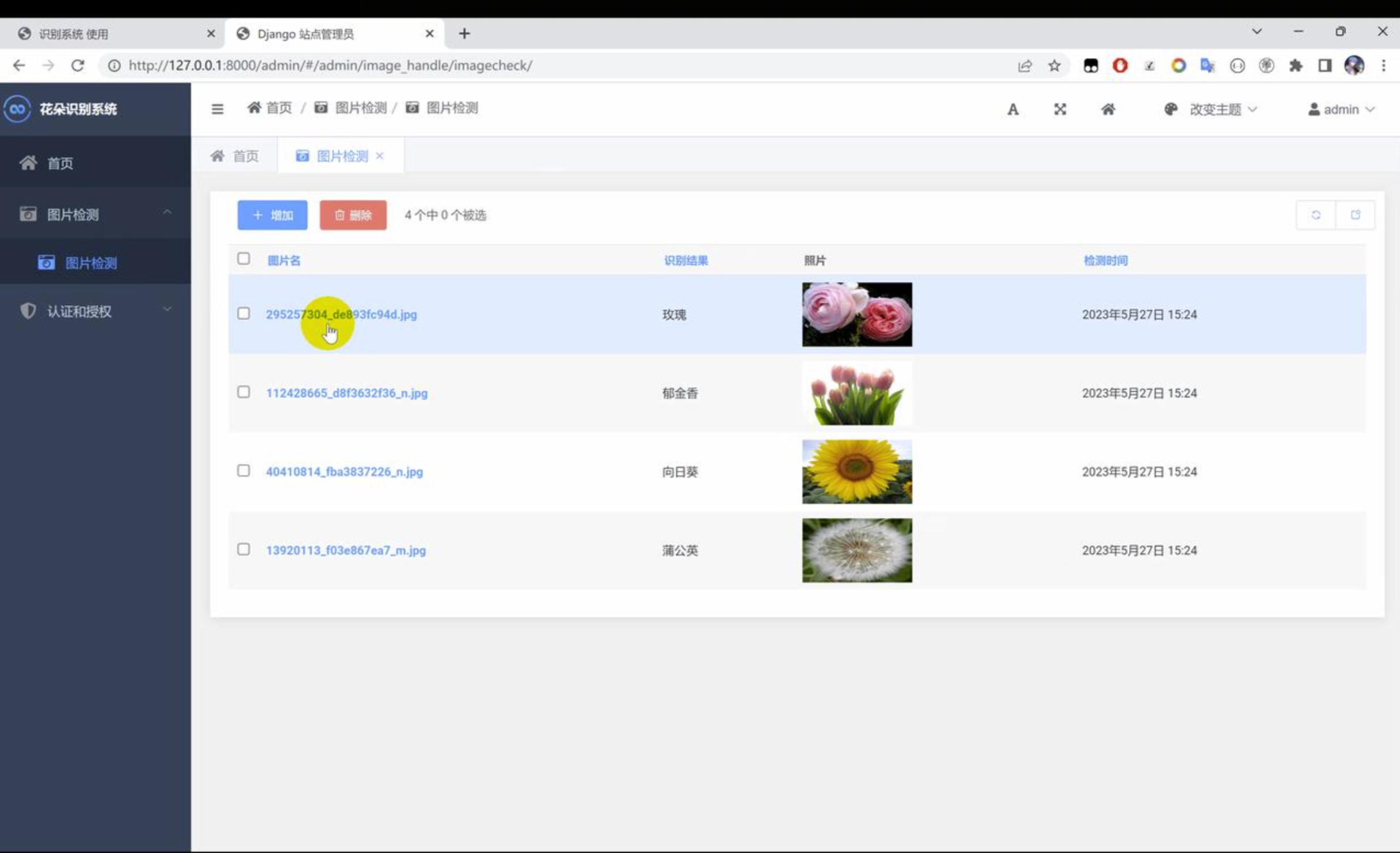
三、演示视频 and 代码
视频 和 代码地址:https://s7bacwcxv4.feishu.cn/wiki/RGpKwv5XQikb8ck6V3ucVmZXnpb
四、TensorFlow在图像分类方面使用
TensorFlow是一个非常流行的开源深度学习框架,它广泛用于各种机器学习任务,其中包括图像分类。TensorFlow提供了大量的API,允许用户从基本操作到高级神经网络模型都能轻松实现。
下面是一个简单的图像分类任务的例子,我们将使用TensorFlow和Keras库(Keras是TensorFlow的高级API)来实现这个任务:
1. 准备数据
我们使用的是CIFAR-10数据集,它包含10个类别的60000个32x32彩色图像。
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
# 归一化像素值,使其在0到1的范围内
train_images, test_images = train_images / 255.0, test_images / 255.0
2. 建立模型
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(10)
])
model.summary()
3. 编译和训练模型
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
history = model.fit(train_images, train_labels, epochs=10,
validation_data=(test_images, test_labels))
4. 评估模型
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('\nTest accuracy:', test_acc)
这只是一个简单的图像分类示例,实际应用中可能会涉及到更复杂的网络结构、数据增强、迁移学习等策略来提高性能。
标签:layers,Python,模型,Django,test,train,images,TensorFlow From: https://www.cnblogs.com/qcpython/p/17757871.html